基于本体的海洋地球化学数据互操作系统设计与实现❋
2019-01-04王小红徐建良洪腾龙卜文瑞候成飞
王小红, 徐建良❋❋, 洪腾龙, 卜文瑞, 候成飞
(1.中国海洋大学信息科学与工程学院,山东 青岛 266100; 2.国家海洋局第一海洋研究所,山东 青岛 266061)
随着数据资源体量、复杂性和异构性的增加,科学家越来越需要数据集成和共享平台来获取分布式的跨学科数据。数据集成平台目前存在多种体系结构,主要可以分为两类:虚拟集成方法和物化集成方法[1]。物化集成系统是指在数据集成过程中将需要集成的数据复制装载到公共的数据集合中[2]。虚拟集成方法是采用虚拟视图来实现的数据集成的系统结构,当用户提交查询请求时,系统根据用户命令访问不同数据源中的数据并返回结果[3]。上述的虚拟集成方法和物化集成方法在体系架构上提出了两类数据集成平台的解决方案,然而在实际应用中,数据异构性是阻碍数据集成的困难之一[4]。因此,处理异构数据首先要理解数据的语义。本体作为一种领域知识模型,为数据底层的互操作提供了规范化的语义表示和准确的语义协同。
为了解决多信息源的不同词汇和服务的互操作,本体模型应该更加广泛的应用在支持知识相关操作(如数据集成、获取、推理、和检索)的互操作平台或应用系统。利用数据互操作平台,科学家能够轻松地获取数据、读懂数据,基于这些跨学科异构数据进行统计、分析,产生更精确的数据和更高层次的知识。
1 问题分析
随着对海底资源的勘察和开发,各国获取了大量的实物样品和分析测试数据。这些数据能够帮助海洋科学家重现数千年以来海洋动态变化的过程。
以岩心沉积物样品为例,水动力、物源、植被、气候、温度在时间轴上的不断变化,造成了岩心沉积物在不同层位所体现的地质时代和地球环境背景信息各不相同。因此,海洋学家对于岩心沉积物样品的研究,常常经过分割、剖分、分层、取小样等操作,分配到不同的实验室,由不同的实验员用不同的仪器进行分析测试(见图1)。同一岩心样品通常会产生不同测试指标的实验结果(见表1)。然而这些实验结果的组织模式又各不相同(见图2)。依靠人工很难完成不同层位的岩心测试结果的集成和共享。因此,海洋领域更需要实现大规模的多源异构数据的互操作。
目前,海洋领域主流的数据互操作方法有两类:第一类是依赖于汇交规范的数据互操作方法。例如:拉蒙特-多尔蒂地球观测中心的EarthChem地球化学数据库[5]和国际海底管理局的中央数据存储库CDR(Central Data Repository)[6]。这种方法是面向数据内容的一种简单的数据组织模式转化,不仅增加了人工劳动量,而且很容易造成数据内容的丢失和语义的误解。第二类方法是基于semantic web技术的数据互操作方法。例如:地球与环境术语语义网[7](The Semantic Web for Earth and Environmental Terminology,SWEET)和海洋元数据互操作项目 (Marine Metadata Interoperability Project,MMI)[8]。该方法通过构建领域本体、术语集、叙词表,或者开发语义管理工具来进行语义互操作和数据集成。

图1 样品切割和分配情况

小样Subsample 样品使用人Sample user 测试指标Test parameter样品化验员Analyst 仪器Instrument1使用人A主量元素1AAS2使用人B微量元素2ICP-MS3使用人C同位素3MC-ICP-MS4使用人A主量元素4XRF5使用人B微量元素5ICP-MS6使用人F稀土元素6XRF7使用人W同位素7TIMS8使用人X有机污染物5GC-MS9使用人D无机碳6总无机碳分析仪

图2 分析测试结果的元数据异构性示例
虽然MMI项目所涉及的数据学科和调查范围非常广泛,但是由于语义映射过程完全依赖人工操作,因此该方法并为得到广泛推广。截至目前,MMI项目注册的244个词汇集中,仅有10对语义映射。为了能更好的解决海洋地球化学数据集成和共享的问题,我们借鉴MMI的语义协同思想,在EarthChem的数据汇集规范基础上,设计了基于本体的海洋地球化学数据互操作系统,支持多模式异构数据采集、融合、推理和共享。
2 数据互操作系统框架的设计
本文提出的基于领域本体的海洋地质化学数据互操作系统的框架,由数据层、语义层、应用层三部分组成(见图3)。
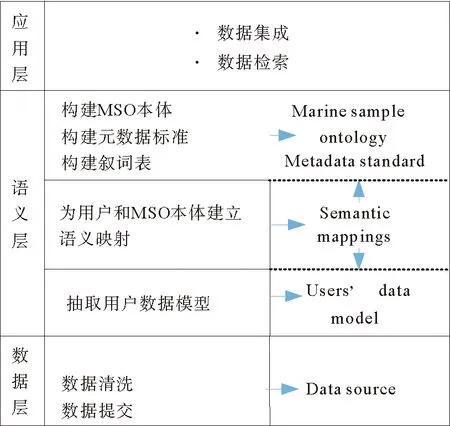
图3 基于本体的数据互操作框架
2.1 数据层
数据层主要完成元数据标准构建、数据汇交模板定制等功能,为多源异构的海洋地球化学数据集,提供了元数据标准和语义规范。
2.1.1 海洋地球化学数据元数据标准的构建 由于海洋调查领域缺少统一的元数据标准,多源异构数据没有数据汇交的模式和语义规范。为了实现大洋样品全生命周期的数据溯源和集成,我们参照《科技平台元数据标准化基本原则与方法》[9],分三步完成了海洋地球化学元数据标准的建设。
(1) 分析资源特点 通过参与我国“国际海域资源调查”样品属性数据汇交,认识和分析了大量地质化学元数据。
(2) 调研相关元数据标准 经过对Marine Community Profile of ISO 19115[10]、数字地理空间元数据内容标准(Content Standard for Digital Geospatial Metadata)[11]、国家标准《GB/T 12763.7-2007海洋调查规范海洋调查资料交换第7部分》[12]和《GBT 12763.8-2007 海洋调查规范第8部分海洋地质地球物理调查》[13]的查阅,结合我国海洋地质调查业务特点,初步制定了海洋地质化学元数据标准。
(3) 确定元数据内容 经过与我国海洋领域专家的多次讨论,确定了海洋地质化学元数据标准的元素和元素之间的层次关系,按照SKOS (Simple Knowledge Organization System)提供的知识组织模式,初步构建了海洋地球化学元数据标准。海洋地球化学元数据标准包括样品(Sample)、测试数据(TestData)、主要分析性元数据(PrimaryAnalyticalMetadata)、机构(Institution)、人员(Person)、位置(Location)6个主要模块。
为了海洋科学家使用方便,将部分元数据标准嵌入Excel电子表格,组成数据汇交模板[14]。大洋样品属性数据汇交模板由样品信息、测试数据、申请书、分析性元数据、词汇集(受控词汇集)、填表说明等6张子表组成。子表间通过外键(箭头上的字)互相连接(见图4)。数据汇交模板相当于语义中介,作为数据汇交规范与其他异构数据进行语义映射。

图4 数据汇交模板
2.1.2 数据汇交模板定制 由于大洋调查数据涉及多学科的数据,仅地球化学分析测试就有18种不同的分析测试指标,其产生的分析测试数据组织模式也不同。因此,开发了汇交模板生成器(见图5),它能够从海洋地球化学、生物化学、海水化学元数据标准中,抽取相应学科的元数据标准,为用户定制数据汇交模板。
模版生成器的上方有“航次”(Cruise)和“申请人”(Applicant)选项,左侧列表框里列出了64种分析测试指标,包括地球化学测试指标18种,海水化学测试指标24种,生物化学测试指标22种。位于工具中间的“〉〉〉”按钮,可以帮助用户将其需要的分析测试指标,添加到右侧的列表框中。同时用户也可以使用“〈〈〈”按钮,从右侧列表框中删除不需要的分析测试指标。

图5 数据汇交模板生成器
2.2 语义层
大洋样品本体作为一种规范化的概念模型,为多数据源提供了一致的语义描述和类层次结构。语义层以大洋样品本体模型为基础,完成了语义抽取和语义映射。
首先,在海洋地球化学元数据标准的基础上,用Protégé建模工具构建了大洋样品本体(MSO)[15]。其次,开发元数据抽取工具和元数据映射工具,在大洋样品本体的配合下,完成了用户元数据与元数据标准之间的语义映射[14]。
2.2.1 语义抽取和语义映射 语义抽取是异构数据集成、共享和互操作的第一步。语义抽取,指用不同技术去识别和抽取实体、事实、属性、概念和事件,用它们来填充元数据字段[16]。语义映射,就是为源文本中抽取的术语和本体或知识库中的概念建立连接,给每个术语一个正确的概念[17]。
为了完成数据模式和语义转换,首先通过元数据抽取工具抽取用户Excel表格中的元数据,再利用元数据映射工具,将多数据源的语义模式与大洋样品本体模型进行映射,从而完成多个模式之间的语义协同和数据复用。详细步骤如图6所示:
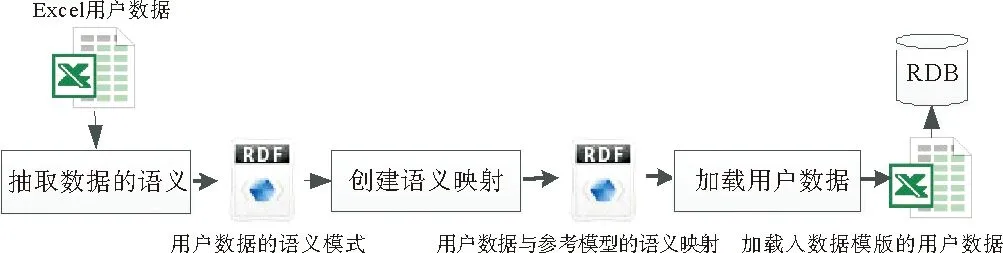
图6 面向Excel数据源的语义模式转换和存储
①针对Excel格式的数据,我们首先借助元数据抽取工具(见图7),抽取用户数据的元数据[14]。使用这个工具,用户只需要提供电子表格的列标题(“title”)所在的行号,用户的元数据就可以自动从列标题中抽取出来。这个工具为用户提供了一个友好的界面,来编辑一些特殊的信息。例如:当测试数据的单位在独立行时,用户需要输入其所在行“unit”的行号。除此之外,用户还需要输入分析测试数据的数值(“data”)起始行行号,以便于后续将用户数据加载入模板。
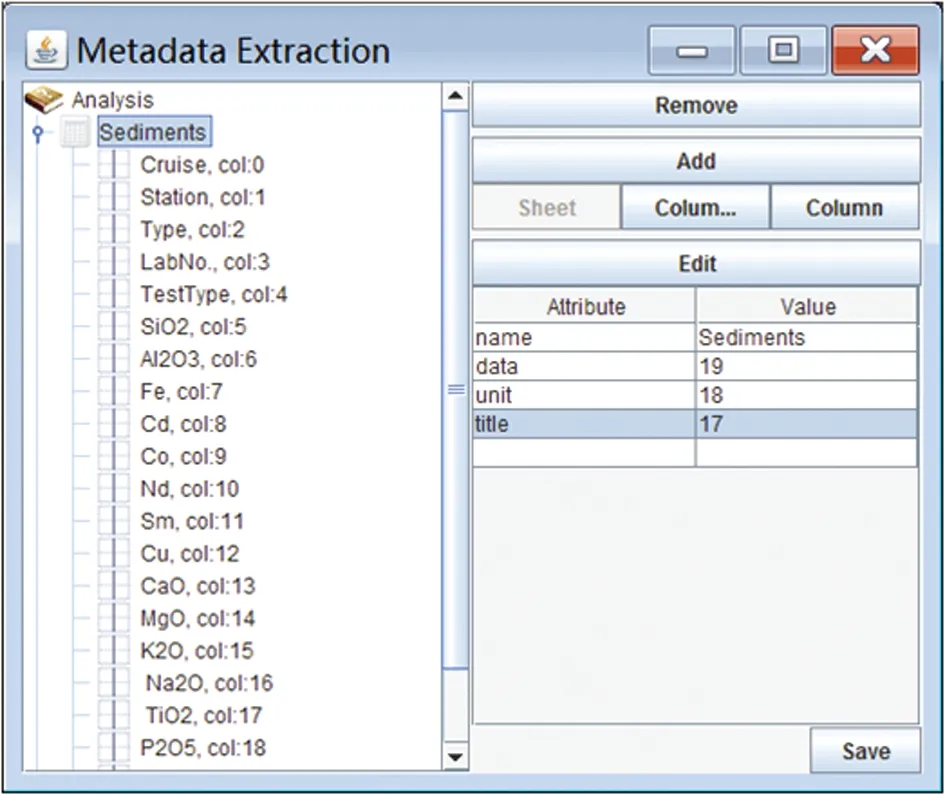
图7 元数据抽取工具
②借助元数据映射工具(见图8),为用户数据模型与领域本体模型之间建立语义映射[14]。在工具左侧列出的是用户元数据的层次结构,右侧是数据汇交模板的层次结构。工具中间有‘=’、 ‘<’、和 ‘>’3个按钮控件,分别对应‘exact-match’、‘narrow-match’、和 ‘broad-match’3种匹配关系。

图8 元数据映射工具
为了自动建立语义映射,我们采取了基于本体的自动匹配机制。成功匹配的结果有两种类型,一对一匹配和一对多匹配。一对一匹配(蓝色字体标记)由本体模型中的等同关系产生。一对多匹配(红色字体标记)通常由本体模型中的等级关系产生。例如:‘Fe’能够自动与它的3个子类‘FeT’, ‘Fe2O3’, ‘FeO’匹配,当用户数据中出现‘Fe’时,其子类将以红色字体显示,提示用户选择其中之一与之对应。由于大洋样品本体模型更新总是滞后于海洋调查、分析测试技术的发展,有一些新兴术语无法与数据汇交模板中的元数据自动匹配。此时,就需要人工干预,用工具中提供的3种 ‘=’、 ‘<’、和 ‘>’按钮控件,为新术语与模板的元数据建立语义关系,或者将无法匹配的新术语添加到右侧‘ExtraSheet’,以供后期的模板更新。
③将用户数据源导入汇交模板。通过元数据映射工具,能够完成信息源和大洋样品本体模型之间的语义映射,根据元数据映射关系,和Excel电子表格中的数据起始位置,将数据导入汇交模板。
④最后按照汇交模板的数据模式构建关系型数据库,将分散异构的Excel数据集,存储到统一模型的数据库中。
2.2.2 关系型数据库模型中的语义协同 针对关系型数据库,我们利用D2RQ[18-20]生成一个描述关系型数据库的RDF模型(见图9)。并且开发了网站(见图10),为RDB和MSO之间建立语义映射。

图9 面向关系型数据库的语义模式转换
在数据库语义映射网站中,首先,我们键入数据库地址(Connect string),来连接数据库;其次,在弹出的窗口中选择需要映射的数据库表和字段(见图10(a));再次,选中的数据库表和字段将会显示在数据映射网站的左侧,大洋样品本体模型的结构显示在右侧(见图10(b));最后,为数据库和大洋样品本体模型建立语义映射。经过字符串比较,能够为拼写完全相同的字段建立映射。剩余字段需要管理员使用“=”按钮,为其建立语义映射。
2.2.3 查询转化模块 为了实现SPARQL查询的转换,我们开发了查询转换模块Transfer。该模块根据大洋样品本体模型和语义映射,获取用户RDB和MSO两个RDF模式之间的推理关系(包括类层次和属性层次),从而将面向MSO模式的SPARQL查询,转换成面向数据库模式的SPARQL查询。
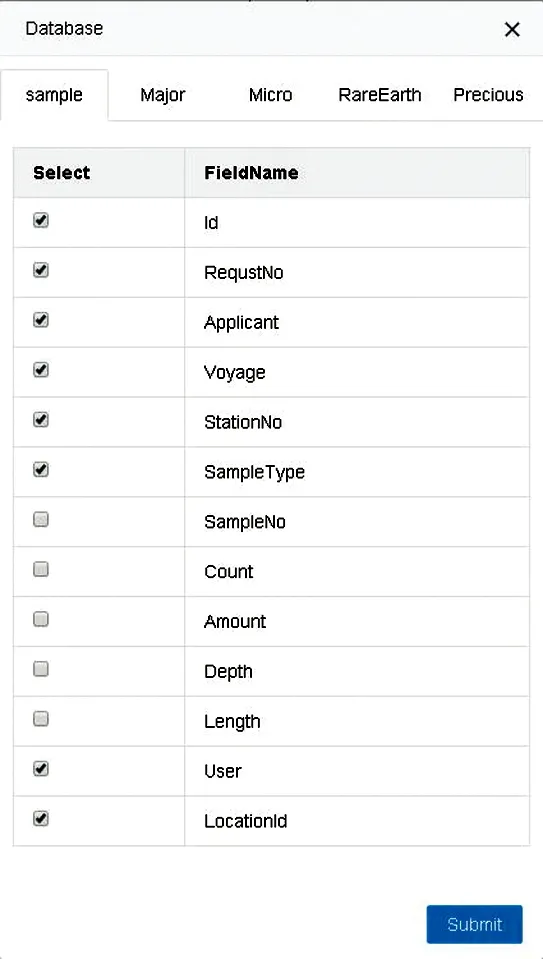
(a) 语义映射网站弹窗Popup window of semantic mapping website

(b) 数据库与本体模型的语义映射网站Website for semantic mapping betweenRDB and ontology
图10 语义映射网站
Fig.10 Website for semantic mapping
2.3 应用层
应用层通过数据查询网站和基于语义的联合查询方法,完成了数据的一站式查询。
2.3.1 联合查询的网站建设 查询网站为用户提供了多种查询方式,包括:样品类型、样品采集位置、分析测试指标、经纬度、数据提供者。而样品采集位置、样品类型、分析测试指标又按照大洋样品本体中的层次关系,建立了树形结构。网页左下侧的分析测试指标是主要的地质化学调查要素,包括一级指标14个,二级分析测试指标9个,三级分析测试指标70个,一共93个分析测试指标(见表2)。
用户通过简单友好的查询界面,即可在样品类型、采样位置、分析测试指标的树形结构中选择查询关键字(见图11),选择后的字段将会显示在右侧列表框中。
2.3.2 联合查询的工作流程 我们提出的这种基于语义的跨系统联合查询,对用户屏闭了多个后台数据库,让查询看起来就像是在一个数据库里完成的。如图12所示,这个方法由以下三步构成。
(1) 根据用户在网站上选择的查询条件生成面向MSO本体模型的SPARQL查询。
(2) 查询转换模块基于RDF推理机制和语义映射,生成新的SPARQL查询。
(3) 利用D2RQ将SPARQL查询语句转换成SQL查询语句。

表2 部分海洋地球化学分析测试指标
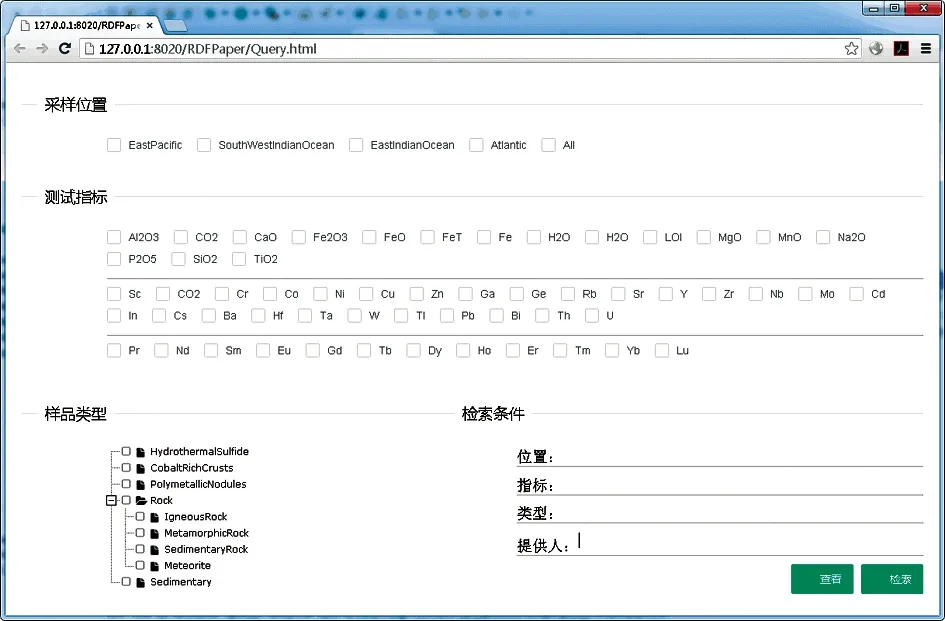
图11 数据查询网站
3 系统测试
3.1 测试步骤
为了验证基于本体的数据互操作方法的有效性,我们用测试数据进行了实验,实验步骤如下。
(1) 创建三个数据库。第一个数据库,参考ODP项目中的ICP-AES数据库模型[21]。第二个数据库,参考拉蒙特-多尔蒂地球观测中心的PetDB海底岩石学数据库模型建立[22]。第三个数据库,参照德国马克斯普朗克研究所(Max-Planck-Institution)的GEOROC数据库模型[23]建立。

图12 数据查询的工作流
(2) 随机选择了一些元素含量分析测试数据集作为测试数据集,分别加载到我们创建的3个数据库中。
(3) 用2.3.2中提出的方法,面向以上3个数据库进行数据查询。
3.2 查询示例
按照2.2.2中的方法,系统和3个数据库进行语义映射后,系统就可以查询采用位置为“西南印度洋”,样品类型为“岩石”,测试指标为“Fe”的测试结果。通过在大洋样品属性数据查询网站上选择相应的查询项,后台产生的SPARQL查询语句如下:
select*where{
?sampleMarineSampleOntology:LocationAt?location.
?locationMarineSampleOntology:SeaArea?area.
filterregex(?area,"SouthWestIndianOcean").
?sampleMarineSampleOntology:SampleType
MarineSampleOntology:Rock.
?majorMarineSampleOntology:MajorElement
ContentOf?sample.
?majorMarineSampleOntology:Fe?Fe.
}
虽然查询条件仅仅涉及“岩石”和“Fe”,但是由于MSO模型中提供了“岩石”和“Fe”的子类,通过语义推理和查询转换,最初的查询条件将转换为针对子类的查询语句,从而根据语义映射关系,一次查询就可以到相应数据库中获取数据。所以,查询示例返回结果中的测试指标包括“Fe”的子类:“Fe2O3”、“FeO”和“FeT”,样品类型包括“岩石”的子类:玄武岩(basalt)、花岗岩(Granite)、石灰石(Limestone)。查询结果返回结果如图13所示。
3.3 互操作系统的优点
与现有的其他方法相比,我们所提出的基于本体的数据互操作系统有以下优势。

图13 查询结果Fig.13 Query results
(1) 本体与数据分别存储在不同的数据源中,在不复制用户数据的情况下访问其数据,可以充分保证数据的安全性和时效性。因此,适用于处理数据体量大、更新频繁、数据密集高的信息源。
(2) 本体作为参考语义规范,可以与多个不同的数据集合建立语义映射,在不改变数据源内容、语义、模式的情况下,实现了任意两个数据集的互操作。
(3) 本体通过语义映射,对数据库概念模型进行了形式化规范说明,为数据库中的数据提供语义,从而实现了多个数据库之间概念模型的映射,做到了跨系统的基于语义的数据检索。
4 结语
本文为解决多源异构数据互操作问题,设计了面向E-science的海洋地质化学数据互操作系统,分别利用3个不同层次的功能,实现了跨系统异构数据的采集、整合、检索、共享。跨系统数据检索实验结果显示:该方法不仅提高了大洋样品属性数据集成工作的效率,而且在确保数据源的独立性、安全性、时效性的前提下,实现了异构海洋调查实体数据和数据模型的复用。本文并未考虑大规模数据的RDF存储、查询和推理,所以未来的工作应着眼于基于Hadoop的大规模语义Web本体数据查询及推理。
