基于地理标签的LBSN链接预测模型①
2019-01-07王勇,王超,程凯
王 勇,王 超,程 凯
1(铜陵有色金属集团股份有限公司金冠铜业分公司,铜陵 244000)
2(金诚信矿业管理股份有限公司,北京 100044)
3(北京宸控科技有限公司,北京 102200)
随着智能手机的爆炸式发展,用户可随时随地在各大社交平台分享自己的地理位置信息.无论是视频、图片或文本信息,都可轻易地嵌入当前用户的地理位置标签(Location Tag).大量的位置Tag构成了基于地理位置的社交网络[1](Location-Based Social Networks,LBSN),结合现有的各种定位系统,可以为用户提供一些个性化服务.根据LSBN中已经存在的链接和节点信息,可以预测出用户位置网络中遗失的Tag或即将出现的Tag链接,该方法称之为链接预测[2].例如,在微博、微信等社交平台中,用户等同于节点,链接预测可用于建立新的好友关系.
文献[3]表明,同一时间出现在同一位置的用户成为好友的概率要远高于处于不同地理位置的用户.因此,挖掘LBSN中潜在的标签信息对实现链接预测具有重大意义.目前,国内外已有很多科研工作者专注于基于地理位置标签的推荐算法研究,判断用户地理位置的途径主要有两种:第一,挖掘用户发布到互联网中的内容信息可推断出用户的地理位置信息[4].第二,通过社交平台中好友的地理位置推测用户的位置[5].近年来也有很多学者研究基于LDA主题建模的层次聚类[6]、无监督学习[7]、标签关联[8]推荐算法.为提高位置预测的准确性,可对用户位置信息进行筛选,过滤掉无用的信息.还可对用户签到信息建立LDA主题生成模型,分析地理位置标签的特征,设计出基于地理位置的推荐系统[9].
从用户签到信息中提取出时间特征和位置特征对于链接预测算法至关重要,因为这些特征可用于评估用户之间的相似度,进而提高预测的准确度.然而实际的LBSN签到信息中,地理位置的分布十分稀疏,想要挖掘出位置和时间信息相当困难.基于用户地理位置标签,本文建立了新的LBSN链接预测模型,提高了链接预测的准确度.首先,本文对Gowalla数据集进行聚类分析,改善了地理位置分布的稀疏性问题.其次,本文对用户地理位置标签进行语义分析,建立基于用户地理标签的LDA主题模型,采用Gibbs抽样算法进行参数估算,分析出用户的地理位置标签的相似性特征.最后,本文综合网络结构相似性特征和基于用户地理位置信息的相似度特征,采用有监督策略的链接预测在Gowalla数据集上进行实验.实验结果表明,本文提出的模型能有效提高LBSN的链接预测准确度.
1 基于地理位置的 LDA 主题模型
本文对LBSN中的用户地理位置标签建立LDA主题模型,以便挖掘出用户的行为偏好.用户的位置标签集合可当作一篇文档,位置标签集合中的某条具体位置相当于构成文档的词汇.对该主题模型进行求解,可得出用户地理位置标签中隐藏的主题分布和地理标签主题下的位置分布.
假定用户u对应的地理位置标签集合为相当于一篇文档,其中m代表用户u的位置标签条数,wu,i代表用户u的第i(1≤i≤m)条位置标签信息,相当于构成文档的某个词汇.地理位置文档集合为,其中M代表用户数量.假定具体的位置数量为V,则可建立基于地理位置的LDA主题模型,如图1所示.

图1 基于地理位置的 LDA 主题模型
模型中的位置主题概率分布可用Gibbs[10]采样算法估算得出,该分布可用一个 doc-topic矩阵来描述,用户u在地点主题tk下出现的概率分布可表示为.同理,每个位置主题下对应的位置概率分布可用一个topic-word矩阵来描述,其中 pk(φv)代表位置v在主题k下出现的概率.
2 基于位置信息的相似度分析
2.1 位置信息语义化
本文实验使用的数据集是Gowalla的地理位置标签数据集,可从SNAP官网直接下载得到,用户地理位置标签的存储格式为:

Checkini,j表示用户i的第j条位置信息.此外,该数据集还记录了用户之间的好友关系.具体示例见表1和表2.

表1 地理位置标签格式

表2 用户好友关系存储格式
由于数据集并没有具体的地理语义信息,故需要先对其进行语义化.本文采用百度公司免费的Place API和 Geocoding API进行语义转换,可将数据集中的地理坐标转换为具体的地址以及附近的POI (Point Of Interest)信息.
由于很多用户只在某一个地点签到过,或跟其他用户没有共同的签到地点,这类用户称之为孤点用户.大量的孤点用户造成了数据的稀疏性,严重影响链接预测的准确性.为解决该问题,本文降低了具体地点的限制,对地点标签进行层次聚类,以签到区域来构建用户关系网络.设定一个距离阈值 δ,若不同签到地点的距离不超过该值,则认为两个地点属于一个区域,本文在实验章节会对该参数进行调优试验.然后利用该距离阈值对签到数据集进行聚类,可得到区域集合D={d1,d2,···,dn},由此可得到区域矩阵:

式(1)中的di,j代表第i个用户在区域j处的签到.显然,利用区域矩阵来构建用户网络关系可极大地减小孤点用户的数量,对签到地点标签信息的挖掘也更充分,因此可降低数据稀疏性的影响.
2.2 基于位置信息的相似度分析
上文提到,采用Gibbs采样算法可估算出LDA主题模型中的两个概率分布:位置主题分布 Θ和所有主题下的地理位置分布 Ψ .每个用户的签到主题分布可以表示成K个位置主题的概率组合,所有用户的签到主题分布构成矩阵 Θ.每个主题下的位置分布可以表示为签到位置的概率组合,所有主题下的签到位置分布构成矩阵 Ψ .利用本文的签到语义数据集,Gibbs采样可输出矩阵 Θ 和Ψ .
本文首先筛选出位置主题概率最大的K个主题来表达用户的位置主题.K的取值可按照经验预设,剩下的主题概率可先置0.本文先设定K=5,在模型学习的过程中会对K值进行不断的修正.然后对这K个地理位置主题分布函数进行归一化处理,如公式(2)所示:
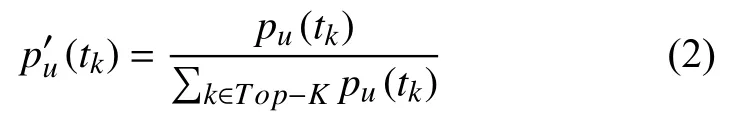
对于两个不同用户产生的概率分布函数,需要计算出二者之间的距离.统计学中的KL 散度(KLDivergence)可用于测量不同概率分布的差异,被广泛应用于基于LDA的推荐算法.然而KL散度并不适用于本文基于地理位置标签的链接预测算法,因为该方法具备非对称性特征.如果两个用户对某主题都无兴趣,KL散度得出的结论是这两个用户具有很高的相似性.同理,如果两个用户都没有在某个地点签到,那么KL散度会认为他们具有很高的相似度,这显然会造成极大的误差.因此,本文采用一种新的方法来评估用户之间地理位置主题的差异性.用户i在k个地理位置主题下的位置总数设为N(i,tk),则不同用户x,y之间的相似度可用公式(3)计算得到:

其中,分子代表用户x和y在k个主题下的位置总数最小值之和,该值越大,说明用户x和y在同一区域签到的数量越大,二者的相似度越高.式(3)进行了归一化处理,最终结果可用于计算用户之间的相似度.
最后,为了验证fW(x,y)的有效性,基于从当前数据集中获取的网络关系,本文将对比分析和fW(x,y)的性能.LBSN链接网络中基于fW(x,y)的好友用户对与非好友用户对的累积分布图(CDF)如图2所示.
从图2可看出,基于位置标签语义分析的用户相似性特征fW(x,y)能够有效地识别好友与非好友的区别.因此可得出结论,fW(x,y)对于分析用户之间的链接预测具有重要意义.
3 基于地理标签的LBSN链接预测模型
3.1 实现方法
本文通过对用户地理位置信息的充分挖掘,得出了基于地理位置语义分析的相似性特征.这是本文所提出的链接预测模型的基础.机器学习中的监督式学习算法经常被用于推荐系统的设计,将收集到的海量训练数据集作为先验知识,建立一个模型,并根据输入的标签不断修正该模型,最终该模型可针对新的输入预测出相应结果.本文的链接预测算法基于有监督学习的思想,输入为Gowalla数据集中的位置标签,建立用户特征向量函数,对其进行模型训练,最终可用于链接预测.
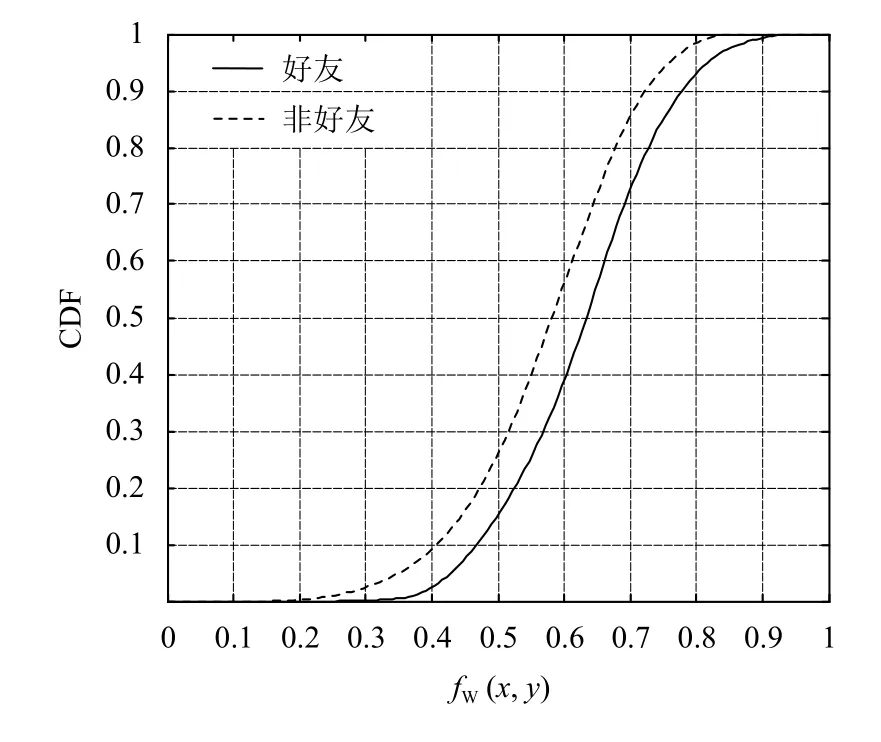
图2 fW(x,y)好友与非好友用户的CDF曲线
接下来,本文将采用有监督学习的策略对其进行链接预测.实验中,LBSN链接预测采用Gowalla数据集进行仿真,使用LBSN基于地理位置语义分析的相似性特征进行辅助实验.本文实施的链接预测实验步骤如下:
(1)筛选原始数据集,过滤掉其中无用的冗余信息和独立用户(即无任何好友关系的用户),最总得到一个可用的LBSN社交关系网络图G=(V,E).
(2)对集合E进行随机采样,其中2/3的数据作为训练集ET,余下1/3的链接数据作为测试数据集EP,显然E=ET+EP且ET∩EP=Ø.从集合ET中取出现有链接中所有的用户集合V′∈V且V′≠V,则子网络图G′=(V′,E′).由V′可将测试数据集修正为EP=E′∩EP,所以空间集合 (V′×V′)-ET可用来表示一切隐含节点对的集合.
(3)由V′可得出所有用户的位置标签列表,获取这个列表集合中的地理位置信息,对其进行聚类,最终得出一个新的用户-位置矩阵.
(4)分析求解隐藏的用户节点信息中基于地理位置的相似性特征fUP(x,y).
(5)同理,分析求解隐藏的用户节点对基于时间戳的相似性特征fT(x,y).
(6)采用Gibbs抽样算法估算出用户基于地理位置主题的概率分布函数,然后进一步求解隐藏用户节点对基于地理位置信息的用户相似度特征fW(x,y).
(7)对社交网络中所有隐藏用户节点之间的相似度进行分析计算,此处主要记录预测性能最佳的Resource allocation (RA)系数指标SRx,Ay.
(8)利用有监督学习策略的算法,对上文计算得出的各类相似性特征做链接预测,最终可得出特征向量,然 后对其进行模型训练,最后再对测试数据集进行链接预测,得出基于地理标签的LBSN链接预测结果.最终得到的结果集中,用1标注确实存在的链接节点信息,0标注不存在链接的节点信息.
3.2 评估方法
将上文求解得到的结果集与测试数据集做对比,可分析出本文链接预测算法的性能.由于本文采用有监督的链接预测算法,故采用信息检索算法中常用的四大性能评估指标来衡量本文算法的性能优劣:精度(Accuracy)、准确率(Precision)、召回率(Recall)以及综合Accuracy和Precision的加权调和平均(F-measure).
由于实验数据中链接分布不均匀,本文还采用了一个新的评估指标 AUC(area under the receive operating characteristic curve)[11],如公式 (4)所示:
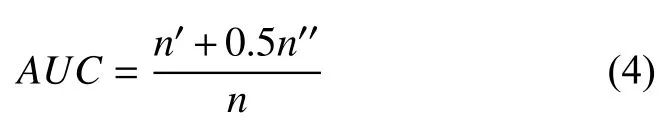
其中,n代表测试数据集中所有标签对被随机独立抽样的次数,对于链接节点对而言,包含了存在和不存在两种情况.n′表示链接节点对存在时的相似度分数大于不存在时的次数,n′′则表示两种情况相似度分数相等的次数.从上式可看出,若存在链接的相似度值大于不存在时,则相似度值加 1,若相等则加 0.5.因此,AUC 指标能够整体地评估链接预测模型的准确度,其值得取值范围是 (0 .5,1),AUC的值越大,表示链接预测模型的精准度越好.
3.3 参数调优
本文采用有监督学习的方式对样本进行分类学习,基于前人对的研究,我们可获取关于类别特征的先验知识.基于已有的类别特征信息,可对模型进行训练并构造相应的分类器.由于本文采用的是真实的Gowalla数据集,故存在样本数据分布不均匀的情况.为深入挖掘该数据集中的隐藏信息,可采用机器学习中常用的k-折交叉验证 (k-fold cross Validation)法,该方法得到的实验结果更加真实.实验证明,当k值取10的时候可得到最佳的实验效果[12],故本文采取10倍交叉验证来评估模型的性能.
上文提到,本文利用有监督的学习思想对模型中需要输入的参数根据经验预先给出,然后通过实验对其不断修正.本文模型中有三个输入参数需要进行调优:对地理位置信息聚类处理时的距离阈值δ,基于用户地理位置标签的LDA主题模型中的主题K的取值,以及分析用户相似度时TOP-K中K的取值.
对距离阈值 δ分别取不同的值,可得到用户基于地理位置标签的相似度特征函数fUP(x,y),现将该特征函数导入样本分类器进行链接预测,实验得出的距离阈值 δ与加权调和平均F值的关系如图3所示.

图3 距离阈值δ 对链接预测性能影响曲线
由图3可知,当链接预测距离阈值δ=500 m 时,链接预测的结果最优.当 δ ∈[400,700]时,该算法的链接预测效果较为良好.此外,随着 δ的不断增大,加权调和平均F值不断减小,即距离越大,链接预测效果越差.当 δ >1km时,F值的值显著降低,说明人与人之间的地理位置距离越远,两者之间的关系也会越生疏,该结论显然符合人类社会客观事实.基于以上分析,本文对地理位置标签进行层次聚类时的最优距离阈值设定为500 m.
上文提到,基于地理位置的LDA主题模型可采用Gibb采样算法进行分析求解,最后得出用户地理位置主题分布 Θ和每个主题下的具体地点分布 Ψ .根据 Θ和Ψ这两个概率分布函数计算出基于地理位置标签信息的相似性特征函数fW(x,y).Gibbs采样算法需要预设的参数是 α,β 和K.其中,α和 β是Dirchlet先验分布的经验参数,由于在对数据进行抽样的过程中会不断地更新 α和 β,因此这两个值先根据经验预设即可,本文设定 α =0.1,β=0.01.LDA主题模型中主题个数K值的选取十分重要,故本文对其进行参数调优实验.分别对不同的K值计算基于地理位置标签信息的相似性特征函数fW(x,y),然后根据fW(x,y)进行链接预测实验.实验结果如图4所示,该图展示了主题个数K和加权调和平均F值的关系.由图可知,当主题个数为13时链接预测性能最优,因此本文实验设定K=13.
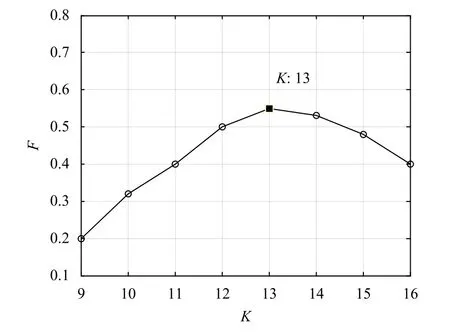
图4 主题个数K选取对预测性能影响曲线
为了以最低的时间复杂度计算出特征函数fW(x,y),并取得最优的链接预测效果,本文将对地理位置标签主题进行TOP-K选择,然后根据选取的TOP-K个主题计算基于地理位置标签信息的相似性特征函数fW(x,y).实验结果如图5所示,途中展示了TOP-K值与加权调和平均F值的关系.从图中观察到当TOP-K≥10时,F值较高且相对平稳,而当TOP-K=5时F值达到巅峰,故本文选取TOP-K=5进行链接预测实验.
3.4 实验结果与分析
本文在第3.3小节进行了相关参数调优,接下来本文将使用开源的智能分析环境WEKA提供的几种分类器对Gowalla数据集进行链接预测实验:朴素贝叶斯分类器(NB)、随机森林分类器(RF)以及决策树分类器(J48).分别对特征向量和单一的用户网络特征进行实验,并对比分析两种不同算法的性能.采用的评估指标是Precision、Recall、F-measure和AUC,这些指标值是通过对比链接预测的实验结果和测试数据集中真是的数据作对比所得出的,如表3所示.

图5 Top–K主题个数对预测性能的影响曲线
从表3中还可看出,以上两个实验中链接预测性能优劣为随机森林算法优于朴素贝叶斯算法,而朴素贝叶斯算法又优于决策树算法,单三者之间并无明显差异,说明本文提出的算法具有良好的稳定性,不同分类器对该算法的影响几乎可以忽略不计.
表3 预测结果对比

表3 预测结果对比
分类器 朴素贝叶斯(N B)随机森林(R F)决策树(J 4 8)提升(%)提升(%)提升(%)f e a t u r e(x,y)⇀P r e c i s i o n0.9 2 0 8.6 0.9 2 1 8.6 0.9 1 8 8.5 R e c a l l0.7 5 9 4.1 0.7 6 2 4.2 0.7 5 8 4.1 F-m e a s u r e0.8 4 0 4.9 0.8 3 4 4.9 0.8 3 3 4.9 A U C 0.8 9 7.5 0.9 1 5 8.4 0.9 1 4 7.9 S R A x,y P r e c i s i o n0.8 4 7 0.8 4 9 0.8 4 8 R e c a l l0.7 2 9 0.7 3 0 0.7 2 9 F-m e a s u r e0.7 8 2 0.7 8 5 0.7 8 4 A U C 0.8 3 3 0.8 3 0 0.8 3 6
4 结论与展望
为解决地理位置分布的稀疏性问题,本文对测试数据集进行聚类分析,并建立了基于用户地理标签的LDA主题模型,分析出用户的地理位置标签的相似性特征.最后,本文综合了网络结构相似性特征和基于用户地理位置信息的相似度特征,采用有监督策略的链接预测在Gowalla数据集上进行实验.实验结果表明,本文提出的模型能有效提高LBSN的链接预测准确度,且具有良好的稳定性.然而随着互联网的发展,LBSN的数据规模呈现指数级的增长,未来可进一步研究基于大数据分布式平台的链接预测算法.
