基于RGB-D视频的多模态手势识别①
2019-01-07马正文蔡坚勇欧阳乐峰
马正文,蔡坚勇,2,3,4,5,刘 磊,欧阳乐峰,李 楠
1(福建师范大学 光电与信息工程学院,福州 350007)
2(福建师范大学 医学光电科学与技术教育部重点实验室,福州 350007)
3(福建师范大学 福建省光子技术重点实验室,福州 350007)
4(福建师范大学 福建省光电传感应用工程技术研究中心,福州 350007)
5(福建师范大学 智能光电系统工程研究中心,福州 350007)
1 引言
人们对手势识别技术的研究已有几十年的历程,经历了不同的发展阶段.手势识别开始于1983年,来自AT&T的Grimes[1]发明了数据手套,其通过数据线与计算机相互连接来进行手势定位跟踪和时序信息的检测处理.采用数据手套的方法数据量小、稳定性和识别准确性高,但由于需要穿戴昂贵的硬件设备,操作不方便的同时也对人体进行了限制,因而难以得到有效的推广,这也迫使研究者寻求更为自然的方法.随后的彩色相机的出现,基于视觉的方式成为主流.传统的动态手势识别方法主要基于动态时间规整(DTW)[2]和基于隐马尔可夫模型(HMM)[3].2010年微软推出的Kinect传感器为计算机视觉提供了全新的数据类型,即深度信息,它包含着物体到摄像头的距离信息,深度信息的利用使得视觉处理中较困难的分割过程更为容易,正是由于可以提供这种有用的深度信息,使得RGB-D相机在手势识别研究被广泛使用.
近年来,深度学习在图像分类[4]、目标检测[5]、语义分割[6]、场景理解[7]等计算机视觉领域得到广泛使用,该技术可以对特征进行分层抽象学习,通过网络训练自动提取特征.利用深度学习技术进行手势的识别是目前主流的研究方法,国内外研究人员在各种手势数据集上进行了研究工作.李宇楠等[8]利用手势RGB图像序列及通过RGB图像序列计算出的光流序列,分别使用 3DCNN(3D Convolutional Neural Networks)网络进行特征提取,然后对提取的特征进行融合,利用支持向量机(SVM)来进行手势识别;清华大学的Chen X等[9]提出一种运动特征增强的RNN网络,对基于骨架结构的手势序列进行动态手势识别;Molchanov等[10]等利用3DCNN网络对手势时空域进行特征提取,配合时空特征增强方法,在VIVA数据集上达到77.5%的识别率.目前绝大部分的研究都采用了深度学习技术处理基于视频的手势识别.
本文是对SKIG RGB-D多模态的孤立手势视频进行手势识别研究.对采样出的32帧RGB图像序列和Depth图像序列,分别利用本文提出的稠密连接的3DCNN组件学习短期的时空域特征,然后将提取的时空域特征输入到卷积GRU网络进行长期的时空域特征学习,最终对单模态训练好的网络进行多模态融合,提升网络识别准确率.本文在SKIG数据集上取得了99.07%的识别准确率.
2 模型架构
基于视频的手势识别涉及到时间和空间因素,因而不仅要考虑手势的空域特征,还要考虑时域特征.对时空域的特征学习是手势乃至其它人体行为识别[11]的重点.LRCN[12]将CNN与LSTM结合用来提取时空域特征,先对视频采样出的帧,通过CNN进行空域特征提取,然后对按序提取出来的空域特征,利用LSTM来学习其时域特征.双流CNN网络利用两条分支分别从RGB图像中提取空域特征和堆叠的光流图像中提取时域特征,对最终的分类进行融合.这两种具有代表性的方式,前者采用分阶段学习时空域特征,而后者是对时空域特征各自独立学习.考虑到手势背景复杂多变,对时空域特征同时学习,是更为有效的方式.3DCNN网络就是基于这种理念,利用三维卷积核对时域和空域同时处理,这种方式比前两种更为有效,因而被众多研究者用来对视频进行时空域特征的提取.GRU对时间序列数据有很好的学习效果,但是采用全联接的方式,对空域特征的学习能力较弱.利用卷积GRU网络可以学习长期的时空域特征.利用本文提出的稠密连接的3DCNN学习视频短期的时空域特征,进而使用卷积GRU从短期时空域特征来学习视频长期的时空域特征是合理的组合方式.本文采用的单模态的网络模型结构见图1.

图1 单模态的网络模型结构
如图1所示,单模态的网络模型结构分为五个部分:(1)预处理好的32帧图像序列,作为网络的输入部分;(2)本文提出的稠密连接的3DCNN结构,用于对输入的序列提取短期时空域特征;(3)双层卷积GRU网络,更进一步对提取的短期时空域特征进行长期时空域特征的学习;(4)空间金字塔池化层用于降维;(5)全连接FC层的输出使用Softmax分类器得到概率向量,对最终的网络输出进行分类预测.具体各部分将依次介绍。
2.1 稠密连接的3DCNN组件
稠密卷积网络[13](DenseNets)使用合适的特征尺寸,将所有层的特征都进行相互联接,来获取网络各层间的最大信息,为了保持前馈性,每层都对之前的所有层的输出进行拼接后作为本层输入,得到的输出特征图传递给后续所有层.依据DenseNets网络Dense block的思想,将其应用到3DCNN,本文提出稠密连接的3DCNN结构用于对手势视频进行短期时空域特征提取.对提出稠密连接的3DCNN结构一些参数的情况加以说明:
(1)规定网络输入的层的输入图像序列的格式以及特征图的格式按“通道数@长度×高度×宽度”方式标记.
(2)3D卷积核和3D池化核的大小为d×k×k,其中d表示时间长度,k为空间大小.每个卷积核大小为3×3×3,卷积核步长大小均为 1×1×1,Padding 方式选用‘SAME’.
(3)3D池化核使用是最大值池化.
如图2所示的结构中,输入部分是对视频采样出的32帧组成的图像序列.通过64个3D卷积核进行卷积操作得到64@32×112×112的特征图,空间尺寸保持不变,然后利用 1×2×2 池化操作,保持时间维度不变,空间尺寸缩小为原来的1/4.稠密连接部分每个卷积层的3D卷积核个数为32,通过跨层拼接的方式,依次得到的特征图个数为:32,64+32=96,64+32+32=128,64+32+32+32=160,然后通过32个3D卷积核卷积操作,提取特征后利用 2×2×2池化进行降维得到32@16×56×56的最终输出特征,作为后续双层卷积GRU的输入.
(2)规模化集约化效益明显。河北省在“矿产资源整合”、“露天矿山整治”等专项行动中关、停、取缔了一些高耗能、低产出,开采技术设备落后、污染重、规模小的矿山企业;关小促大、保优压劣促使矿业结构进一步优化,“三率”提高,矿山企业规模化集约化效益明显,这是河北省矿山企业健康发展、创新发展和绿色发展的开端。

图2 稠密连接的 3DCNN 结构
2.2 双层卷积GRU
传统的GUR输入到状态,状态到状态之间的转换是采用全连接的方式,而全连接方式对空间维度没有进行有效利用,因而本文使用卷积GRU,将全连接方式使用卷积操作代替,用来对长期的时空域特征同时提取,具体如公式(1)所示:
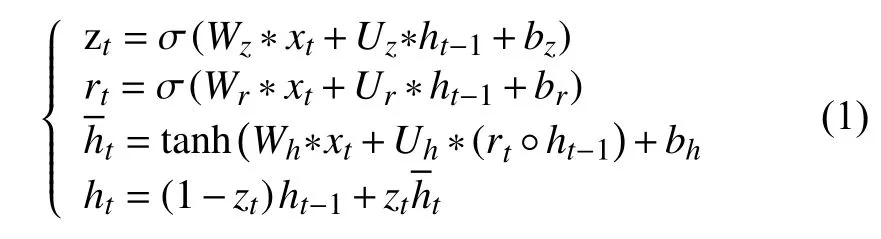
其中,x1,···,xt为不同时刻的输入信息,h1,···,ht对应不同时刻的隐藏状态,zt是更新门,用来控制当前的状态需要遗忘多少的历史信息和接受多少的新信息,rt重置门,用来控制候选状态中有多少信息是从历史信息中得到,是候选隐含状态,ht是当前时刻的隐含状态,W∗和U∗均是2维卷积核,σ为Sigmoid激活函数,′°′表示矩阵Hadamard积.
本文使用双层的卷积GRU,第一层的卷积核数目为256,第二层的卷积核数目设为384,卷积核的大小均为 3×3,卷积核步长大小均为 1×1,Padding 方式选用‘SAME’.将第二层最终学习到的特征作为双层卷积GUR 的输出,384@1×28×28,其中 384 指特征图个数,28×28为每个特征图的空间大小,时间长度为1.
2.3 空间金字塔池化层
双层卷积GRU输出为384@1×28×28,总的维度太高,要先进行降维处理,本文使用了4种层次的SPP,分别是 1×1、2×2、4×4、7×7 结构,如图3所示,最终生成1+4+16+49=70个384维的特征,Flatten变平化为1维向量后的结果为1×70×384=26880,再与全连接层相连.采用多层SPP降维的同时对同一特征图多种尺度的提取特征,对网络识别精度有所提高.

图3 空间金字塔池化层
2.4 模型融合
多模态融合是常用的提升模型准确度的方法,本文融合模型是对训练好的两种模态网络的Softmax层输出的概率向量进行相加除以2,选取最终得到的融合概率向量中数值最大的概率所对应的类别作为分类的结果,融合模型如图4所示.

图4 多种模态的融合模型结构
3 实验验证及结果分析
3.1 数据集
本文基于 Sheffield Kinect Gesture (SKIG)Dataset[14]RGB-D孤立手势视频数据集,对提出的手势识别网络模型进行实验,数据集类别共10类,如图5所示,图中展示了RGB图像及所对应的Depth图像.
SKIG数据集包含手势的RGB视频及Depth视频两种模态,该手势数据集是利用微软Kinect设备的RGB摄像头和深度摄像头,同步采集人体手势而得到,数据集没有划分训练集与测试集.具体细节如下:

图5 SKIG 前后 5 种手势类别
(1)一共采集了6人(subject)的手势,每个手势的RGB视频有相应的Depth视频.(2)包含10个手势类别:Circle(画圆)、Triangle(画三角形)、Up-down(上下移动)、Right-left(右左移动)、Wave(挥手)、‘Z’(画Z 字形)、Cross(画十字形)、Come here(招唤动作)、Turn around(翻转)以及 Pat(轻拍).(3)每种手势分别使用3种手形执行:握拳、伸食指和张开手掌.(4)采用3 种背景:木板、白纸和报纸.(5)2 种光照:较亮和较暗.(5)总视频数2160,RGB视频和Depth视频各占一半 (6×10×3×3×2=1080 个).
3.2 实验环境
(1)硬件环境:NVIDIA Tesla P40 24 GB 显卡 8 核32 GB CPU
(2)软件环境:CentOS7 操作系统 Python 3.5.2 版TensorFlow 1.2.1 版 TensorLayer 1.6.5 版 CUDA8.0 cuDNN5.0
3.3 模型参数
因为实验用到的网络模型是第一次提出,整个网络从头开始训练,RGB模态和Depth模态数据集各自独立训练,两种模态的网络训练参数设为一致.批次大小为18;学习率初值设为0.001;权重衰减系数设为0.0004;每 6000 次迭代,学习率下降为原来的 1/10;网络训练时每迭代500个批次,就对测试集进行一次测试;训练的周期数,设为 300 个周期,对应 12000 左右的迭代次数.
3.4 实验及结果分析
数据集没有划分训练集与测试集,采用文献[15]中的 3 折交叉验证,将 6 个 subjects,划分成三个子集,其中子集 1 为:subject1+subject2;子集 2 为:subject3+subject4;子集 3 为:subject5+suject6.
分组1:训练集为子集1和子集2,测试集为子集3,结果如图6所示,经测试选取的两个训练好的单模态网络模型参数为:RGB数据集11 000次迭代时测试准确度为98.33%的模型参数和Depth数据集10 000次迭代时测试准确度为99.17%的模型参数.
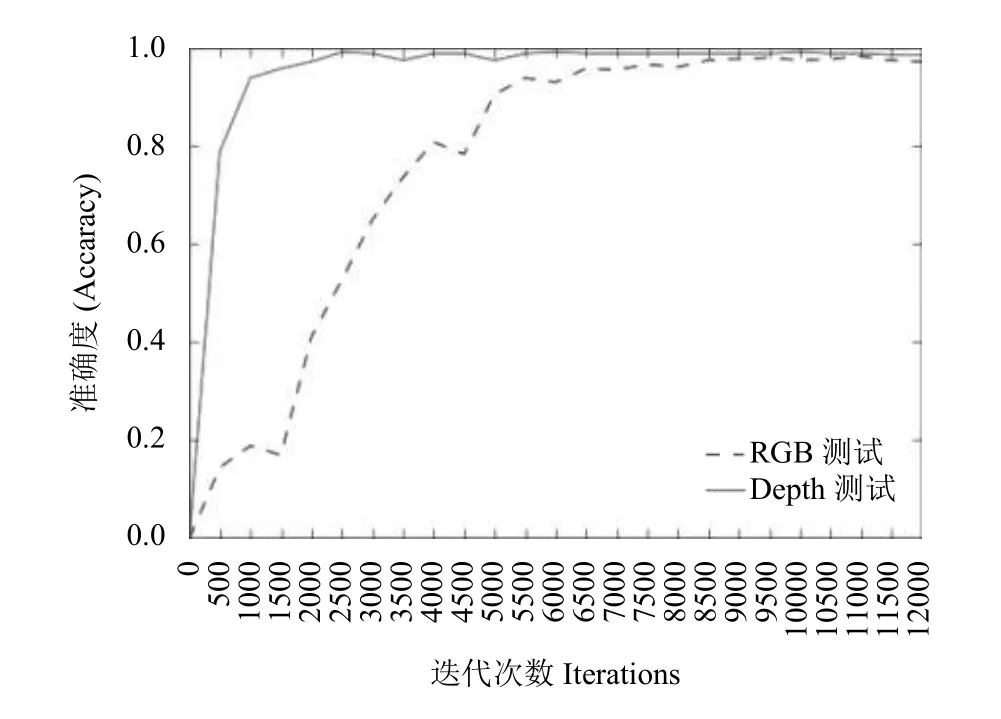
图6 分组 1 的测试结果
分组2:训练集为子集1和子集3,测试集为子集2,结果如图7所示,经测试选取两个训练好的单模态网络模型参数为:RGB数据集10 000次迭代时测试准确度为96.94 %的模型参数和Depth数据集10 500迭代时准确度为97.78 %的模型参数.
分组3:训练集为子集2和子集3,测试集为子集1,结果如图8所示,经测试选取的最优的两个训练好的单模态网络模型参数为:RGB数据集11500次迭代时准确度为93.06%的模型参数和Depth数据集9000迭代时准确度为99.17 %的模型参数.
对每个分组单模态网络各自训练好的模型,按本文所用的方法进行模型融合,得到各分组多模态融合后的准确率,如表1所示.

图7 分组 2 的测试结果

图8 分组 3 的测试结果
将本文方法结果与近几年在SKIG数据集上相关实验的结果进行对比,如表2所示,本文提出的方法具有更高的准确率,达到99.07%.其中RGGP+RGB-D方法使用受限图形遗传编程(RGGP)方法,从视频中自动提取具有鉴别性的时空特征,对RGB和Depth信息的融合来进分类,识别率为88.7%,与本文准确率相差10.37%.MRNN方法利用2DCNN对视频的空间特征进行学习,学习到的特征输入到MRNN网络进行手势分类,与本文准确率差了1.27%.3DCNN+CLSTM利用3DCNN结合CLSTM的方法来进行时空域的学习,达到了98.89%的准确率,它使用的是传统的3DCNN,与本文提出的稠密连接的3DCNN在特征的处理上并不相同,本文的模型参数少于其一半,约 930 万,大幅降低模型参数的同时保持相对应的性能,本文模型提升了约0.2%.

表2 不同方法在 SKIG 上的比较
4 结语
本文提出的稠密连接的3DCNN结构,实现对多层特征图进行重复利用,使得参数利用效率更高,更加容易进行网络的训练.通过对不同层的特征进行稠密的组合,可以对后续层的输入增强多样性,在提升网络的性能的同时,降低网络模型的参数量.利用卷积GRU相比传统的GRU而言增加了对空间信息的处理能力,因而能更好的对长期时空域特征进行提取.本文模型参数及卷积核个数的设置并不是最优,双向卷积GRU可能会进一步提升模型准确率.后续计划将注意力机制引入,期望有更好的性能提升.
