基于HTTP协议的业务系统网页数据采集应用集成
2019-01-30路辉高尚飞李少龙
文/路辉 高尚飞 李少龙
随着现代信息技术的迅猛发展,互联网规模的不断扩大,尤其家庭光纤网络宽带的接入和4G移动网的不断普及,新的网络业务层出不穷,互联网应用已经深入到人们生活的方方面面,B/S(Browser客户端浏览器/Server服务器端服务应用)技术架构的互联网网站由于其可直接通过浏览器进行网站访问优势,是其发展及应用最为突出和广泛。互联网网站使用超文本标记语言(HTML)作为表达的信息展示www(万维网)网站,其分为客户端浏览器和服务器端应用程序的开发架构模式。目前,企事业单位内部业务系统采用B/S架构以成为系统建设共同遵循和采用的技术架构,广泛应用于企业级信息管理系统和业务系统。
HTTP协议,即超文本传输协议(HTTPHypertext transfer protocol)是一种详细规定了浏览器和万维网服务器之间互相通信的规则,通过因特网传送万维网文档的数据传送协议。HTTP协议是一种分布式、协作式的通信协议,用户客户端浏览器与服务端web服务器的数据传输交互,是互联网上应用层上应用最广泛的协议。
1 业务系统集成分析
互联网网站主要分为信息提供和业务操作类,信息提供如新闻、股票行情之类的网站,业务操作如网上营业厅等。当然,也有很多网站同时具有这两种性质,如购物网站、视频网站等,既提供信息,也实现某些业务。随着互联网的飞速发展,由于基于HTTP协议传输的Browser/Server模式架构的优势,企业级业务系统采用B/S技术架构已是通用架构标准。B/S结构是随着Internet技术的兴起,对C/S结构的一种改进,在这种结构下,软件应用的业务逻辑完全在应用服务器端实现,用户表现完全在Web服务器实现,客户端只需要浏览器即可进行业务处理,是一种全新的系统构造技术。
目前,基于B/S架构的企业级业务系统实现系统间数据集成方式主要有两种方式,一是采用接口的系统间数据集成,其应用最为典型和广泛的为Web Service的服务接口应用;二是数据库层数据库账号授权访问的数据获取集成方式。
Web Service是使用SOAP机制的XML消息传递,XML 是目前主流的数据交换技术,它可以实现具有相当灵活性的、通用的数据交换接口,可以有效的解决不同应用系统、不同数据源之间的数据共享与交流问题,实现原理如图1Web Service接口实现原理所示。
数据库的账号授权访问是指通过在数据库中以管理员身份权限创建一个新的用户,并给其赋予相应权限的操作。典型的数据库权限控制为Oracle数据库,其权限为允许用户访问属于其它用户的对象或执行程序,ORACLE系统提供三种权限:Object对象级、System系统级、Role 角色级,日常用到的为系统及管理权限,主要包括DBA、RESOURCE及CONNECT三种权限;然而,在业务系统的数据库账号访问实现业务系统数据共享时,往往要精确到实体级(即数据库表或视图)上的select(查询)、update(更新)、insert(插入)、delete(删除)等具体的数据访问控制,确保数据的安全管控。
业务系统的接口集成或数据库授权访问集成,均需要原业务系统进行相关改造或申请账号及授权操作,其往往在实际工作中由于改造需项目资金支持或利益风险等原因,导致业务系统数据集成工作常常难以推进,影响相关业务开展工作。
2 互联网网页数据采集分析
互联网网页数据的采集通常是针对信息提供类网站的网页数据抓取后进行分类存储,是一个自动提取网页表单数据的Web 程序。互联网信息采集我们主要采用基于垂直搜索引擎的主题爬虫技术,对互联网上的某类主题信息页面全自动识别、分类、抓取, 并能够实现网页指纹消重和信息消重, 同时对主题信息页面进行去除无关信息和信息自动抽取。针对不同的网络爬虫采集形式,其主要实现原理如图2互联网数据采集基本实现流程所示。
网络爬虫的基本工作流程:首先选取一部分精心挑选的种子URL;再将这些URL放入待抓取URL队列;从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。最后分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
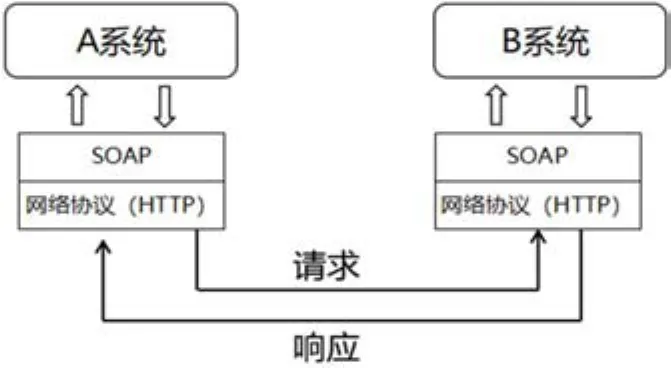
图1:Web Service接口实现原理
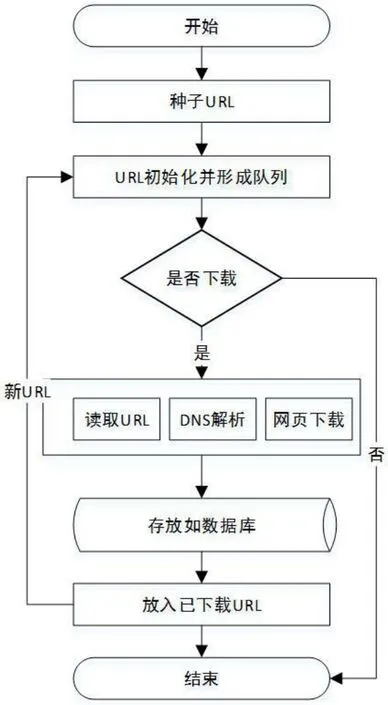
图2:互联网数据采集基本实现流程
3 基于HTTP协议的业务系统数据采集设计
3.1 设计思路
基于HTTP协议的业务系统数据采集功能结构设计包括采集设置、数据采集、任务调度及数据存储4部分。数据采集结构如图3业务系统数据采集系统结构图所示。
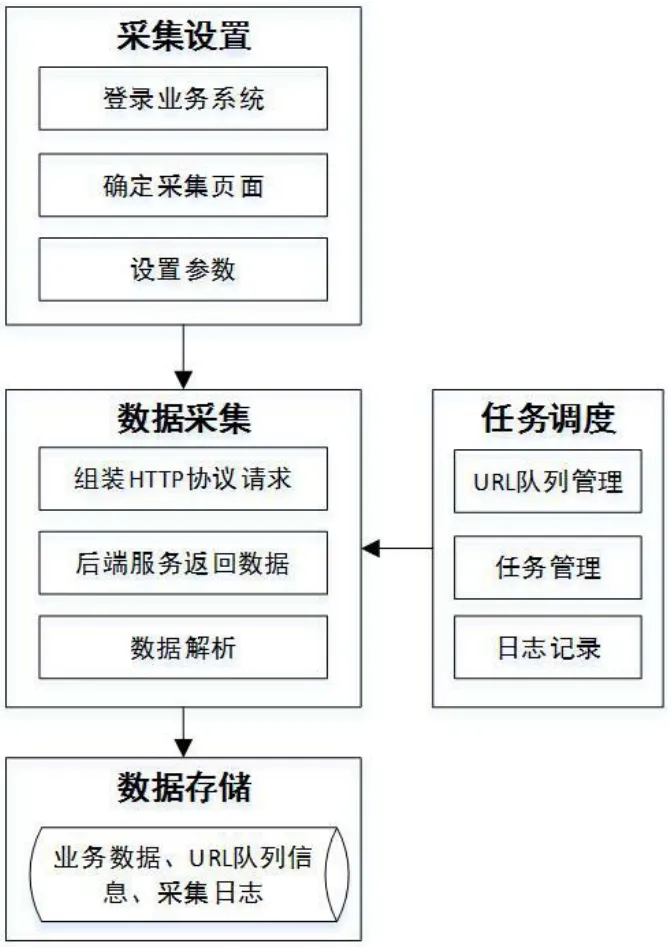
图3:业务系统数据采集系统结构图
数据采集设置主要要求使用者完成要采用业务系统的登录操作,且需保证采集用户是业务系统的合法用户,权限满足数据采集要求(有操作查看数据的权限),一般要求为管理员用户角色权限,然后确定需要采集的数据页面,即确定好采集URL地址,最后再按照要求进行采集参数设置(如采集某一年、某一地区)。数据采集过程是按照任务调度的分发进行数据采集执行,核心操作为按照采集参数设置,组装HTTP协议请求报文向后台应用服务请求,后端服务监听到前端请求后作出响应并返回数据,采集程序再接到返回数据后按照数据解析规则进行数据解析,整个采集过程都将进行URL队列的管理及采集日志记录;数据采集过程最后把采集并解析的业务数据、任务调度的URL队列信息及采集日志统一存储至数据库表中。
3.2 数据采集
基于HTTP协议的业务系统数据采集原理如图4数据采集基本流程图所示,核心步骤主要包括HTTP协议请求报文、HTTP响应报文及数据解析过程。
根据系统数据采集采集操作、数据采集、任务调度及数据存储4部分功能结构相关关系,系统总体流程执行如下:
(1)以业务系统的合法、权限满足用户账号登录相应业务系统,确定需要采集数据的页面URL地址,通常业务系统架构多数采用框架进行的多页面集成,所以采集页面对应的URL地址一般为数据查询列表的查询按钮事件连接。
(2)按照采集页面的查询参数进行采集参数设置,如时间、区域等参数,一般为全数据采集,确定参数后进行进行HTTP请求报文(从客户向服务器发送的请求报文)组装,HTTP请求报文由请求行(request line)、请求头部(header)、空行和请求数据4个部分组成。
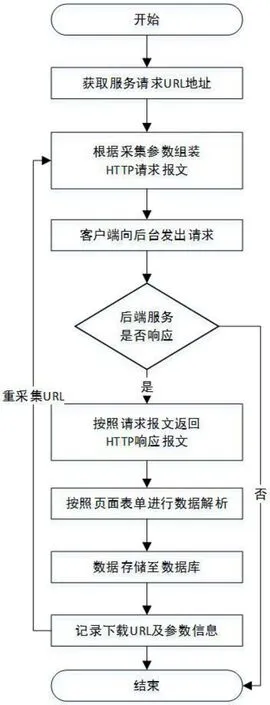
图4:数据采集基本流程图
(3)组装好请求报文后,客户端向服务的发送报文请求,其根本操作就是按照请求报文内容的请求对应的URL地址发送去搬过去,URL地址和报文头的Host属性组成完整的请求URL。
(4)服务器端的响应报文,系统后台服务按照客户端请求返回响应报文,HTTP响应也由三个部分组成,分别是:状态行(statusline)、 消 息 报 头(headers)、 响 应 正 文(response-body)。
(5)页面表单数据解析操作就是针对响应报文返回的响应正文进行数据解析,一般简单时直接用正则表达式对整个响应报文进行匹配提取出对应信息,但我们业务系统的数据库内容一般都是批量操作的,返回的数据均是整个数据库中存储对应数据表的全量数据,所以用解析HTML的方法解析。
(6)数据解析完毕后,按照业务列表即表头标识把对应列页面数据存储至数据库中,同时进行相关日志记录,并把采集的URL地址及参数信息同时记录存储至数据库日志表中。
(7)重复以上步骤(2)-(6),直至数据采集完毕,则数据采集程序结束。
在数据采集过程中,由于目前很多业务系统为了数据响应的及时性,会按照页面列表显示的条数进行指定数据行数的返回,此时要特别注意进行“下一页”的URL继续采集,直至“最后一页”采集完毕。
3.3 数据解析
HTTP响应报文数据解析主要是对响应正文(response-body)内容进行解析,其内容为标准的HTML标记语言格式,由规范的
HTML标签组成,数据解析主要针对标签内容。营销管理系统中查询转变用户清单时,显示如图5营销管理系统转变用户清单列表图系统列表界面所示。
分析报文中的的标签内部内容其内部嵌套有标签,详细标签内容如下:


图5:营销管理系统转变用户清单列表图
依据其标签规范,我可以发现其列表内容均为标签的内集合里面,并根据其内部的标签获取对应的列值。在解析数据时,首先遍历集合,其次嵌套遍历标签集合,同时按照一定的规则规律过滤掉不符合的
另外,pathon语言提供的许多工具可以行轻松的HTTP协议的响应报文内容解析操作,如导入beautifulsoup4库,可以把HTTP响应报文格式为HTML文档,遍历此文档,可以从中挑选出特定的标签;导入re(正则)库可以很容易的实现和正则相关的验证。例如,判断一个字符串是否可以匹配某个正则表达式、从一个字符串中找出所有的能够匹配的字符串等。
3.4 数据存储
数据存储前需要进行对应数据库表的设计,表名可按照业务系统列表内容进行命名,数据库字段名则按照业务系统列表值的分析,可以直接按照列表页面(图5营销管理系统转变用户清单列表图)的列表头(如序号、用户编号、用户名称等)进行表字段名的直接英文翻译命名。后续按照开发的应用进行数据的直接插入数据库表中进行存储,实现业务系统页面数据的获取,为下一步的数据集成共享提供对应业务系统的数据支撑。
4 结语
本文对基于HTTP协议的业务系统网页数据采集做顶层的研究与设计,并结合电力营销管理系统进行数据的抓取和解析分析,为基于B/S架构的业务系统不通过接口或数据库直接访问的方式实现系统间的数据集成共享,有效解决因业务系统间安全规范、网络不允许等客观条件、或业务系统建设方不配合开放接口时,实现业务数据间的数据集成共享问题。
