基于特征向量的煤矿领域实体关系抽取
2019-01-23伊海迪石一鸣杨博杜新玉刘旭红
伊海迪,石一鸣,杨博,杜新玉,刘旭红
(北京信息科技大学计算机学院,北京100000)
0 引言
煤炭是我国的基础能源,我国多数煤矿建设了安全监测监控、综合信息化网络信息管理等各类系统,但是煤矿重大灾害总量仍居高不下,本文将建立煤矿领域知识图谱,融合各种来源的数据,为灾害分析和预防提供帮助。
随着知识图谱技术的发展,国内外相继出现了许多大型的知识图谱,例如:DBpedia、Freebase、YAGO,以及百度的知心搜狗的知立方等,皆为综合性知识谱图,在很多特定领域例如煤矿领域,仍然没有建立完整的知识图谱。
实体关系抽取是构建知识图谱的关键步骤,研究人员提出多种算法用于提高实体关系抽取结果的正确率。Miller等[1]提出了基于完全语法解析树的方法,在解析树中增添了对应于实体和关系的语义信息,并建立生成模型集成了命名实体识别和关系抽取等任务,以寻求全局优化;Claudio等[2]考虑了实体及其上下文特征、动词特征、距离特征、实体扩展特征等,并将关系抽取转化成一个基于SVM的分类问题;黄鑫[3]通过单独选取词法、实体和基本短语块为基本特征,使用SVM工具进行关系抽取,发现组合特征能显著提高关系抽取的性能;毛晓丽[4]提出了基于特征选择的实体关系抽取方案,引入了文本分类中的特征选择算法,如信息增益、期望交叉熵和x2统计,有效地实现了实体关系抽取中的特征空间降维。
对于上述四种改进方法,对于实体关系抽取的准确率都有不同程度的提升,但其本质都为监督学习方法,需要大量的人工标注,在数据量日益剧增的环境下,为降低人工成本,在此使用远程监督方法,通过知识库对齐朴素文本的方式进行实体对标注。接着通过编写启发式规则减少远程监督方法产生的噪声数据,实现对煤矿领域“发生”关系的抽取。
1 煤矿领域实体关系抽取框架
煤矿安全与灾害等相关网站蕴含了大量的煤矿灾害发生的信息,为煤矿知识图谱构建提供了海量的数据。根据煤矿数据的特点,本文抽取具有“发生”关系的实体对,并构建知识图谱。例如在“棠浦煤矿(国有地方),发生一起顶板事故”中抽取“棠浦煤矿”和“顶板事故”作为一对具有“发生”关系的实体对。
网页大多属于非结构化数据,针对该特点,本文提出如下的实体关系抽取框架,如图1所示。

图1 实体关系抽取框架
具体步骤如下:
(1)对数据进行预处理和实体识别
从网页上爬取的数据含有大量的冗余信息,为了从庞大的数据中选取所需的小部分有用信息,需要对数据进行清洗,去掉重复数据,抽取出网页的数据部分,去除标题、摘要、引用文献以及HTML标签等无用信息。然后,进行分词、词性标注和和命名实体识别。
基于煤矿领域字典,将出现在字典中的实体全部提取,标明每个实体所在的文章和句子位置。
(2)生成候选实体对集合
为了抽取句子中的具有“发生”关系的实体对,将同一篇文章同一句话的实体进行笛卡尔积运算并去除重复项得到候选实体对。结合实体对表和文章表,使用N-Gram模型提取基于候选实体对的语义特征。
(3)基于远程监督学习产生具有“发生”关系的训练数据
采用远程监督方法抽取实体关系有助于减轻人工标注的负担。利用外部知识库对候选实体对进行一次权重标注,总结候选实体对出现时的特征,设置启发式规则,对候选实体对进行二次标注,将两次打标结果求和得到每个实体对的权重值。两次标注大大提高了实体标注的准确率,并且启发式规则也起到过滤噪声的作用。
(4)基于因子图[5]进行概率推理
由第(2)步得到的候选实体对包含大量的噪声数据,通过进行降噪处理。对第(3)步所得实体对权重表的权值进行二值化处理,得到已知“具有”关系、已知“不具有”关系以及大量“未知”关系的实体对。结合特征表和实体对权重表,统计推理候选实体对间具备“发生”关系的置信度;其间迭代使用吉布斯采样和随机梯度下降算法学习得到候选实体对的特征权重及边界概率,最终抽取置信度高于规定阈值的候选实体对,并去掉低于规定阈值的候选实体对噪声数据,即为具有“发生”关系的煤矿及发生的事故类型。
下面详细说明权重标注步骤、启发式规则编写依据以及规则权重给予情况。
1.1 权重标注和启发式规则设计
远程监督关系抽取的本质是一个带有稀疏和噪声特征的多标签分类问题。其产生的噪声数据主要分为两种,一种是多实例问题,即与外部知识库对齐所得实体对并不包含指定关系;另一种是多标签问题,即同一实体对在外部知识库中有多种关系标签[6]。由于本文研究面向煤矿领域,只抽取一种“发生”关系,所以,本文所做实验不存在多标签情况。为此,本文主要研究多实例问题,并提出以下解决方法。
由实验步骤(3)可知本实验通过对所得实体对进行两次打标来降低噪声数据对关系抽取的影响,打标过程如图2所示。由于本实验抽取的实体关系为煤矿与事故间的“发生”关系,可知,“发生”关系为单向关系,所以在每句话抽取的多个实体进行的笛卡尔积结果中,对于实体对

图2 实体对打标图
通过观察整体数据,挑选出具有代表性的“具有”和“不具有”“发生”关系的例句,总结为表1:

表1 “发生”关系类型表
观察实验数据,总结“发生”关系成立或不成立的特点及该特点对“发生”关系成立与否的影响程度大小,编写启发式规则及其打标权重如下:
(1)同时出现在知识库和实体对表中的实体对给予权重3。
(2)两实体AB间有发生关键字且实体A在实体B之前(正向),给予权重2。
(3)两实体AB间有发生关键字且实体B在实体A之前(反向),给予权重-10。
(4)两实体AB间无发生关键字,给与权重-10。
(5)两实体AB间有另一实体C,给予权重-10。
(6)两实体AB间有特殊符号,给予权重-1。
(7)两实体AB相距过远,给予权重-1。
通过观察常用句式特征,发现实体对是否具有“发生”关系的特征具有标志性,通过特征1、2,可以判断此实体对极大可能具有“发生”关系,故给予较大的正权重,通过特征3、4、5可以很明确判断此实体对极大可能无“发生”关系,故给予了较大的负权重。而对于规则6、7出现情况较少且对于实体对不具有“发生”关系不提供明确证据,故给予较低负权重。
远程监督方法结合启发式规则,可有效提高标注数据的质量,对于知识库中未包含的实体对可以进行更加准确地判断,大大减轻了噪声数据对关系抽取的负面影响;有利于提高因子图模型判别实体关系的效果。
1.2 因子图模型构建
本文面向煤矿领域数据构建因子图模型,进一步减少噪声数据。根据各实体对共享不同特征的情况,计算实体对具有发生关系的边界概率;结合吉布斯采样降低计算维度,在不影响实验准确率的情况下减小了机器的工作量,提高了工作效率;并采用随机梯度下降进行迭代学习,直至模型收敛。
因子图就是对函数因子分解的表示图,一般含有两种节点,变量节点和因子节点。通过因式分解可以将一个全局函数分解为多个局部函数的积,这些局部函数和对应的变量就能体现在因子图上。例如现在有一个全局函数,其因子分解方程是:g(x1,x2,x3)=fa(x1,x2)fb(x1,x2)fc(x2,x3)fd(x3),因子图表示如图 3 所示:
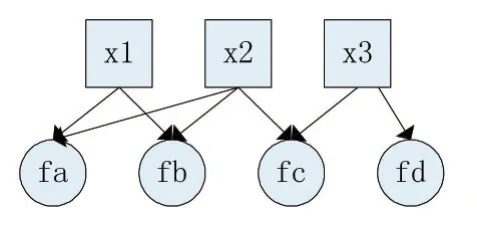
图3 因子图示例
如表2所示为实体对-特征示例表,实验中的实体对vi(i=1,2,3…)作为模型的变量节点,每对实体对都具有关系标签(T,F,NULL),分别表示实体对“发生”关系为“具有”、“不具有”、待判断,标签值在学习过程中不断更新。实体对所具有的特征集合为模型的因子节点fi(i=1,2,3…),每个实体对具有至少一种句内特征即每个因子节点至少和一个变量节点相关联。
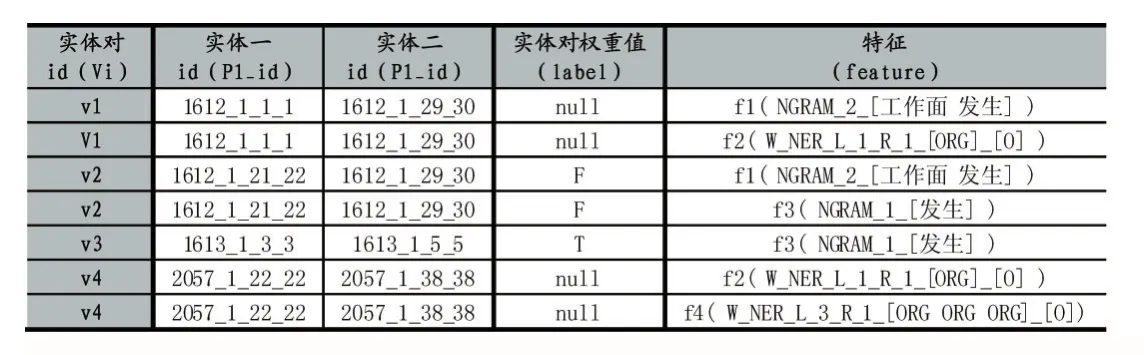
表2 变量节点-特征示例表
因子节点和变量节点的连线称为因子图的边集,不同的因子节点,通过共享变量节点而相连,各特征经函数映射转化为关联权重因子wi=func(feature),可得特征因子-特征函数表如表3所示:

表3 特征因子-特征函数表
根据已知实体对权重值以及特征推理未知实体对权重值并完成因子图构建,
由公式 Pr(I)∝ measure{w1f1(v1,v2)+w2f2(v2)}[7],首先计算实体对每种情况下的概率值,例如实体对(v1,v2)label值有四种可能情况:(1,1)、(1,0)、(0,0)、(0,1),然后计算 Pr(1,1)=Pr(1,1)/Pr(1,0)/Pr(0,0)/Pr(0,1)得到两实体对label都为1时的概率,由此可以判断出未知label的实体对标签。
具体推理过程如图4所示。借助因子图模型良好的统计和推理性能,可计算得到全部候选实体对具有“发生”关系的置信度;通过尝试多次试验,设置关系判别的阈值α(如α=0.5);筛选出置信度高于该阈值的实体对,即实现“发生”关系抽取任务。
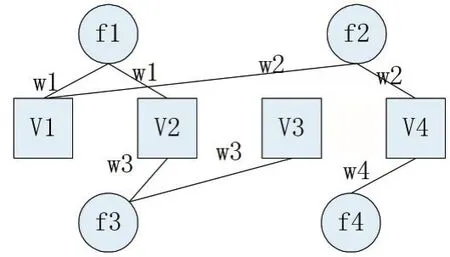
图4 构建因子图示例
2 实验结果与分析
本实验所用数据为煤矿安全网、煤矿事故网、安全管理网上爬取的事故新闻、分析报告,使用WebMagic框架,分析新闻标题XPath,爬取数据。数据清洗后,共剩余2418篇煤矿领域文章,所抽出实体经过笛卡尔积运算并筛选后共得到8054对实体对。其中训练数据占总数据的80%。
图5为正确率图,将测试集中的数据对应的推理出的概率值取其与 k/10 的近似值,其中 k=1,2,3,…,10,即将概率值分为10个概率桶,图片显示了每个概率桶的正确预测的比率。理想情况下,实线应遵循虚线,对于高概率桶,表示系统发现大量证据对较高概率桶的正面预测,对于较低概率桶,系统发现线性预测证据数量较少。在本实验中,引入远程监督方法降低人工标注工作量,由此产生的噪声数据未去除干净和训练数据的稀疏等原因会使实线在虚线上下浮动,此情况在正常范围之内。
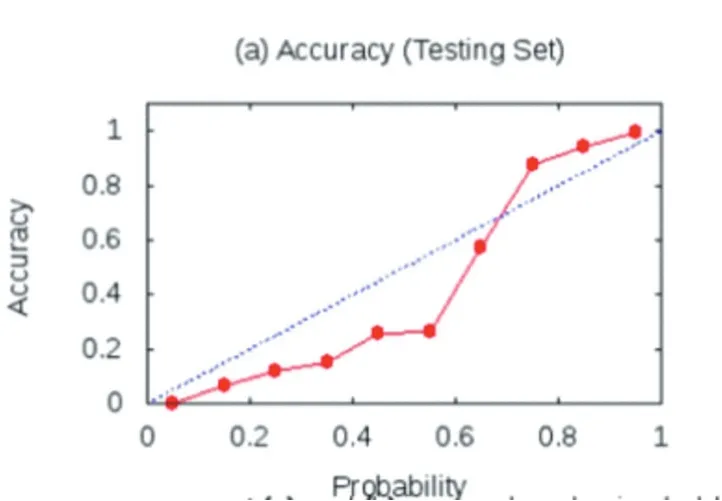
图5 测试集正确率图
图6中的两个图分别为测试集和训练集的总预测数。理想情况下,这些图应遵循左高右低的U形曲线。图中横轴表示实体对具有发生关系的置信度,纵轴表示具有这种置信度的实体对数量。由图6(1)、6(2)可以看出本实验结果符合正确预测,由于引入远程监督方法产生大量噪声数据使得生成大量置信度为0的实体对,在后续步骤中使用启发式规则很好地去除了此类噪声数据。
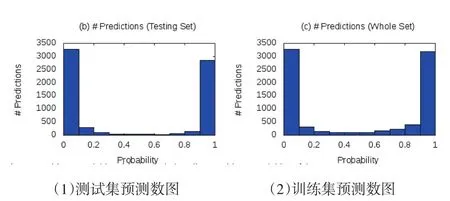
图6
在本实验中,2418篇文章抽取的8054对实体对中,包含大量因远程监督和笛卡尔积运算产生的噪声数据,由图6(2)可以看出系统预测出较多置信度为0的实体对,这其中有较大一部分为噪声数据。通过分析实验计算得到数据精确率(P)、召回率(R)、F值如表4。可以看到,本实验P、R、F值均在85%以上,由此可以得出本文所提方法,适用于煤矿领域“发生”关系抽取。

表4 P、R、F表
3 结语
本文基于特征向量对煤矿领域实体关系进行抽取,为构造煤矿领域的知识图谱做好了前期准备,通过编写爬虫及数据清洗脚本,结合本实验所需信息特征,从大量数据中准确获取有用信息。在训练数据的过程中结合远程监督以及启发式规则提高抽取结果的准确率,降低噪声数据对抽取结果的影响。最后基于因子图模型推理出候选实体对具有“发生”关系的边界概率,实验结果表明,本文提出的算法具有较高的准确率,适用于煤矿领域“发生”关系的抽取。
本文对于煤矿领域只抽取了“发生”这一种关系,实际上煤矿领域具有价值的关系还有“责任”、“因果”和“分类”等,如何一次抽取实体间的多种关系是下一阶段的研究方向,在此基础上,构建一个完整的煤矿领域知识图谱。
