基于核估计的北斗RDSS传输延时随机数生成法
2019-01-10夏田奇刘瑞华
夏田奇,刘瑞华
(中国民航大学 电子信息与自动化学院,天津 300300)
0 引 言
北斗卫星导航系统(BDS)由我国自主发展、独立运行,是国家正在建设的重要空间信息基础设施. BDS采用卫星无线电导航业务(RNSS)和卫星无线电测定业务(RDSS)双模结构体制,在航空、气象、地质、海洋等领域有着广泛的应用. 例如,在通用航空器监视、指挥、位置信息收集、气象信息发布等应用领域,北斗短报文通信都能发挥出重要的作用[1-2]. 而在对信息传输实时性要求较高的应用场合,对北斗短报文的传输成功率和传输延时这两项性能指标要求相对苛刻,故需要具体分析北斗短报文传输延时分布情况.
1 北斗RDSS通信性能测试
1.1 测试方法
文中测试使用某公司用户机类型为二类用户机设备,做用户端北斗硬件部分与地面指挥端硬件部分,分别通过串口与计算机连接,编写程序对串口进行读写,实现北斗短报文发送和接收. 北斗用户卡通信等级为3级非密用户,短报文服务频度为60 s,通信长度为628 bit[3].
测试分为两组:1) 由用户端向指挥端发送测试报文;2) 由指挥端向用户端发送测试报文.
测试报文内容包括:报文生成日期时间,精确到千分之一秒;报文计数,用于统计报文发送个数.
发送时,指挥端或用户端记录时间和报文计数并生成报文,同时通过串口向北斗设备发送报文,用户端或指挥端通过串口解析到报文的同时记录时间. 发送时以固定的频度发送测试报文,接收时进行CRC校验数据是否出错,将报文内容、接收时间以及校验结果保存成TXT格式文件.
1.2 测试数据
测试报文的一条保存内容如下:
2018-01-21 18:14:25.357 | 24 54 58 58 58 00 1D 06 FC 60 62 06 FC 60 00 00 00 48 01 21 18 14 24 03 61 00 01 00 74 CRC正确.
翻译成明文为:接收时间2018年1月21日18时14分25.357秒;接收方ID:457***;发送方ID:235***;发送时间:1月21日18时14分24.361秒;第1条报文;CRC校验正确.
我们在两个多月间断测试了约1 169个小时,共发送70 151条报文,接收67 648条有效报文. 测试样本如表1所示.

表1 北斗短报文测试样本
其中序号为2、4、5和7的测试样本为用户端发指挥端收,共测试约701个小时,发送42 116条报文,接收41 067条有效报文;序号为1、3和6的测试样本为指挥端发用户端收,共测试约467个小时,发送28 035条报文,接收26 581条有效报文.
1.3 测试数据统计分析
1.3.1 传输成功率统计
北斗短报文传输成功率是评价北斗短报文通信性能的一个重要参数[4-5],定义为
(1)
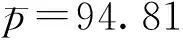
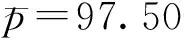
总计发送短报文个数为Tsum=70 151条,接收有效的短报文个数为Rsum=67 648条,即短报文传输成功率psum=96.43%.
1.3.2 平均传输延时统计
北斗短报文平均传输延时定义为[6]:
(2)

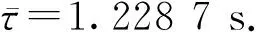

2 北斗RDSS传输延时核密度估计
在概率密度分布未知的条件下,通过已知的样本数据对未知的概率密度分布进行估计,从而预测概率密度分布. 常用的概率密度估计方法有两种:参数估计和非参数估计[7].
参数法根据样本数据频率直方图的轮廓推断总体的概率密度分布,使用样本数据对推断的概率分布参数进行估计. 参数法凭借对样本数据分布的推断,常采用复杂的多元函数对概率密度分布参数进行估计,需要在计算机上使用最大似然估计等方法得到概率密度参数估计值,过程较为复杂不便.

(3)
式中:n为样本总数;h为带宽;K为核函数,核函数常选用以0为中心的对称单峰概率密度函数[8]. 某点x处的概率密度估计值与该点附近所含有的样本个数相关. 若x附近样本个数较多,则概率密度估计值较大,反之较小. 核函数K的形式对概率密度估计值的影响较小,带宽h的大小会直接影响概率密度估计的结果. 带宽h取较小的值,估计结果的曲线会为不光滑的折线,但能说明每个样本数据所包含的信息;取较大的值则会使较多的样本数据对概率密度估计结果产生影响,估计结果的曲线也越光滑,但丢失了部分样本数据的信息. 使用核密度估计,可以得到每个样本点的概率密度估计值,但不能得到像参数法那样总体的概率密度函数.
以1.2节中北斗短报文实测传输时延样本1、2、3、4、5、6和7的数据为基础,使用数学工具MATLAB软件中ksdensity函数对北斗短报文实测延时数据进行核密度估计,获得传输延时分布的概率密度估计值并绘制曲线,如图1所示.
利用多个含权重系数的高斯函数对概率密度估计曲线进行拟合[9],其表达式为
基地选择:海拔200~2 000 m;土壤为沙壤土或红壤土,中性至微酸性(pH值5.5~7.0),肥沃;坡度10°~30°,便于排灌。
(4)
式中:n为所用高斯函数个数;ai、bi、ci为分布参数,i=1,2,…,n. 拟合方法通过MATLAB软件中的拟合工具实现,所用高斯函数个数由函数f(x)曲线与概率密度估计值曲线的符合程度决定. 当使用的高斯函数的个数n=6时,f(x)曲线与实测延时概率密度估计值曲线最为接近,拟合所获得的函数f(x)的参数如表2所示.
同时利用威布尔函数进行拟合并且与高斯函数拟合的结果进行对比,如图2所示,高斯函数拟合结果对延时概率密度估计值曲线描述更加准确.
3 北斗RDSS延时伪随机数生成
根据已知概率密度曲线生成伪随机数的方法主要有反函数法、变换法和舍选法,本文应用的舍选法是冯·诺曼最早提出来的. 它的基本思想是:按照给定的概率密度分布函数f(x),对均匀分布的随机数序列{r1,r2,r3,…,ri}进行舍选. 舍选的规则是:在密度函数f(x)较大的地方,保留较多的随机数ri;在密度函数f(x)较小的地方,保留较少的随机数ri,这样得到的子样本中ri的分布将满足概率密度分布函数的要求[10].
生成概率密度函数分布为f(x)的伪随机数X的步骤如下[11]:设随机变量X的概率密度函数为f(x),又存在实数a 1) 选取常数λ,使得λf(x)≤1,x∈(a,b); 3) 比较r2与λf(y),若r2≤λf(y),则令x=y;否则剔除r1和r2,重返步骤2). 如此重复循环,产生的随机数序列x1,x2,…,xn的分布由概率密度f(x)确定. 本文按照上述方法和步骤分别生成1 000、10 000和100 000个传输延时伪随机数,进行核密度估计后绘制曲线与箱线图并与实测延时数据进行比较,结果如图3~5所示. 从三组数据的统计对比结果可以看出,随着实验生成的随机数的个数增加,生成随机数的概率密度曲线与实测延时数据概率密度曲线吻合程度越来越高,箱线图中两者分布形状也越来越接近,几乎无法区分,直观上说明生成的延时随机数与实测的延时是同分布的,满足模拟北斗短报文传输延时伪随机数的要求. 本文对北斗短报文通信性能进行了长时间的测试,获取了大量的短报文通信测试样本数据, 在此基础上,对北斗短报文传输延迟和平均传输成功率进行了统计分析,利用多个含权重系数的高斯函数对短报文传输延时的核密度估计值曲线进行拟合,采用舍选法模拟生成符合北斗短报文传输延时分布的伪随机数.论文内容可为今后北斗短报文应用场景中工程仿真提供模拟延时数据.4 结束语
