基于VGG-19混合迁移学习模型的服饰图片识别
2019-01-21唐浩漾孙梓巍
唐浩漾, 孙梓巍, 王 婧, 钱 萌
(西安邮电大学 自动化学院, 陕西 西安 710121)
网上购买服饰产品已成为人们日常生活消费方式之一,服饰图像的分类和识别技术也在不断发展。传统的服饰图像识别方法往往是设计特征提取算子对图像特征进行提取[1-2],如文献[1]利用局部二值模式(local binary patterns,LBP)和颜色直方图方法提取服饰图片的纹理和颜色特征,将图像划分成多个局部区域并添加位置信息。文献[2]对服饰图片进行分割后,利用图像的尺度不变特征变换(scale invariant feature transform, SIFT)提取服饰图片的局部特征,如纹理和颜色特征,利用支持向量机(support vector machine, SVM)分类器分类。这些识别与分类方法需要人为设置某种特征来训练分类器,分类器的好坏取决于人为设置的特征是否合理,该方法不具有客观性[3]。
深度学习技术能够较好地解决图像特征提取的问题[4],基于深度神经网络(deep neural network, DNN)和卷积神经网络(convolutional neural network, CNN)的方法已被广泛地应用于图像识别中[5-7]。文献[8]将预训练的模型进行微调后,获得类哈希的图像特征表示,再通过层级深度搜索进行图像分类。文献[9]通过深度神经网络,利用余弦相似度进行跨场景的服饰图片识别。但是,这些方法需要通过试探性的实验搭建网络模型,且需要更新模型中大量参数才能使模型达到最优[3]。通过迁移学习的方式可以有效地解决新模型的搭建和参数调整的问题[10-12],文献[10]提出了一种基于迁移学习的图像识别方法,从源数据集上对卷积神经网络进行预训练,然后,将卷积层参数迁移至目标数据集后再训练。这种方式能够有效地迁移卷积低层特征的提取能力至目标数据集,却忽略了高层卷积层的语义性[13]。
本文拟提出一种基于视觉几何组19(visual geometry group-19, VGG-19)混合迁移学习模型的服饰图片识别算法,利用卷积神经网络特征提取能力,将源数据上的VGG-19模型卷积层参数迁移至目标数据模型,再通过稀疏自动编码器(sparse auto encoder, SAE)无监督学习得到数据特征的简明表达,最后,使用softmax分类器对服饰图片进行分类。
1 VGG-19网络模型
1.1 VGG-19网络拓扑结构
使用VGG-19卷积神经网络为预处理模型。相比于传统的卷积神经网络,VGG-19在网络深度上进行了提升,采用多个卷积层与非线性激活层的交替结构,比单一卷积层结构能够更好地提取出图像特征。
VGG-19的网络结构,如图1所示。
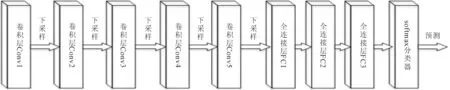
图1 VGG-19的网络结构
如图1所示,VGG-19主要由5段卷积,5个下采样层以及3个全连接层组成,每段卷积内有2至3个卷积层,其中卷积核大小均为3×3,卷积步长为1。
使用maxpooling进行下采样,修正线性单元(rectified linear unit,ReLU)为激活函数。3个全连接层的节点个数分别为4 096、 4 096、 1 000。输入图像大小为224×224,网络最后一层为1个softmax回归分类器,对输入的图片用概率进行分类。
1.2 网络的卷积层与激活函数
卷积神经网络中用卷积层模拟视觉通路的特性,通过不同的卷积核对图片进行卷积操作以得到不同特征的响应。设网络中第l层第j个特征图[6]
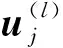
为了增加整个网络的非线性映射能力,需要向网络中加入激活函数,VGG-19网络中使用ReLU作为激活函数,能够有效的改善深层网络在反向传播时梯度饱和的问题,激活函数[6]
f(x)=max(0,x)。
激活函数图像,如图2所示。
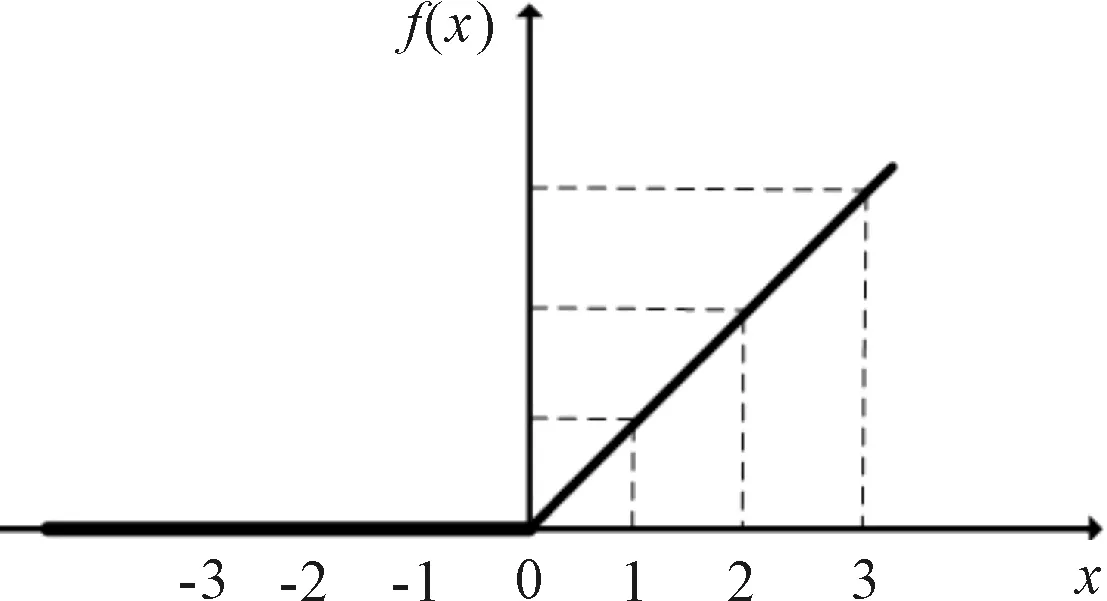
图2 ReLU激活函数
1.3 网络的下采样层和全连接层
下采样层主要用来提升网络对图像的抗畸变能力,同时保留样本的主要特征并减少参数个数。VGG-19网络中采用最大池化(maxpooling)作为下采样函数,即选取改图像区域中最大的值作为该区域池化后的值。下采样层的表达式为[6]
网络在连续堆叠卷积层、下采样层之后,一般连续有多个全连接层。全连接层将卷积层输出的二维特征图转化成一维向量,再根据此向量利用softmax回归分类器实现最终的分类。
2 基于VGG-19混合模型的迁移学习
采用ImageNet数据集[14]作为源数据集,该数据集数据量丰富,训练得到的模型泛化能力强,能够从中提取出丰富多样的边缘特征、纹理特征和局部细节特征,可通过迁移学习识别服饰图片。
2.1 混合迁移学习模型
混合迁移学习模型主要由卷积层、下采样层、稀疏自动编码器和softmax分类器构成,如图3 所示。
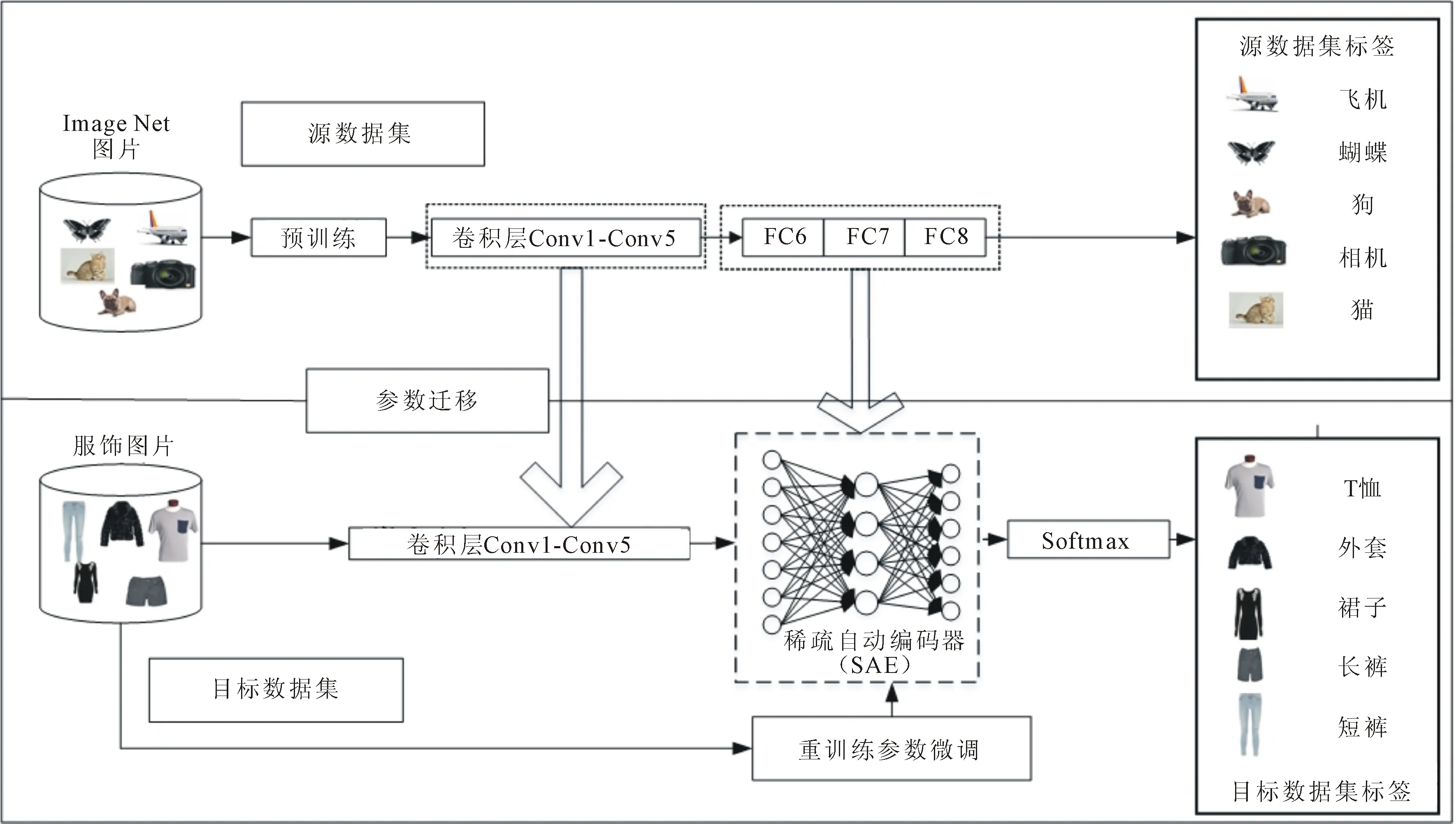
图3 混合迁移学习模型示意图
如图3所示,卷积部分参数为迁移得到的VGG-19预训练的参数,将卷积层最终输出的512个特征图串联为一个大小为512×3×3的特征向量输入到SAE中。SAE的第一层网络共有3 072个神经元,为了起到数据压缩的作用,隐含层为1 500个神经元,最后一层为3 072个神经元。如果需要对5种不同类别的服饰进行分类,则softmax为5个神经元。
对VGG-19网络进行预训练,即可得到迁移的卷积层参数,此方式能避免大量参数调整。
2.2 VGG-19网络模型预训练
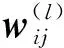
假设源训练集中共有m个样本,单个输入样本为(x(i),y(i)),x(i)为n维向量,y(i)为样本真实标签,网络模型的整体代价函数为
其中,λ为权值衰减系数,nl为网络总层数,sl为网络第l层节点数,hw,b(x(i))表示网络前向传播时得到的输出值。
(1)
考虑到网络隐藏层中不能直接使用误差函数进行计算,因此,需要借助网络残差实现反向逐层传递[6],反向逐层传递表达式为
(2)
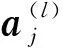
(3)
经过多次迭代,当代价函数值最小时,就完成了源数据集上的预训练,再将得到的卷积层参数迁移至服饰图片数据集上。
2.3 稀疏自动编码器重训练
在参数迁移完成后,由于ImageNet数据集和目标服饰数据集存在一定差异,导致迁移参数的新模型的特征识别力受到影响。所以在特征图输出后再通过稀疏自动编码器进行重训练,稀疏自动编码器不仅全连接了所有特征图的特征,还能将这些特征进行无监督学习,获得更好的高层语义性。
稀疏自动编码器通过无监督的方式进行学习,使输出的特征尽可能等于输入的特征。为了保证隐含层的稀疏性,获得比原始服饰图片数据更好的特征描述,在代价函数J(W,b)中添加一个稀疏性惩罚项,则代价函数[15]变为
(4)
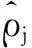
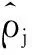
当代价函数建立后,需要将SAE结合softmax分类器实现对服饰图像的分类。在训练softmax分类器的同时,继续将训练残差反向往前传输,使用BP算法进行有监督学习调整SAE网络和softmax的参数。根据式(3),得出稀疏自动编码器的更新量为
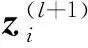
2.4 卷积层参数微调
为了使新模型的卷积层能够更好地提取出服饰图片特征,避免过拟合现象的发生,需要对网络中卷积层参数进行微调。
本文采取逐段冻结的方式进行微调,首先冻结某层参数,则网络残差反向传播时只传播到该层的前一层,更新后面几层的参数,该层参数不更新。整个模型微调完成后,就可以将服饰图片输入至模型进行分类与识别。
3 实验结果与分析
实验采用的计算机配置为I7-7700HQ, 2.8 GHZ,ubuntu16.04操作系统,同时使用NVIDIA Tesla K40显卡加速训练。
实验采用的数据集为DeepFashion数据集[17]中部分服饰图片,从中选取五类图片进行识别,分为T恤、外套、裙子、长裤和短裤,各600张共3 000张图片作为训练集,另外,额外选取每类200张共1 000张作为验证集。考虑到图片大小不同,需先将原始图片进行归一化处理,裁剪为224×224大小送进网络进行训练。将上述数据集输入至模型中,学习率设为0.01,迭代步数设为10 000步,使用TensorFlow作为网络训练框架,批大小设为50。
分别冻结5段卷积时,网络在训练集和验证集错误率的情况,如图4所示。
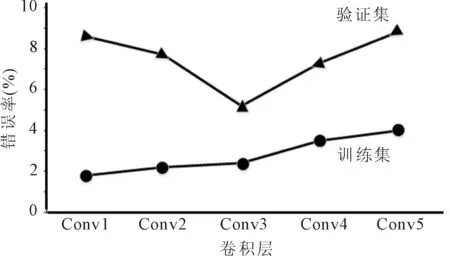
图4 卷积层微调错误率
图4展示了分别冻结5段卷积时,网络在训练集和验证集错误率的情况。当冻结Conv1层时,对后面4段卷积都进行参数更新,可以看出训练集的错误率较低,而验证集的错误率偏高。这是因为服饰图片数据量远小于ImageNet数据集,网络发生了过拟合的现象。当冻结Conv3层时,验证集错误率最低,表明参数更新至本层时较为合适,可避免过拟合的现象发生。
对Conv3层进行冻结时,经过10 000步迭代训练后,模型在验证集上识别率与代价函数值的变化情况,如图5和图6所示。
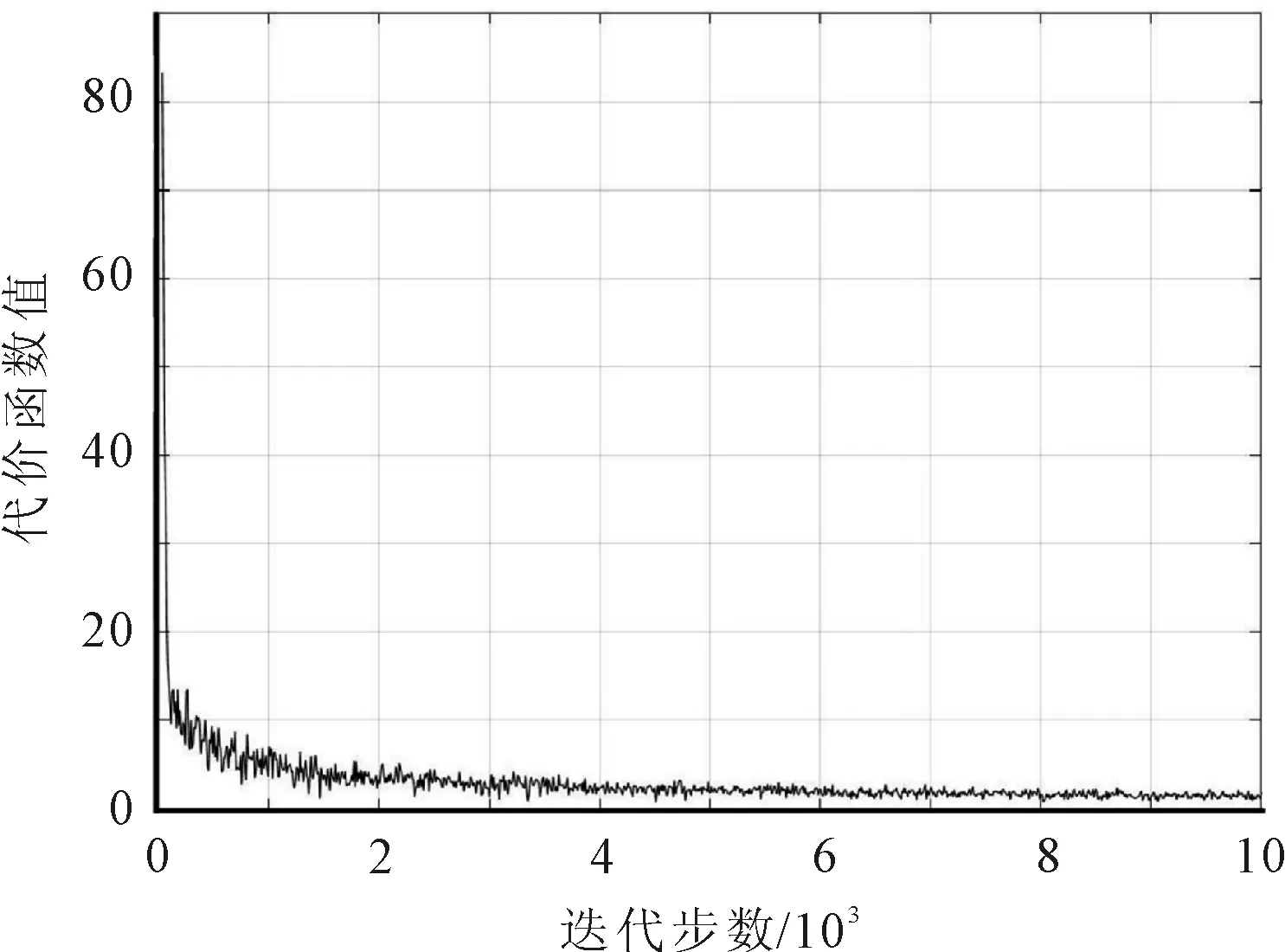
图5 代价函数值-迭代步数曲线
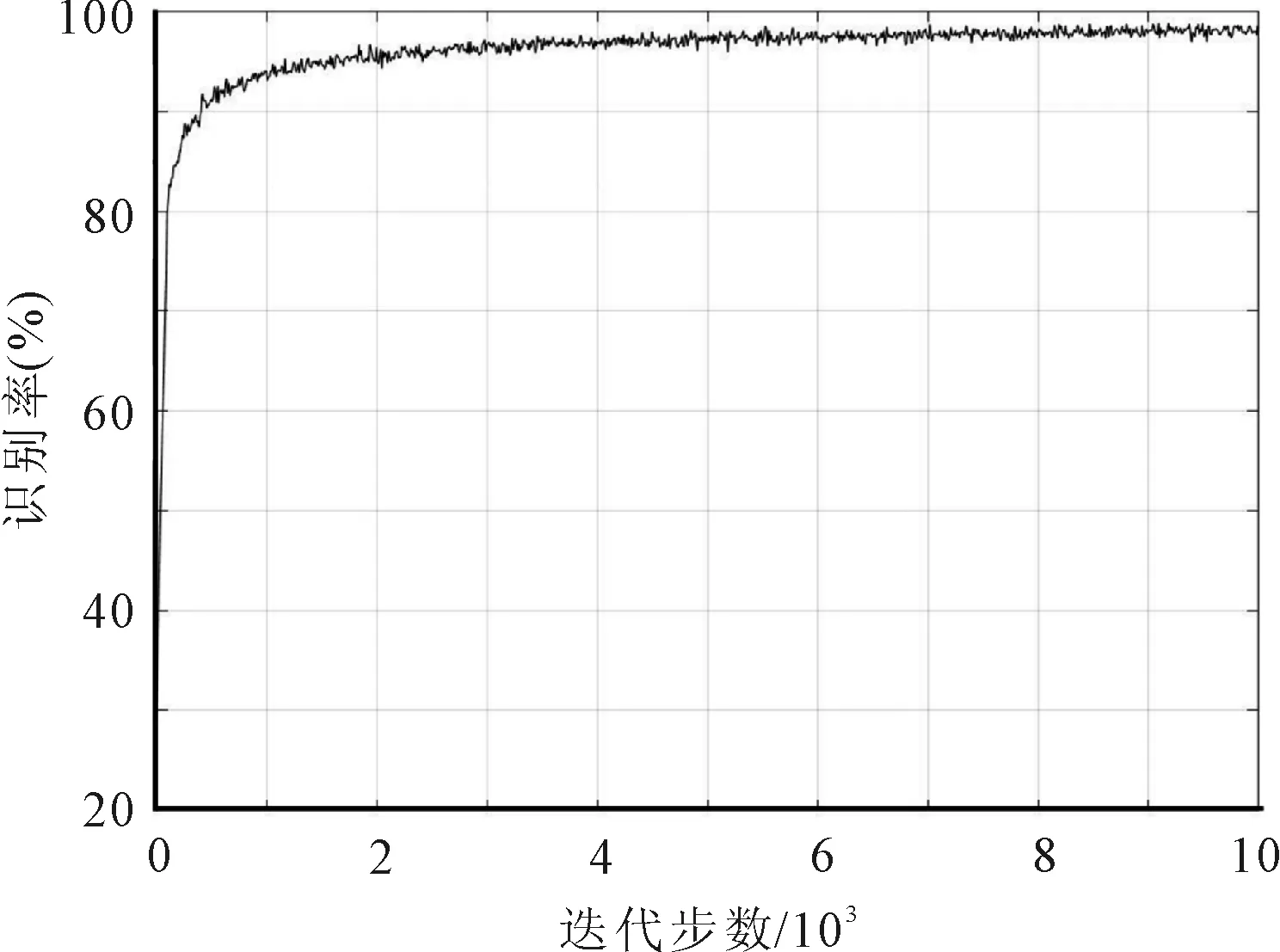
图6 识别率-迭代步数曲线
图5和图6分别展示了对Conv3层进行冻结时经过10 000步迭代训练后,模型在验证集上识别率与代价函数值的变化情况。可以看出随着迭代步数的更新,在前1 000步时,代价函数的数值下降很快,识别率快速提升,这是由于网络进行参数迁移后,参数不用经过多次迭代而能快速满足新模型的性能需求。在8 000步之后,数据的识别率与代价函数值趋于稳定。经过参数的不断更新,最终测试数据集的识别率达到97.2%。5类服饰的识别结果,如表1所示。
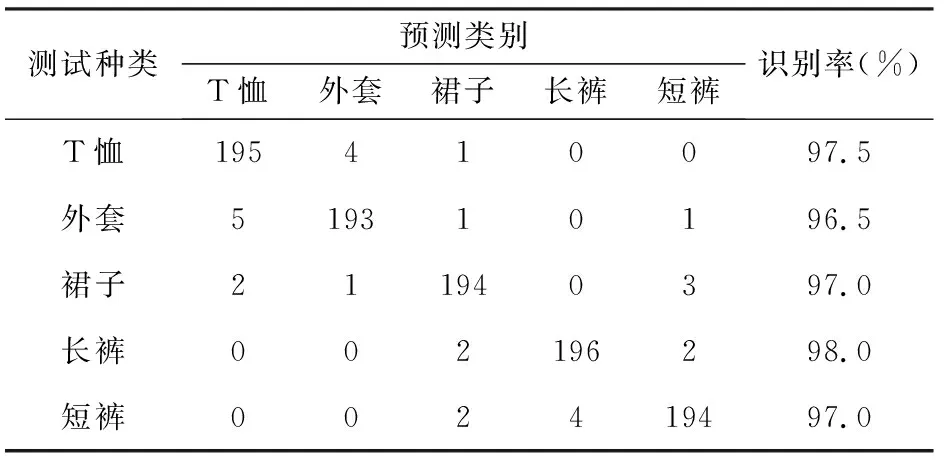
表1 5类服饰图像识别结果
表1为5类服饰的识别结果,可以看出将T恤误识别为外套有4个样本,而并没有误识别为下装类(长裤、短裤)。同样,在对短裤进行识别时,有4个样本被误识别为长裤,并没有误识别为上装类(T恤、外套)。说明该模型对有较大特征差异的数据集可以进行识别。
将本文方法与文献[10]方法的卷积层特征提取进行对比,结果如图7所示。

(a) 文献[10]模型卷积层特征提取
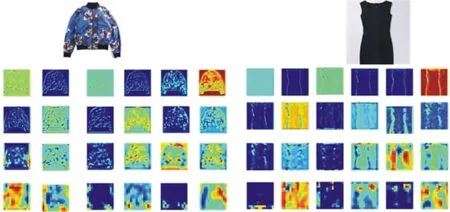
(b) 本文模型卷积层特征提取
图7展示了部分外套和裙子的卷积特征图,可以明显看出,这两种方式在低层时都主要提取的是图片的边缘、纹理、形状等特征。但是通过高层卷积特征图可以发现,本文方法的SAE重训练分类比文献[10]方法所提取的特征更加细微,说明添加稀疏自动编码器能够给出比原始服饰图像数据更好的特征描述,可以提取出潜在的服饰图片信息。
在模型识别性能方面,本文方法与基于SITF-SVM的服饰图片方法[2]、层级深度搜索服饰图片分类方法[8]、通过深度神经网络并利用余弦相似度进行跨场景识别方法[9]和参数迁移后接全连接层的识别方法[10]进行对比,结果如表2所示。
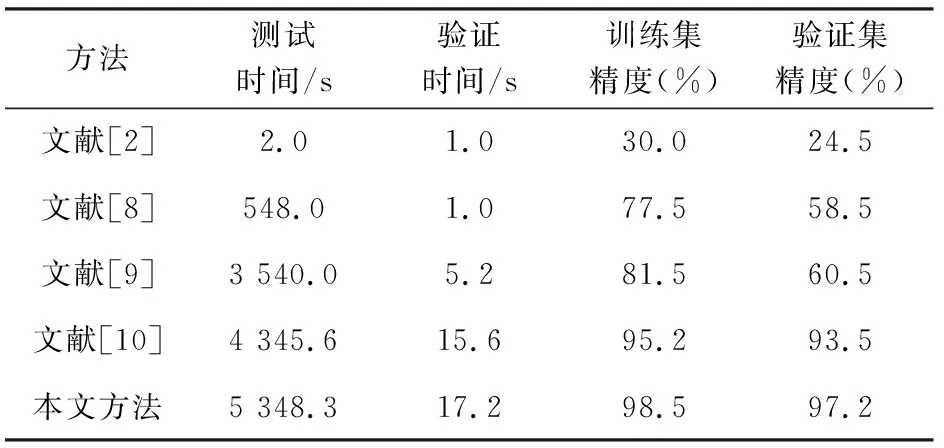
表2 各类方法识别性能对比
从表2可以看出,文献[2]方法在训练时间和验证时间上有很大的优势,但是对于识别的效果却不理想,在验证集上精度只有24.5%,这是由于传统的机器学习方法在图像特征提取时极大依赖于先验知识,而且对数据依赖性很高,需要大量的数据对模型进行训练。
文献[8]方法和文献[9]方法较于文献[2]方法在识别精度上有了明显提升,验证集上精度分别达到了58.5%和60.5%。主要是因为使用了深度模型来代替了人工特征提取的方法,但是,这两种模型依然需要大量数据进行训练才能保证模型的泛化能力。
文献[10]方法相对于文献[2,8-9]方法,能够有效地提升识别精度,但其识别精度低于本文方法。本文方法比文献[10]的精度高3.7%,原因在于,文献[10]中参数迁移后直接连接了全连接层,而本文方法则通过SAE进行了无监督学习的重训练,获得了高层语义性的特征描述,也导致了本文方法测试时间略长。
4 结语
本文提出了一种基于VGG-19混合迁移学习模型的服饰图片识别方法。通过迁移学习和稀疏自动编码器无监督学习结合的方式能够解决迁移过程中数据集差异而带来的特征提取能力降低的问题。实验结果表明,在提取服饰图像特征时,本文方法获得了更好的服饰图片细节特征,对T恤、外套、裙子、长裤、短裤5类服饰识别率达到了97.2%。性能对比实验证明了本文服饰图片识别的精度在训练集和测试集上均较高。
