基于Hadoop平台的优化协同过滤推荐算法研究
2019-01-23申晋祥鲍美英
申晋祥,鲍美英
基于Hadoop平台的优化协同过滤推荐算法研究
申晋祥,鲍美英
(山西大同大学计算机与网络工程学院,山西 大同 037009)
针对协同过滤推荐算法在大数据环境下存在的数据稀疏性和可扩展性问题,在分析研究Hadoop分布式平台与协同过滤推荐算法后,本文提出一种基于Hadoop平台的优化协同过滤推荐算法。该推荐算法将相似度高的用户或项目聚为一类,再设计用户和项目矩阵,以更有效的获得各自的最近邻居集,采用加权系数处理两者的预测评分,并对设计矩阵完成MapReduce并行化实现,这种加权系数处理后的推荐架构,很好的缓和了数据稀疏性且提高了预测精度。实验验证该算法能有效提高推荐系统的推荐效率,同时获得良好的可扩展性。
协同过滤推荐算法;Hadoop;数据稀疏性;扩展性
0 引言
随着互联网的迅速发展,人们将会面对海量数据信息,大量的网络信息在给人们带来方便的同时,信息过载问题也会越来越突显[1-2]。如何在海量信息中获得自己想要的内容是目前急待解决的问题。作为信息过滤的重要手段,推荐技术[3-4]是完成这一任务的有效方法,其中推荐算法是整个推荐系统中最核心、最关键的部分,而协同过滤推荐CFR(Collaborative filtering recommendation)是推荐算法中最为广泛,也是最成功的方法之一,同时也是目前研究的热点问题[5]。Hadoop作为一个分布式和可并行处理大规模数据的云计算平台,给推荐系统提供了很好的解决方案[6-7]。Hadoop充分利用集群进行计算[8],有利于处理海量数据,也是对传统单机模式的补益。
大数据时代的到来,使网络中的信息、用户以及推荐对象的数量都会海量涌现,海量数据的存储和计算的快慢将起到决定性作用。传统模式的协同过滤算法将越来越难满足海量数据的运算需求,因此优化协同过滤推荐算法将是一个新的研究方向。近年来有一些高效的协同过滤推荐研究,比如Pan R[9]等人提出的基于ALS(Alternating Least Squares)的协同过滤算法。Jeong B[10]等人提出基于融合的方法对预测评分数据进行填补,来缓和数据稀疏性。邓[11]等人基于项目属性研究进行评分,依据项目间的关联度最终产生推荐对象,很好的改善了数据稀疏性问题。
针对协同过滤推荐算法在大数据环境下存在的数据稀疏性和可扩展性问题,本文提出一种基于Hadoop平台的优化协同过滤推荐算法。该推荐算法综合考虑了基于用户(User-based)的协同过滤算法的预测评分和基于项目(Item-based)的协同过滤算法的预测评分,构建User和Item矩阵,有效的获得各自的最近邻居集,采用加权系数处理两者的预测评分,这种推荐架构,很好的缓和了数据稀疏性且提高了预测精度,同时获得良好的可扩展性。
1 基于Hadoop平台的优化协同过滤推荐算法
1.1 算法流程
本文所提出的优化协同过滤算法是一种基于用户和项目的综合考虑的协同过滤算法架构,主要完成聚类模块、User和Item矩阵构建模块、最近邻居查找模块、预测评分处理模块,流程如图1所示。
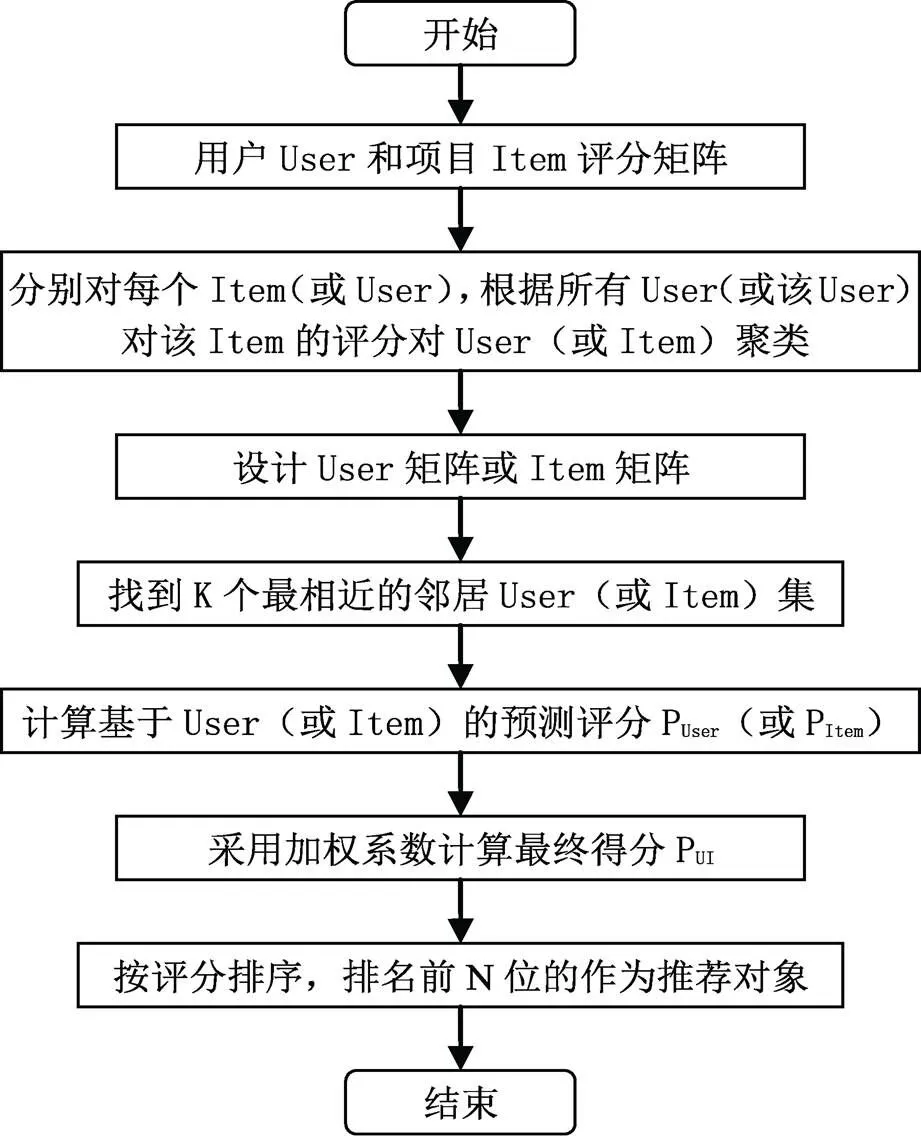
图1 优化协同过滤算法流程
结合以上流程可知,该算法同时考虑了用户和项目两方面信息,在一定程度上缓和数据稀疏性问题。设计User矩阵和Item矩阵,更好的找到最近邻居集,提高推荐的准确性。综合考虑使系统的多样性(即推荐对象的覆盖率)更好,同时也可较好的应对冷启动问题。
1.2 算法设计
该算法从用户的评分信息中展开数据挖掘,选取目标User(或Item)相似度最高的最近邻居,从中预测评分然后产生推荐。
聚类设计,我们知道K-means算法存在K值不好确定以及聚类结果不稳定的问题。本文所提算法分别对用户和项目进行聚类,将偏好相近的用户或项目聚为一类,再从中选出邻居用户集和邻居项目集,进行偏好度预测,提供推荐。基于用户聚类如表1所示。基于项目聚类如表2所示。
表1 基于用户聚类的示例

Tab.1 Examples based on user clustering
表2 基于项目聚类的示例
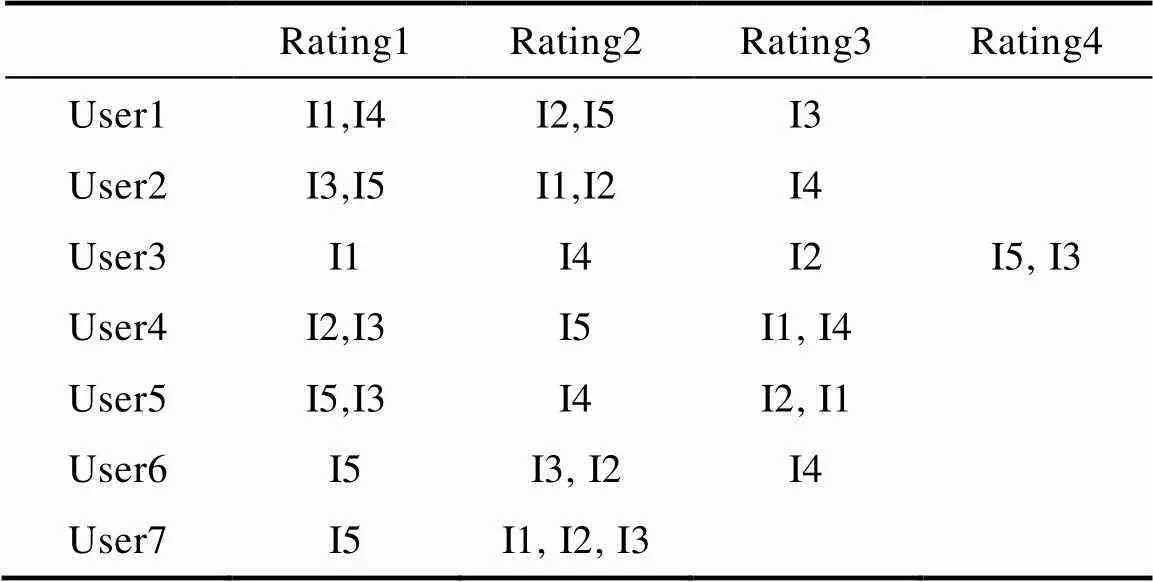
Tab.2 Examples based on item clustering
表中U(即User)表示用户,I(即Item)表示项目,Rating表示用户对项目的评分,表1根据所有用户对Item的Rating,对这些用户进行聚类操作,将Rating相似的用户聚为一类。表2根据当前User对Item的Rating,对这些Item进行聚类操作,将Rating相似的项目聚为一类。
User和Item矩阵设计,User矩阵如表3所示,根据每一Item中User的聚类情况,计算两两User相聚一类的次数。Item矩阵如表4所示,根据每一User中Item的聚类情况,计算两两Item相聚一类的次数。次数越多表示他们之间的关系度越大。
最近邻居集的形成,本算法采取预定值法,预先取一个适当的K值,将相似度排前K位的对象作为最近邻居集合。对于User矩阵而言,行表示即定用户,列表示对应的邻居用户,值即为两两相聚一次的结果用CR计数,CR的值越大表示之间的偏好越相似。然后对CR进行排序,取前K个作为即定用户的最近邻居集Neighbors(user)。如表3的User矩阵中,对即定用户U1取前3个相似度最大的最近邻居集为{U3,U6,U2}。对于Item矩阵同理求得最近邻居集Neighbors(item)。
表3 User矩阵的示例
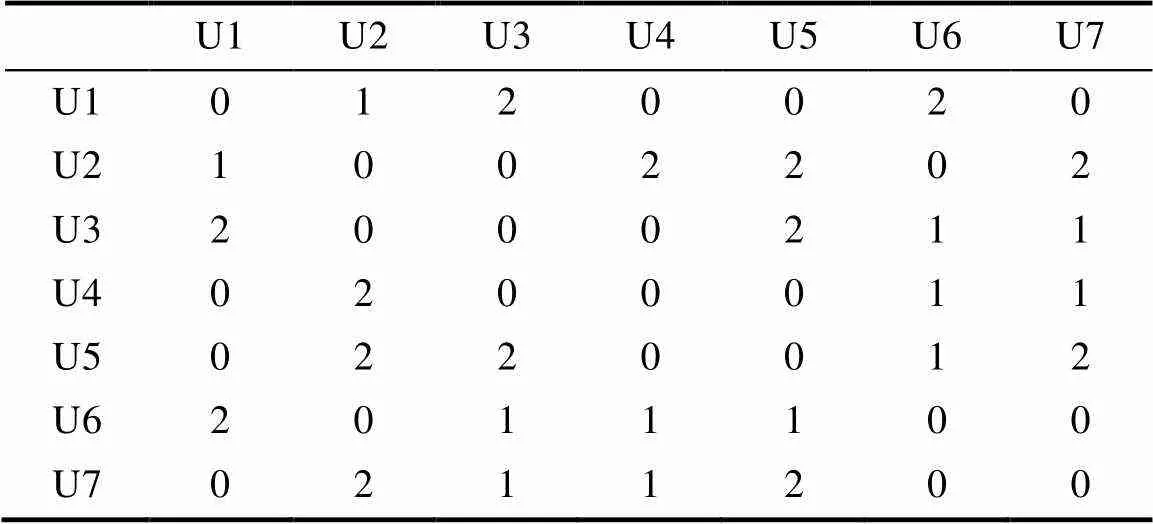
Tab.3 Examples of the User matrix
表4 Item矩阵的示例
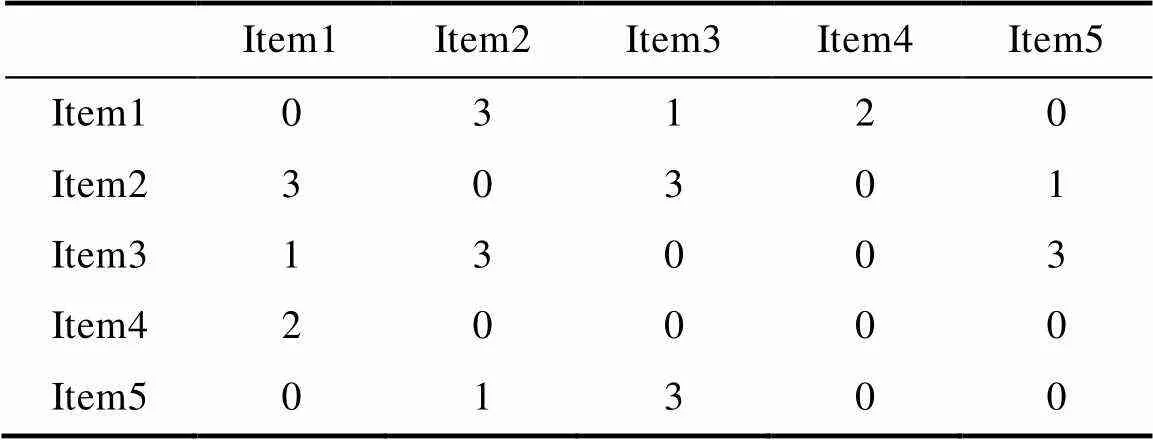
Tab.4 Examples of the Item matrix
评分预测及加权系数处理,本算法计算相似度的方法采用Pearson相关系数。基于用户的协同过滤算法的预测评分如公式(1)和公式(2)所示。
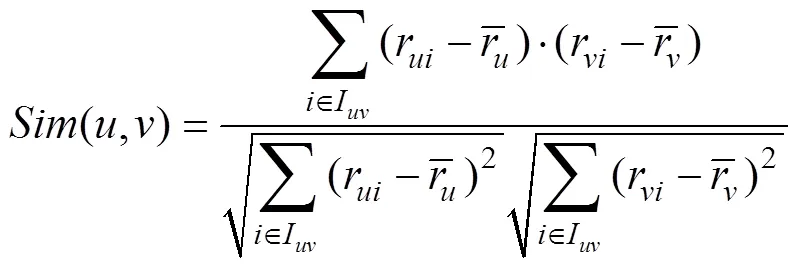
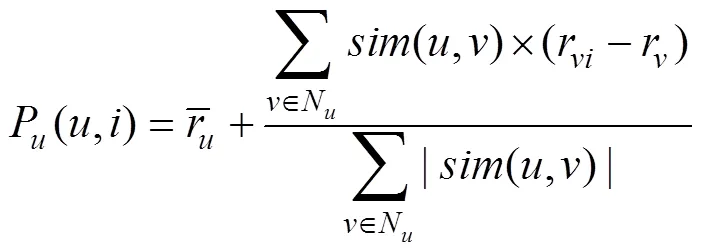
基于项目的协同过滤算法的预测评分如公式(3)和公式(4)所示。
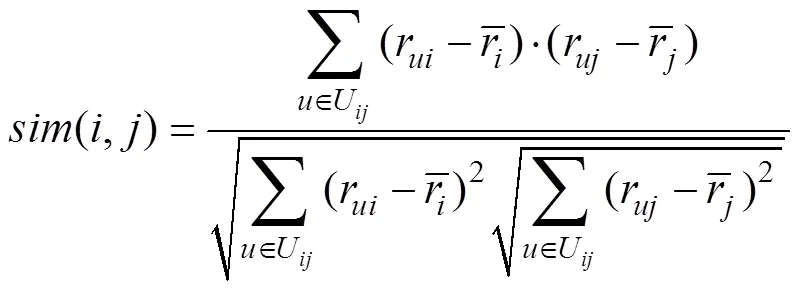

以上公式中,用U表示是同时对项目和共同评过分的用户集合,用r和r分别表示用户对项目和的评分,用r和r上加一横线分别表示所有用户对项目和的评分均值,用r和r上加一横线分别表示用户和用户对项目的评分均值,用I表示用户和同时评过分的项目集合,用N和N分别表示项目和用户的最近邻居集。
本文采用系数C(Coefficient,C)对基于用户和基于项目的两种计算得出的预测评分进行加权处理,如公式(5)所示。
P(,)=CP(,)+(1-)P(,) (5)
将最终得出的评分预测值排前K位的项目作为推荐结果。
1.3 优化算法的MapReduce并行化实现
MapReduce是Google提出的一个软件编程框架,用于大规模数据集的并行运算。对算法进行并行化实现主要是对User和Item矩阵设计部分进行实现,使其更利于大数据量的处理。MapReduce并行化实现过程中相关的数据存放在Hadoop平台下对稀疏性数据有良好支持的HBase分布式开源数据库中。具体涉及User矩阵并行化和Item矩阵并行化两项工作。
User矩阵并行化主要包括一个Map和一个Reduce操作过程。Map过程如下:
(1)Map(key,value){//value:将HBase中的用户偏好模型表uim作为Map的输入;
(2)user+item=value.getRow()
rating=value.getValue(data:rating)
fu=value.getValue(data:fu)
//得到user、item和fu(基于用户聚类时的标记)的信息;
(3)Outputkeyvalue(item+fu,user)
//输出形式为
(4)Combine(key,values){
For each value1 in values
For each value2 in values
IF(value1.user!=value2.user)
Outputkeyvalue(value1.user+
value2.user,1)
End IF
End For
End For
}//在这里Combiner得到的输入形式为
Reduce过程如下:
(1) Reduce(key,values){
For each value in values
CR+=value
End For //输入是通过Shuffle过程得到的
(2) Store(key,CR) into table userMatrix
//存入HBase的user矩阵表userMatrix中;
Item矩阵并行化过程同理。
2 实验结果与分析
2.1 实验数据集
本实验采用GroupLens提供的MovieLens电影评分数据集,相关数据有用户特征信息、电影属性信息、用户对项目的评分信息等,用户对项目的评分值是从1到5的整数,实验采用1MB的数据集,其中包括6040个用户对3900部电影的1000209条评分记录。
2.2 实验评估标准
本实验通过平均绝对偏差(MAE)和均方根误差(RMSE)计算评分预测的准确度,MAE是算法计算得出的预测评分值和用户对项目的实际评分值之间的偏差,RMSE是计算预测评分与真实评分之间的偏差的均方根值。MAE值和RMSE值越小,说明预测值和真实值之间的误差越小,预测的准确度越高。用N表示实验测试项目数,Pi表示预测评分值,Ri表示实际评分值,MAE和RMSE的计算如公式(5)和公式(6)所示。
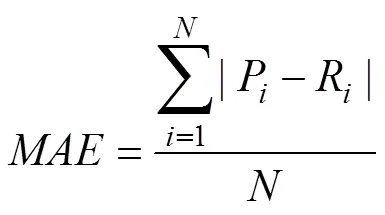

2.3 实验结果
(1)最近邻数的影响
将本文提出的优化协同过滤推荐算法(OCFRA)和采用K-means算法实现基于用户和项目双重聚类的协同过滤算法(KCFRA)、基于用户聚类的协同过滤算法(UCFRA)、基于项目聚类的协同过滤算法(ICFRA)进行对照,验证最近邻数对MAE和RMSE的影响。实验结果如图2和图3所示。

图2 最近邻数对MAE值的影响
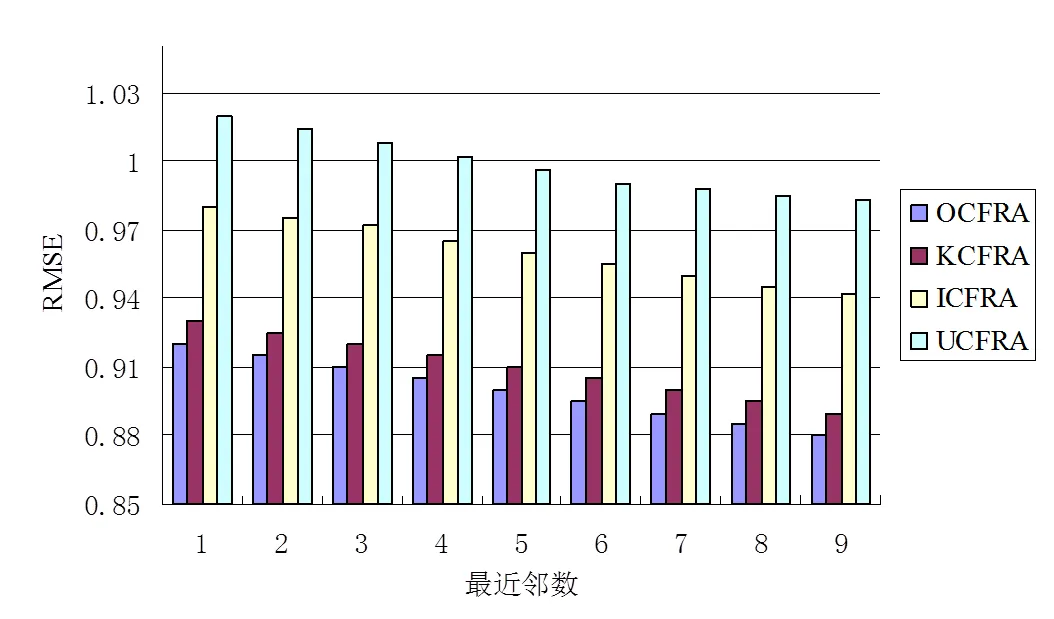
图3 最近邻数对RMSE值的影响
实验结果可以看出,随着最近邻数的增加,各种算法的MAE值和RMSE值都在减少,本优化算法相比其它算法要更小,有更好的推荐效果。
(2)矩阵密度的影响
将本文提出的优化协同过滤推荐算法(OCFRA)和采用K-means算法实现基于用户和项目双重聚类的协同过滤算法(KCFRA)进行对照,验证不同的矩阵密度对MAE和RMSE的影响。实验结果如图4和图5所示。
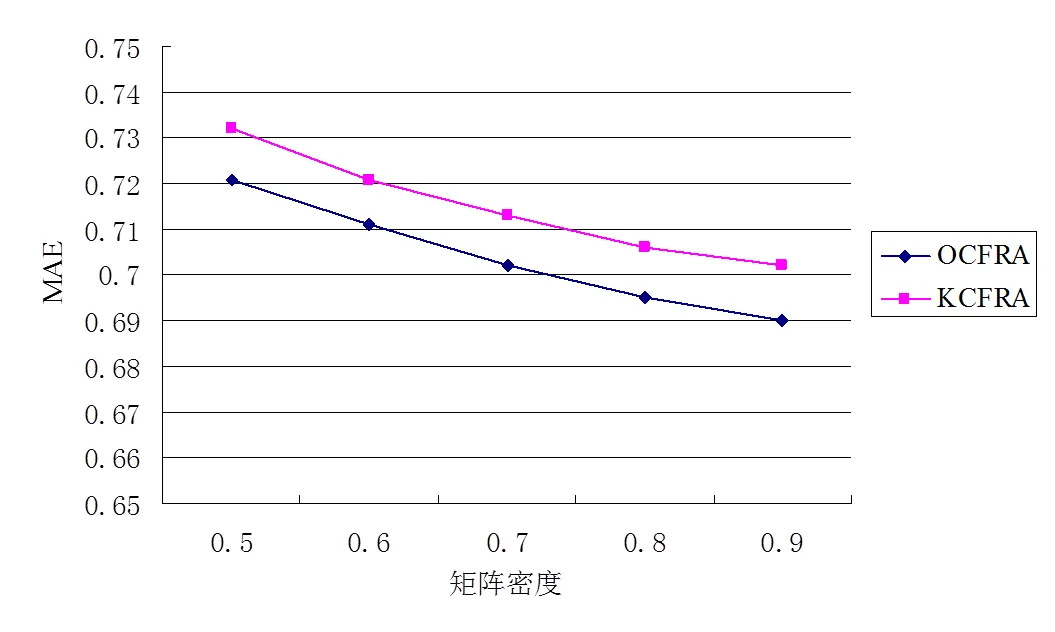
图4 矩阵密度对MAE值的影响
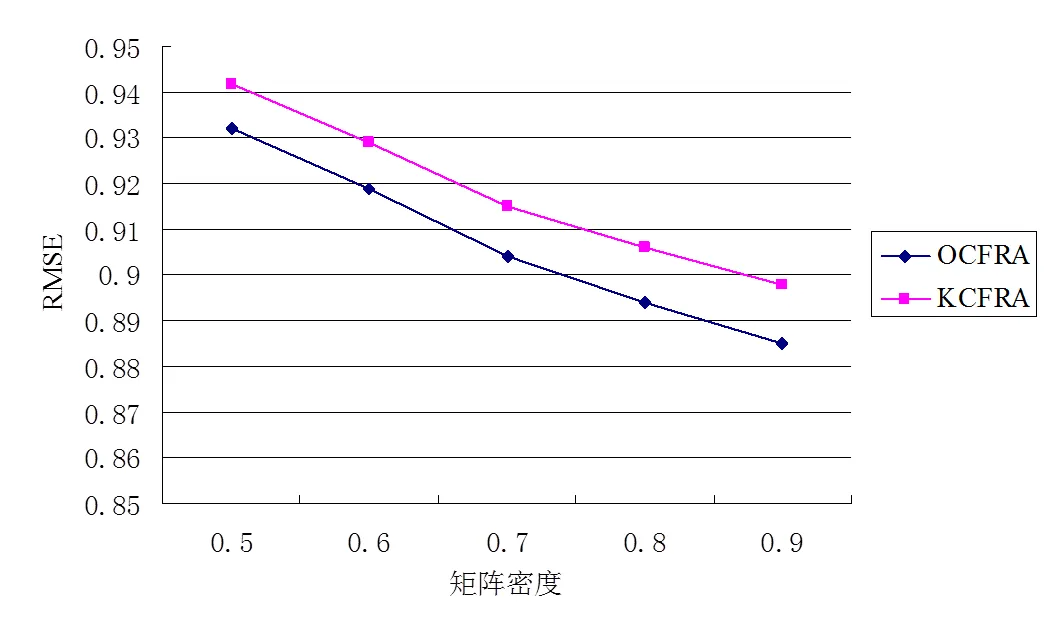
图5 矩阵密度对RMSE值的影响
实验结果可以看出,随着矩阵密度的不断增大,各种算法的MAE值和RMSE值都会受到影响而下降,本优化算法在不同矩阵密度下效果最好,有更高的预测准确度。
3 结论
本文针对协同过滤推荐算法在大数据环境下存在的数据稀疏性和可扩展性问题,结合Hadoop分布式计算的特点以及目前已有的研究现状,提出了一种基于Hadoop平台的优化协同过滤推荐算法。该算法对用户和项目的聚类再进一步设计User矩阵和Item矩阵,并完成MapReduce并行化实现,最后加权系数处理预测评分。通过实验验证了该推荐算法的优势,良好的改善了数据稀疏性和可扩展性,为用户提供更加准确和优质的推荐对象。
[1] Duan Miao. Collaborative filtering recommendation algorithm[J]. International Journal of Security & Its Applications, 2015, 9(7): 99-108.
[2] 翁小兰, 王志坚. 协同过滤推荐算法研究进展[J]. 计算机工程与应用, 2018, 54(1): 25-31.
[3] Luo Qi, Miu Xin-jie, Wei Qian. Further research on collaborative filtering algorithm for sparse data[J]. Computer Science, 2014, 41(6): 264-268.
[4] 彭石, 周志彬, 王国军. 基于评分矩阵预填充的协同过滤算法[J]. 计算机工程, 2013, 39(1): 175-182.
[5] 孙辉, 马跃, 杨海波. 一种相似度改进的用户聚类协同过滤算法[J]. 小型微型计算机系统, 2014, 35(9): 1967-1970.
[6] Manolis G, Vozalis, Angelos M, et al. Collaborative filtering through SVD-based and hierarchical nonlinear PCA[J]. Artificial Neural Networks ICANN, 2010, 6 396-399.
[7] 黄震华, 张佳雯, 田春岐, 等. 基于排序学习的推荐算法研究综述[J]. 软件学报, 2016, 27(3): 693-708.
[8] KYONG-HA LEE. Parallel Data Processing With MapReduce: A Survey[J]. SIGMOD Record, 2011, 40(4): 15-19.
[9] Pan R, Zhou Y, Cao B, et al. One-class collaborative filtering[C]//Proceedings of the Eighth IEEE International Conference on Data Mining, 2008: 505-510.
[10] Jeong B, Lee J, Cho H. An iterative semi-explicit rating method for building collaborative recommender systems[J]. Expert Systems with Applications, 2009, 36(3): 6182-6185.
[11] Deng Ai-lin, Zuo Zi-ye, Zhu Yang-yong. Collaborative filtering recommendation algorithm based on item clustering[J]. Journal of Chinese Computer Systems, 2004, 25(9): 1666- 1765. (in Chinese).
Research on Optimized Collaborative Filtering Recommendation Algorithm Based on Hadoop Platform
SHEN Jin-xiang, BAO Mei-ying
(College of Computer and Network Engineering, Shanxi Datong University, Datong Shanxi 037009, China)
In order to solve the problem of data sparsity and scalability in big data environment, a collaborative filtering recommendation algorithm based on Hadoop platform is proposed in this paper after analyzing and researching the Hadoop distributed platform and collaborative filtering recommendation. The recommendation algorithm can aggregate users or projects with high similarity into one class, then designs users and project matrices to get their nearest neighbors more effectively. The weighted scores are used to deal with the prediction scores, and the design matrix is parallelized by MapReduce. The recommended architecture of this weighting coefficient has greatly alleviated the sparsity of data and improved the prediction accuracy. Experiments show that the proposed algorithm can effectively improve the recommendation efficiency of the recommendation system and obtain good scalability.
Collaborative filtering recommendation algorithm; Hadoop; Data sparsity; Scalability
TP391
A
10.3969/j.issn.1003-6970.2018.12.001
国家自然科学基金项目(11871314);山西省青年科技基金(2015021101);山西大同大学校级科研项目(2017K7)
申晋祥(1977-),男,讲师,硕士,主要研究方向:大数据,云计算。鲍美英(1975-),女,副教授,硕士,主要研究方向:网格计算,云计算。
申晋祥,鲍美英. 基于Hadoop平台的优化协同过滤推荐算法研究[J]. 软件,2018,39(12):01-05
