基于案例推理的工业园区废气污染溯源方法研究
2019-01-05张春梅贾云霞李晓云
张春梅, 贾云霞, 李晓云, 王 晨
(1. 太原市环境监测中心站, 山西 太原 030002; 2. 山西大学 物理电子工程学院, 山西 太原 030006)
0 引 言
改革开放以来, 我国经济发展和社会建设取得了巨大的成就, 但与此同时, 人们的环境保护意识淡薄、 人类的各种活动与自然环境的不和谐也导致了各类环境问题的出现. 近年来, 特别是党的十八大以来, 生态文明建设得到高度重视, 我国总体环境得到了一定程度的改善, 但具体环境状态依旧不容乐观. 2016年, 全国338个地级及以上城市中, 有84个城市环境空气质量达标, 占全部城市数的24.9%; 254个城市环境空气质量超标, 占75.1%; 平均优良天数比例为78.8%, 比2015年上升2.1个百分点; 平均超标天数比例为21.2%. 超标项主要包括细颗粒(PM2.5)、 可吸入颗粒物(PM10)、 二氧化氮(NO2)、 二氧化硫(SO2)和一氧化碳(CO)等[1].
目前, 环境保护已经成为我国可持续发展的重要环节和关键任务, 而全国范围内环境污染问题突出, 特别是工业园区在污染监测、 控制、 管理等方面存在较多问题,工业园区聚集了大量的工业企业, 在推动各地区工业发展、 经济技术及科学发展方面发挥着重要作用. 近年来工业园区(经济园区)在各地繁荣兴盛起来, 甚至有不少园区已经取得了一定的经济效益, 成为推动地区经济增长的重要因素. 然而众多工业园区在其实际发展中也排放出大量污染物, 成分复杂, 监测的范围广, 导致园区环保监测出现网络建设缺乏系统规划、 决策因子缺乏代表性、 监管规范不完善等问题. 工业园区的空气质量不仅直接影响园区自身的环境水平, 而且影响着所在区域甚至整个城市的大气环境. 如何对工业园区内不同类型的企业进行废气排放方面的有效管理, 已经成为园区环境管控乃至城市环境保护的重点工作.
通常情况下, 由于工业园区成分复杂, 加之地形、 时间等限制因素, 不能准确直接定位污染排放企业的位置. 目前, 主要以两种思路研究废气污染溯源模型与方法: ① 基于数理统计、 概率论而形成. 此种思路基于大气扩散的数值分布, 运用各种算法统计分析确定排放源的位置; ② 以优化理论为契机, 在确定目标函数的基础上, 计算出其最优化解[2]. 殷凤兰等人主要从概率统计学的角度展开研究, 首先确定点源位置、 个数, 并基于最佳摄动量正则化算法得出污染源强数值[3]; 文献[4]中定义了气体泄漏源、 反算污染源参数, 首先通过模式搜索法进行定义, 然后以贝叶斯推理法进行计算. 此种算法通常以经验为依据假设模型参数, 需观测大量数据进行分析, 计算量大, 适用于气体泄漏的溯源工作. 对于优化理论方法在气体溯源的研究方面, 骆蓓、 邹吉然、 史阳、 张久凤等学者[5-8]基于气体浓度的实际观测值及其理论计算值, 确定目标函数然后再利用各种人工智能算法求解目标函数的最优解. 本文提出的基于案例推理的气体污染溯源方法, 可以突破单一气体追溯的限制, 以整个工业园区作为研究对象, 综合园区环境和周边, 综合分析气体污染源.
1 案例推理概述及推理过程
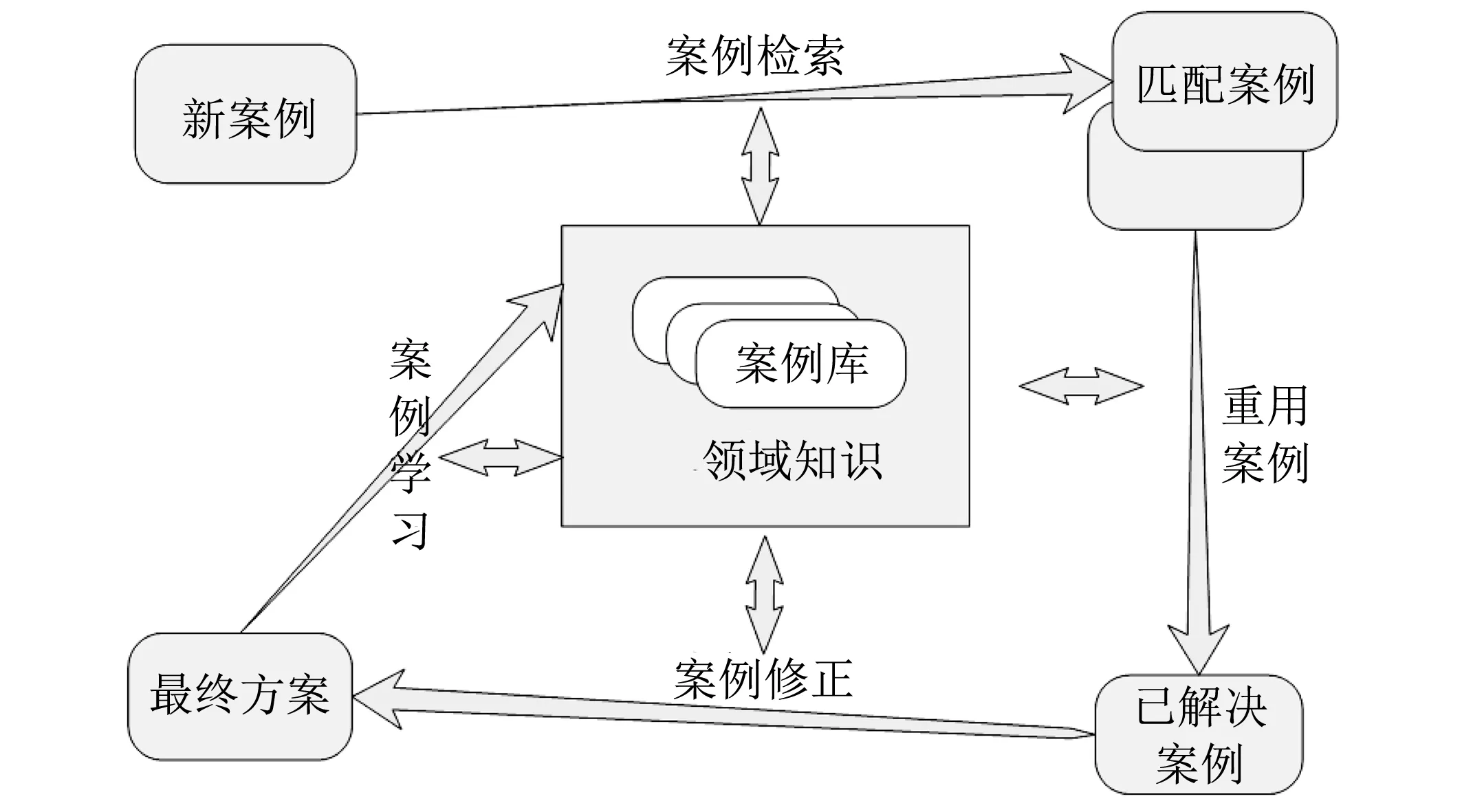
图 1 案例推理模型Fig.1 Case-based reasoning model
案例推理即CBR(Case-based Reasoning)技术最早出现在Roger Schank对计算机和人的提醒和学习理论的动态记忆的描述中[9], 是智能领域中应用比较多的关于知识的问题求解方式和学习方法, 它对已有的经验和案例作为知识单位进行存储, 核心思想是利用过去解决类似问题的经验来解决新的问题. R4 模型是CBR中应用最普遍的一种模型, 如图 1 所示, 通常包含4大步骤: ① 案例表示; ② 案例检索; ③ 案例修正; ④ 案例学习. 图 1 较为详实地介绍了CBR的整个过程.
1.1 案例表示
案例表示即以结构化的形式描述相关知识. 选择何种案例方式, 则何种描述方式将对整个案例的效率、 性能形成较大的影响. 有很多方法都可用于案例表示, 一般认为只要适用于知识表示, 其通常也适用于案例表示.
现阶段最为典型的案例表示方法主要有: 语义网、 框架表示、 本体描述等, 每种方法各具优缺点, 适用的范围也各不相同. 案例表示实际上就是对已知案例的一种描述, 同一案例可以有不同的表示方式, 而不同的表示方式对案例推理的性能影响也不尽相同, 案例表示合理可以使推理变得简单高效, 不合理的表示会使推理辨识繁琐和低效.
本体描述语言是案例表示的一种形式, 常用于对异构知识的表示中. 本体表示具有逻辑性、 易于表示、 清晰度较高, 所以被普遍应用. 本文基于此建立废气污染溯源通用本体模型.
1.2 案例检索
案例检索是CBR非常重要的过程, 直接影响着案例推理的效率和结果, 也是CBR步骤中专家学者的研究重点, 目前已经形成了丰富的案例检索法, 其中决策树法、 最近相邻法得以最普遍的应用.
在废气污染溯源推理案例检索过程中, 采用了计算相似度的检索方案, 考虑到影响因子的特殊性, 即具有模糊性、 不确定性等特点, 所以在计算相似度时采用直觉模糊粗糙集方法.
1.3 案例修正
尽管案例匹配时能找到与待解决问题匹配度很高的相似案例, 但是自然因素和社会环境瞬息万变, 很难保证匹配案例和待解决问题完全一致, 所以必然会形成不同的解决方案. 基于此, 应结合其它方法进行修正. 本文引入专家意见法, 希望通过此法提高修正的可靠性, 将通过案例检索已经解决的案例交由专家系统进行调整, 对其不合理的部分进行修正以提高案例匹配的准确度.
1.4 案例学习
案例学习是指新问题解决后的最终方案保存至案例库, 以供后续问题参照, 使得推理系统案例和知识不断得到补充和完善. 因此, 案例学习步骤体现了案例推理自学习、 自适应的特点. 本文采用最简单的案例学习方法把已解决问题作为案例补充到案例库.
2 废气污染溯源推理方法
追溯污染气体排放源头、 定位污染排放企业是管理废气污染时需要解决的重要问题, 很多学者以往的溯源研究一直局限于园区本身条件来进行溯源, 本文提出基于案例推理对废气污染进行溯源的推理方法. 溯源推理总体思路就是首先根据其他工业园区污染溯源案例库, 与待解决的工业园区案例信息进行检索匹配, 找出与之相匹配的最佳案例, 然后根据匹配案例比较分析得出废气溯源结果.
2.1 废气污染案例表示
在设计废气污染溯源推理本体模型时主要以环境领域的有关概念为依据, 结合领域专家的经验、 知识描述废气污染源[10], 同时所形成的废气污染溯源推理主体必须得到领域专家的认可, 从而正确阐释说明影响本体概念的要素. 本文定义废气污染溯源推理本体模型, 构建了废气污染溯源推理的指标体系并给定指标间的关系, 如图 2 所示.
废气污染溯源推理案例是基于废气污染溯源本体模型进行案例表示, 废气污染溯源推理案例包含了本体中关键影响因子, 并表明影响因子的相互作用. 案例搜集主要收集了国内近几年来各工业园区的有关案例, 并总结分析了其污染类型、 环境因素、 爆发情况等等, 最终得出表 1 的结果.

表 1 废气污染溯源案例库部分案例信息
由于篇幅有限, 表 1 仅仅列举了案例库中的部分案例及部分案例信息, 案例库实际收集整理了183个工业园区案例.

图 2 废气污染溯源本体表示 Fig.2 The source of exhaust pollution traceability
2.2 废气污染案例检索与匹配
2.2.1 复杂网络关联特性模型

图 3 废气污染溯源总网络表示Fig.3 Total network representation of exhaust pollution traceability
废气扩散过程中会涉及到气体之间、 气体与外界环境之间的相互作用, 周边环境(包括自然和人文环境)的各种物质都会通过一定的相互作用联系在一起, 这种联系或大或小, 相互作用的强度也存在一定差异性. 考虑到扩散内部的实际情况, 即内部关系复杂加之尚未能明确扩散机制, 所以为了更为准确地描述废气污染扩散, 本文引入复杂网络关联特性模型.
节点之间的连线段用来表示各个概念之间的相互关系, 节点集合形成点集V(V={v1,v2,…,vi,vn}), 其中Vi表示第i个节点, 网络节点总数为n, 连线集合形成边集合E(E={e1,e2,…,ej,…,em}), 表示第j条边, 边总数为m.
在废气污染溯源过程中, 结合影响因子的性质, 一般认为影响因子可细分为子网络、 总网络. 前者用于细分后者的属性, 后者表示污染案例的综合属性. 具体如图 3, 图 4 所示.

图 4 废气污染溯源子网络表示Fig.4 Network representation of exhaust gas pollution traceability
根据废气污染溯源总网络和子网络影响因子集合表示如下.
总网络集合形式:V={自然环境, 排放类型, 经济因素, 人文环境}.
自然环境:V1={光照强度, 地理位置, 湿度, 空气温度, 风速, 风向, 大气稳定度, 周边环境, 地面覆盖物}.
排放类型:V2={突发泄漏, 持续排放, 间断排放}.
经济因素:V3={处理投资力度, 二次污染}.
人文环境:V4={人口流动性, 人口密集度, 废气处理方式}.
总网络中Vi表示总网络的第i个影响因子,Vik表示第i个子网络的第k个影响因子.
2.2.2 网络节点[11]权重优化确定

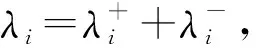
(1)
Uk用于表示信息节点的难易程度, 利用式(2)即可计算
(2)
式中:Uk用于说明k个节点的网络效率, 是衡量节点重要性的重要指标.Uk越大, 该节点与其他节点间的传输效率越高, 网络效率越好, 该节点在网络中的作用越大.
根据图 2 和图 3 给出的总网络与子网络间相互关系可求得该网络特征参数为
λ=[3,2,2,3];λ+=[0,2,1,2];λ-=[3,0,1,1],
δ表示节点之间的直接连接度, 若两个节点之间有连线则δ=1, 否则δ=0.
将以上参数代入式(2)中可得总网络中各节点的重要性
网络中节点对案例匹配结果影响的重要程度与节点间相互关系及网络节点拓扑结构相关. 为了描述这种节点贡献度, 引入节点贡献度矩阵概念, 计算式如(3)所示.
(3)
式中:k表示网络节点度的平均值, 从式(3)中可以看出:Hc表示所有节点之间的作用强度. 但是节点的网络效率除了与其他节点间的作用用关, 还与自身的网络效率有关, 因此节点贡献度矩阵
(4)
结合节点贡献度矩阵分析可知: 通过分析节点间拓扑关系及位置信息可说明节点的贡献度. 节点贡献度矩阵HEij表示第j个节点对第i个节点的贡献值. 考虑节点自身的网络效率和对其他节点的网络效率, 定义节点总网络贡献度
(5)
对节点总网络节点贡献度矩阵归一化得到网络节点权重
(6)
由此得到总网络的节点权重为ω=[ 0.364 9,0.135 1,0.135 1,0.364 9]. 各子网络节点权重分别为
ω1=[0.032 1,0.042 5,0.238 5,0.123 1,0.221 4,0.008 4,0.019 2,0.132 1,0.182 7],
ω2=[0.314 9,0.457 1,0.238 0],
ω3=[0.268 7,0.573 4,0.167 9],
ω4=[0.418 9,0.357 1,0.234 0].
2.2.3 案例匹配
案例库中的节点属性一般可分为3种类型: ① 选项型; ② 数值型; ③ 布尔型. 对于持续排放、 突发泄露等布尔型和选项型数据, 在匹配案例时, 需要对比属性值, 假设经对比完全相同, 则认为其节点的属性匹配度为1, 不同或者案例节点缺失则节点属性匹配度为0. 对于湿度、 风速等数值型节点属性, 考虑复杂环境下的数值模糊度, 所以选用直觉模糊粗糙集匹配[12]方法.
令集合为R, ∀x∈R中的上近似和下近似分别表示为x+和x-, 则模糊集S可表示为
S={〈S,μS-(x),μS+(x),λS-(x),λS+(x)〉|∀x∈x},
(7)
式中:μS-∶S-→(0,1),μS+∶S+→(0,1)分别代表S的下近似隶属度函数和上近似隶属度函数, 分别用来表示案例节点的负面影响和可能的负面影响.
λS-∶S-→(0,1),λS-∶S+→(0,1)分别代表S的下近似非隶属度函数和上近似非隶属度函数, 分别用来表示案例节点的正面影响和可能的正面影响.
以湿度为例, 结合实践经验定义湿度对废气溯源推理的正面影响和负面影响, 得到湿度正面隶属度函数λ(SD)和湿度负面隶属度函数μ(SD), 如式(8)和式(9)所示.
(8)
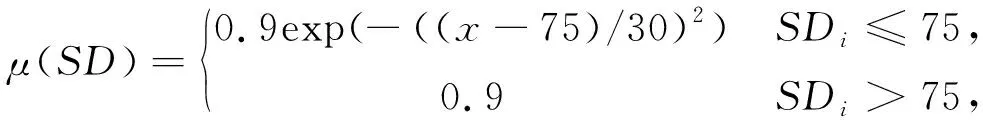
(9)
式中:λ(SD),μ(SD)均作为模糊粗糙集的下近似. 同理, 其他数值型均可用λ和μ表示.
对于非空论域X={x1,x2,…,xn}上的模糊粗糙集S1和S2, 相似度计算[13]如式(10)所示.

(10)
式中:πS1(x)=1-μS1(x)-λS1(x),πS2(x)=1-μS2(x)-λS2(x),πS1(x),πS2(x)分别刻画了S1,S2自身存在的粗糙程度.
在案例匹配时, 需要综合考虑案例总网络以及子网络的节点贡献度和节点间贡献度求解案例对比相似度, 案例综合相似度
(11)
式中:Spq表示案例p和案例q的相似度;ωi表示总网络中第i个节点的贡献度;ωij表示第i个子网络中第j个节点的贡献度;Mij表示第i个子网络中第j个节点的相似度, 求解实际问题和案例库中每个案例的相似度进行比较, 确定匹配案例, 即案例中相似度最大的, 并对比0.5, 当案例最大相似度大于等于0.5 时匹配案例可用, 此时可将该案例交由专家审阅, 如果通过专家审阅即可用于实际项目. 相反的如果相较于 0.5 该案例的最大相似度较小, 则说明当前案例库中并无可匹配于待解决的问题. 这不仅有助于形成有交性的决策结果同时可确保更新后案例库的准确性.
3 案例推理方法实现与分析
针对废气污染溯源案例推理方法进行验证, 以案例库中衡水循环经济园区的案例信息为例, 获取案例信息情况如表 2 所示.

表 2 衡水循环经济园区案例库相关信息
首先使用本文所采用的案例匹配方法对布尔型与选项型属性节点进行匹配, 匹配后得出与衡水循环经济园区相匹配的包括案例库中的案例4柳州洛维工业园区、 案例7临沂工业园区、 案例8菏泽鲁宏工业园区等案例; 然后使用本文所采用的模糊粗糙集进行数值型属性节点匹配, 在此基础上可确定匹配筛选案例及衡水案例情况.
结合Ih=52%, 筛选各案例湿度I4=38 μg/m3,I7=57 μg/m3,I8=43 μg/m3, 结合模糊计算公式, 确定直觉模糊粗值.S={〈S,μS-(x),μS+(x),λS-(x),λS+(x)〉|∀x∈X}}, 具体为
案例(衡水循环经济园区)湿度与其它案例湿度相似度可用式(10)计算.
M(Ih,I4)=0.532 4,
(16)
M(Ih,I7)=0.943 4,
(17)
M(Ih,I8)=0.523 2.
(18)
按照上述所有方法计算确定所有数值型的相似度, 与布尔型及选项型的相似度一起代入式(9)可算出综合贡献度分别为
Sh4=0.362 7,
(19)
Sh7=0.563 9,
(20)
Sh8=0.482 1.
(21)
通过对比表明: 案例7的综合贡献度大于阀值(0.5), 且最大, 因而本文将该案例作为衡水循环经济园区废气污染溯源的最佳匹配案例, 溯源结果与案例7临沂工业园区的结果一致, 污染均来源于园区西南角的化工企业, 与案例库的信息相一致, 从而证明了本文所提方法的准确性.
4 结 论
本文针对工业园区废气污染溯源的实际应用问题, 构建了废气污染溯源推理本体模型进行案例表示, 并在案例搜索的过程中构建了复杂网络关联特性模型, 定义了节点贡献度的概念和网络贡献度公式, 同时引入直觉模糊粗糙集进行案例匹配, 基于案例推理方法实现了废气污染的溯源工作, 借助衡水循环经济园区真实案例进行案例推理方法实现, 实验结果表明了该方法的推理准确性.
