基于协同过滤的歌曲推荐算法研究
2019-01-08王炳祥
王炳祥

摘要:根据用户的历史听歌记录挖掘用户的音乐偏好,给用户做出满意的个性化歌曲推荐具有重要意义。采用基于用户的K最近邻协同过滤推荐算法,以网易云1000多份热门歌单作为测试数据集,虾米音乐用户听歌行为数据,在PyCharm集成开发环境中进行实验研究,并用三种方法对获取的歌单推荐结果进行评估。
关键词:歌曲推荐;协同过滤;KNN
中图分类号:TN391 文献标识码:A 文章编号:1007-9416(2019)10-0126-02
0 引言
在上世纪初期的90年代,推荐系统的研究开始逐步盛行,它應用了认知诊断、信息搜索、机器学习等多领域的知识[1-2]。推荐系统即利用一定的技术和方法,通过已有的历史记录对用户的兴趣爱好建立模型,给用户推荐满足其个性化需求的物品和信息[2]。推荐系统可被看成一种信息过滤工具,因此,推荐算法也被叫做过滤算法。根据过滤算法的不同,推荐算法可以分为三类:基于内容的过滤、协同过滤、混合过滤。目前应用最为广泛的是协同过滤的方式[3]。
对于音乐推荐而言,用户的偏好通常隐式地通过对音乐产生的行为记录和聆听习惯来表达。另外,用户无法全面而的且准确地对音乐进行定位。因此,根据用户的历史听歌记录挖掘用户的音乐偏好,给用户做出个性化推荐,提高推荐系统的准确度和用户满意度是很重要的一项研究目标。
1 协同推荐算法
协同过滤(CF,Collaborative Filtering)也叫做基于近邻(NN,Nearest Neighbor)的推荐算法,主要思想是:利用已有用户群的过去行为或意见来预测数据,根据与当前用户/当前物品较为相似的近邻数据来产生推荐结果。本文采用基于用户的K最近邻推荐(User-based KNN)协同推荐算法。算法基本原理如下:
首先,对输入的评分数据集和当前用户ID作为输入,找出与当前用户过去有相似偏好的其它用户,这些用户叫做对等用户或者最近邻;然后,对当前用户没有见过的每个产品p,利用用户的近邻对产品p的评分进行预测;最后,选择所有产品评分最高的TopN个产品推荐给当前用户。
通过下式计算用户u对歌曲i的喜爱程度:
其中N(i)表示对歌曲/单i有过行为的用户集合,wuv是用户u和用户v之间的相似度,rvi表示用户v对歌曲/单i的打分。
算法输入是一个“用户-物品”评分矩阵,输出数据一般有两类:当前用户对物品喜欢和不喜欢程度的预测值和n项的推荐物品列表。
2 数据集获取
任何机器学习算法解决问题,首先需要考虑的就是数据从何而来。在歌曲推荐算法中首先要考虑歌单数据的来源问题。
2.1 测试数据集
本研究中,采用传参动态密码的高级加密标准AES(AES, Advanced Encryption Standard)算法爬取了网易云1000多份热门歌单作为测试数据集。爬虫主体是利用requst获取html内容,用BeautifulSoup提取有用数据。
2.2 数据预处理
对数据进行预处理,将歌单数据转化成推荐系统格式数据。主流的Python推荐系统框架,其评分基础数据格式为user item rating timestamp,主要抽取歌单id和歌曲流行度,同时保存好歌单id到歌单名的映射字典文件。
2.3 歌曲推荐数据
利用scrpy_redis分布式爬虫,爬取虾米音乐用户听歌行为数据,最终得到了大概6万多条真实的未脱敏用户播放数据。
要完成推荐,需要得到每个用户对每首歌的一个评价矩阵。因此,需要从中摘取出用户id、歌曲名和评分(播放次数越多,评分越高),然后做成excel表格,再用pandas转换成数据框格式进行读取。
3 实验研究
3.1 实验设计
本次实验是在PyCharm集成开发环境中进行的,所使用的主要库为Surprise(Simple Python Recommendation System Engine)。首先对整理好的用户评分矩阵整理成excel表,然后用pandas函数转化成数据框格式进行读取,载入自己的数据集并进行手动5折交叉验证。用基于用户的协同过滤算训练模型,计算相似度(采用内置的皮尔森相似度),然后调用Surprise库并用KNNWithMeans算法对数据集进行实验。
3.2 实验分析
首先,导入数据集readersurprise库算法,然后用pd.reader_ excel读取用户评分矩阵并将其转化成推荐格式,接着载入数据集并进行模型训练,最后生成用户推荐列表。推荐结果如图1所示。
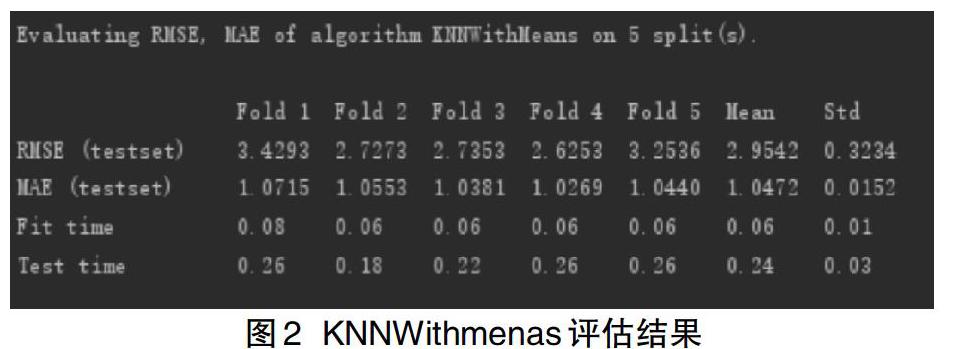
然后对数据集用KNNWithMeans算法进行实验评估,结果分别如图2所示。
评估标准均方根误差RMSE和标准平均绝对误差MAE,理论上这两个值是越小越好。
4 结语
本文提出了基于标签的个性化音乐推荐和基于用户特征的个性化音乐推荐的方法,在推荐性能上有了一定的改进,但仍存在需要进一步改善的地方。比如,当音乐的数据量越来越大,音乐的平台越来越多的时候,对用户信息的提取和利用应该更加完善,因此对于音乐推荐可以更多的考虑深度学习训练音乐特征,进一步改进音乐推荐效果。
参考文献
[1] 高凤丽,孙连山.个性化推荐系统概述[J].技术与市场,2015,22(2):78-79.
[2] 朱天宇,黄振亚,陈恩红,等.基于认知诊断的个性化试题推荐方法[J].计算机学报,2017(1):176-191.
[3] 冷亚军,陆青,梁昌勇.协同过滤推荐技术综述[J].模式识别与人工智能,2014,27(8):720-734.
