作物表型组数据库研究进展及展望*
2019-01-29王璟璐潘晓迪卢宪菊马黎明郭新宇
王璟璐 ,张 颖 ,潘晓迪 ,卢宪菊 ,马黎明 ,郭新宇 ※
(1. 北京市农林科学院北京农业信息技术研究中心,北京100097;2. 数字植物北京重点实验室,北京100097)
0 引言
作物及其相关领域科学研究与粮食问题息息相关。由于全球气候变化,作物生产面临着更频繁的极端天气,加之有限的水分及养分资源和可耕地面积,农业生产迫切需要新型气候适应性品种的繁育,以满足人们日益增长的粮食需求以及生物能源等其他工业用途的作物供应需求。
随着人类基因组计划(Human Genome Project,HGP)的完成,水稻[1-2]、玉米[3]、高粱[4]、大豆[5]和小麦[6]等主要农作物的基因组也相继被破译,作物研究随之进入组学时代。计算机技术的快速发展为有效管理急速增多的生物学数据提供了可能,而生物信息学成为处理和挖掘高通量数据信息的主要手段。在生物信息学中,数据库作为其研究的主要载体出现在生命科学的众多领域。数据库管理系统(Database Management system,DBMs)可以实现数据的存储、检索、分析和维护,互联网技术为数据库的开发、维护、推广和应用提供了有效工具。如今,基因组学、蛋白质组学、代谢组学等各类组学数据库,不仅为该领域的研究和发展提供了丰富的数据信息,同时又加强了多组学间及与其他系统生物学分支间的联系,为学科间的交叉研究奠定了基础。
近年来,表型组学(Phenomics)日渐兴起并成为一门快速发展的数据密集型学科。表型组学相关技术和研究手段的高速发展,带来了数量巨大、尺度多维、数据多样的表型信息,如RGB、高光谱、近红外、热和荧光成像等图像数据,植物生长过程中的各项生理指标数据等[7]。促使该领域的模型和数据管理系统随之发展,以便能够合理利用这些复杂的、动态的、大规模表型数据。
文 章 从Web of Science(http://apps.webofknowledge.com)、NCBI的PubMed(https://www.ncbi.nlm.nih.gov/pubmed/)和中国知网(CNKI,http://epub.cnki.net/kns/default.htm)等常用公共文献数据库中对已发表的作物表型组学相关研究文献进行检索,据此对国内外作物表型组学研究现状进行分析,并基于其中的数据库研究,对目前的作物表型相关数据库进行综述。最后,该文就作物表型组数据库构建的标准及要求进行了介绍,并将参照这些数据库构建原则在实际研究中设计自己的作物表型组数据库。
1 作物表型组学研究现状
表型组学这一概念于1996年由衰老研究中心主任Steven A.Garan在滑铁卢大学的一次应邀演讲上首次提出[8]。表型组学的定义类似于基因组学及其他组学,是指在基因组水平上系统地研究某一生物或细胞在各种不同环境条件下所有表型的学科。自2009年以来,随着植物表型无损获取方法以及大规模自动化高通量表型获取设施的建立[9],表型组技术开始应用于基础植物研究和作物育种中,并有望打破育种中的表型瓶颈[10]。如今,表型组学在植物,尤其是作物研究中逐年增多。作物表型组学的研究基于高通量信息获取平台收集的大量作物表型数据,包括株高、叶面积、果实等形态特征,水分利用效率和光合作用等生理特征以及花青素含量等生化特征。因为作物表型本身具有很高的复杂性,且时常处于动态变化中,所以研究人员在实际研究过程中一般只关注少数几个表型,进行非动态的粗略研究。加之传统的作物表型获取效率低,表型研究技术也相对落后,使得表型组学在作物研究领域严重滞后于其他组学研究。截至目前,在单一表型或只关注少数几个表型层面的研究已有很多,而从组学出发对作物表型进行的研究才刚刚起步。
该文在常用文献检索数据库Web of Science、PubMed和中国知网上对已发表的作物表型组学相关研究进行检索。从表型组的概念提出至今,外文文献中以表型组学为主题的文献有720篇,其中限定为作物和常见作物名称(如水稻、玉米、小麦等)后的文献数量为288篇。而以作物表型组学及常见作物名称为关键词在中国知网中进行检索,可得到中文期刊文献约20篇。由图1可以看出,近年来,作物研究领域中以表型组学为主题的文章数目逐年增多,且近5年来数量陡增,可见随着高通量作物表型获取手段的不断开发和完善,研究人员越来越关注表型组学的研究。

图1 近年来作物表型组学研究文献数量及趋势Fig.1 The number and trend of published papers focused on Crop Phenomics in recent years
作物表型组学的急速发展伴随着大量表型数据的产生,这就需要研究人员思考如何更好地对获得的表型数据进行管理。在数据管理中,建立标准数据库是一种十分便利且有效的方式。通过建立作物表型组数据库,可以对表型数据进行存储和分类,便于研究人员检索、分析并分享研究成果。
2 作物表型组数据库研究进展
不同于基因组学已有许多大型的、公认的、成熟的公共数据库,如人类基因组图谱数据库(The Genome Database,GDB)[11]、Ensembl基因组注释数据库[12]和GenBank DNA序列数据库[13]等,作物表型组学数据库虽已有一些,但综合性较强、普适性较广的通用标准数据库却不是很多。在该文检索到的近300篇有关作物表型组学的研究中,关于表型组数据库的研究仅20余篇。这些作物表型组数据库大多以物种进行分类,其数据形式丰富多样,具体内容和访问网址详见表1。
该文对Planteome数据库[14]、PGP知识库[15]和OPTIMAS-DW玉米资源库[16]等主要作物表型相关数据库进行介绍,便于相关研究人员更好地使用,也为建立自己的作物表型组数据库提供借鉴。

表1 主要作物表型数据库信息Table 1 List of main crop phenotypic databases
2.1 Planteome数据库:植物基因组和表型组数据共享平台
Planteome数据库[14]为特定物种的植物本体以及基因和表型注释提供了一套参考。本体用作大量且不断增长的植物基因组学、表型组学和遗传学数据语料库的语义整合的通用标准。参考本体包括植物本体论(Plant Ontology),植物性状本体论(Plant Trait Ontology),由Planteome开发的植物实验条件本体论(Plant Experimental Conditions Ontology),基因本体论(Gene Ontology),生物学兴趣的化学实体(Chemical Entities of Biological Interest),表型和属性本体论(Phenotype and Attribute Ontology)等。该项目还提供了来自世界各地的各种植物育种和研究团体开发的特定物种作物本体的途径。该数据库中提供了来自95种植物分类群的植物性状、表型、基因功能和表达的综合数据并以参考本体术语注释。Planteome项目还开发了一个植物基因注释平台——Planteome Noctua,方便研究人员参与交流。所有Planteome本体都是公开可用的,并存放于Planteome GitHub站点,便于共享、跟踪修订和新请求。Planteome数据库中所存储的数据均可免费访问。
Planteome数据库拥有8种特定种类的作物本体(Crop Ontologies)[14],其中对性状和表型评分标准的描述已被国际育种项目maize(玉米),sweet potato(甘薯),soybean(大豆),pigeon pea(木豆),rice(水稻),cassava(木薯),lentil(小扁豆)和wheat(小麦)采用。此外,该数据库还提供了Planteome Noctua基因注释工具,用于将研究社区与植物基因的功能注释相结合。
Planteome数据库具有本体浏览器和分面搜索选项,可访问各种生物实体的本体和基于本体的注释。所有数据和本体都存储在一个索引系统中,该索引系统允许通过本体浏览器进行全文搜索。GitHub存储库(https://github.com/Planteome/amigo)提供了数据存储设计的模式和索引文件。在目前的Planteome 2.0 Release中,Planteome数据库囊括了大约200万生物或数据对象的访问,包括蛋白质、基因、RNA转录、基因模型、种质和数量性状基因座。生物实体注释通常使用来自同一或多个引用本体类的多个本体术语。目前,这200万个实体大约有2 100万个注释。此外,该数据库还提供了转至多个参考本体的链接(表2)。
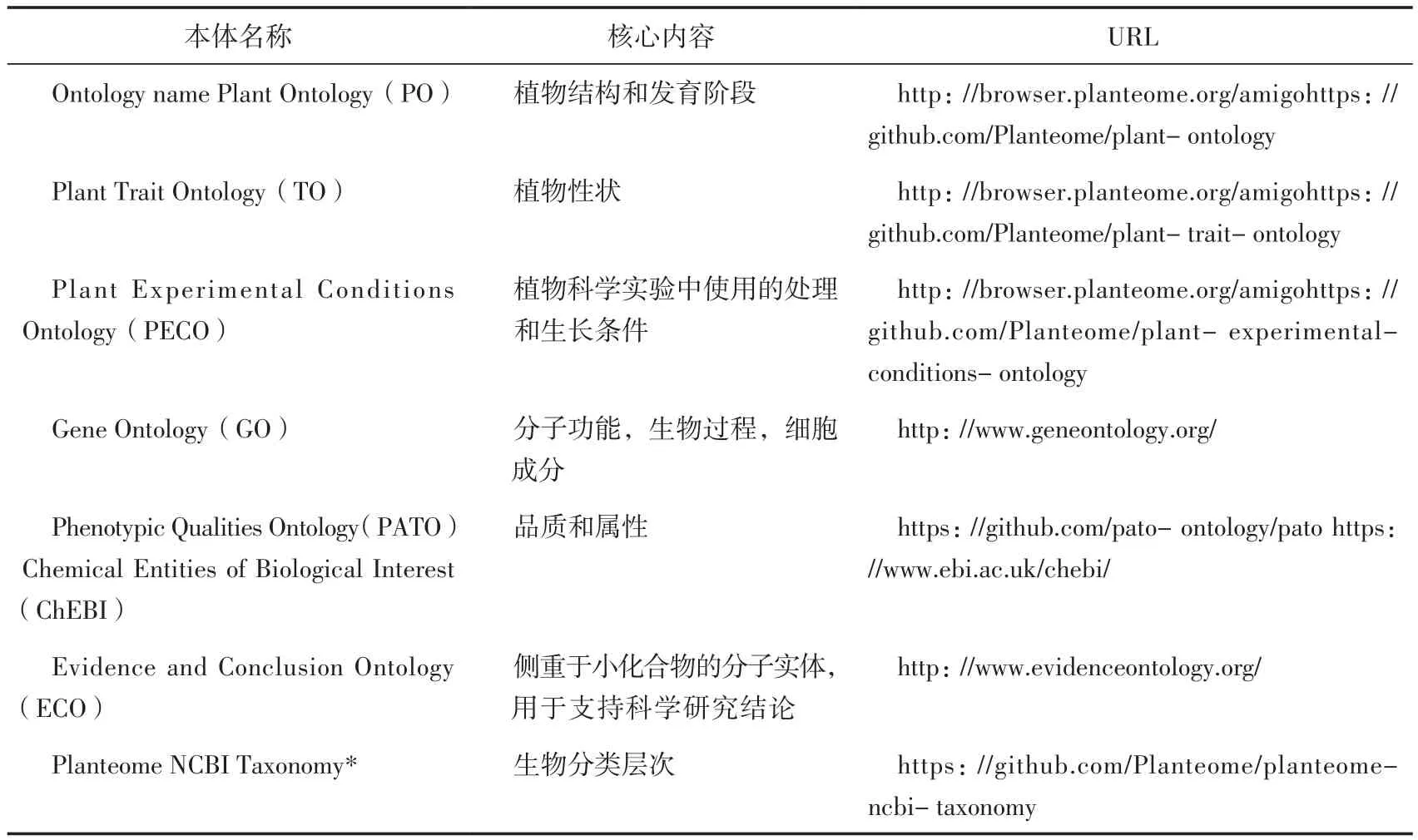
表2 Planteome参考本体和词汇Table 2 Planteome reference ontologies and vocabularies
2.2 PGP知识库:植物表型和基因组学数据发布基础平台
PGP 知识库[15](Plant Genomics and Phenomics Research Data Repository)是由莱布尼茨植物遗传与作物植物研究所和德国植物表型分析网络联合发起的植物基因组学和表型组学研究数据库,目的在于分享源自植物基因组学和表型组学的研究数据。PGP中涵盖了因数量或数据范围不被支持而未在中央存储库中发布的跨域数据集,如来自植物表型和显微镜的图像集,未完成的基因组、基因型数据,形态植物模型的可视化,来自质谱以及软件和文档的数据等。该存储库由莱布尼茨植物遗传学和作物植物研究所托管,使用e!DAL作为软件基础平台,并使用分层存储管理系统作为数据存档后端。PGP知识库具有成熟的数据提交工具,该工具高度自动化,可降低数据发布的障碍。经过内部审核流程之后,数据将作为可引用的数字对象标识符发布,并在DataCite中注册一组核心技术元数据。e!DAL嵌入式网页前端为每个数据集生成登录页面并支持交互式探索。PGP作为有效的EU Horizon 2020开放数据存档,在BioSharing.org、re3data.org和OpenAIRE已注册为研究数据存储库。在上述功能中,编程接口和标准元数据格式的支持使PGP能够实现FAIR数据原则——可查找、可访问、可互操作和可重用。
PGP主要着眼于发布和共享涵盖各种数据领域的主要实验数据,如高通量植物表型分类的图像收集、序列组装、基因分型数据、形态植物模型的可视化和质谱数据,甚至软件。PGP存储库中的数据集被分配给在DataCite上注册的可用DOI,其中包含一组标准化的技术元数据。截至2015年12月,PGP中已有54个数据集作为DOI发布,并在DataCite研究数据目录中注册。其中,每个数据集中都包括与特定实验或科学论文相关的所有记录。PGP存储库目前拥有21 157个数据实体,总体容量为65.4 GB。
2.3 OPTIMAS-DW:玉米的转录组学、代谢组学、离子组学、蛋白质组学和表型组学综合数据资源库
OPTIMAS-DW(OPTIMAS Data Warehouse)数据库[16]是有关玉米研究的综合数据集。该数据库整合了来自不同数据域的数据,如转录组学、代谢组学、离子组学、蛋白质组学和表型组学。OPTIMAS项目中设计并注释了44 K寡核苷酸芯片,以描述所选unigenes的功能。该项目进行了几个处理和植物生长阶段实验,并将测量数据填充到数据模板中。数据模板中的数据通过基于Java的导入工具导入数据库中。Web界面允许用户浏览OPTIMAS-DW中所有数据域的存储实验数据。此外,用户可以过滤数据以提取自己感兴趣的信息。数据库中的所有数据可以导出为不同的文件格式,以进行进一步的数据分析和可视化。数据分析集成了来自不同数据领域的数据,使用户能够找到不同系统生物学问题的答案。此外,OPTIMAS-DW数据库中还给出了玉米特异性通路信息。该数据库的特点是能够处理不同的数据领域,还包含了几项数据分析结果,这些都对相关研究人员的工作起到支持作用,特别是系统生物学研究领域。
2.4 BIOGEN BASE-CASSAVA:木薯表型组和基因组信息资源库
BIOGEN BASE-CASSAVA是用于研究木薯表型组学和基因组学信息的网络可访问资源库[17],该数据库中展示了农作物木薯(Casssava)的研究成果。其中,木薯表型检索板块中,每种种质都有包括定量和定性性状在内的约28个表型特征。CASSAVA数据库使用PHP和MySQL设计,并配备了广泛的搜索选项。它通过开放、通用和全球性的论坛为所有对该领域感兴趣的个人提供丰富的遗传学和基因组学数据。该数据库界面友好,所有数据均公开发布,有助于相关研究者对木薯的研究和开发。BIOGEN BASE资源库由泰米尔纳德邦农业大学的两个研究站(Tapioca和Castor)维护。除木薯外,BIOGEN BASE资源库还拥有水稻和玉米资源库以及其他数据库资源。
2.5 其他作物表型相关数据库
除以上作物组学数据库外,还有一些数据库中也包含了特有的作物表型信息。TRIM数据库[18],即台湾水稻插入突变体数据库,包含了有关突变体系的整合位点和表型信息,为水稻表型组学研究提供了良好资源。Gramene[19]是一个植物基因组比较基因组学数据库,提供了多种作物(如水稻、高粱和玉米等大田作物)的公开数据来源,除作物基因组学数据(如遗传标记、基因、蛋白、信号通路等)外,还包含了部分作物表型信息。Grain Genes作为小麦家族作物信息的专门数据库,包含了小麦等麦类的分子和表型信息数据。
3 作物表型组数据库构建标准及要求
数据管理是管理、存储和共享研究数据的过程[7]。当数据研究涉及多个研究人员或在复杂环境中进行研究时,这项工作将非常具有挑战性[21]。数据的管理方法取决于整个研究过程中所涉及的数据类型、数据收集和存储方式以及数据的利用。而数据的管理情况也在一定程度上影响着研究结果。对数据进行管理有助于研究人员在后续研究中进行更好地分析和利用,确保研究质量。如果数据管理得当,研究人员可以轻松查找信息,并有助于他们得到预期结果。
如今,随着高通量植物表型获取技术的开发和应用,大规模作物表型数据相伴而生,作物表型数据量也呈指数级增长。因此,这就需要研究人员在研究期间及获取数据后对表型数据进行妥善管理。需要对从各种表型平台中获得的大量原始表型数据进行分析,而拥有最优数据管理才能实现最佳应用,从而完成对数据的深度挖掘。针对与日俱增的作物表型数据,构建作物表型组学数据库便是一项有效的数据管理措施。
3.1 表型数据的标准化和存储
通过现有的高通量作物表型信息获取平台和技术,研究人员获得的表型数据量通常高达GB甚至PB,而且这些非结构化的“大数据”,通常包含大量复杂的图像、光谱和环境数据。因此,表型数据的有效存储、管理和检索成为目前研究人员需要考虑的重要问题[22]。
当前普遍接受的信息标准化原则包括3个方面:(1)最小信息(minimum information,MI),建议利用最小信息法来定义数据集的内容;(2)本体术语(ontology terms),采用本体术语作为数据的唯一和可重复性注释,有利于数据共享和荟萃分析;(3)数据格式(data format),选择适当的数据格式来构建数据集,如CSV,XML,RDF和MAGE-TAB等。
组织文件是数据存储的重要组成部分。在数据集中,跟踪文档及其版本至关重要,例如目录结构命名和文件命名约定。对于多站点项目,原始数据将上传并存储在文件服务器上。在通过脚本处理之后,输出文件存储在文件服务器上,研究人员可以从该文件服务器下载副本。从数据库数据标准化和存储的角度来看,基于“云技术”的存储方案正在成为植物表型数据存储发展的趋势。云存储系统可以优化作物表型平台系统架构、文件结构和高速缓存等设计。目前,各种表型数据采集平台仍然相对独立,尚未在地区、国家或大陆层面建立。通过人工智能的先进技术,建立基于多层表型信息的典型作物表型数据库,例如GDB人类基因组数据库,将引起相关研究人员的极大关注。
3.2 表型数据的科学管理
对于任何科学数据管理系统,都需要满足多项必要的要求[7]。
(1)数据存储和管理
数据密集型学科(如组学)中的研究活动通常会产生大量数据。有效获取、存储和管理大量数据的能力至关重要。
(2)数据背景化
需要拥有足够的上下文信息,以便更有效地组织、理解和挖掘原始数据。背景信息包括概念域模型(如研究活动如何组织和实施)和元数据(如出处信息)。
(3)数据安全
数据安全包括许多方面,如访问控制和存档。有效的数据管理系统需要通过使用身份验证和授权以及声音版本控制和备份解决方案来确保数据安全。
(4)数据识别和使用寿命
为了支持科学发现的传播,数据库中的数据需要在发布后可以公开访问,因而需要持久且唯一的命名方案。此外,有价值的科学数据也需要永久存储。
(5)数据重用和集成
上下文信息有助于理解原始数据。此外,还需要通过全文搜索、分面浏览和复杂查询应答等机制使数据可被发现,以允许集成和重用原始数据。
(6)模型可扩展性
数据管理系统可能需要管理各种各样的数据,这些数据可以由不同软件生成并由不同平台捕获。因此,表达和可扩展的域模型对于满足域概念的修改、添加和删除至关重要。此外,还需要设计数据管理系统,以便在发生此类模型更改时最大限度地减少服务中断。
3.3 表型数据库的构建规划
一个数据库的构建规划由许多元素组成,这些元素涵盖了描述、文档、过程和存档等多方面内容,因此表型数据库的构建规划中也必须具备以下几个方面。
(1)数据描述
数据的描述主要包括研究目的、数据及数据内容、数据来源、数据收集方式及形式、数据收集耗时及变化频率以及管理人员信息等。
(2)说明文档
说明文档涵盖的范围较广,主要有①创建的便于其他研究人员理解数据的文档;②元数据标准化、管理和存储方式;③文件格式及其标准;④文件命名、存储、安全和备份程序;⑤阅读或查看数据等需要的工具或软件。
(3)数据处理
诸如数据的访问、共享和重用等,都需要明确以下信息:①数据版权;②数据分享内容、时间和方式;③数据及其他信息的知识产权;④数据共享专利;⑤允许重用、再开发,或创建新工具、服务、数据集或产品等。
(4)存档
在数据的存档中,需规定:①数据归档方式;②数据存档期限及访问权限;③数据提交方式及要求;④数据保留时间等。
3.4 表型数据的共享和发布
生物技术和生物科学研究委员会(BBSRC)已实施数据共享政策。根据BBSRC要求,数据共享应包括以下细节:数据区域和数据类型,标准和元数据,与公共存储库中可用的其他数据的关系,二次使用—已完成数据集的进一步预期或可预见的研究用途、数据共享方法、专有数据、时限以及数据集最终格式[23]。
4 展望
作物表型组学是一个快速发展的领域,新的表型获取手段和研究方法不断出现,只会催生越来越庞大复杂的作物表型组数据。因此,构建综合性作物表型组标准数据库,或构建特定作物的表型组数据库,将成为该领域相关研究人员的工作重点。
在形式上,理想的作物表型组数据库应具备界面友好、图文并茂、操作简单和更新及时等特征,不仅要具有多维度、多生境表型信息的存储能力,还要便于用户检索和查阅,增强数据资源的信息共享,提高来之不易的作物表型数据的利用效率。在内容上,作物表型组数据库应涵盖从微观到宏观,从显微到器官再到个体乃至群体的多维度数据,应包含作物相关的生理生化和颜色纹理等多种信息。
农业信息化是现代农业的必然发展趋势,作物表型组数据库的构建也是顺应时代发展的产物。今后,应持续关注作物表型组研究领域内的数据库相关研究,充分利用各种综合和专用数据库,并在实际研究中着力构建自己的作物表型组数据库。
