基于智能终端的聊天机器人设计
2019-01-08袁瑞雪
袁瑞雪
摘要:应用人工智能技术,以Android studio为开发工具,采用Python语言,通过Android调用第三方语音识别接口,设计能够进行语音识别输入与文字转换、根据发送信息进行自动回复、可以和其他程序结合进行训练的简易聊天机器人。
关键词:聊天机器人;自然语言处理;语音交互
中图分类号:TN929 文献标识码:A 文章编号:1007-9416(2019)10-0144-02
0 引言
随着社会信息化进程的日益加快,人们希望能够用自然语言与计算机进行交流,聊天机器人的市场因此产生。聊天机器人旨在通过自然语言处理等技术,对人们提出的问题进行理解,通过检索知识库等方式产生对应的回复[1-2]。它是一种模拟人类的对话模式,使用自然语言与人类进行交流的程序。它不仅能回答用户所提的问题,还能人性化地与用户交流,同时提醒或者安排用户完成一些任务。研究聊天机器人的相关技术,尤其是对话理解等问题,对促进人机交互方式的发展具有重要意义[3-4]。本设计旨在通过Android智能终端与机器人聊天,进行语音识别输入与文字间的转换,理解输入发送的信息并进行自动回复,最终将问题的输入以及对话的效果以APP的形式展示。
1 语料获取和处理
对话系统的关键基础就是数据集,即语料库。但目前开源的语料库很少,该系统选取了两个语料库进行对比,分别是电影独白语料库和公开的小黄鸡语料库。本文选择学习训练时间比较快的小黄鸡语料来进行学习。
原始语料文本不能用来直接训练,需要进行句子和向量间的转换;然后是构建语料问答对,对其进行拆分;最后保存和训练语料模型即深度模型,实现语音识别输入与文字的转换,理解输入发送的信息并进行自动回复并以APP形式展示。
2 Android客户端交互设计
安卓交互模块主要具有如下四个功能:(1)语音识别输入:软件调用科大讯飞接口,具有语音识别输入的功能,直接对语音内容进行识别,转换为文本内容发送给服务器;(2)文字键入:除了语音识别输入,还可以文字的键入;(3)信息显示:内容显示界面,包括软件名称,聊天框,聊天内容,语音识别功能和发送按钮的显示等;(4)语音播报输出:在进行回答结果信息显示的同时可以进行语音播放,同样也是调用科大讯飞输出结果。
3 语音听写和合成设计
该系统调用的是科大讯飞接口,它是国内著名的语音技术提供商,专业于语音和文字产品,提供了语音识别和合成接口,可接入使用。该平台为开发者们提供了中文分词、词性标注、语义角色标注等NLP技术服务。
调用科大讯飞接口主要有以下步骤:注册登陆科大讯飞开放平台(http://www.xfyun.cn/)、进入控制台、创建应用,记下AppID、点击开通服务进入语音听写去下载相对应的SDK、下载安卓版本的SDK。
语音合成與语音听写识别刚好反过来,是把文字内容转变为语音信息,使得机器可以像人类一样说话。
4 客户端和服务端设计
客户端模块主要由语音听写和合成、网络请求和UI绘制这个三个模块组成。(1)语音听写和合成模块:使用科大讯飞提供的语音听写和语音合成SDK,将语音内容转变成文本内容返回和将文本内容转换为语音输出;(2)网络请求模块:通过http协议,用get的请求方式将语句字符串发送到服务端;(3)UI绘制模块:以适当布局显示用户输入的语句内容和服务端返回的问答字符串结果。
服务端的操作系统为mac,环境配置为python3.7和jdk。首先需要flask模块,实例一个此类,该系统使用的是单一模块_name_。用route告诉flask使用url来激发应答函数。此函数将问答模型对象中得到结果的函数返回给客户端进行信息的显示。服务端模块主要由请求解析模块、语义解析模块和应答封装这三个模块所组成:(1)请求解析模块:将http数据报的内容解析到response对象中,供开发者调用;(2)语义解析模块:从请求解析模块中提取文本,得到应答语句,将其提供给应答封装;(3)应答封装:最后把应答语句以json串的形式返回给开发者调用。
5 模型训练和评估
5.1 模型训练
有基于seq2seq的train和train_anti两种模型进行训练,设置同样的参数进行训练比较,其中可以选LSTM和GRU这两种模型,该系统采用2层隐藏层的神经网络模型,隐藏节点个数为128个,学习率即步长为0.001,迭代训练的迭代次数有20次,100次。
5.2 训练效果评估
交叉熵是Shannon信息论中一个重要概念,主要用于度量两个概率分布间的差异性信息。交叉熵的意义是对文本识别的难度。将交叉熵引入计算语言学消岐领域,采用语句的真实语义作为交叉熵的训练集的先验信息,将机器翻译的语义作为测试集后验信息。计算两者的交叉熵,并以交叉熵指导对歧义的辨识和消除。
交叉熵可在神经网络(机器学习)中作为损失函数(Cross Entropy Loss)。
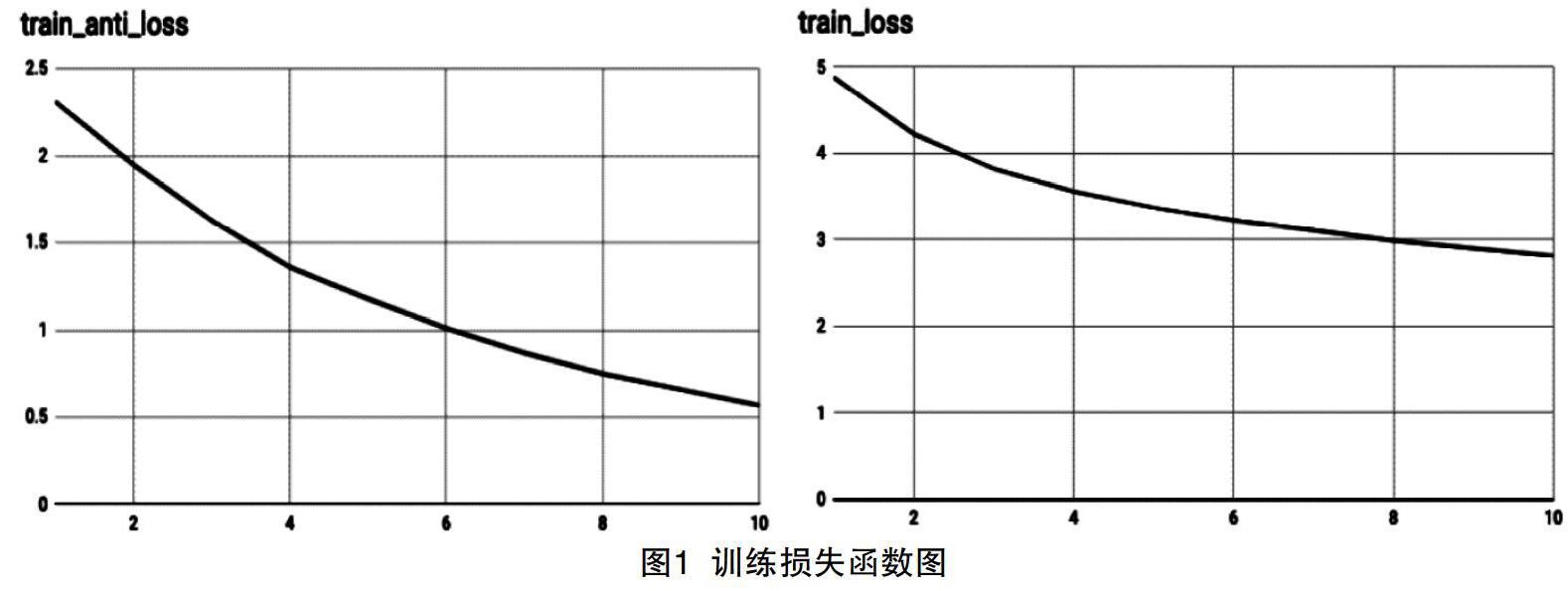
图1展示了加入attention机制后两种模型训练下的损失函数。
由图可见:随着纵坐标数值的增加损失函数 L 越小;第二种模型收敛的速度更快,交叉熵一开始更小,也更快达到1以下,优于正常的seq2seq模型。
这种优势也是基于迭代次数的,在前期较少的轮数训练下,两种训练效果区别不大。
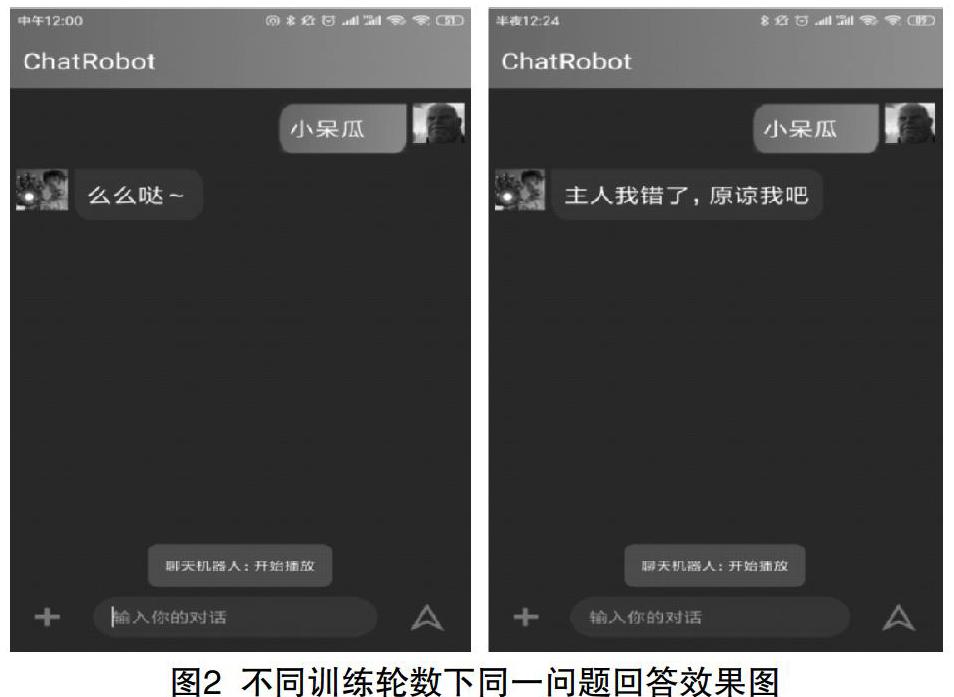
训练轮数为20轮、100轮时同一问题回答效果如图2所示。
6 结语
本文针对闲聊机器人模型的背景,通过对其中可能涉及到的算法的阅读与学习,选择了最符合本文特点的相应算法,依托Andriod开发环境搭建出整个聊天机器人系统。但在由于中文自然语言的复杂性,产生式聊天机器人容易构建出无意义的回复,如何将产生式深度模型应用于闲聊机器人领域还需要深入的研究。
参考文献
[1] 冯志伟.自然语言处理综论(第二版)[M].北京:人民邮电出版社,2018.
[2] 周志华.机器学习[M].北京:清华大学出版社,2016.
[3] 郑泽宇,顾思宇.Tensorflow:实战Google深度学习框架[M].北京:电子工业出版社,2018.
[4] 张旭,崔阳,刘海平.Python自然语言处理[M].北京:人民邮电出版社,2014.
