车险订单数据汇总模块完善与优化
2019-01-23张舵程磊张之江
张舵, 程磊, 张之江
(上海大学 通信与信息工程学院,上海 200444)
0 引言
随着我国汽车保有量的增长以及近年来移动互联网热潮,互联网车险取得了长足的发展[1]。通过APP购买车险相比于传统业务模式具有更灵活、快捷的优势,相应的也需要开发配套的运营管理平台来完成车险规则与活动等信息的动态配置与业务数据的高效管理。
本文涉及到车险运营平台中订单数据汇总模块的功能完善与优化。该模块负责对每天的车险交易数据跟据承保合作方、出单地区以及出单时间分类汇总,并支持运营人员通过运营管理平台网站查询报表。该模块原有方案为“T+1”全表统计,且随着数据量的增长该汇总方案的执行效率明显下降。本文将对该模块进行完善,使其支持运营人员实时查询汇总数据且通过数据库优化提升该功能执行效率,同时避免影响日常下单功能的数据写入性能。
1 主要技术方案
1.1 MySQL主从复制原理
MySQL是基于主库的二进制日志文件内容实现了主从复制功能。用户对主数据库的创建、修改、删除等操作以及对表的增、删、改、查操作都会记录到二进制日志文件中,从数据库通过I/O线程来连接主服务器,通过主服务器创建的新线程获取二进制日志的内容并拷贝到它的中继日志当中,之后利用SQL线程从中继日志读取事件,并重放其中的事件而更新到从数据库当中,使其与主数据库中的数据保持一致[2]。
1.2 Spring框架
Spring框架是一个由 7个定义良好的模块组成的分层架构。这些Spring模块构建在核心容器定义了创建、配置和管理bean的方式的核心容器之上。Spring框架的两大特性是“控制反转”和“面向切面”[3]。应用了“控制反转”,一个对象就不需要自己创建或者查找依赖对象,其依赖对象会通过被动的方式传递进来。这样降低了对象之间的耦合,这个特性在web框架、数据库框架以及通过分布式框架远程调用服务时都会用到,使得项目中各组件在开发时互相解耦合,但不影响各组件在运行时的互相调用。
1.3 Dubbo框架
Dubbo是阿里巴巴提供的、基于Java的Http Client请求、高性能的开源RPC远程服务调用方案,通过Dubbo可以把业务逻辑分离出来,作为一个独立的模块,使得前端应用能快速和稳定地响应请求。使用Dubbo架构可以支撑高并发的项目,且低耦合,扩展性、稳定性都很强[4]。
Dubbo中注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费在启动时与注册中心交互。服务提供者向注册中心注册其提供的服务,服务消费者向注册中心获取服务提供者地址列表,并根据负载算法直接调用提供者。在项目中,我们选择采用ZooKeeper来作为Dubbo的注册中心[5]。
2 系统设计与实现
原有的订单数据汇总功能通过在每天凌晨执行定时任务,对已配置的合作方与业务开展地区的订单数据进行汇总,并将汇总结果保存在汇总数据表中。该方案需要反复读取数据,对数据库IO占用较高,且在统计当年、当月以及累计数据时需要查询全表数据,因此查询效率较低耗时较长,不能满足运营人员即时查询的需求,而且在工作时间执行该汇总方案会影响车险购买流程的数据写入性能。
2.1 主从数据库与Dubbo微服务配置
出单即时汇总模块在设计上需要解决以下两点问题:
1) 即时查询的请求多发起于工作时间,此时出单业务繁忙,会影响到下单速度。
2) 由于订单数据表数据量过大,进行全表查询会导致数据表暂时锁死或低速响应。
为了避免查询时下单业务卡死,可以采用数据库读写分离。订单数据汇总操作连接到从数据库执行,并将用户权限设置为只读。主数据库设置如下:
Server-id=1 #这是数据库ID,此ID是唯一的,主库默认为1
log-bin=wysq1-bin #二进制日志文件,此项为必填项,否则不能同步数据
binlog-do-db=bussiness #需要同步的数据库,如果需要同步多个数据库
binlog-ignore-db=account #不需要同步的数据库
从数据库设置如下:
Server-id=2 #这里ID改为2 因为主库为1;
log-bin=mysq1-bin #必填项,用于数据同步;
master-host=123.56.XXX.XXX #主库IP;
master-user=slave #同步用的账户
master-password=password #同步账户密码;
master-port=3306 #同步数据库的端口号。
对应主从数据库,需要配套负责订单数据写入的生产者以及负责订单数据读取的生产者,两个生产者分别负责对主数据库与从数据库的操作,供消费者调用不同服务。对应的Dubbo生产者配置如下:
〈!--dubbo配置--〉
〈dubbo: application name="wallet-provider" owner="it" organization="capli"/〉
〈dubbo: registry address="${dubbo.register)"/〉
〈dubbo: protocol name="dubbo" host="${dubbo.host}" port="${dubbo.port}"〉〈/dubbo: protocol〉
〈dubbo: annotation package=""/〉
消费者配置如下:
〈!--账户注册包--〉
〈dubbo: reference interface="com.mobisoft.wallet.api.OrdreWriteApi" id="OrderWriteApi" version="1.0.0" timeout="100000"〉〈/dubbo: reference〉
〈dubbo: reference interface="com.mobisoft.wallet.api.OrdreReadApi"〉 id="OrderReadApi" version="1.0.0" timeout="100000"〉〈/dubbo: reference〉
〈!--提供方应用信息,用于计算依赖关系--〉
〈dubbo: application name="wallet_web" owner="baobei_it" organization="baobei"〉
〈!--使用zookeeper注册中心暴露服务地址--〉
〈dubbo: registry address="${dubbo.register} timeout="100000"/〉
〈dubbo: annotation package="com.mobisoft.wallet"/〉
2.2 即时汇总运行效率优化
即时统计有两种思路:
1) 数据库总体情况统计,即执行即时统计功能时对于全表数据进行统计,这种方式逻辑简单、统计结果全面但存在执行时间随着数据增长而变长的情况。
2) 数据库增量数据统计,即记录每次更新数据的时间点和结果,新一次查询时只需统计两次查询之间的增量数据即可。这种方式的查询量减小了几个数量级,不过只能依据已配置的合作方与地区进行统计,对于新增合作方与地区维度的支持不佳。
由于在生产中存在统计维度变更的情况,所以我综合两种思路的优劣,采用了对新增维度进行全表查询,对已有统计数据的维度做增量查询的方式,方案流程图如图1所示。
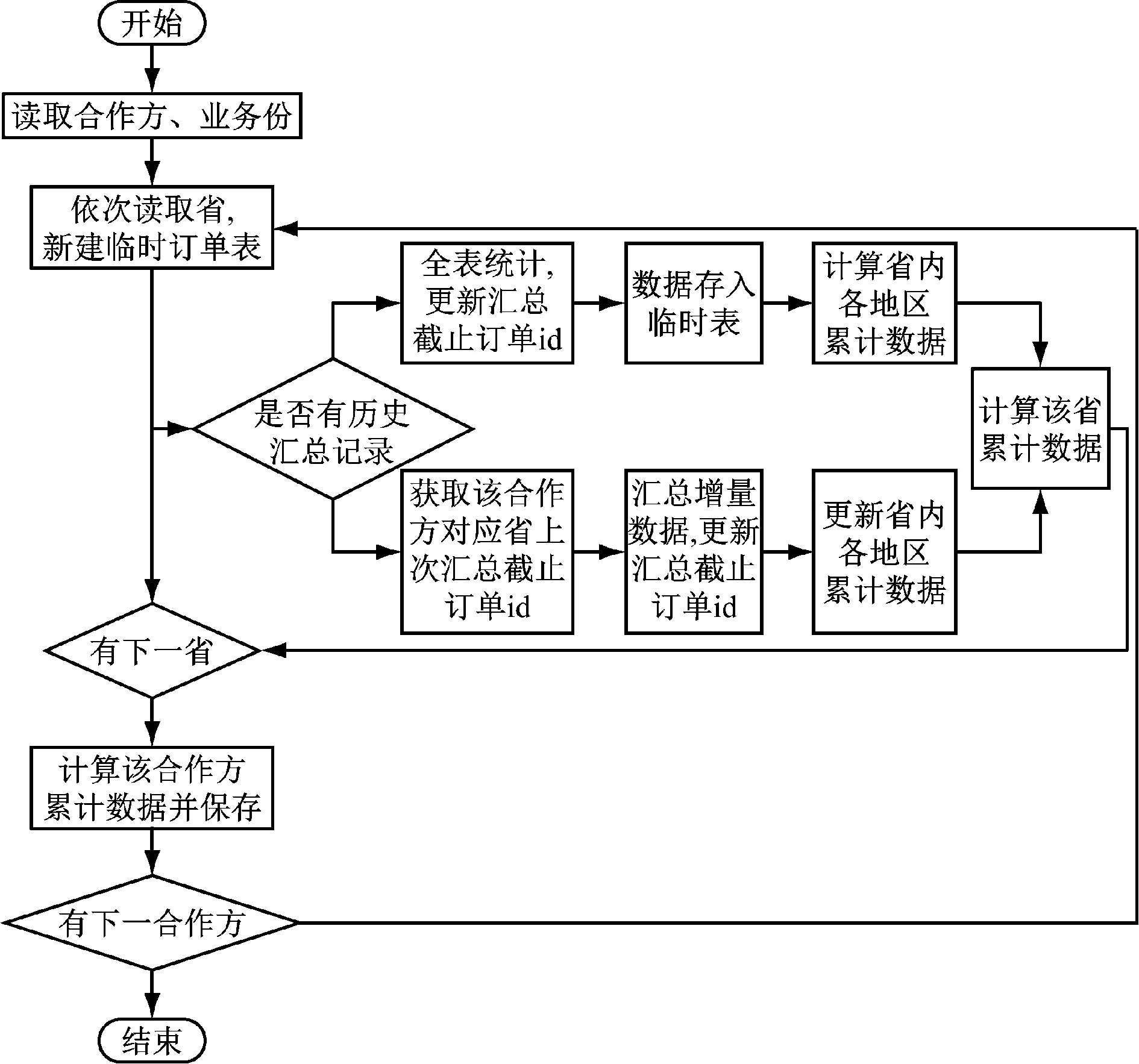
图1 方案流程
为了提高汇总执行速度并实现代码逻辑与业务数据的分离,主要汇总逻辑选择在存储过程中实现。采用存储过程有以下几点优点[6]:
1) 提高性能:普通SQL语句会在创建过程时进行分析和编译。而存储过程则会在首次运行一个存储过程时预编译,查询优化器对其进行分析、优化,并将得到的最终存储计划保存在系统表中,这样,在执行过程时便可节省此开销。
2) 降低网络开销:只需要提供存储过程名和必要的参数信息就可以完成调用,从而降低了网络的流量。
由于出单统计涉及到大量数据表的读写,采用存储过程可以将这些操作在数据库内完成,减少了对数据库IO的占用。
为了支持增量数据汇总功能,我在汇总数据表中增加了上次统计ID字段,并将数据做了垂直拆分以减少数据呈现时的冗余数据[7],修改后的订单统计报表结构如图2所示。
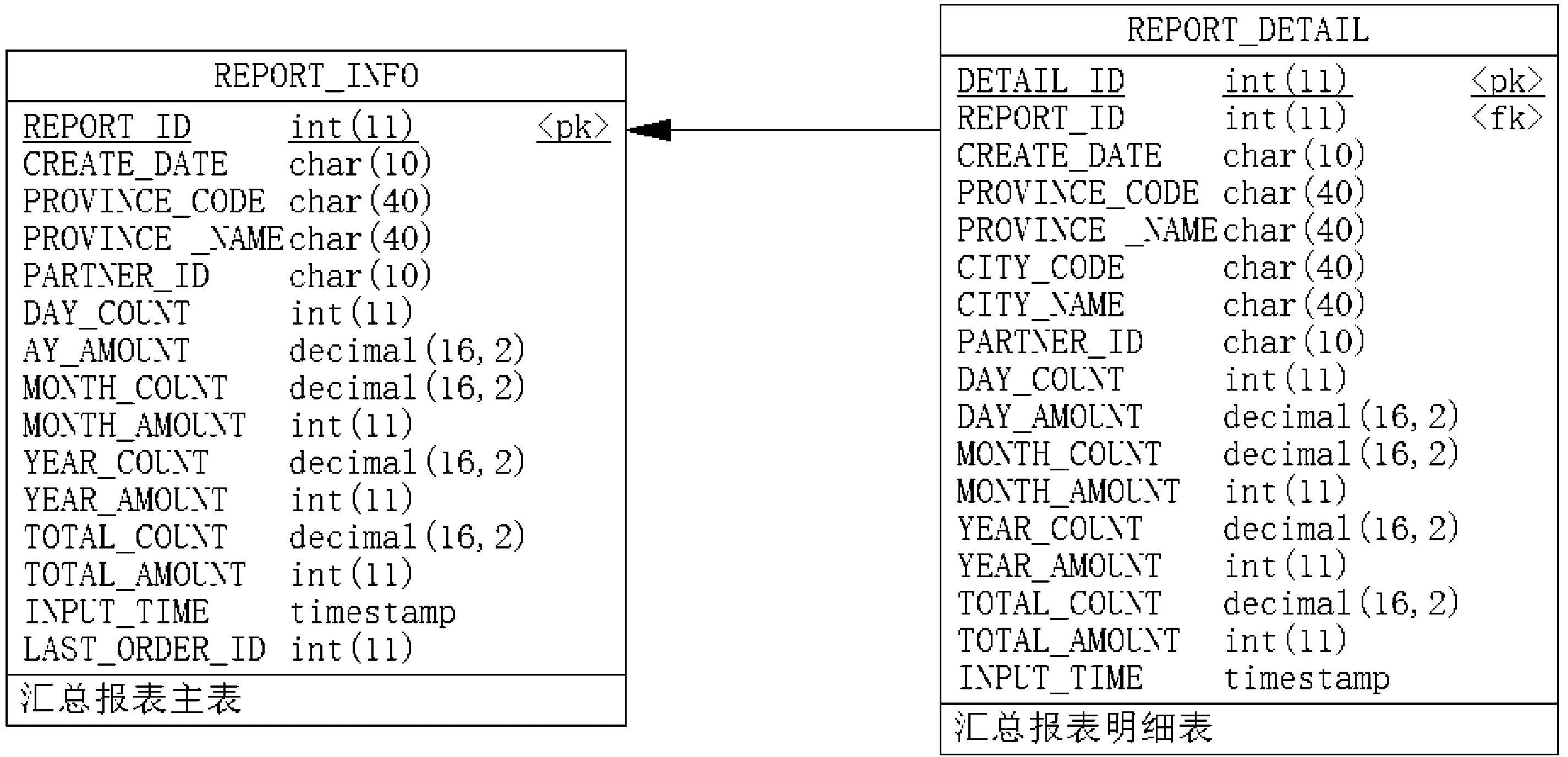
图2
垂直拆分之后,主表用来保存省级汇总信息,明细表用于保存次级地区汇总信息。这样在页面展现省级数据时减少冗余数据对带宽的占用,并能有效提高查询次级地区汇总信息时的速度。
3.2 系统测试
跟据系统需求以及设计方案,我们设计了测试用例对出单数据即时统计的功能进行了测试,并记录了系统相关运行参数。具体数据如表1所示。
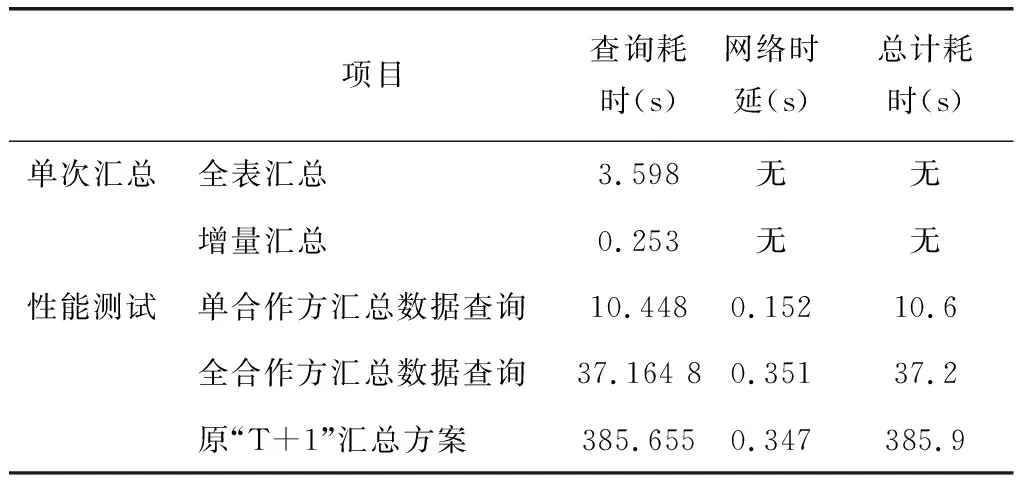
表1 系统相关运行参数
从测试数据可以看到,增量汇总方案单个地区汇总耗时仅为全表汇总的1/14,且在实际操作中,执行全合作方查询操作用时也仅为原汇总方案的1/10。并且由于功能调整后单合作方查询时仅需汇总对应合作方数据,所以单合作方数据汇总耗时减少到了10.6秒,大幅提升了用户使用体验。
3 总结
本文跟据订单数据即时汇总需求完善了其汇总数据与分类呈现功能,并通过数据库读写分离、分别设置读写功能的Dubbo微服务、利用存储函数减少数据库IO性能压力以及对有历史记录的统计信息进行增量统计的方式来对订单数据汇总模块性能进行优化。系统测试显示,这些优化措施使得系统运行速度提升的同时也很好地改善了运营人员的使用体验。
