基于改进CNN特征的场景识别①
2019-01-07薄康虎李菲菲
薄康虎,李菲菲,陈 虬
(上海理工大学 光电信息与计算机学院,上海 200093)
随着信息时代的发展,场景识别在很多图像(视频)处理任务中扮演着重要的角色.然而,由于同类间的相似性和异类间的差异性导致场景识别在计算机视觉领域的发展具有挑战性,强有力的特征提取和准确的分类器成为攻克难关的重要关键所在.
传统的方法主要是提取低级特征用于贝叶斯或支持向量机(SVM)分类.但是,将低级特征直接进行映射可能会引起更大的语义鸿沟[1],后来又将低级特征编码为中层语义信息进行解决上述问题.其中广泛使用的编码方法有词袋模型(Bag of Words)[2]、空间金子塔模型[3]、概率生成模型[4],稀疏编码[5]等.
近年来由于计算硬件的发展,卷积神经网络(CNN)在计算机视觉领域带来革命性的改革,推动了场景识别的发展.与传统的统计学方法相比,神经网络无需对概率模型进行假设,具有极强的学习能力和容错能力,所以卷积神经网络不仅可以提高场景识别的准确性,而且还可以作为各种通用特征提取器进行识别任务,如目标检测、语义分割以及图像检索等.只要简单的预处理图像就可以直接作为输入,省去了复杂的特征工程,提高CNN的传输能力,因此卷积神经网络逐渐成为图像识别问题的重要工具,在图像理解领域中获得了广泛应用.
基于上述研究方法的考虑,本文采用卷积神经网络进行场景识别的研究,由于不同模型之间的特性和运行效率,故选择AlexNet模型作为基础模型,分别进行不同方式的改进提高场景识别率.
1 卷积神经网络
卷积神经网络模型是利用空间结构数据的特殊神经网络架构.一个标准的CNN包含三种特征操作层,即卷积层、池化层和完全连接层.当这些层被堆叠时,如图1所描述的那样就形成了CNN架构.

图1 标准的卷积神经网络框架
1.1 卷积层
卷积层首先执行卷积操作来完成一系列的线性激活,然后每个线性输入到非线性激活函数中,例如ReLU、tanh.在卷积层中,输入与一系列的卷积核进行卷积学习,卷积是一种在两种信号上的线性操作,例如:有两个函数x(t)和ω(t),t为连续变量,移位值a,卷积操作可以定义为:
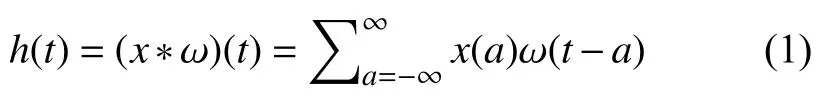
其中,x表示信号输入,ω表示卷积核 (滤波器),输出h表示特征映射,t表示时间,a表示移动的步长.
传统的神经网络每个输出都连接每个输入,而卷积神经网络拥有局部感受野,这意味着每个输出单元只连接到输入的一个子集,利用空间局部相邻单元之间的相关性进行卷积运算.CNN的另一个显著特性是参数共享,卷积层中使用的参数共享意味着每个位置共享相同的参数(权重和偏差),减少了整个网络的参数数量,提高了计算的效率.
1.2 池化层
池化层一般存在于每个卷积层之后来降低上一层卷积计算输出的维数,即将特征图像区域的一部分求个均值或者最大值,用来代表这部分区域.如果是求均值就是 mean pooling,求最大值就是 max pooling.常用的是最大值池化,最大值池化输出的是矩形邻域内的最大值,图2描述了具有2×2滤波器和步长为2的最大值池化,下采样表示空间大小,此外,池化操作可以保证图像的转移不变性.

图2 最大池化示例
1.3 全连接层
在完成多个卷积层和池化层之后,卷积神经网络通常采用全连接层结束学习,完全连接层中的每个神经元都完全连接到前一层中的所有神经元,在整个卷积神经网络中起到“分类器”的作用.
2 改进 CNN 网络模型
传统的卷积神经网络(CNN)稀疏的网络结构无法保留全连接网络密集计算的高效性和实验过程中激活函数的经验性选择造成结果不准确或计算量大等一系列待优化的问题,本章节以AlexNet作为基本的网络模型,分别从模型深度、宽度、多尺度提取以及多层特征融合方面进行改进提高场景识别的有效性.
2.1 基本原则
(1)避免早期网络阶段的表达瓶颈问题
一般来说,在最终的表示之前从输入到输出表示的尺寸(特征映射分辨率)会缓慢降低,步幅的减少可能会减缓特征映射分辨率的下降并减少图像信息的丢失,集成多分辨率特征来学习更多空间信息从而克服表达的瓶颈问题.
(2)平衡模型的深度、宽度以及卷积核大小的关系
随着深度的加深,宽度和卷积核大小需要适当的调整.表1显示了卷积核大小和步长之间的几个经验值.深度和宽度是调节网络参数的两个关键因素.尽管模型的深度越来越深,模型性能的显著提高以及计算成本的加剧,但是深度依然被认为是设计CNNs架构时的最高优先级[6–8],另外,减少滤波器 (卷积核)的数量只能部分地补偿参数过多的问题.过多的参数最终会导致过度拟合并限制分类精度的提高,因此深度是考虑优化的第一要务,但不是唯一因素.

表1 卷积核大小和步长的经验值
(3)降低模型复杂度
从神经元数量、模型参数尺度以及所有卷积层的时间复杂度三个方面考虑深度卷积神经网络的模型复杂度,综合评估一个表现良好的网络模型需要考虑这三个方面.
① 时间复杂度

其中,M代表每个卷积核输出特征图(Feature Map)的边长;K代表每个卷积核(Kernel)的边长;Cin代表每个卷积核的通道数;Cout表本卷积层具有的卷积核个数,即输出通道数.
由此可见,每个卷积层的时间复杂度由输出特征图面积M2、卷积核面积K2,输入Cin和输出通道数Cout完全决定.
输出特征图尺寸本身由输入矩形尺寸X,卷积核尺寸K,Padding以及Stride四个参数所决定,表示如下:
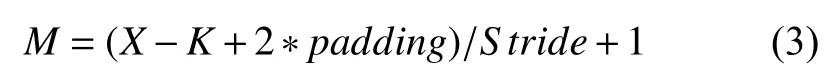
卷积神经网络整体的时间复杂度可以表示为:
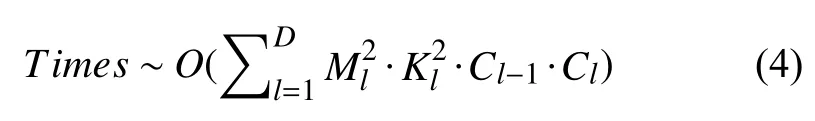
其中,D表示神经网络所具有的卷积层数;l代表神经网络第l个卷积层;Cl表示神经网络第l个卷积层的输出通道数Cout.
② 空间复杂度(模型的参数尺度)
空间复杂度即模型的参数数量,体现为模型本身的体积,可表示为:

可见,网络的空间复杂度只与卷积核的尺寸K、通道数C、网络的深度D相关.而与输入数据的大小无关.
时间复杂度一方面决定了模型的训练/预测时间,如果复杂度过高,则会导致模型训练和预测耗费大量时间,既无法快速的验证想法和改善模型,也无法做到快速的预测;另一方面决定了模型的参数数量,由于维度限制,模型的参数越多,训练模型所需的数据量就越大,而现实生活中的数据集通常不会太大,这会导致模型的训练更容易过拟合.
③ 神经元数量
神经元是神经网络进行计算的重要单元之一,计算机模拟人的大脑去感知和认知世界,在某种程度上来说,神经元越多,学习能力必然会越强.但是,计算机不会像人脑一样同时可以进行多样任务的学习,庞大的神经元系统自然也就导致了一系列的问题,如计算效率下降、难以优化等.
2.2 增强的AlexNet网络模型
基于卷积神经网络的场景识别主要分三个主要部分,即图像预处理、卷积操作提取特征以及全连接层的分类.以AlexNet网络为基础模型进行改进,AlexNet网络模型如图3所示,具体算法如下:
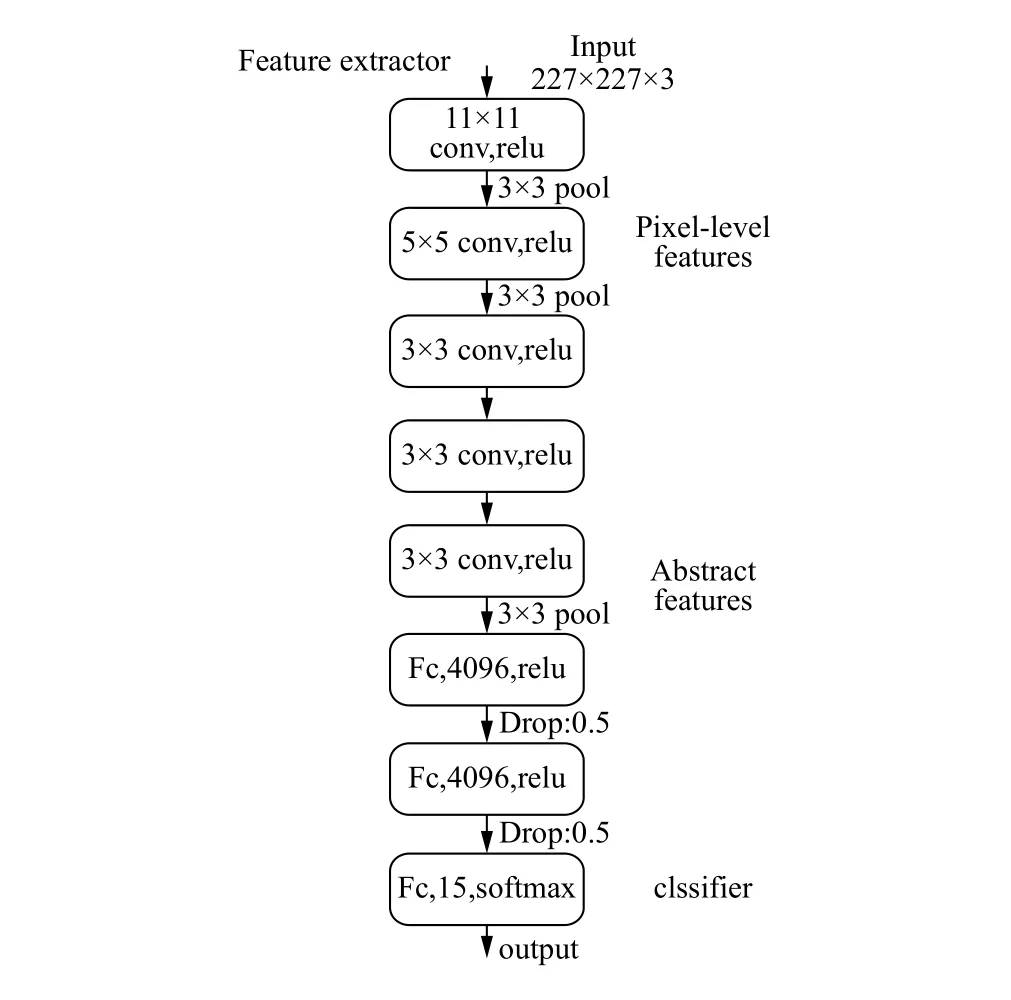
图3 AlexNet学习框架
对于场景识别任务而言,空间布局信息是至关重要的,卷积神经网络提取特征的过程中特别容易丢失空间布局的细节信息.现实中一张场景图像包含多个目标场景,其次大部分场景对象相对于其他对象保持在水平或者垂直方向,如图4所示.
考虑到不同目标场景图像之间的冗余信息在特征提取过程中可能会有或多或少的影响,本实验尝试采用图5所示的划分方式,和原数据集组合为一个数据集,这样一方面可以保留独立的个体目标的表现力,另一方面可以达到数据增强的效果.

图4 场景图像的布局信息示例

图5 场景图像分割示例
(1)算法 1.改变滤波器的数量.
有研究显示AlexNet网络模型第三、四层的特征提取能力最强,故本文选择高层次(第四层)的卷积核进行改进,对于特定的分类任务,在一定范围内,卷积核数量过大提取过多的冗余信息会降低最终的识别效率,相反卷积核数量过小提取特征会表现得不充分,故本文通过多次实验,选择合适的卷积核数量进行改进,实验结果如图6所示,第四层滤波器数量取388识别率可达91.5%,效果最佳.
(2)算法 2.加深网络的深度.
网络模型的深度直接影响特征提取的表现能力,网络模型越深,提取的特征就会越抽象.因此,本文中尝试将AlexNet网络模型进行加深,分别在第二层、第四层、第五层卷积层后面添加卷积层(卷积核为3×3),其中2-1代表的是在第二层卷积层后面添加一组卷积核为3×3的卷积层,如图7表示对最终识别任务的影响,最高精度可达90.0%,前三种加深方法具有一定的提升,后三种的深度增强了提取特征的冗余性,降低了最终的识别率.
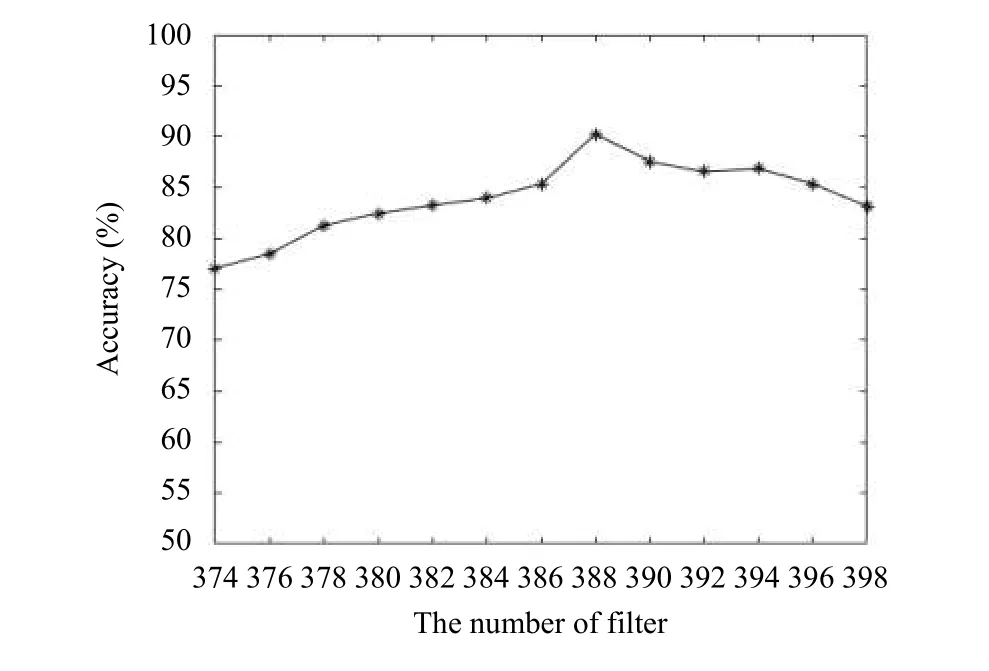
图6 滤波器数量对识别精度的影响

图7 网络模型深度对识别精度的影响
(3)算法 3.多尺度化特征提取.
获得高质量模型最保险的做法一般是增加模型的深度(层数)或者其宽度(层核或者神经元数),但是这样做法会引起三大共同的问题:① 如果训练集有限,参数过多会容易过拟合;② 网络越大计算复杂度越大,难以应用;③ 网络越深,梯度越往后传播越容易消失,难以优化模型.鉴于此,本文通过不同的尺度卷积实现多尺度特征的利用,多尺度化提取模块如图8所示.
此外本文还采用两个3×3的卷积核代替5×5的卷积核进行比较实验,经过多次实验可知多尺度提取结构所在层数越高,通道数越多,该方法越能获得更高的效率.因此在兼顾特征冗余性影响的同时,分别在第五个卷积层(conv5)后加入1,2,3个多尺度化提取结构,改进前后的识别率分别为:88.6%,82.4%,73.6% 和91.5%,89.6%,88.9%.
(4)算法 4.多层特征融合.
传统的CNN将输入图像层层映射,最终得到特征提取的结果.通过对AlexNet网络模型进行反卷积可视化可得,末端卷积层Layer5提取的特征具有完整的辨别能力,而卷积层Layer2主要映射的是具有颜色和边缘属性的特征,卷积层Layer3提取的主要是比较有区别性的纹理特征.CNN主要采用的是最终提取的特征,卷积层Layer2、卷积层Layer3对图像也具有一定的表现能力,故本算法将Layer2、Layer3卷积层进行多层再学习融合,具体学习框架如图9所示.

图8 多尺度化提取结构
图9中,虚线框中对应的多层特征融合模块,实验步骤可以总结如下:(1)首先采用Fine-tuning的方式训练学习实线部分的框架;(2)固定学习到的实线部分参数权重不变,如图10,Block块分别为无卷积层、Block1、Block2、Block3 四种情况进行学习;(3)融合第(1)、(2)步骤学习到的特征,进行全连接然后送入分类器中.经过多次实验,对应的四种情况识别精度分别为 82%,85%,87%,92%.
综合上述四种算法,算法1和算法2为常见的CNN改进算法,本文主要就场景识别任务进行了验证,且都达到了一定的提升效果;算法3和算法4在此基础上对网络结构进行了改进,其中算法3对单层网络结构进行多尺度化特征学习,使得最终的表达能力更为丰富,识别精度可以达到与算法1等高的91.5%,但此算法在泛化能力上明显优于前者;算法4使用多层特征融合的方式,考虑到不同特征之间的冗余性,采用不同的Block再学习方式,识别效果和算法3差距比较小,而且它充分利用了不同层次的特征,使得表现力更加多元化.所以,下文将采用算法3和算法4的网络模型作为改进的AlexNet网络模型与原始AlexNet网络模型进行对比,并作相应的评测.

图9 多层特征融合学习框架

图10 多层特征融合学习中Block块的选取
3 实验与分析
3.1 数据集
改进CNN识别能力分析需要选择合适的数据集.深度卷积神经网络在训练过程中需要输入大量的图片进行数据处理,因此实验所用的数据集应该包含丰富的场景信息.其次,所选的数据集应该具有一定权威性和公开性,方便与之前研究方法进行比较.
(1)数据集的选取
本次实验采用数据集为 Fifteen Scene Categories进行前期改进的测试,采用数据集为eight sports event categories dataset进行后期性能的评估,前者数据集包括15类场景图像,每类含有216~400张图像,本实验中每类随机选取100张图像作为训练集,其余剩下的作为测试集,如图8所示部分图像.后者包含8 种体育场景图像,分别为划船,羽毛球,马球,地滚球,滑雪板,槌球,帆船以及攀岩.根据人体判断,图像被分为简单和中等,还为每个图像提供前景对象距离的信息.

图11 Scene15 数据集图像示例
(2)图像预处理
改进CNN分类性能分析需要大量的数据集进行实验评估,但是现实中数据集一般都比较少,无法满足训练网络的要求,所以一般进行实验前都对数据进行必要的数据增强操作,比如旋转、翻转、移动,裁剪等一系列随机变换.
3.2 实验设置
在进行场景识别实验之前,需要构建合适的网络模型学习框架,现如今流行的深度学习框架主要有Caffe、Torch、MXNet以及 TensorFlow,本文实验中采用的是Caffe[9],作为清晰而高效的深度学习框架,其核心语言采用 C++,支持命令行、Python和MATLAB接口,且可以在GPU上运行,直接集成了卷积神经网络神经层,并且提供了如LeNet,AlexNet以及GoogLeNet等示例模型.
(1)实验平台
本文的实验均在ubuntu16.04系统下进行,采用的是Caffe学习框架,其中使用编程语言python,且在图像预处理过程中采用MATLAB.
(2)参数设置
使用caffe进行深度学习时,为了使得更快收敛并获得比较高的识别精度,调参是必不可少的工作,表2为本次实验时根据以往实验的经验进行的参数设置.

表2 Caffe 训练参数设置
(3)采取微调(Fine-tuning)的方式训练模型
在本次研究中,采用的是一种微调预训练卷积神经网络(AlexNet)模型的方法,这样可以更好的解决由于缺乏标记图像而导致的过拟合问题.因为前几层提取的底层特征可以更好的适应不同的问题,故在微调的过程中前几层应该被保持不动,最后的完全连接层是唯一一个可以用于调整权重的特征图层,应修改为合适的数据集标签.另外,在整个训练过程中使用多批次的图像进行学习,批量的大小由于CPU内存决定,图9证实了微调预先训练好的模型是有效的实验方法.

图12 微调 AlexNet模型效果图
3.3 实验与分析
综合上述四种算法的改进,可知算法4和算法3表现得较为明显,提升幅度达到6.2%和5.7%,最差的算法4提升幅度为4.2%,考虑到模型的泛化能力,因此选择算法4和算法3作为最终的改进算法,为了更好的验证改进算法的有效性,将数据集eight sports event categories输入到训练好的改进模型中进行测试,并取最好的实验结果进行比较和作合理的评价.
表3和表4为各种方法分别在两种实验数据集上的识别精度结果,文献[10,11]采用的是传统的手工特征提取的方法,实验表明使用CNN进行自动提取并进行改进远远高于普通手工提取的方法.在Scene15数据集上,改进的算法最终的结果比传统的手工算法高8.1%~13.3%,比改进前 AlexNet高 6.2%;同样的在eight sports数据集上,改进的算法比传统算法高7.2%~15.1%,比改进前 AlexNet高 2.9%.此外,由实验结果可以得知算法4的泛化能力略优于算法3.

表3 不同方法对 Scene15 数据集的平均识别精度
图13为改进模型在 eight sports数据集上的混淆矩阵,分别表示每个运动场景类别的准确度.图13表明了 8 类运动场景中,其中“bocce”、“sailing”场景均可以达到 100% 的识别率,而 “badminton”容易被“polo”和“rowing”混淆,识别率相对表现得有点逊色,其他运动场景类均可以达到90%以上的识别率.

表4 不同方法对 eight sports 数据集的平均识别精度
4 结论与展望
为了获得高质量的网络模型,本文首先从常规的改进方法出发(即增加模型的深度或者其宽度),并在场景识别任务上进行了测试;接着提出多尺度化特征提取和多层特征融合的改进方法,分别测试其识别效果;最终通过实验结果的比较选择最适合场景识别任务的改进模型,并选择常用的数据集进行了有效性的验证.实验表明,本文的改进方法优于一般常见的识别算法.

图13 改进模型在 eight sports 数据集上的混淆矩阵
基于本文的研究,后续的工作将从两方面开展:首先选择其他比较深的网络模型进行改进,比如VGG和ResNet网络,探索出更加优化的网络模型;其次保证高精度识别的同时,提高其识别的效率,此外结合迁移学习的思想对模型的泛化能力进行优化.
