基于卷积神经网络和支持向量机算法的马铃薯表面缺陷检测
2019-01-04许伟栋赵忠盖
许伟栋,赵忠盖
(江南大学轻工过程先进控制教育部重点实验室,江苏 无锡 214000)
中国是马铃薯资源大国,年种植面积和产量均位于世界前列[1]。马铃薯的经济效益与马铃薯深加工业的水平息息相关,而去除有表面缺陷的马铃薯是实现马铃薯深加工的前提。目前,中国马铃薯表面缺陷检测行业大都采用人工检测方法,该方法存在效率低、主观性强、成本高等缺点[2]。机器视觉检测技术具有功能多、人工干预少、非接触、精度高等优点[3],能很好地代替人来进行检测。因此近年来,基于机器视觉的马铃薯表面缺陷检测方法逐渐成为人们关注的焦点[4]。
Hassan[5]选取HSI三种颜色特征参数,结合马铃薯缺陷物理特征,人工设定阈值,对分类器进行训练,实现马铃薯表面缺陷检测。但是,该方法需要人工确定阈值,鲁棒性和移植性较低。李锦卫等[6]采用快速灰度截留法分割出马铃薯表面疑似缺陷区域,并选择面积比率和十色比率作为缺陷判别特征,对分割出的深色区域采用阈值法进行缺陷识别。但是,该方法只能检测黄色薯皮的马铃薯,具有一定的局限性。Raz等[7]利用图像分割算法对马铃薯表面缺陷区域进行提取,然后提取颜色特征训练SVM分类器,对马铃薯图片各像素进行分类,缺陷识别准确率达95%左右。Barnes等[8]提出基于机器视觉的像素级分类器的马铃薯表面缺陷检测方法,该方法将马铃薯与背景分割后,首先提取与给定像素区域的颜色和纹理相关的候选特征集合,然后使用自适应增强算法(Adaptive Boosting,AdaBoost)自动选择最佳特征,用于检测马铃薯表面缺陷。但是,该方法分类准确率有待提高。现有研究虽然取得一定成果,但是传统检测方法均采用“检测目标区域分割-人工特征提取和描述-分类算法识别”的模式,马铃薯特征的好坏对分类器性能有着至关重要的影响,而马铃薯生长环境复杂,缺陷种类繁多且部分缺陷目标非常细微,设计并提取好的特征绝非易事。因此,本试验研究了采用卷积神经网络自动提取马铃薯表面特征并利用支持向量机(Support Vector Machine, SVM)完成分类的新方法。
近年来,携着“深度学习”之势,神经网络重新归来,再次成为最强大的机器学习算法之一。卷积神经网络(Convolution Neural Networks,CNN)是神经网络的延伸,它的权值共享和稀疏连接特性使之更类似于生物神经网络,不仅降低了网络模型的复杂度,减少了权值的数量,而且直接将图像作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建过程[9]。当前CNN已被广泛应用于各图像分类问题中。Faghih-roohi等[10]采用深度卷积神经网络检测钢轨表面缺陷,比较了不同大小和激活函数下的不同网络体系结构的效果,试验结果表明,深度卷积神经网络的分类准确率达93.04%。余永维等[11]针对建立射线无损检测智能化信息处理平台的需求,提出一种基于卷积神经网络和径向基网络的智能识别方法,该方法在精密焊件射线图像中识别缺陷率达91%,有较高的准确率和较好的适应性。刘明等[12]为了解决传统方法中T波检测困难等问题,提出基于卷积神经网络的T波分类算法,在MIT-BIH QT心电数据库上进行测试,算法准确率达99.91%,能够识别五类不同的T波形态。
本试验提出基于改进的卷积神经网络和支持向量机模型的马铃薯表面缺陷检测新方法。首先利用机器视觉系统获得马铃薯图像,训练采用包含1×1卷积层和dropout层的CNN,然后利用全连接层输出的特征向量训练分类性能更好的SVM来完成缺陷检测。该方法通过网络对图像数据的学习,能得到马铃薯表面本质特征,克服了传统方法中人工提取特征和特征描述的局限性,将特征提取和模式分类合二为一,为马铃薯等农产品表面缺陷检测开辟了新思路。
1 卷积神经网络
卷积神经网络是普通神经网络的延伸,受到了早期延时神经网络(TDNN)的影响[13]。CNN是第一个真正成功训练多层网络结构的学习算法,每层由多个二维平面组成,每个平面由一些具有学习能力的权值和神经元构成。CNN作为一个深度学习架构的提出是为了最小化数据的预处理要求。在CNN中,图像的一部分(局部感受区域)作为层级结构的最低层的输入,信息依次传输到不同的层,通过多层处理,逐渐将初始的“低层”特征表示转化为“高层”特征表示后,用“简单模型”即可完成复杂的分类等学习任务[14]。目前,CNN已在语音分析和图像识别领域取得重大成果[15-16]。
1.1 构成
典型的CNN模型由输入层、卷积层、池化层、全连接层和输出层构成,如图1所示。
卷积层是特征提取层,增强原始信号特征的同时降低了噪声。每个神经元的输入都和前一层(输入层或采样层)的局部感受野相连,卷积核在该局部感受野上滑动来提取特征,形成特征图,该局部特征被提取后,它与其他特征间的位置关系也相应确定;池化层为特征映射层,每个特征映射为一个平面,平面上所有神经元的权值相等。根据局部相关性原理对上一层特征进行子抽样,既减小了图像的空间大小,也控制了过拟合。在全连接层中,神经元与前一层的所有神经元相连接,所有的结点由一些带权重的值连接起来,组成图像的特征向量,最后在输出层完成目标的分类。

图1 典型CNN结构图Fig.1 Structure diagram of typical convolution neural networks(CNN)
1.2 特点
图像的空间联系是局部的,如同人是通过一个局部的感受野去感受外界图像一样,每一个神经元都不需要对全局图像做感受[17]。如图1所示,CNN中每个隐层内的神经元只与前一层的局部区域相连接,最后在更高层,将这些感受不同局部区域的神经元想结合,得到图像的全局信息。此外,隐层中每个特征图上的神经元共享同样的权值。
综上所述,CNN通过将局部感受、权值共享以及空间亚采样这三种结构思想结合既减少了训练的权重个数,降低了算法的复杂度,缩短了算法运行时间,又使得网络获得了某种程度的位移不变性。
2 针对马铃薯搭建的CNN-SVM模型
图1的CNN模型在分类性能上已经优于传统方法,为了进一步提高算法效率和准确率,对其进行了改进。针对马铃薯搭建的CNN-SVM改进模型如图2所示,该模型包括输入层,依次连接的三组卷积层、1×1卷积层、池化层,以及Dropout层、全连接层和SVM分类层。可将该模型分为特征提取和模式分类两个模块。
3组依次相连的卷积层、1×1卷积层和池化层构成模型的特征提取模块。在卷积层内,卷积核在与上一层相连接的局部感受野上滑动,进行卷积运算,完成特征提取,并通过激活函数形成该卷积核的特征图。输出如式(1)所示:
(1)
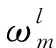
在CNN中,由于图像包含3个维度,所以1×1卷积层能高效地进行3维点积,起到降维和减少计算量的作用。
池化层使用某一位置相邻输出的总体统计特征来代替网络在该位置的输出,实现对特征图像素的二次挖掘,既减少了模型参数总量,又保留了激活值最大的图像特征。池化层紧跟卷积层的特殊结构,使网络具有更高的鲁棒性。池化层计算公式如式(2)所示:
xm=down(xl-1)
(2)
其中,down(·)为下采样函数。
在图2所示模型中,通过合理设计卷积核尺寸、特征图个数、全连接层结点数等参数来构建网络。模型部分参数和输出尺寸如表1所示。

图2 马铃薯表面缺陷检测模型Fig.2 Detection model of potato surface defect
表1部分CNN模型参数
Table1PartialparametersofCNNmodel

层特征图个数卷积核尺寸参数个数输出尺寸卷积层C1645×5×34 864227×227×64卷积层C2481×1×643 120227×227×48池化层S3482×2×480114×114×48卷积层C41285×5×48153 728114×114×128卷积层C5901×1×12811 610114×114×90池化层S6902×2×90057×57×90卷积层C72565×5×90576 25657×57×256卷积层C81801×1×25646 26057×57×180池化层S91802×2×180029×29×180Dropout D10180-029×29×180全连接层F11--75 690 5001×500
本试验模型输入是 227×227像素的RGB彩图。C1和C4层采用 5×5卷积核与图像进行卷积,并使用ReLU作为激活函数得到卷积层的输出,部分样本经C1层卷积后输出(图3)。C2和C5层采用 1×1卷积核,通过降低卷积核的数量,达到减少网络中参数总量的目的。池化层均使用卷积核尺寸为 2×2、步长为2的最大值池化方式。此外,应用Dropout技术在训练过程中每次更新参数时随机断开一定比率的神经元,达到减少过拟合和提高网络泛化能力的效果[18],根据经验法则,设置模型Dropout概率值为0.5;在3组卷积和池化之后,连接包含参数最多的全连接层,输出一个500维的特征向量,并作为支持向量机的输入,训练得到SVM分类器。最后在测试集图像上验证CNN-SVM模型的分类性能。
3 网络训练算法
卷积神经网络通过学习大量带标签的图像数据,提取出从简单到复杂,从局部到全局的深度特征,形成一种端到端的学习结构和映射关系,最终实现模式分类的目标。CNN的训练过程可分为前向传播和反向传播两个阶段。
(1)前向传播阶段
a.采用一些考虑非线性映射影响后的均值为0且服从高斯分布的不同小随机数作为待训练权值和偏置的初始值[19]。
b.将训练样本输入初始化参数后的网络,按照图2中的网络从左到右层层运算,得到模型预测输出。
(2)反向传播阶段
a.按式(5)计算预测类别与实际类别间的误差。
b.以最小化代价函数为原则,采用优化算法反向传播,更新网络中的权重ω和偏差b。对C1、C4和C7层中各10个卷积核学得参数进行可视化,结果如图4所示。
(3)
(4)
其中,α为学习率;ε为一个常数;ω和b为要迭代更新的卷积核权重和偏置;Vdω和Vdb为经过指数加权平均后的导数均值;Sdω和Sdb为经过指数加权平均后的导数平方。
(5)
其中,E为交叉熵损失函数;k和N为类别和样本个数;hj是模型对第j类的预测输出;hyi是第i个样本实际类别对应的预测输出。
本试验模型采用Adam[20]优化算法进行参数更新,具体公式见式(3)、(4)。该算法能减小批量梯度下降过程中梯度在垂直方向上的来回波动量,并加大在横轴方向上的更新步长,加快收敛速度。
模型训练结束后,将参数保存,能避免后期加入新数据时重新训练,减少计算成本。

图3 C1层输出可视化Fig.3 Visualization of the output of C1 layer
4 结果与分析
4.1 试验数据和环境
试验用马铃薯样本均采购于无锡朝阳农贸市场。采集图像前,对马铃薯进行简单清洗,然后通过机器视觉实验平台采集马铃薯RGB彩色图像。部分马铃薯样本如图5所示。
在机器视觉和深度学习任务中,更多的图像数据能帮助模型学习更复杂的函数,提升算法的性能,为了节约成本,数据增广是一种经常使用的技术。本试验采用垂直镜像对称,随机裁剪和彩色转换3种方法来实现数据增广[21]。样本数据增广效果如图6所示。
本试验通过GPU加速技术进行模型训练与预测,试验环境配置有GPU:Nvidia TITANX,内存:32G;软件,操作系统:Linux,开发工具:Python。

图5 部分试验样本图Fig.5 The experimental samples
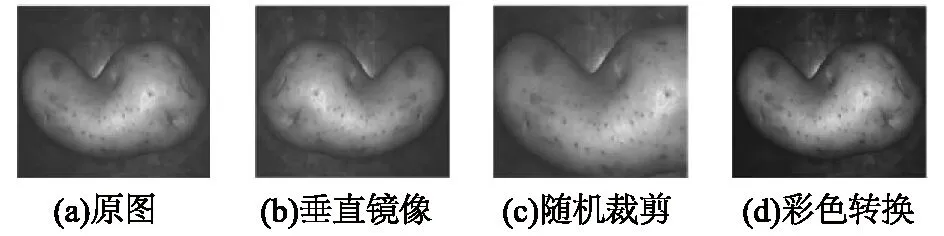
图6 数据增广结果Fig.6 The results of data augmentation
4.2 数据划分与预处理
试验图像数据由机器视觉平台和数据增广方法所得图片组成。共采用8 000张马铃薯彩色图片作为数据集,按 6∶2∶2的比例划分训练集(4 800张)、验证集(1 600张)和测试集(1 600张),分别用于模型训练、模型参数与结构评估、模型性能评估。根据NY/T1006-2006《马铃薯等级规格》国家农业行业标准[22],对数据集中的马铃薯图片进行类别标注,无缺陷和有缺陷(包括绿皮、机械损伤、发芽、腐烂和虫咬五类较为常见缺陷)马铃薯分别用0和1标识。卷积神经网络需要输入相同尺寸的图片,因此将样本图片尺寸缩放为 227×227×3。
在图像处理中,图像像素值可看成是一种特征,将图像像素减去像素均值能去除图像中的共有部分,凸显个体差异。因此,通过计算训练集图像像素均值,分别将训练集和测试集图像减去该均值来使数据中心化。
4.3 卷积神经网络模型超参数选择
卷积神经网络有两类参数,一类是基础参数,如卷积层或全连接层的权重和偏置项,另一类是超参数,如网络训练时的学习率、学习次数等。卷积神经网络要取得好的性能,需要选择一组好的超参数。因此,试验中对网络训练时的学习率和训练次数这2个超参数进行了选择。
4.3.1 学习率选择 在模型训练过程中,学习率对算法的收敛有重要影响。学习率太大,算法会在局部最优点附近来回跳动,不会收敛于最优点;但如果学习率太小,会使收敛速度变慢[23]。为了研究CNN模型训练时学习率与模型准确率的关系,在固定模型训练次数为30的条件下,观察不同学习率下模型准确率的变化情况(表2)。试验结果表明,当学习率为10-3时,验证准确别率仅为70.3%,而学习率为10-4时,准确率最高,且随着学习率的降低,训练时间会逐渐变长。因此,试验在保证准确率的基础上,为了避免训练时间过长,选择10-4作为模型训练时的学习率。
表2不同学习率下网络收敛时的损失和准确率
Table2Lossandaccuracyatdifferentlearningrates
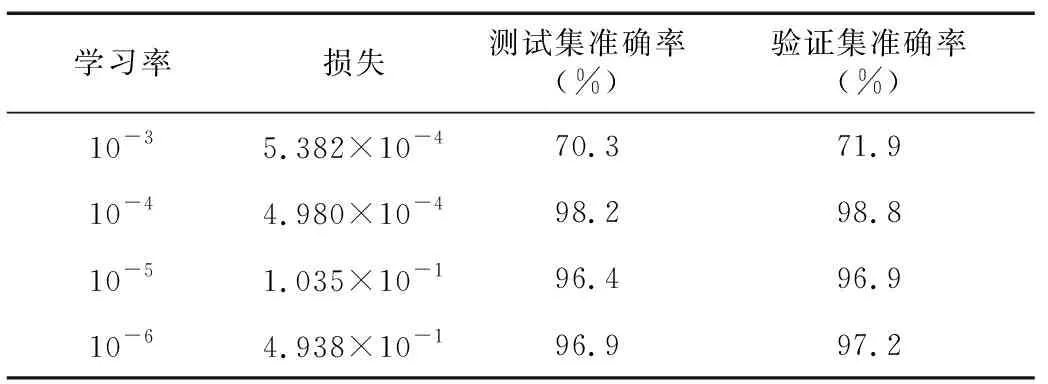
学习率损失测试集准确率(%)验证集准确率(%)10-35.382×10-470.371.910-44.980×10-498.298.810-51.035×10-196.496.910-64.938×10-196.997.2
4.3.2 训练次数选择 为了研究试验模型训练次数对样本准确率的影响情况,在学习率设为10-4的条件下,通过改变训练次数来观察模型准确率的变化情况(表3)。试验发现,当训练集训练次数为1时,由于训练次数太少,导致模型训练不充分,没有学习到足够多的特征,验证集准确率仅有59.3%,随着训练次数的提升,准确率逐步提高,当训练次数为30时,准确率达到98.1%,网络模型已基本学习到位,此时再继续增加训练次数,准确率基本不变,但训练时间会逐步增加。因此,综合考虑训练速度与准确率的关系,把训练次数设为30。
4.4 支持向量机参数选择
由于在CNN训练时,卷积操作是一个对线性不可分数据增加其线性可分程度的过程[24],传统模型中采用softmax算法需考虑全局数据,分类超平面会受任意样本的干扰,相比之下,SVM分界面只依赖于部分支持向量样本的优点就得到了体现。此外,SVM在处理小样本时,有较好的性能。因此,试验中训练好CNN后,取出模型F11层中的特征向量,并利用其训练SVM得到分类器。
表3训练次数与准确率的关系
Table3Relationshipbetweentrainingtimesandaccuracy

训练次数 1510203050100测试集准确率(%)59.394.295.696.798.198.198.2验证集准确率(%)62.595.096.997.598.898.998.9
试验中,采用网格搜索法对SVM核函数以及参数进行对比选择,其中候选核函数为:多项式、线性、高斯径向基核函数;参数搜索范围为:γ∈(0,50)、C∈(1,200)、d∈(1,10),其中γ为径向基函数的参数、C为惩罚因子、d为多项式函数的阶数。
根据验证集准确率选择出最优核函数和参数组合,并用测试集评估模型性能(表4)。
表4SVM参数网格搜索结果
Table4Theresultsofgridsearchforsupportvectormachine(SVM)parameter

项目γC测试集准确率(%)高斯径向基核函数1199.20
4.5 改进CNN-SVM算法与其他算法对比
将本试验方法与文献[7]、文献[8]和常规CNN模型的结果进行对比(表5)。试验结果表明,本试验算法在测试集上准确率最高,因为本试验模型是一种基于“端到端”思想的新方法,不仅避免了缺陷区域的分割,而且无需人工特征提取,直接学习(从原始输入数据到期望类别的映射)。与“分治”策略下的传统方法相比,“端到端”的方式更能获得全局最优解。
多层模型下的CNN更关注图像局部信息的改变,能提取比手工设计更好的特征,而支持向量机比softmax分类器更适合本试验图像数据的分布,也提升了算法的性能。
表5CNN+SVM算法与其他算法对比
Table5ComparisonamongCNN+SVMandotheralgorithms

马铃薯表面缺陷分类方法 测试集准确率(%)特征提取+KNN分类识别[7]91.25颜色特征提取+SVM分类识别[7]95.00边缘、纹理相关特征集+AdaBoost[8]89.60常规CNN分类识别98.10改进CNN+SVM分类识别99.20
5 结 论
马铃薯表面缺陷检测技术在提升马铃薯外部品质、经济价值和市场竞争力以及防范食品安全等方面有着重要的作用,是农产品检测中的一个重要研究方向。传统检测方法依赖于人工提取特征,该过程费时费力,并且马铃薯多变的生长环境导致其表面缺陷种类多样化和部分缺陷目标细微化,设计并提取好的特征较困难。本试验提出基于改进的卷CNN+SVM模型,该模型能自动提取马铃薯图像特征,完成分类,利用1×1卷积层和dropout层改进模型,达到加快算法运行时间和减少模型过拟合的效果。在测试集上对试验方法进行评估,试验结果表明,本试验方法能克服现有研究中人工设计和提取特征费时费力等问题,能够检测有缺陷和无缺陷两类马铃薯,准确率达99.20%。在接下来的研究中,一方面要扩充样本集,进一步发挥CNN对大数据处理的优势,另一方面要寻找更有效的方法,加快模型训练速度。
