IPoIB在国产并行系统上的实现与优化①
2019-01-18陈淑平何王全
李 祎, 陈淑平, 何王全
(江南计算技术研究所, 无锡 214083)
最新公布的HPC top 500显示, 有207台超级计算机使用以太网作为互连网络, 这表明TCP/IP是广泛使用的网络协议. 但随着众多学科领域对网络性能需求的不断提升, TCP/IP协议中频繁数据拷贝、复杂协议处理机制和中断上下文切换逐渐成为数据传输瓶颈.而IB[1](InfiniBand)相比传统以太网具有高带宽低延迟的通信性能优势, 更能满足上层应用需求. 将IB网络与传统以太网结合, 可以同时利用两者优势以满足不同的网络需求, 这是当今网络融合趋势下的一种研究方向, 其中IPoIB[2](IP over InfiniBand)和SDP实现了在IB网络之上对TCP/IP协议的支持, iWarp和RoCE实现了在以太网上对RDMA (Remote Direct Memory Access)传输技术的支持. 这几种技术和传统的TCP/IP协议相比, 均能获得更高的网络性能, 且各有优势, 使用者可以根据具体应用场景选择合适的技术.
IB是一种高性能、低延迟的基于通道的高速互连结构标准, 支持RDMA技术, 具有零拷贝以及CPU负载卸载的特点, 能够有效减少系统CPU和内存的开销,提高网络吞吐量并降低网络延迟. IPoIB是一种在IB网络之上构建TCP/IP的技术, 隐藏IB网络的复杂性, 使得TCP/IP 应用程序可以不加修改地在以IB协议为基础的网络之上运行, 同时还能利用IB网络特有的优势以获得更好的网络传输性能[3]. 目前IPoIB主要应用于商用x86集群服务器中, 官方维护组织OFED不断地从数据处理、网络管理、服务支持等角度对IPoIB进行优化更新, 但尚未有将IPoIB应用于国产众核服务器系统中的实例.
众核处理器具有计算能力强、性能功耗比高等突出优点, 异构众核架构已成为当前超级计算机体系结构的重要发展方向. 本文基于“国产异构众核并行系统”展开, 对IPoIB进行移植, 并在已有优化方法上研究进一步提升IPoIB网络性能的手段, 对于支持TCP/IP应用具有重要的意义.
文章的后续部分组织如下: 第1节介绍国产并行系统平台环境, 第2节给出相关工作介绍, 第3节简要介绍IPoIB的实现, 第4节详细阐述IPoIB在国产并行系统上的优化手段, 第5节是实验结果, 最后对本文进行总结.
1 国产异构众核系统
“国产并行系统”[4]运算单元采用面向高性能计算的众核处理器, 包括Intel的MIC、Nvidia和AMD的GPU、Godson-T、申威众核处理器等. 申威众核处理器包含4个Core-Groups (CGs), 每个CG包含一个MPE(Management Processing Element, 主核)、一个 8*8 的Computing Processing Element (CPE, 从核) cluster和一个Memory Controller (MC), 4个CG通过片上网络(NoC)互连, 处理器通过System interface (SI)连接外部设备. 申威众核处理器的主核和从核共享Memory, 从核采用轻量级的核心设计, 配备由软件管理的高速存储器 SPM (Scratch Pad Memory), 支持通过 DMA(Direct Memory Access)方式在Memory和SPM间批量传输数据.
运算系统采用申威众核处理器构建, 通过中心交换网络和管理网络与存储系统和管理系统连接, 系统的登陆界面和存储空间采用单一映像组织, 为用户提供统一的视图.
2 相关工作
数据中心网络一般采用TCP/IP协议并基于以太网技术搭建, 近年来, 为了满足数据中心网络对高带宽、低延迟、低能耗的需求, 减少TCP/IP协议处理对CPU产生的负担, 业内研究者重点着眼于TCP/IP协议卸载技术. TOE (TCP卸载引擎)技术利用硬件分担CPU对TCP/IP协议处理所造成的负担, 将协议的处理放到网卡专用硬件中, 使CPU占用率大幅下降, 带宽性能也有一定提升, 但由于网卡和主机接口的不兼容性和延迟增加的额外消耗, 其发展难以维系.
研究者又从新型高速网络(IB、FC等)与传统TCP/IP协议结合以提升网络性能的角度出发, 提出iWARP、RoCE、SDP等网络融合技术: iWARP (Internet Wide Area RDMA Protocol)[5]是一种在TCP/IP协议栈之上实现RDMA的技术, 实现了远程数据的直接存取, 数据可以直接放入上层协议的接收缓存区, 避免了不必要的内存拷贝, 大大提升了时延和带宽性能, 可用于广域网间RDMA通信; RoCE (RDMA over Converged Ethernet)[6]是一种在以太网数据链路层之上实现RDMA的技术, 一般建立在无损以太网之上, 和iWARP相比降低了复杂性和部署难度, 简化了管理, 且通信性能比 iWARP 略好[7], 但造价更高; SDP (Socket Direct Protocol)[8]是一种在InfiniBand可靠连接之上实现字节流传输的技术, 利用IB网络中send/receive和RDMA等操作, 为应用程序提供socket套接字接口调用, 与传统TCP/IP相比, 拥有协议卸载、旁路核心、零拷贝的特点, 与IPoIB相比, 更好地利用了IB网络的高速通信能力, 但由于SDP需要另外搭建socket库且难以进行网络管理, 已逐渐被淘汰.
IPoIB作为在IB中兼容TCP/IP应用的主要技术,其性能优化一直是研究热点, 研究人员从IPoIB的多个方面对其进行了数据处理方面的优化探索: 包括支持LRO、aRFS、RSS、TSS等CPU负载卸载技术、优化中断处理流程、实现隧道卸载、利用多个pkeys实现VLAN等, 实现了IPoIB在多数据流多处理器下的性能提升.
上述工作都是关于网络融合技术在商用平台上的研究进展, 目前在国产系统上尚未有网络融合技术的应用. 本文做了一种新的研究尝试, 将IPoIB协议应用到国产并行系统中, 对移植后的IPoIB进行性能测试和评估, 并且使用一系列优化方法来提高IPoIB在国产并行系统中的通信性能.
3 IPoIB在国产并行系统上的实现
IB是IBTA提出的一种基于通道的高速互连结构标准, 可提供低延迟、高带宽的数据传输能力, 在HPC领域具有广泛的应用. 它采用RDMA编程语义,为用户提供IB verbs编程接口, 但其语义和编程方法与Socket编程语义有非常大的差异, 传统的TCP/IP应用不能在其上直接运行. IPoIB解决了该问题, 它将HCA卡虚拟成网卡设备, 使通用的TCP/IP 应用程序不加修改地在IB网络中运行, 拓展了IB应用领域及范围.
3.1 IPoIB协议原理
图1给出了IPoIB协议架构. IPoIB协议位于内核层, 处于TCP/IP协议栈之下、IB传输层之上. 用户层应用程序调用socket套接字接口将数据送进内核层TCP/IP协议栈, IPoIB 通过注册net_device结构以及一系列设备操作函数为上层TCP/IP协议或ARP协议提供网络设备传输接口, 设备操作函数利用IB的诸多verbs: QP (Queue Pair)队列对、CQ (Completion Queue)完成队列以及MR (Memory Regions)地址空间注册信息等与远程节点交互, 通过IB的send/receive操作实现数据传送接收及处理. 可以将IPoIB看作为以太网的数据链路层.

图1 IPoIB协议架构图
IPoIB分别利用两种IB服务进行数据传输, 其中RC (reliable connected)是面向连接的可靠传输服务, 最大可发送2 GB大小的数据; UD (Unreliable Datagram)是不可靠的数据报服务, 一次最多发送4 KB数据.
IPoIB主要实现下列功能: (1)地址解析: 将IB地址信息编码进MAC地址, 通过ARP获取目的方MAC 地址, 进而获得 QPN (Queue Pair Number)、LID等IB地址信息; (2)报文封装: IPoIB为IP报文添加4字节的链路层包头, 并封装成一条IB消息, 通过IB网络发送给远程节点, 完整的IPoIB 数据包如图2所示; (3)多播支持: IB多播在IPoIB中起关键作用, ARP协议必须通过IB多播实现. IPoIB定义了多播GID和对应的多播组, 并启动多播组任务处理组播列表的变化、响应多播请求, 使节点自由加入多播组或从多播组中删除.
3.2 IPoIB协议实现方式
图3为IPoIB数据包在协议栈中的处理流程[9], 包括数据发送和接收过程.
发送过程: 应用程序通过sys_socketcall系统调用进入socket内核层, socket层再通过sock_sendmsg函数调用进入inet_sendmsg函数, 然后调用TCP层发送函数tcp_sendmsg, 该函数在准备好sk_buff结构后调用skb_do_copy_data_nocache将用户数据拷贝到内核层, 然后数据包依次通过IP层、设备驱动层, 最后利用IPoIB驱动中的ipoib_hard_header函数为ip报文添加 4 字节报文头, 然后调用 ipoib_start_xmit函数, 将数据内存地址进行DMA映射, 并通过IB的send操作将数据发送出去.
接收过程: 应用进程调用sys_socketcall系统调用进入内核层, 再通过socket层的接收函数sock_recvmsg进入到TCP层, TCP调用tcp_recvmsg函数接收数据,当没有数据包到来时, 用户接收进程会休眠. IPoIB驱动程序通过NAPI轮询函数ipoib_poll检查是否有数据到达, 并对数据包进行正确性检验, 去掉IPoIB层链路头, 然后通过netif_receive_skb函数将数据依次移交给IP层、TCP层处理. TCP层再通过skb_copy_datagram_iovec将内核层的数据拷贝到用户层缓冲区.

图2 IPoIB数据包格式图
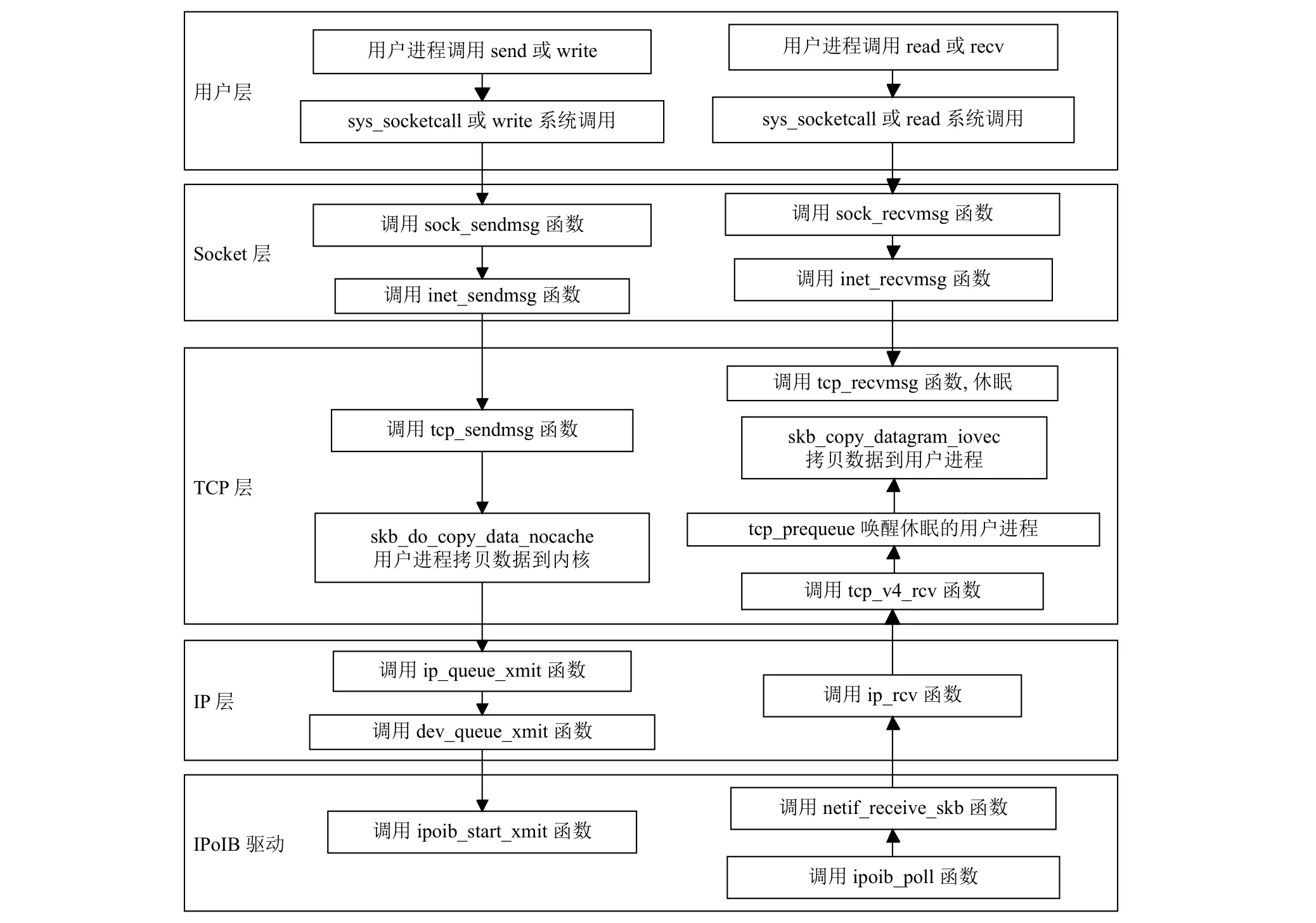
图3 IPoIB数据包协议处理流程图
4 IPoIB在国产并行系统上的优化
IPoIB数据包在TCP/IP协议栈处理过程中会占用较多的CPU时间和内存资源, 主要包括数据拷贝、协议处理机制、延迟应答等3个方面. 数据拷贝包括数据包在网卡和内核空间以及内核空间与用户空间之间的拷贝; 协议处理机制包括复杂的拥塞控制[10]、超时重发机制[11]、TCP协议完整性校验、数据包分发和整合等; 延迟应答可以推迟TCP ACK的发送, 以便使ACK与数据包一起发送. 本章针对国产并行系统上IPoIB的性能瓶颈点, 对这三个方面的处理流程进行了优化.
4.1 乱序处理
非确定性路由中数据包沿不同的路径到达接收端以及数据包在发送单元中调度顺序与到达顺序不一致等因素都会导致接收端产生乱序数据包[12]. 在高速网络中, 发送端的发送窗口很大, 频繁的乱序数据会导致重发大量的数据包, 致使性能大幅下降. 针对乱序数据包对网络性能产生的影响, 提出一种重排序的解决方案: 每对连接发送的数据包都携带一个16位的序列号msg_id, 接收端按照序列号进行重排序, 如果数据包是顺序的, 则直接将该数据包交上层协议栈处理; 如果是乱序的, 则进行缓存. 这种方案的缺点在于若网络中乱序情况严重, 顺序的数据包迟迟不到达, 接收端长时间缓存乱序数据包引起超时, 进而导致上层TCP重传数据, 反而致使性能下降更严重, 得不偿失, 且缓存大量乱序包会消耗过多的系统内存. 为了防止上述现象出现, 采用“尽可能”保序的手段, 规定接收端对数据包进行重排序的窗口长度大小限制在W, 对不在窗口内的数据包不进行乱序处理, 预期序列号next_id始终指向窗口左边界的位置. 具体见如图4所示的乱序处理方法.
窗口长度W的大小设置原则以在一次网卡硬件收包中断发生时, NAPI设备轮询函数所能处理的报文数量上限NAPI_POLL_WEIGHT为参考, 一般为32或64. 这种设置原则是有依据的, 在一些中断处理速度较慢的网卡设备中, 若是窗口长度W超过了一次轮询报文数量上限, 乱序较重情况下, 乱序数据包很可能被缓存较长时间, 直到下一次中断触发处理新到来的数据包, 从而造成网络性能下降.

图4 乱序处理示意图
详细算法描述如算法1.

算法1. 乱序处理算法INPUT:到达接收端的数据包序号msg_id预期序列号next_id←0 BEGIN IF(msg_id=next_id)BEGIN DO{将数据包转交给上层;next_id← next_id+1;}WHILE(next_id位置已缓存数据包)END ELSE IF(msg_id<next_id)将数据包转交给上层;ELSE IF(next_id<msg_id≤next_id+W)暂时缓存数据包;ELSE IF(msg_id>next_id+W)DO{IF(next_id位置已缓存数据包)BEGIN将该数据包转交给上层;END next_id← next_id+1;}WHILE(msg_id>next_id+W)END
4.2 优化内存拷贝
优化内存拷贝是提高IPoIB性能的重要手段. 在图3的IPoIB数据包处理流程走向图的指导下, 逐一查看每个功能模块函数调用的局部时间, 发现RC模式下用户层到内核层数据拷贝速率较慢. 分析发现TCP协议在skb_do_copy_data_nocache函数将用户层数据拷贝进内核层时, 需要对数据进行正确性校验,这会对网络性能造成损耗. 而不计算数据校验和时,内存拷贝速率明显提高. 一般来讲服务器均已实现拷贝内存的“纠单错、报双错”机制, 同时IB也实现了对数据进行校验的功能, 因此本文将RC模式下计算数据校验和的工作由TCP协议转交给IB网卡硬件完成, 从而减少TCP协议计算检验和的工作, 减轻CPU负担, 实现了IPoIB用户层数据到内核层拷贝的优化.
4.3 通过调整网络参数优化协议栈处理流程
网络参数调优是提高IPoIB性能的手段之一, 通过调整内核参数达到提升IPoIB性能的目的.
图5给出了网络参数优化模型. 网络参数按照功能分为以下几类: (1)资源分配: 诸如信道分配、队列大小、缓冲区空间等, 科学合理配置资源可以提高网络的利用率, 有助于IPoIB运行时吞吐量的显著提升;(2)任务调度: 包括中断缓和、传输队列轮询等, 网络任务调度直接影响网络系统的负载均衡, 对IPoIB的平均时延有一定影响; (3)协议运行时设置: ACK应答机制、延时机制、时间戳等, 优化IPoIB的多种协议运行机制, 可以不同程度上提高网络带宽以及网络系统整体性能.
网络参数调优对内核环境影响较小, 但是网络性能提升效果却较为明显. 需要注意的是, 内核参数多种多样, 参数的设置受具体的服务器系统环境影响, 需要根据实际网络应用负载对参数进行适应性调整, 在寻找最优参数中必须分清主次, 突出改善主要参数, 使网络尽可能得到有效利用. 针对具体的输入数据流, 本文利用sysctl命令设置网络参数, 试验了网络参数优化模型中不同的参数变量值和不同的参数组合, 找出能为IPoIB带来性能提升的参数组合及其数值. 根据试验结果, 给出令IPoIB通信性能最优的配置策略: (1)启用tcp_low_latency, 要求TCP/IP栈在高吞吐量的情况下尽量保持低延时; (2) 将rmem_max和wmem_max设为16 MB, 增大TCP连接在发送和接收ACK期间所能处理的最大数据包, 从而减少传输等量数据过程中处理ACK所用时间; (3) 将tcp_rmem和tcp_wmem中的max值设为16 MB. 目的在于增大socket发送和接收缓冲区内存空间, 使一块内存空间存放尽量多的数据, 减少为数据分配多个内存块的管理开销, 优化数据传输流.

图5 网络参数优化模型图
4.4 避免应答延迟(Delayed ACK)
TCP采用应答延迟机制时, 如果当前时间与最近一次接收数据包的时间间隔小于延迟应答超时时间,则会推迟ACK应答的发送, 积攒多个应答并将它们结合成一个响应包, 与需要沿该方向发送的数据一起发送, 从而减少协议开销. 然而, 在应用程序进行交互处理时, 延迟ACK应答时间过长可能会降低应用程序的效率. TCP协议中利用宏定义TCP_DELACK_MIN控制最小延迟确认时间, 一般默认值为(HZ/25), 也就是40 ms. 本文在不改变其它参数的情况下, 逐一试验在1 ms~40 ms范围内不同的 TCP_DELACK_MIN 值, 并测试网络最大带宽, 发现最小延迟应答时间设为5 ms左右时, 网络带宽可以达到最大, 既能维持较低协议开销, 又可以减少TCP传输中ACK的等待时间, 使得网络带宽最大化, 提升内存的利用率. 最佳的延迟应答时间受服务器系统环境和网络应用场景的影响, 本文所得结果在其它集群系统中可能不是最优, 但其试验方法具有普适性.
5 实验结果
本文在国产异构众核系统上对IPoIB进行测试,配备32 GB内存, 节点间采用40 GB/s的Infiniband EDR网络连接. 网络性能测试工具选用Netperf-2.4.5和Iperf-2.0.2. Netperf主要用于记录两对联节点间TCP单连接带宽、延迟、CPU利用率、内存等资源的占用情况, Iperf用于记录两对联节点之间TCP多连接带宽.
5.1 优化效果分析
5.1.1 不同消息大小带宽对比
利用Netperf工具测试两对联节点间单个TCP连接优化前后不同消息大小带来的带宽变化, 结果如图6所示.
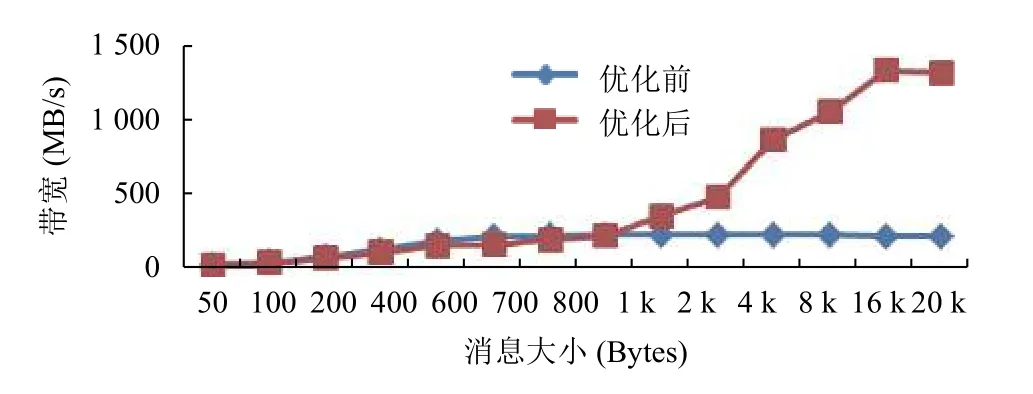
图6 不同消息大小带宽对比图
从图6可以看出, IPoIB通信性能优化效果良好,优化后的IPoIB网络带宽明显高于优化前. 由测试数据可知, 优化后的峰值带宽达到1340 MB/s, 对比优化前的227 MB/s提升近6倍. 可见针对IPoIB的优化对带宽具有较好提升效果, 使得系统的IB网络资源得到尽可能的使用, 提升了IPoIB在国产异构并行系统上的运行效果, 证明优化方法足够有效.
5.1.2 多连接带宽对比
使用Iperf测试两节点间多个TCP连接的网络最大带宽, 从2个连接测到10个连接, 如图7所示.

图7 不同连接数带宽对比图
测试数据表明, 连接数为6或7时, 网络带宽达到最大. 优化后的网络带宽可以达到1800 MB/s, 相比单连接最大带宽1340 MB/s提升1.34倍, 相比优化前多连接的网络最大带宽 615 MB/s, 提高近 3 倍. 可以看出, 在多个进程下网络带宽能有较大提升, 主要原因是: (1)并行系统的CPU多核组得到了有效利用; (2)通过在传输过程中对数据包进行抓取, 发现在其中某个TCP连接等待ACK不发送数据包时, 另一个TCP连接不用等待ACK, 继续发包, 从而使得链路带宽得到有效利用.
5.1.3 CPU利用率对比
在高速网络环境下, CPU的处理能力很大程度上影响网络的性能. 通过测试发现, 优化前IPoIB CPU利用率为33%, 优化后的IPoIB CPU利用率在24%左右,优化后的CPU利用率明显低于优化前. 在最好的情况下, IPoIB优化后的CPU利用率可以降低约30%.
5.2 与万兆以太网的性能对比
利用Netperf测试优化后的IPoIB在国产并行系统上两节点间通信的带宽和延迟, 并与万兆以太网对比.万兆以太网卡型号 T520, 10 GB/s, 理论带宽为 1250 MB/s,万兆网卡测试环境采用国产中标麒麟服务器, 处理器型号为申威1621. 测试结果如表1所示.

表1 IPoIB与万兆以太网性能对比
从表1可以看出万兆以太网的稳定带宽在1024 MB/s左右, 而IPoIB优化后的带宽达1340 MB/s,是万兆以太网持续带宽的1.31倍; 万兆以太网延迟平均约为 30 μs, IPoIB 延迟平均 39 μs, 相比万兆以太网延迟高9 μs. 基础性能对比结果表明, IPoIB在国产异构众核并行系统上的通信性能相比基于10 GbE的万兆以太网通信性能要略显优势, 持续带宽优于万兆以太网, 延迟虽然比万兆以太网略大, 但实际应用中聚合带宽是主要考虑因素, 因此IPoIB相比10 GbE是更好的选择.
5.3 乱序处理效果分析
利用Iperf测试国产并行系统上两节点间通信处于不同流量负载时的乱序情况, 乱序处理窗口长度W设为32, 为消除偶然因素影响, 每个负载下运行10次取平均值. 表2显示了在不同流量负载下乱序处理前后每秒发生的乱序次数并统计乱序减少比例. 可以看出, 乱序处理对于减少乱序数据包的作用效果十分明显: 网络流量较高时乱序情况比较严重, 而经过乱序处理后乱序次数明显减少, 乱序减少比例可达95%以上;当网络负载较轻时, 经过乱序处理后网络不再有乱序包.

表2 不同流量负载下乱序处理效果
为了验证乱序较重时窗口长度W设置过大对性能造成的不利影响, 每隔一段时间让发送方故意丢弃一次数据包以模拟乱序较重的情况, 利用Iperf测试窗口长度分别为32和80的最大网络带宽, 结果如表3所示. 从表3可以看出, 乱序较重时,W为32的最大带宽为1782 MB/s, 乱序程度减少95.8%;W为80的最大带宽为1624 MB/s, 即便乱序减少效果更好, 但带宽下降明显. 实验结果证明窗口长度不宜设置过大, 过大反而会造成带宽性能下降.

表3 不同窗口长度的网络性能对比
6 结束语
本文将IPoIB移植到国产异构众核并行系统上,并进行了乱序处理、拷贝优化、网络参数调优以及应答延迟避免等一系列优化措施. 测试结果显示, 优化后IPoIB基础带宽峰值性能为1340 MB/s, 比优化前IPoIB带宽提升近6倍, 也高于10 GB万兆以太网; 多连接下带宽达到1800 MB/s, 相比单连接提升1.34倍;CPU利用率也有了显著降低; 乱序处理机制作用效果明显.
IPoIB基于IB的send/receive异步消息机制实现,而没有利用具有零拷贝、CPU负载卸载优势的RDMA机制, 考虑到在一些特定的应用场景下利用RDMA实现IPoIB的通信效果可能会更好, 后续将制定以RDMA为底层通信机制的IPoIB实现策略, 以期进一步提高IPoIB通信性能.
