基于改进OPTICS聚类的雷达信号预分选方法
2019-01-19吴连慧周秀珍宋新超
吴连慧,周秀珍,宋新超
(中国船舶重工集团公司第七二三研究所,江苏 扬州 225101)
1 概 述
雷达信号分选是由多部随机交错的脉冲信号流分离出各单部雷达辐射源脉冲的过程[1]。雷达信号分选分为预分选和主分选。传统的雷达信号预分选一般采用小盒法[2]。小盒法简单易行,但是由于采用固定容差的方式,聚类形状固定,容易引起边界效应,造成增批和漏批现象[3]。
聚类分析[4]是数据挖掘中的重要技术,基本思想是根据数据对象之间的相似性,将数据样本分成不同的簇,使得同一簇内差异尽可能小,不同簇中差异尽可能大。利用聚类分析可以弥补传统预分选方法的不足。
文献[5]提出了一种改进的DBSCAN聚类分选方法,减少了参与聚类运算的数据个数,提高了未知雷达信号的聚类分选速度。然而由于DBSCAN对参数敏感,使得该方法不能有效作用于密度差异较大的雷达信号。文献[6]提出了一种基于近类点和模糊点的未知雷达信号分选算法,能够发现密度不均匀的聚类,但分选速度有待提高。
针对以上不足,本文结合雷达信号本身各参数的特点,采用基于密度的OPTICS算法,并进行网格单元划分,采用两级处理,缩短运行时间。这是一种能够克服边界模糊效应,得到任意聚类形状的雷达信号预分选方法。
2 OPTICS算法及预分选过程
OPTICS算法是一种由DBSCAN算法发展而来的密度聚类算法[7-8],引入了核心距离和可达距离的概念。通过建立增广数据集排序(可达图)[9]来表示它基于密度的数据结构,可达图可以看作一系列参数设置的基于密度的聚类[10-11]。
使用OPTICS算法进行雷达信号预分选的核心思想是:从一个随机选定的脉冲出发,朝着脉冲最为密集的区域扩张,最终将所有同类的脉冲组织成可视化有序序列。
基于OPTICS聚类的雷达信号预分选过程如下所述。
输入脉冲数据集{vi},i=1,2,…,N,其中vi为脉冲描述字(PDW)中载频(RF)、到达角(DOA)、脉宽(PW)构成的三维空间,N为总脉冲样本个数。
欧式距离计算。设置ε为半径,MinNp为同一聚类的最小脉冲数,计算每个脉冲样本vi与脉冲数据集所有样本的欧式距离公式如下:
(1)
式中:j=1,2,…,N;fri代表vi的RF特征量;doai代表vi的DOA特征量;wpi代表vi的PW特征量。
核心距离计算。用Nε(i)表示d(vi,vj)中距离小于半径ε的脉冲样本数。若|Nε(i)|≥MinNp,即半径ε内脉冲样本数超过最小脉冲数门限,则vi为核心对象。脉冲样本vi的核心距离是指vi成为核心对象的最小εi′。如果vi不是核心对象,那么vi的核心距离没有任何意义。核心距离为:
(2)
式中:MinNp是自然数,MinNp-d(vi)表示vi到其最邻近的MinNp个邻接点的最大距离。
可达距离计算。脉冲样本vj到脉冲样本vi的可达距离是指vi的核心距离εi′和vi与vj欧式距离之间的较大值。如果vi不是核心对象,vi和vj之间的可达距离没有意义。可达距离公式:
dr(vi,vj)=
(3)
核心距离和可达距离示意图如图1所示。已知半径ε,最小脉冲数MinNp=4。A的核心距离为ε′(A)=d(vA,vB),C到A的可达距离dr(vA,vC)=εi′(A),D到A的可达距离dr(vA,vD)=d(vA,vD)。

图1 核心距离和可达距离示意图
有序种子队列建立和结果队列生成。将待处理的脉冲样本按照可达距离升序排列得到有序种子队列,总是选择可达距离最小的脉冲进行处理,使得聚类朝着脉冲最为稠密的区域扩张。直到处理完当前稠密区域,才会探索稀疏的边界,进入下一个稠密区域。根据有序种子队列,生成结果队列,用以存储聚类结果。
脉冲聚类标记数组{mi}的获得。通过识别结果队列中陡峭下降沿和上升沿区域来提取聚类,得到脉冲聚类标记数组:
(4)
式中:k=1,2,…,K,表示聚类个数,如图2所示。
脉冲聚类通道划分。根据聚类标记数组{mi},将脉冲数据集{vi}进行分类,送往聚类缓冲区中聚类号所对应的通道中,从而实现信号预分选。
图2 聚类通道缓冲区示意图
3 OPTICS算法改进
由于DBSCAN对参数敏感的特点决定了该方法不能有效作用于簇密度差异较大的脉冲数据集中,继而不适用于复杂体制雷达的信号分选。OPTICS算法虽然在一定程度上克服了DBSCAN对参数的敏感性,但是应用到信号分选中存在着一些不足之处。当脉冲密度过大时,处理时间比较长。
本文提出一种网格化的思想:将RF、DOA和PW划分成网格单元,以网格的质心代替网格中数据点的集合[12],将落在某个单元中的脉冲个数当成这个单元的密度。最后,利用OPTICS算法输出簇排序的可达图。由于脉冲集合有效压缩,因此使得算法运行速度得到提高。
3.1 网格单元划分
设网格单元RF分辨率为Δfr,DOA分辨率为Δda,PW分辨率为Δwp。输入脉冲数据集{vi},i=1,2,…,N,其中vi为脉冲描述字(PDW)中载频(RF)、到达角(DOA)、脉宽(PW)构成的三维空间,记作vi={fri,doai,wpi},N为总脉冲样本个数。

(5)
式中:Cntl为单元内的脉冲个数;SRFl为单元内所有对象的RF之和;SDOAl为单元内所有对象的DOA之和;SPWl为单元内所有对象的PW之和。
将网格单元中有脉冲(Cntl>0)的单元格取出来,生成压缩后的脉冲数据集{wm},m=1,2,…,M,对应脉冲数{cntm},m=1,2,…,M,其中wm={frcm,doacm,wpcm},M为压缩后的网格单元数。相关参数对应公式(5)。
(6)
式中:frcm,doacm,wpcm,cntm分别为第m个有脉冲(Cntl>0)的单元格的载频质心、方位质心、脉宽质心和单元格脉冲数。
对压缩后的脉冲数据集进行OPTICS算法处理,计算核心距离和可达距离时,考虑计数值的影响。
网格单元脉冲数生成示意图如图3所示。图3左侧表示原始脉冲的RF和DOA关系,进行网格单元划分后,记录每个单元的质心和脉冲数,如图3右图所示。

图3 网格单元脉冲数生成示意图
3.2 两级OPTICS网格单元处理
针对密度不均的雷达信号分选,当信号环境存在噪声时,采用网格单元划分的OPTICS算法对高密度分选有效,但对低密度信号效果不明显。本文提出一种两级OPTICS网格单元处理方法。基本思想是:一级OPTICS网格单元处理,将高密度信号分选处理,并进行网格过滤;将低密度信号和噪声流入第二级处理,进一步累积,若为低密度信号,继续累积存在一定的规律,若为噪声,则继续累积也没有规律。图4为两级OPTICS处理示意图,网格颜色越深,表示脉冲数越多。
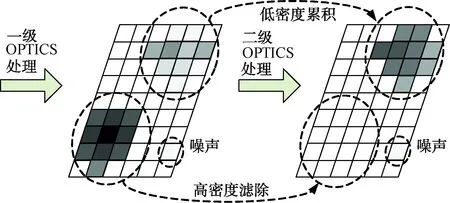
图4 两级处理示意图
4 仿真实验与分析
为了验证聚类算法的有效性,本文进行仿真实验。
4.1 OPTICS聚类实验
雷达参数设置如表1所示。
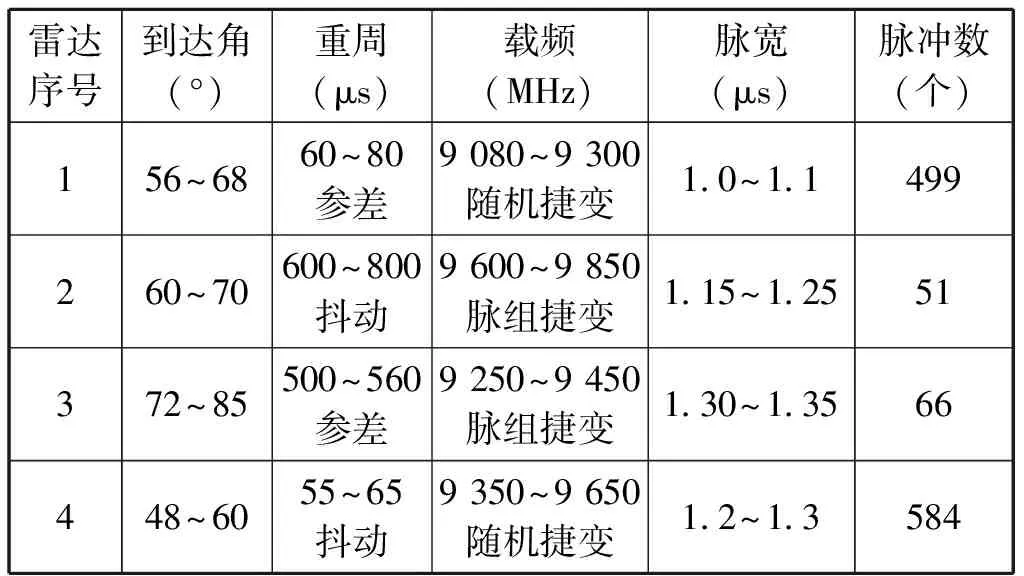
表1 雷达参数信息表
从表1可以看出,不同属性维度上4部雷达都相互混叠,相同时间内,雷达1和雷达4脉冲数多,雷达2和雷达3脉冲数少。采用DBSCAN聚类进行雷达信号分选,若ε设置偏小,则分选出雷达1和雷达4,而认为雷达2和雷达3是噪声,没有分选成功;若ε设置偏大,能够分选出雷达2和雷达3,但雷达1和雷达4合并成一批了。
采用OPTICS聚类进行雷达信号预分选可达图如图5所示。通过识别结果队列中陡峭下降沿和上升沿区域,可以看出共有4部信号。每部信号对应的脉冲数与设置相同。
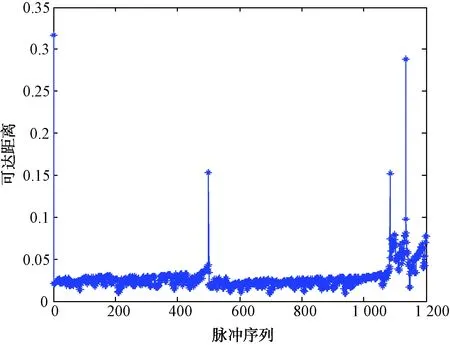
图5 OPTICS聚类的雷达信号预分选可达图
4.2 网格单元划分实验
对表1脉冲进行网格单元划分,将脉冲依次添加到网格单元中,计算出单元的质心和脉冲数。图6以RF-DOA网格单元划分为例,高度为脉冲数,高度越高表示脉冲数越多。

图6 RF-DOA网格单元划分
图7为采用网格单元划分的OPTICS聚类的雷达信号预分选可达图,可以看出同样分为4部信号。
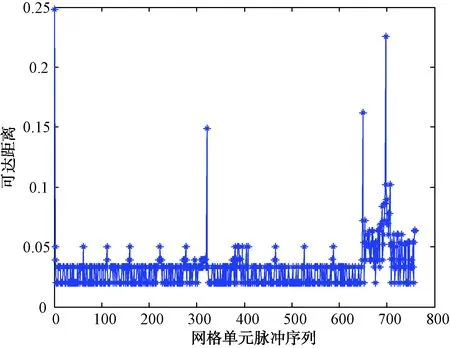
图7 网格单元OPTICS聚类的雷达信号预分选可达图
4.3 噪声情况下两级处理实验
根据表1的辐射源参数产生雷达脉冲数据流,对前1 200个脉冲分别进行OPTICS聚类和改进OPTICS聚类,表2为2种算法在不同噪声情况下的分选正确率。可以看出,高密度信号分选正确率受噪声影响小;在噪声情况下,通过网格划分和两级处理,低密度信号的分选正确率有效提高。

表2 不同噪声情况下的分选正确率
对表1信号分别选取1 200,2 000,5 000,8 000,10 000个脉冲,对比传统OPTICS聚类和本文改进OPTICS聚类的运行时间,随着脉冲数的增加,传统OPTICS聚类时间增加明显,而改进OPTICS聚类时间增加较少,大大减少了运行时间,如图8所示。

图8 不同输入脉冲数情况下运行时间
5 结束语
由于在DBSCAN算法中,变量ε,MinNp是全局唯一的,当空间脉冲密度不均匀时,聚类质量较差。为了克服在聚类分析中使用一组全局参数的缺点,提出了OPTICS聚类的雷达信号预分选方法。同时采用网格单元划分来提高聚类速度。实验结果表明,与传统的DBSCAN算法相比,改进OPTICS算法适用于不同密度分布的雷达信号,从而提高了复杂体制雷达信号分选的正确率,同时降低了算法运行时间。后期为了进一步提高分选正确率,可以将固定网格划分变成自适应网格划分[12]。
