基于深度学习的ATM机非法改装行为自动识别
2019-01-19易先军周巨罗兵杨锐
易先军,周巨,罗兵,杨锐
(1.荆州市公安局信通科,湖北 荆州 434000;2.五邑大学 智能制造学部,广东 江门 529020)
银行自动柜员机(Automatic Teller Machine,ATM)给人们带来方便的同时,也存在一定安全风险问题,如通过非法改装 ATM 机来盗取用户信息,从而盗取用户资金,造成财产损失[1]. 对于ATM非法改装行为自动识别的研究,最初主要集中在ATM设备本身和资金的安全,以及事后的人工查看发现线索[2]. 本世纪初就提出了基于图像和视频特征的识别方法,但准确率低,处理速度慢[3].随着深度学习理论研究的突破,该技术也被应用到行为识别,但结合 ATM 应用中存在非法行为样本少,难以进行深度学习的困难[4]. 此外,设计的方法通用性差,算法程序难以适应不同视角、分辨率的视频设备 . 为此,本文结合深度学习技术,设计了3D深度网络结构,建立了ATM监控视频样本库,设计了设定输入区域和视频比例调整来适应不同视频设备的差异性,并通过样本库的样本对建立的深度网络进行训练和测试,取得了快速、准确的识别结果.
1 非法改装ATM机的行为特点
非法改装 ATM 机的行为一般是在插卡口上加上一个附加的读卡器,并在键盘上部某个位置安装一个微型摄像头,读卡器盗取用户的卡号信息,摄像头偷拍用户输入的密码. 非法改装ATM机的行为与正常的 ATM 操作行为在行为表现有明显差异. 但将这些行为差异准确描述为计算机可使用的图像或视频特征并不容易.
图1是监控拍摄的非法改装ATM机的视频截图. 多数情况下,嫌疑人还会戴口罩、墨镜等进行面部遮挡、伪装,如图2.

图1 非法改装ATM机视频截图

图2 非法改装ATM机嫌疑人的脸部遮挡视频截图
虽然不同的 ATM 机的视频摄像头型号、角度等会有差异,但非法改装行为在插卡口、机器顶部或键盘上都会有异常行为表现,存在共性特点,虽然人工处理难以选择明显、准确的特征,但深度学习可以通过对大量样本的学习自动产生归类特征[6].
2 基于深度学习的异常行为识别
近十年人工智能、深度学习理论研究和应用技术发展进步迅速,基于视频进行异常行为检测得到深入研究和广泛应用 . 采用深度学习方法,使异常行为检测准确率得到大大提高,可以很好地从图像或视频样本自动学习来提取发现过去人工难以准确描述的类别特征[5].
传统基于图像或视频特征的方法,提取人工特征需要精巧的设计、大量实验尝试来选择图像特征或视频的光流特征等[4-5],识别准确率低,提取的特征依赖于人的经验和尝试,可靠性、准确性都很差[6].
深度学习是对神经网络(ANN)、机器学习的发展. 神经网络可以很好地实现非线性映射、分类等工作,根据经验建立网络结构,通过样本进行机器学习优化网络权重参数,但神经网络存在输入维数不能太高、网络隐层节点数、层数也不能太多、样本不能太多的局限,否则其机器学习将陷入局部最优而无法找到优化结果或过拟合[6]. 深度学习通过多隐层结构、无监督学习聚类的特征发现、监督学习过程中的随机样本抽取、反复迭代等方法使其能够输入更高的维数,可直接输入图像、视频而无需人工提取特征,通过大量的样本学习而达到针对高维数据的准确非线性分类[6]. 因此深度学习方法在有大量样本的基于视频的异常行为识别上得以应用并取得了较好的应用效果[7].
对于 ATM 机前抢劫用户、偷窥输入密码等异常行为,已有学者研发了基于深度学习的识别方法[8]. 这些基于深度学习进行视频中异常行为检测都是利用视频的全视场,如果测试样本与训练样本的摄像机拍摄角度或分辨率存在差异,或 ATM 机型号不同、插卡口位置不同等,训练好的深度学习网络就难以很好地适应这种差异,甚至无法有效识别;而且,网络参数多,训练、识别速度均较慢[6-8]. 为此,本文设计了专门针对视频中插卡口区域的局部视场的视频图像作为插卡口区域异常行为识别. 取视场中顶部区域作为非法安装顶部摄像头异常行为识别网络的输入;取键盘区域作为加装伪键盘的识别输入. 这样用3个深度网络分别识别3种异常行为,分别用各自区域样本进行训练. 3个网络比一个全视场输入网络结构简化,且可以通过人工设定输入区域,可以适应ATM不同机型的差异而无需重新进行机器学习,使建立的网络具有了通用性.
本文研究对于ATM机前非法改装行为的识别,还建立了非法行为视频样本库,针对不同型号、不同分辨率、不同视角摄像头的通用识别方法进行了研究.
3 ATM机非法改装行为识别算法设计
3.1 软件框架
深度学习可以较好地对视频进行异常行为识别,但大数据量的样本库建立与训练以适应不同型号摄像头、不同拍摄角度获取的视频仍然是需要解决的问题. 文献[9]采用正交归一化处理方法,但适应性仍然不足. 本文设计了按指定区域分割视频,分别用于识别插卡口的改装异常行为、顶部安装摄像头异常行为、键盘部位覆盖键盘的异常行为,并检测人脸后利用脸部图像进行遮挡伪装判断.这样,即使摄像头型号、视角的差异,但在插卡口的正常插取卡行为、改装异常行为就更好地形成两类聚类,顶部改装与正常使用 ATM 机行为也较好形成了两类聚类,正常使用键盘与改装键盘的异常行为也形成了两类聚类. 另外,对视频图像进行人脸检测. 检测到人脸后,进行脸部有遮挡伪装的检测判断,可用于进一步的智能监控功能,如防止异常取款交易等. 也可以通过检测到人脸后,再启动非法改装ATM机行为的识别程序. 软件框架如图3所示.
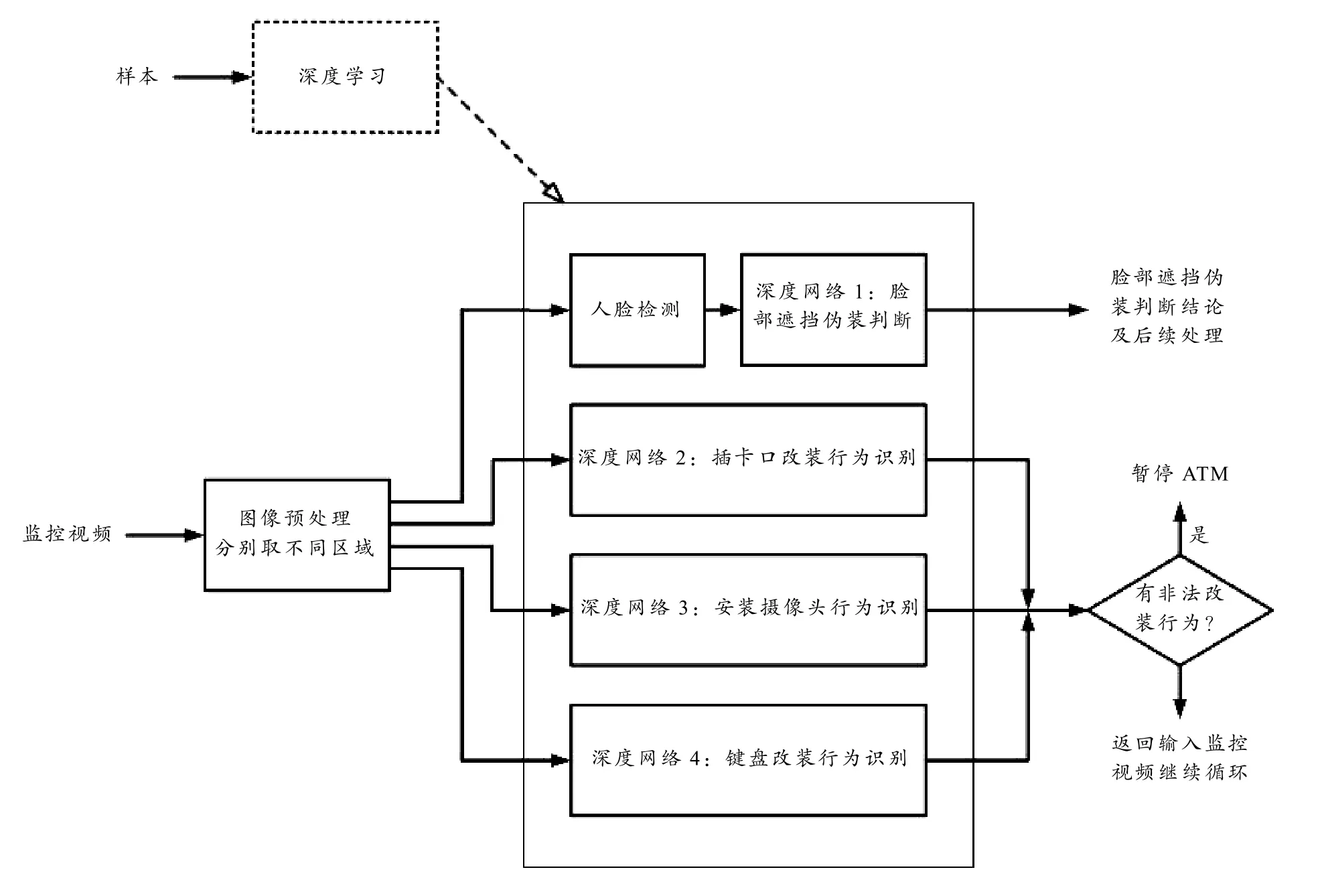
图3 基于视频的ATM机非法改装行为识别软件框架图
图3的软件结构框架中的深度网络2、3和深度网络4的结构如图4所示,均为三维时序卷积神经网络.

图4 三维时序卷积网络结构示意图
图4中的三个时序过渡层由四个并联的可变时序深度的三维卷积层组成,后面再连接一个1× 1× 1的三维卷积层和一个2× 2× 2的平均池化层,这种结构可以更好地利用视频图像多帧图像间的时序信息[8]. 这三个时序过渡层的结构相同,如图5所示.
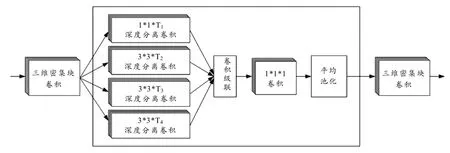
图5 时序过渡层的结构示意图
3.2 样本库的建立
已有的ATM机监控视频收集了大量的正常行为视频,非法改装异常行为视频非常少. 为此,本文采用拍摄模拟非法改装行为来扩充非法改装行为视频.
用各种型号摄像机在多种型号 ATM 机上采集视频,人工模拟非法改装行为:脸部带墨镜、口罩、围巾、头盔遮挡或不遮挡等多种情形;在插卡口模拟各种非法改装动作;在顶部模拟非法加装摄像头;在键盘上模拟非法加盖假键盘等.
这样,收集了10 000个正常使用ATM机的行为视频,收集了3种非法改装行为视频各2 000个,建立了样本库. 随机抽取各100个作为测试样本,其余作为训练样本.
3.3 视频图像预处理
对于输入视频,采用识别前人为设置3个区域:插卡口区域、顶部区域、键盘区域,这样来解决不同ATM型号设备摄像头拍摄角度的差异. 插卡口区域选取宽为240像素点、高为160像素点;顶部区域选取为宽480像素点、高为160像素点;键盘区域为宽160像素点、高160像素点. 这样各区域的像素点数与三个深度网络的输入节点数也一致了. 对不同设备,可人为设置 3个区域的位置,可以根据实际图像区域,拖动长宽比例固定的框、并可按比例调整框的大小.
同时,降低视频数据量. 将视频进行每秒2帧的下采样以减少数据量,然后将3个区域的视频分别送入3个识别三种异常行为的深度网络.
对于不同分辨率的摄像头,深度学习可以适应差异不大的空间差异,但如果分辨率成倍数变化,则可以根据设备分辨率调整参数来进行视频图像的空间采样使视频图像分辨率归一化. 或者通过人为设定输入区域时设定的区域大小自动进行图像采样调整,使3个区域的输入图像像素归一化为设定的3个深度网络的输入节点数.
这样,不同型号与分辨率的摄像头采集的视频,经过预处理后可以得到近似的视频输入效果.
3.4 分区域的异常行为识别
对视频图像进行人脸检测采用 OpenCV的开源人脸检测算法. 然后用检测到的人脸区域图像作为人脸遮挡伪装检测判断的输入. 也可以根据检测到人脸后启动异常行为程序.
对 ATM监控视频分割出的 3个区域:机插卡口处、顶部区域、键盘区域分别建立深度网络以进行各自异常行为的识别. 3个深度网络均采用三维时序卷积网络,使用 Facebook公司的 PyTorch框架实现. 每个深度网络的输入视频分辨率采用 3.3节划分的区域大小像素和时间下采样率,每次输入16帧(即8 s的视频数据).
4 实验结果与分析
用3.2节描述建立的样本库,对3.4节描述的3个深度网络进行深度学习训练和测试. 作为对比,分别用人工特征方法、全视场区域深度学习方法进行异常行为识别对比[4-5].
训练样本总数为15 400个,测试样本数为600个. 训练样本中,正常行为视频9 700个;三类异常行为视频各1 900个. 测试样本中,正常行为视频 300个,3类异常行为视频各 100个. 视频长度均为8 s,每秒24帧.
硬件采用Intel i7-3770 3.4GHz CPU + GeForce GTX 1080 NVIDIA GPU进行训练和识别测试.
用15 400个训练样本,全视场区域视频输入深度学习方法和本文分区域三网络深度学习方法进行训练的时间对比如表1. 对600个测试样本的测试时间对比如表2. 本文方法虽然只有3个深度网络,但输入维数大大减小、网络结构简化、需训练的权值少,所以训练时间减少. 测试时,3个深度网络采用并行处理,因此测试时间也得以缩短.

表1 两种深度学习方法的训练时间对比

表2 两种深度学习方法的平均测试时间对比
表3是人工特征方法、全监控区域视频输入深度学习方法和本文分区域三深度网络识别方法对600个测试样本的识别准确率对比.

表3 3种识别方法对测试样本的识别准确率对比 %
从实验结果可以看出,分区域分割视频进行不同异常行为识别,使得聚类效果更明晰,深度学习效果更好.
5 总结与展望
基于ATM机监控视频可以很好地自动识别非法改装ATM机的异常行为. 通过对插卡口、顶部、键盘3个区域分别人为划定固定长宽比例的区域,将3个区域的视频分别用3个三维时序卷积深度网络进行识别,使得识别精度大大提高、训练时间和识别时间均得以缩短,而且可以适应不同型号ATM机分辨率、视角位置差异的摄像头采集的视频.
本方法由于输入8 s时长视频,所以存在大约9 s的延时. 另外,对于不同视角的视频,没有对视角差异太大的视频进行实验. 进一步将本系统集成到 ATM 机并进行总体控制是还需要深入研究开发的内容.
