基于分布式并行计算的大数据自助分析系统的研究与应用
2019-01-23翁业林蒋道霞俞新华
翁业林,蒋道霞,俞新华
基于分布式并行计算的大数据自助分析系统的研究与应用
翁业林1,蒋道霞1,俞新华2
(1. 江苏财经职业技术学院,江苏 淮安 223001;2. 江苏省移动公司,江苏 南京 210001)
大数据一旦进入更多的企业,我们就会对大数据提出更多期望,除了数据统计,大数据时代还需要智能化分析,打破IT的约束,需要探索最高效的方式,快速抢占数据制高点。本文通过对某公司的分布式并行计算下数据自助分析平台中的应用方案进行研究与应用,提出在自助分析系统中对海量数据处理的思路,对分布式并行计算和分布式通信进行了重点分析,同时结合自助分析系统的功能特点,给出系统部署的应用建议。研究内容对于分布式计算在大数据决策分析系统的落地具有一定的实用价值。
分布式并行计算;大数据;自助分析
0 引言
进入4G时代以来,用户信息从基本的语音、话费、基础行扩展到偏好、消费预测等信息[1]。随着新的数据的接入和整合,数据规模不断扩大,分析维度从10、50,涨到百,甚至千;数据广度也在不断增加[2]。所以需要搭建全新的数据处理平台及自助分析系统帮助企业处理海量的数据、进行复杂的数据结构分析、实现精细化业务需求以及平台能力开放、共享等,提高数据挖掘的价值,为企业经营提供决策、营销、服务建议的支撑工作[3]。
1 大数据和分布式并行计算
1.1 大数据
引用IDC基于信息基础设备推进研究会中对大数据的描述,就是具备大量数据体、数据类型繁多、数据处理快以及数据的价值密度偏低等四方面特征的数据集合。大数据技术是以数据为本质的新一代革命性的信息技术,在数据挖潜过程中,能够带动理念、模式、技术及应用实践的创新。大数据优势:存取能力,具备强大的分布式存取能力;降低成本,利用科学的算法,深入挖掘数据价值可提升营销的精准度,增加业务收入和降低运营、运维成本。运算性能,具备海量的数据处理能力,具有流式计算、准实时分析计算、离线分析计算三种强大的计算能力。扩展能力,具备集群易扩展性、易维护的能力,并提供可视化的操作界面。指导运营,优化流程提高经营效率的同时,量化企业运营的指标,用更科学的方法指导企业的经营。降低成本,利用科学的算法,深入挖掘数据价值可提升营销的精准度,增加业务收入和降低运营、运维成本。通过大数据实时分析,可获取营销商机,触发营销;通过大数据分析识别信用指数,避免金融欺诈。
1.2 分布式并行计算
并行计算(Parallel Computing,也称平行计算,)是指让多条指令同时进行一种计算模式,分为时间并行和空间并行两种。时间并行主要是利用多条流水线同时作业;空间并行则是指使用多个处理器执行并发计算,以降低解决复杂问题所需要的时间。并行计算一般在解决计算问题的过程中同时使用多种计算资源执行并行计算,计算资源可能包括一台配有多处理机(并行处理)的计算机或一个与网络相连的计算机集群,或者两者结合使用。
分布式计算是与集中式计算相对应的概念。分布式计算是将一个需要巨大的计算能力才能解决的问题分成许多小的部分,然后把这些分成的小部分计算分配给许多计算节点进行处理,最后把这些计算结果综合起来得到最终的结果。分布式计算是在两个或多个软件互相共享信息,这些软件既可以在同一台计算机上运行,也可以在通过网络连接起来的多台计算机上运行。
本文的分布式并行计算基于MPP架构的智能化平台,如图1所示。该平台能够把计算分布到多个计算节点,再在指定节点将计算结果汇总输出。机器角色主要有Naming Node、 Client Node、Map Node、Reduce Node。Naming Node:负责命名工作。它知道当前有多少台Map Node和Reduce Node,及这些Server的配置状况。Map Node和Reduce Node会定期发送各自配置情况,workload(工作量),CPU,内存等信息。Naming Node通常是一台机器,但可以做冷备份。Map Node:负责处理Map Task。原始数据和Map Task的代码文件集被预先部署到MapNode上。当它接收到Client Node发送的Map Task,可以直接执行该任务。Map Node可以有多台机器。Reduce Node:负责处理Reduce Task。它被预先部署了Reduce Task的代码文件集,可以直接执行该任务。Reduce Node可以有多台机器,而且可以指定某台干固定的任务。大量的细节数据在压缩后,以文件的形式被分布式存储在集群的硬盘中。当计算时,会把被打中的数据拉入到内存中,也就是热点数据会常驻内存。当发生数据失效时,会将新数据交换到内存中参与计算。内存计算是对传统数据处理方式的一种加速,是实现大数据分析的关键应用技术。
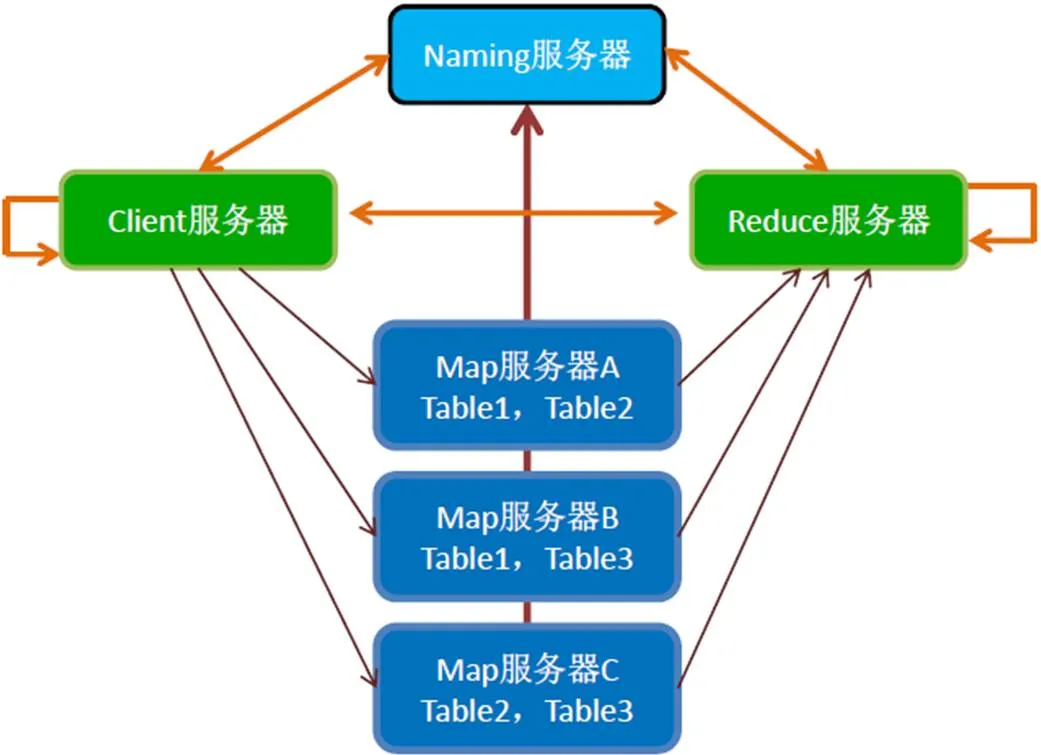
图1 MPP架构的智能化平台
2 分布式自助分析系统的规划与设计
企业的数据复杂性越来越复杂。需要整合各种数据;企业对数据分析的方法要求越来越高。需要进行数据二次关联加工,提升可视化效果;企业对数据分析实效性的要求越来越高,用于决策的时间越来越短。需要提高分析效率,把握营销时机;企业数据分析的人力成本越来越高。需要降低人力成本,实现业务人员自助分析;硬件的成本越来越低。需要基于廉价的X86服务器,构建分布式自助分析系统。因此,大数据时代也需要智能化分析,打破IT的约束,需要探索最高效的方式对数据二次分析、挖掘,快速抢占数据制高点。基于分布式并行计算的大数据自助分析系统架构如图2所示。
2.1 数据抽取
自助分析支持从多种类型的数据库中抽取数据,将数据按照主题建立成多个集市导入到MPP集群中。如果采用Hive方式访问数据,可以采取ODBC/JDBC的方式直接建立连接读取数据。如果采用HBase方式访问数据,可以定制一个Customized Query来读取数据。如果是直接访问HDFS文件来导出数据,可以定制一个Customized Query来读取数据。ETL过程中可以做数据清洗,格式转换,还可以跟其他库的维度表进行关联,形成宽表入库。入库时还能根据时间或者区域来给数据打上粗粒度标签,便于以后做数据优化调整使用。历史数据集中导入,增量数据自动导入,增量更新的时间粒度根据系统对实效性的要求,可以是每分钟,每小时,每天。ETL的客户端可以是多节点同时导入集市,以此来提高导入效率。
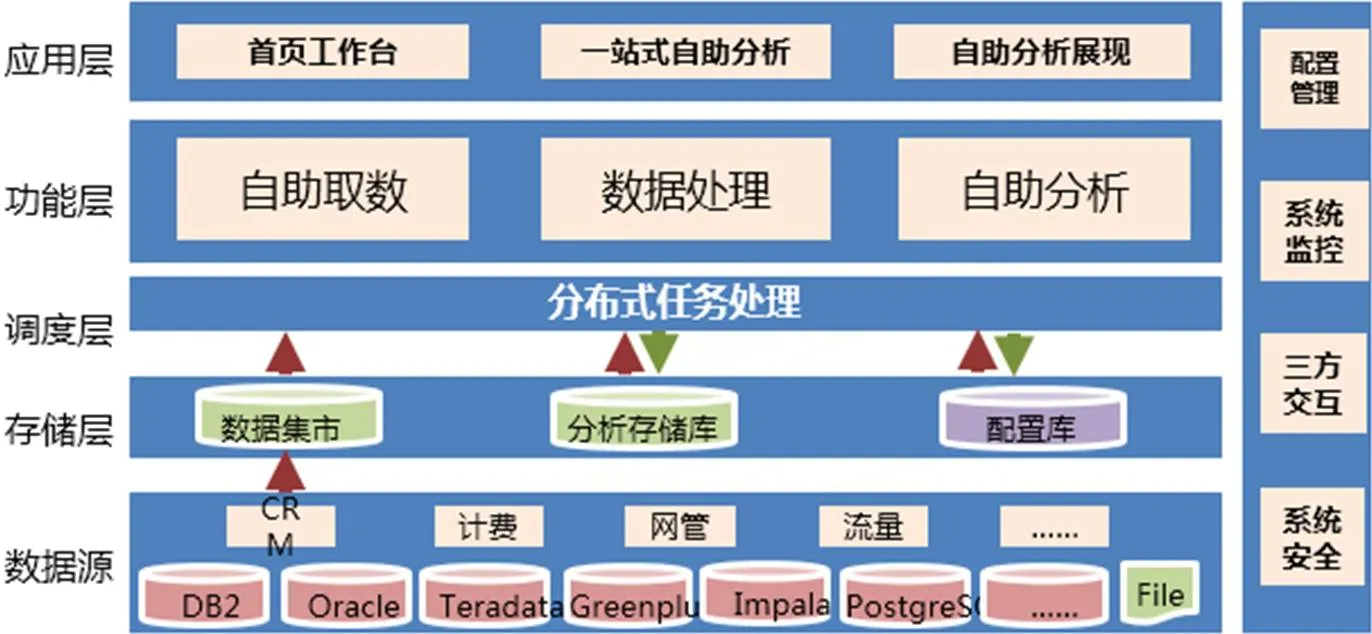
图2 基于分布式并行计算的大数据自助分析系统架构
2.2 数据存储
为方便整个架构的横向扩展,以线性地横向扩展而没有性能影响,保证性能和容量的灵活伸缩,解决大数据量的存储问题。硬件高可用,通过软件设计、硬件故障作为一个常态而非特例来解决。“不共享”架构,分布式机器节点之间相互独立,分布式数据中心与分布式数据集市之间相互独立,避免资源争用。保证架构在应对实时计算、离线计算和流式计算等不同的计算需求时,高效稳定的运行。探索式自服务分析,针对未知和灵活多变的业务需求,可以实现自主数据服务和分析服务。
2.3 数据功能
傻瓜式取数配置:简单的取数操作界面,为业务人员提供傻瓜式的自助取数能力。提供关联筛选,上传文件条件筛选,数据集交差并、左关联、全关联处理,帮助用户快速整合数据。灵活的数据计算:取数过程中支持多种指标计算功能,帮助用户灵活获取数据;通过自助分析平台,可在自助提取数据后,进行数据的分析及汇总分析。
2.4 数据应用
应用层的客户端可以是多台机器,也就是说一套数据集市可以支撑多个应用系统,每个应用系统用不同的客户端来做数据展现。例如一个系统是专门来做固定报表定时推送的,另外一个系统是专门来做BI展现前端,用户通过账号登陆进去,访问可视化的界面,并做实时的数据分析和交互。
2.5 分布式通讯
基于分布式并行计算的大数据自助分析系统中各层之间的通讯采用分布式,如图3所示。系统中的中间计算结果能否在集群中稳定且高效地传输,是整个集群能否达到实时计算的关键。系统采用可复用的TCP/IP 连接,系统的TCP/IP连接是可复用的,不像传统方式一样,一个信息传递需要建立一个连接,而信息交换的接收与发出逻辑对应的软件进程/线程是可复用的。这一方法降低了整个系统的TCP/IP负载,以及线程/进程开销。
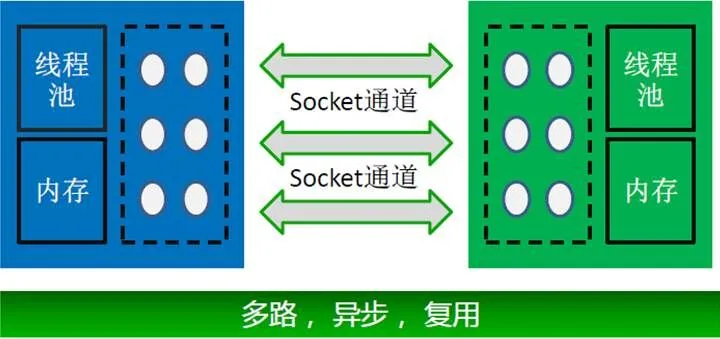
图3 分布式通讯
系统的信息传输是多路的。这类似于高速公路的多车道。如果一个TCP/IP 连接不够,可以增加TCP/IP 连接。而如果闲置,可以收回多余的连接以释放网络、CPU、内存资源。
系统的信息传输是异步的。发出信息的请求方不会占据着TCP/IP 连接,而是在发出信息之后立即释放资源。以异步的消息通知机制等待返回处理结果,这一异步机制让系统在等待返回处理结果时不会白白耗费资源,在接收方处理信息时也不会占据TCP/IP连接和相应的线程/进程资源。系统以异步信息交换的方式,成功地消除了信息处理与信息传输之间的耦合。提升了信息交换能力,但有效地降低了信息交换所需要的网络资源、CPU、或者内存资源。稳定的内存使用:由于整个通讯过程中Socket通道是复用的,而Socket通道对应的读内存块和写存块也是复用的,很少有内存的申请和释放操作。这提升了整个系统的性能和稳定性。
健壮的信息传输:系统的TCP/IP连接是可自修复的。网络可能会有各种问题导致连接出错,为了避免数据流里可能丢失了数据,给每个数据流的头部加了标识位,在任何找不到标识位的情况下,连接都会自动关闭。系统会自动重新建立连接。
2.6 系统前端设计
作为商业智能平台的前端,为用户操作提供方便,提供了多样的数据展现形式,丰富的图表展示形式,人性化的人机交互方式,支持各种商业逻辑的动态脚本引擎等。客户可以进一步与数据互动(Interactive),过滤(Filter)、钻取(Drill)、刷取(Brush)、关联(Associate)、变换(Transform)等等技术,深入分析互联网用户的行为,准确了解用户的行为习惯。主要功能设计如下:
(1)数据下载,提供取数结果下载功能,支持TXT/CSV/PDF格式,PDF文件支持数字水印保护。支持批量下载和离线下载。外部文件上传及关联,导入外部文件,在取数时进行关联。
(2)数据集二次处理,对于系统中的即时/定时任务、外部导入、已二次处理等数据集,可以进行两个数据集的交、差、并、左关联等运算以获取新的数据集。多维分析,分析表格支持多维分析,维度单元格自动合并。
(3)表格功能。报表单元格钻取下载清单,自助分析提供分析报表单元格下载清单数据,方便业务分析人员针对分析结果查看对应的分析数据源清单;报表单元格钻取关联分析,自助分析提供分析报表单元格钻取关联其他分析,方便业务分析人员快速进行关联分析;报表发布及审批,制作好的分析报表可以保存及发布,能够灵活发布到自助分析模块或者经分系统中。发布时可指定审批人,审批完成后即可进行查看;报表下载,对于制作完成的报表,用户可以下载。下载的格式为Excel文档,支持手机验证码验证。
(4)数据透视分析。提供用户自行设计数据透视表界面及展示内容的能力,用户可以动态地改变数据透视表的版面布置,以便按照不同方式分析数据,也可以重新安排行标签、列标签和指标函数,同一数据集的不同分析方式,实现透视分析。
(5)数据生命周期。系统记录所有任务的数据集操作历程,方便查询所有对数据集的操作内容。展现所有当前和历史的任务数据情况,包含“数据已删除”和“任务已删除”的任务。
2.7 数据安全保障
由于涉及查询用户的清单明细信息,所以自助分析提供了多种数据安全保障措施,能够有效防止敏感数据的越权查询和泄露。用户预览、查看数据时,按其归属地域做权限管控;用户下载重要数据时,需要做金库认证;屏蔽了所有页面的右键,并防止拷贝敏感数据:对于敏感数据,浏览时可以做模糊化处理;支持将用户下载的数据推送至虚拟桌面进行浏览;预览、浏览数据时,对数据背景做了水印处理:用户浏览、下载数据的日志可追溯。
3 结论
自助分析系统的架构在用户访问、数据处理、数据存储等层次都支持分布式部署,因此可通过对服务器集群线行扩展来提高数据处理能力。分布式架构的核心问题是系统运行过程中的高并发和高1/0。通过数据中心上层部署分布式数据集市的方式,分担分布式数据中心的压力。分布式数据中心作为数据仓库,需要承担数据的存储,计算和其他数据请求,需要在数据的增、删、改、查和运算等各个功能做好资源的均衡。可视化的业务操作页面,通过简单的拖拽点选即可快速完成业务分析模型。生成的可视化报告,可以实现数据联动,数据筛选,使得数据展现成为数据分析开始的第一步,使可视化之后的进一步深入的探索式分析得以继续,充分释放数据的价值。
[1] Yao D, Yu C, Dey A K, et al. Energy efficient indoor tracking on smartphones[J]. Future Generation Computer Systems, 2014, 39(39): 44-54.
[2] Sun Q, Deng B, Fu L, et al. Non-redundant Distributed Database Allocation Technology Research[C]//International Conference on Computing Intelligence and Information System. IEEE Computer Society, 2017: 155-159.
[3] M. D. Samrajesh, Gopalan N P. Towards Multivariable Architecture for SaaS Multi-tenant Applications[J]. International Journal of Software Engineering & Its Applications, 2016, 10(4): 13-26.
[4] 孟维一. 基于数据仓库的保险商业智能系统设计与实现[D]. 北京交通大学, 2016.
[5] 郑啸, 李景超, 王翔, 等. 大数据背景下的国家地质信息服务系统建设[J]. 地质通报, 2015, 34(7): 1316-1322.
[6] 罗鹏, 龚勋. HDFS 数据存放策略的研究与进步[J]. 计算机工程与设计, 2014, 35(24): 1127-1131.
[7] 顾涛. 集群Map Reduce 环境中任务和作业调度若干关键问题的研究[D]. 天津: 南开大学, 2015.
[8] 杨杉, 苏飞, 程新洲, 袁明强, 董润莎. 面向运营商大数据的分布式ETL研究与设计[J]. 邮电设计技术, 2016, 8(1): 50-52.
[9] 侯雪燕, 洪阳, 张建民, 等. 海洋大数据: 内涵、应用及平台建设[J]. 海洋通报, 2017, 36(04): 361-369.
[10] 孙大为, 张广艳, 郑纬民. 大数据流式计算关键技术及系统实例[J]. 软件学报, 2014, 25(4): 839-862.
Research and Application of Big Data Self-help Analysis System Based on Distributed Parallel Computing
WENG Ye-lin1, JIANG Dao-xia1, YU Xin-hua2
(1. Jiangsu Vocational and Technical College of Finance and Economics, Huai'an 223001, China; 2. Jiangsu Mobile Corporation, Nanjing 210001, China)
Once big data enters more enterprises, we will put forward more expectations for big data. In addition to data statistics, the era of big data requires intelligent analysis, breaking the constraints of IT, and exploring the most efficient way to quickly seize the commanding heights of data. Based on the research and application of the application scheme of the data self-help analysis platform under the distributed parallel computing of a company, this paper puts forward the idea of massive data processing in the self-help analysis system, and focuses on the analysis of distributed parallel computing and distributed communication. At the same time, combining with the functional characteristics of the self-help analysis system, the paper gives the following suggestions: Put forward the application suggestion of system deployment. The research content has certain practical value for the landing of distributed computing in large data decision analysis system.
Distributed parallel computing; Big data; Self help analysis
TP311.1
A
10.3969/j.issn.1003-6970.2018.12.019
翁业林(1981-),男,硕士,讲师,研究领域:计算机网络技术;蒋道霞(1965-),女,博士,教授,研究领域:计算机软件;俞新华(1981-),男,硕士,高级工程师,研究领域:移动通信。
翁业林,蒋道霞,俞新华. 基于分布式并行计算的大数据自助分析系统的研究与应用[J]. 软件,2018,39(12):83-86
