分布式高铁动车组PHM大数据架构设计与实现
2019-01-23姜喜民刘光俊
赵 珂,王 伟,姜喜民,刘光俊
分布式高铁动车组PHM大数据架构设计与实现
赵 珂1,王 伟2,姜喜民2,刘光俊2
(1. 昆明理工大学 城市学院,云南 昆明 650051;2. 中车青岛四方机车车辆股份有限公司,山东 青岛 266111)
在高铁动车组的故障预测与健康管理系统设计中,采用传统数据库或单一的大数据平台难以达到系统精确预测故障的业务功能设计的准确度要求,PHM大数据架构设计需综合考虑海量数据的膨胀、数据协议的复杂度、在线机理模型的变化以及机器学习的训练等因素。本文基于多组件的大数据生态技术分层架构体系进行设计与实现,详细阐述了高铁动车组的故障预测与健康管理大数据平台架构设计的方法和实现过程。
大数据架构;轨迹回放;流计算;负载均衡;实体主机
0 引言
在高铁动车组的车载故障预测与健康管理系统(Prognostic and Health Management,PHM)中难以实时实现多工况机理模型关联对比分析、长时序分析、多平台数据融合分析。因此路局服务站和主机厂检修维护只能采用线下PHM大数据平台实现高铁动车组的实时监控与在线决策的方法来实时掌控运营中的高铁动车组状态和故障情况。PHM大数据平台使用移动通信网络或互联网实时与非实时两种方式采集车地数据传输系统/高铁检修服务系统/数据离线采集系统/线路资源系统等多系统平台的数据进行智能诊断和信息分析[1]。只有综合利用车载数据、地面监控数据才能构建更为高效的高铁动车组的地面PHM系统。
本文基于分布式大数据平台架构设计满足实时监控、在线规则引擎配置与计算、离线分析和数据挖掘,构建各业务部门各种业务机理模型和分析平台。
1 技术选型
技术选型需综合考虑项目实施工期、工程师大数据技能、业务应用要求、计算效率、安全性、高可用、Nosql、结构化与非结构化、可扩展算法等,并满足PHM监控、流计算、海量数据聚合计算、长时序查询、在线挖掘、在线规则引擎与离线分析挖掘,而使用关系型数据库(Relational Database Management System,RMDBS)或大规模并行处理数据库(Massively Parallel Processor,MPP)都很难满足应用多样性要求。因此只能采用分布式计算与分布式存储的大数据架构才能满足业务要求。
1.1 大数据平台选型
业务数据来源主要从动车组车载信息无线传输系统(Wireless Transmission System ,WTD)的二进制通信数据包,图纸数据文件,办公文件,高铁检修系统(Maintenance, Repair & Operations,MRO),生产制造质量系统(Quality Management System,QMS),生产制造工艺管理系统(Manufacturing Execution System,MES),企业采购系统(Enterprise Resource Planning,ERP)等业务系统的业务数据。采用传统RMDBS数据库是无法实现高铁动车组PHM大数据平台的业务要求。因此PHM大数据平台需具备很强的升级能力和扩展性。
表1对比各种大数据平台的升级能力和社区活跃度,并结合PHM业务要求机理模型多、平台升级快、扩展性强的特点,因此选择hdp版本作为分布式存储与分布式计算的基础大数据平台。
表1 主流大数据平台关键点对比表

Tab.1 Key point comparison table of mainstream big data platform
1.2 流计算引擎选型
从apache社区可选择Storm、Samza和spark- streaming等流计算引擎。Samza使用一个嵌入的key-value存储;storm可使用类sql进行流式数据操作,而这两种引擎对二进制解析、图操作和机器学习等业务就比较困难。但spark-streaming不仅能实现二进制解析、图操作和机器学习,并能结合SQL,Mllib,GraphX实现机理模型和在线挖掘。
同时从工程师擅长java/scala/python/R等多种编程语言的角度出发,结合高铁动车组的流式二进制解析、结构化数据、文本、图式json等格式消息,而且业务处理效率允许3秒延迟,因此综合考虑流技术引擎选择spark-streaming。
1.3 大数据低延迟高并发数据读取
高铁动车组的传感器和逻辑开关每天产生大于40亿条逻辑值和模拟量数据。检修运维人员需结合历史数据对比分析高铁动车组的实时状态和故障情况。根据系统一次写入多次读取的使用特点,选择基于hdfs分布式存储的KV数据库引擎hbase,作为低延迟高并发的数据存储数据库[2]。
2 关键技术
根据高铁动车组的业务模型和应用要求,PHM大数据平台关键技术分为流式二进制解析、分布式计算资源负载均衡、在线规则引擎、集群资源虚拟化、数据链路可视化、海量数据聚合计算和大数据平台调优。
2.1 流式二进制数据解析
上千列高铁每秒产生4 MB以上的二进制消息,解析后达到40 MB/s以上。使用spark-streaming进行二进制解析、规则映射、数学计算、数据过滤、数据分拣、数据关联、时序计算和聚合计算等过程,在不重启流计算引擎的情况下,可满足机理模型热部署和消息流分层的复杂性要求,也能满足海量数据聚合计算效率。
2.2 分布式计算资源负载均衡
高铁动车组PHM大数据平台业务访问并发数大和计算复杂,需计算资源的CPU核数(线程数)与内存分配比较合理,按照平台资源划分为后台任务并行队列资源负载均衡与前端web访问负载均衡,如图1所示。
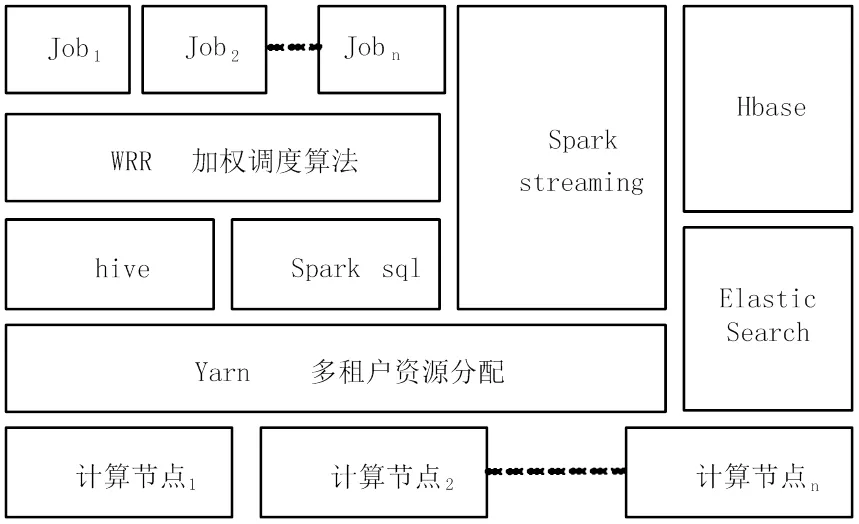
图1 并行队列资源负载均衡图
图1中后台任务并行队列主要使用yarn的多租户计算资源管理方法进行分配,划分为spark streaming计算资源,hbase计算资源,hive计算资源,ES计算资源,后台业务程序计算资源。后台业务程序计算主要依赖yarn进行分配和调度,但由于存在本地单节点计算,因此在单一租户的情况下,采用加权轮询调度算法(Weighted Round Robin,WRR)进行任务负载均衡动态申请集群计算资源,可以实现不同节点的计算资源空闲情况进行加权负载均衡。
由于PHM大数据平台前端web访问量不是海量访问,因此负载均衡使用nginx的默认轮询算法就能保障平台的稳定性。
2.3 在线规则引擎
本系统在线挖掘业务要求数据流程可配置、算法可热拔插、支持数学计算算法(含机器学习算法)、规则托拉拽配置。保证单条数据机理模型监控算法计算,并能实现分钟级别的窗口数据聚合计算,因此后台规则引擎采用apache camel实现数学计算公式,集成spark-mlib算法库,数据流程采用streamsets进行配置管理,定制开发能托拉拽的在线规则引擎。
2.4 集群资源虚拟化
集群计算资源虚拟化是利用闲置资源和保障平台稳定性的技术基础,使用Docker实现元数据库封装、功能组模封装、数据挖掘训练资源封装,可保障大数据集群资源在磁盘I/O、通信网络、CPU内核线程数和内存合理的分配。
2.5 数据链路监控
传统离线数据采集技术实现数据链路监控比较容易,但若基于大数据流式实时计算时会经常出现多种原因的数据丢失。因此需采用kafka的消息缓存机制,每天定时进行数据链路比对,自动触发从kafka提取二进制消息数据进行处理和计算,并将每个流计算环节的日志写入hbase日志中。部署数据链路展示前端功能进行实时监控,发生问题及时通过短信提醒运维人员并进行人工干预分析。
2.6 大数据平台调优
大数据平台调优划分操作系统、集群资源、任务队列和功能代码四个方向。操作系统调优包含网络通信、防火墙策略、文件权限、文件夹目录、I/O读写规划、CPU规划、内存规划和系统补丁与关联内核调整等。集群资源调优主要采用多租户的计算资源分配、平台软件参数调整、吞吐量优化等。任务队列调优采用将24小时按照分钟级时间片段、作业优先级、依赖关系等进行执行计划编排,防止单租户在同一时间的集群资源利用率达到90%以上。功能代码调优采用测试环境论证资源开销情况,并进行代码级检查分析程序异常和执行效率。
3 分布式高铁PHM大数据架构设计
分布式高铁PHM大数据架构设计既要满足实时流式计算、长时序聚合计算、在线规则引擎挖掘、离线分析计算,也要满足历史数据过滤搜索,同时要求保障大数据平台在规定的年限内不做存储和计算资源扩容。其平台架构分层设计如图2所示。
3.1 数据层
数据来源采用sqoop、flume、企业服务总线(Enterprise Service Bus,ESB)等组件配置采集,使用统一标准的数据采集校验接口机制。同时将业务数据划分为实时流式数据处理,在线规则引擎分析,离线数据统计分析。系统中流式数据划分两层:
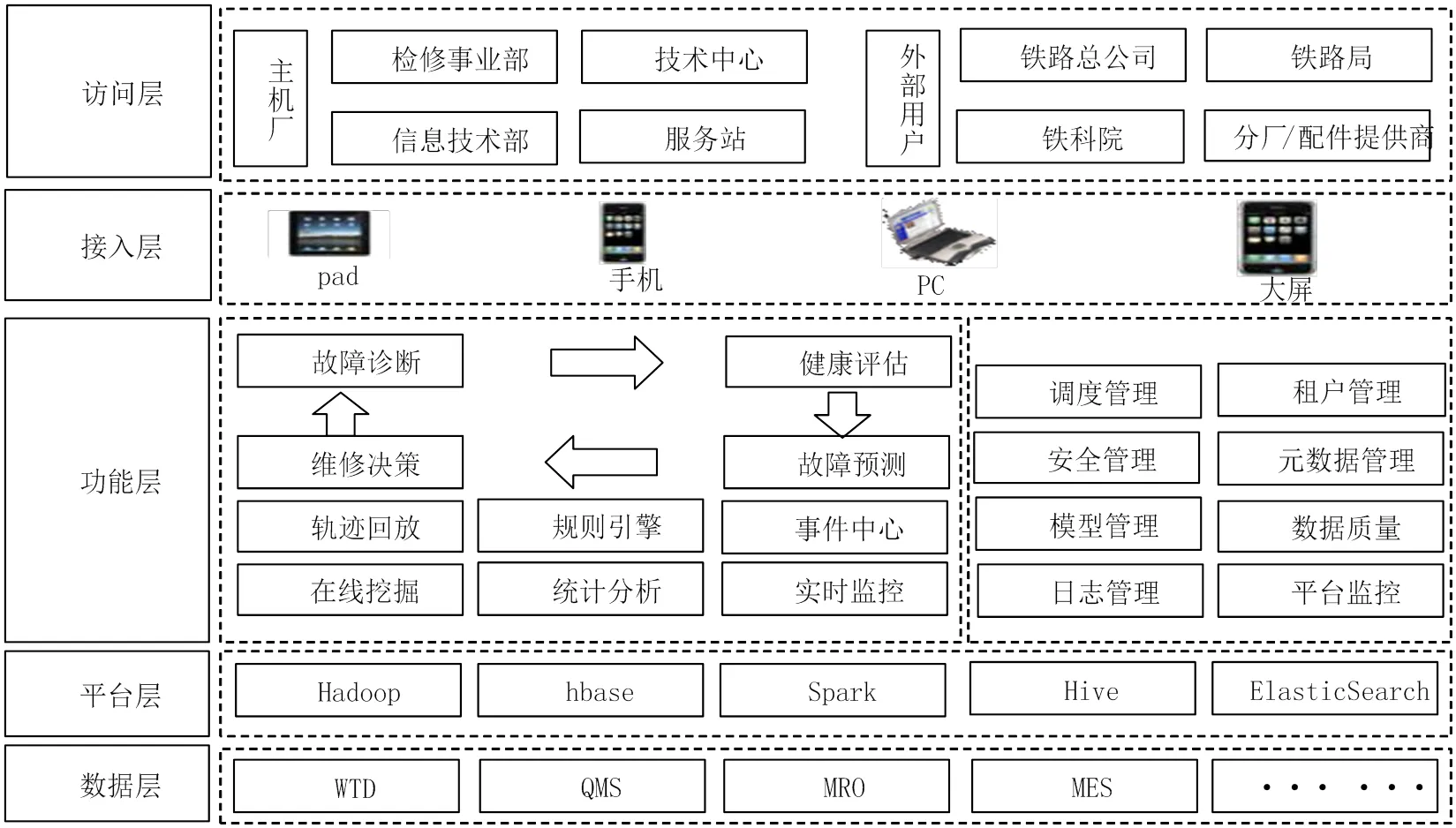
图2 分布式高铁PHM大数据系统架构
第一层:非结构化基础流式标签和窗口数据标签模型,主要进行二进制数据转换、拆分、分拣等基础传感器逻辑值和模拟量。同时为复合型的需要时间窗口进行逻辑值的平均值、最值计算、累计值、连续性等基础标签。
第二层:业务主题结构化模型需将非结构化语言表述数据转换成结构化主题模型,PHM采用流式计算与在线规则引擎以降低数据挖掘难度。
数据链路主要按照实时流式计算主要采用spark- streaming封装数据模型。运用kafka存储流式数据, 通过ETL工具和开源组件将数据输出到hbase、hive和Elasticsearch中。
3.2 平台层
高铁动车组的机理模型训练和监控算法阀值多次迭代训练都需要很多平台资源,因此采用多租户资源管理、作业计划编排与资源权重监控工具实时监控平台运行的工作运行效率和资源开销。
3.3 功能层
关键业务功能需在海量数据里面提取部分数据进行轨迹回放仿真演示[3],业务人员等待5秒之内,提取7天传感器状态和故障数据,并通过GIS地图参数进行回放的方法可解决实时监控无法做仿真分析的技术难点。其列车轨迹回放仿真功能见 图3。

图3 列车轨迹回放仿真功能图
通过图3的列车轴温与直流电压、三次侧电压的状态轨迹回放仿真功能图,业务人员能过滤故障发生时的相关机理传感器数值进行模拟仿真,可辅助检修人员对故障发生时间段进行相关机理分析。
4 分布式高铁PHM大数据系统实践
PHM系统前期采用分布式的虚拟机环境,发现共享I/O会导致网络通信异常问题,同时发现CPU和内存性能指标不稳定。因此后期采用X86物理机在私有云大数据平台的硬件性能得到保障后,PHM系统稳定性大大提高,不会出现重启大数据平台情况,系统满足实时机理模型、在线规则引擎挖掘和离线数据分析的业务要求。系统实施过程中对大数据组件产品和应用功能进行测试论证时需部署测试环境集群和PHM大数据生产平台两个集群,网络拓扑如图4所示。
图4所示,测试环境采用docker虚拟10台主机部署hadoop。生产环境部署了14台计算/数据节点,2台管理节点,2台前置互联网接口机,3台kafka消息集群,3台元数据服务器,3台web服务器。
分布式大数据平台上部署hadoop/hbase/hive/ spark/Elasticsearch等大数据组件产品,实测3T大小的高铁状态和故障数据性能指标见表2。
表2对比可见分布式高铁动车组PHM大数据平台若采用单机版或虚拟机集群系统稳定性得不到保障,同时效率和并发数都不能满足业务要求,只有采用实体机集群能满足业务部门的效率要求。服务检修部门和工程中心在PHM上部署60多个机理模型,为保障计算资源的合理分配,PHM大数据平台使用多租户分配资源,以能充分保障平台的稳定性和较高的并发计算效率。

图4 高铁动车组PHM大数据平台网络拓扑图
表2 单机版/虚拟机集群/实体机集群性能对比表
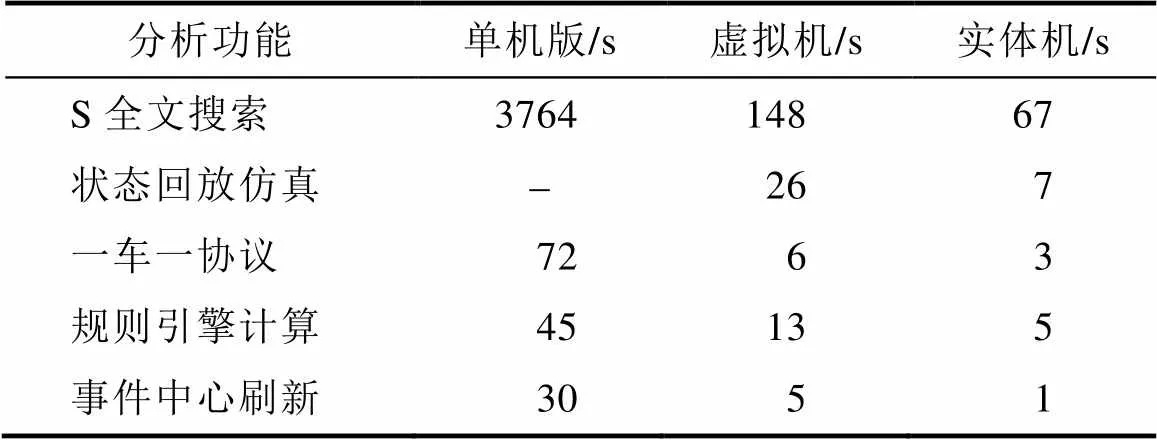
Tab.2 Single machine / virtual machine cluster/entity cluster performance comparison table
5 结论
本方案采用大数据生态技术分层架构体系的方法,运用成熟稳定的开源hadoop大数据平台,实现了高铁动车组PHM系统的业务功能扩展要求,满足了业务上要求的流式计算、在线规则引擎数据挖掘和离线机理模型训练。在不影响业务数据分析与挖掘的运算效率的情况下,能进行核心部件多工况机理模型的长时序数据挖掘和离线机理模型训练。业务数据大小从每天0.6TB以上膨胀到1.3TB的情况,并且在不断扩展机理模型的情况下也不影响业务应用性能。
[1] 田歆, 汪寿阳, 鄂尔江等. 零售大数据与商业智能系统的设计、实现与应用[J]. 系统工程理论与实践, 2017, 37(5): 1282-1293.
[2] 葛磊蛟, 王守相, 瞿海妮等. 智能配用电大数据存储架构设计[J]. 电力自动化设备, 2016, 36(6): 194-202.
[3] 黄聪. 基于大数据分析的城轨列车运行路线追踪研究[J]. 现代电子技术, 2018, 41(5): 110-115.
[4] 罗伟雄, 时东晓, 刘岚等. 数据虚拟化平台的设计与实现[J]. 计算机应用, 2017(37): 225-228.
[5] 王逸飞, 张行, 何迪等. 基于大数据平台的电网防灾调度系统功能设计与系统架构[J]. 电网技术, 2016, 40(10): 3213- 3219.
[6] 赵征凡, 刘睛波, 黄萌等. 某型火炮预测与健康管理技术(PHM)体系结构设计与应用[J]. 计算机测量与控制, 2017, 25(12): 114-116.
[7] 李勇, 常天庆, 白帆等. 面向服务的装甲装备PHM体系结构研究[J]. 计算机测量与控制, 2012, 20(7): 1880-1903.
[8] 陈惠娟, 加云岗. 大数据时代下的信贷风险预警系统研究[J]. 软件, 2018, 39(1): 39-44.
Design and Implementation of PHM Big Data Architecture for Distributed High-speed Rail EMU
ZHAO Ke1, WANG Wei2, JIANG Xi-min2, LIU Guang-jun2
(1. City College, Kunming University of Science and Technology, Kunming 650051, China; 2. China Railway Rolling Stock Corporation Qingdao Sifang Co. LTD, Qingdao 266111, China)
In the fault prediction of high-speed EMU and health management system design, the accuracy requirements of business function design using big data platform for traditional database or single system is difficult to achieve the accurate prediction of the fault, the design of PHM large data structure should be considered in massive data expansion, data protocol complexity, online mechanism model Type changes and machine learning training and other factors. In this paper, the hierarchical architecture system of big data components of ecological technology based on the design and implementation, and describes the methods for fault prediction of high-speed EMU and health management of big data platform architecture design and implementation process.
Big data architecture; Track replay; Stream computing; Load balancing; Entity host
TP391
A
10.3969/j.issn.1003-6970.2018.12.021
赵珂(1978-),女,硕士,讲师,主要研究方向:信号与信息处理、大数据挖掘;王伟(1991-),男,研究生,信息技术工程师,主要研究方向:大数据挖掘;姜喜民(1979-),男,本科,大数据主管,主要研究方向:信息化规划、大数据架构;刘光俊(1993-),男,本科,助理工程师,主要研究方向:数据统计分析,大数据挖掘。
赵珂,王伟,姜喜民,等. 分布式高铁动车组PHM大数据架构设计与实现[J]. 软件,2018,39(12):90-94
