基于不完备日志的块状并发过程挖掘
2019-01-02杜海森杜玉越
杜海森,杜玉越
(山东科技大学 计算机科学与工程学院,山东 青岛 266590)
0 概述
过程挖掘即从事件日志中提取有价值的过程相关信息,其出发点是在过程模型与从事件日志中捕捉到的“现实”之间建立有效关联。过程挖掘主要有3种类型的应用:使用不包括任何先验信息的事件日志生成模型,将一个已知的过程模型与它产生的事件日志相比较以检测日志中的记录与实际情况是否相符,利用实际过程产生的事件日志来扩展或改进一个已存在的过程[1-3]。
在过程挖掘中,完备性的概念很重要,它表示日志中含有的数据是否过少。完备性假设所有可能直接跟随彼此的活动在日志中的一些迹中直接相互跟随,这导致传统的基于跟随关系的局部完备日志需要在日志中存在大量的迹。例如,针对存在10个并发执行活动的过程模型,α算法[1]需要90次不同的观察。
挖掘不完备日志时,由于日志中迹的数量过少,导致活动间的关系不能被正确表示,而隐含的活动间关系不能被表示会导致挖掘结果不正确。通过引入间接关系的表示,可以从不完备的日志中获得完备的并发关系,该过程通过分层可以发现潜在的因果跟随关系并得到相应的过程模型。
本文挖掘含有较少迹的日志,这些迹可能不完整,但是足够有效,利用这些迹可以发现潜在的因果跟随关系。在此基础上,提出一种块状并发过程挖掘算法α‖+,以得到具有代表性的并发过程模型。
1 相关工作
过程挖掘领域已经出现了很多挖掘算法。α算法是较基本的过程发现算法,针对α算法的缺陷进行的改进算法也相继被提出,例如α+算法[4]和α++算法[5]。α+算法主要使α算法能处理短循环,如长度为2的短循环。α++算法则处理非自由选择结构。虽然α算法和其改进算法可以发现具有完备日志的过程模型,但在处理不完备日志、罕见行为和一些特定结构时,存在很多限制和缺陷。因此,研究者又提出较多高级挖掘算法。
启发式挖掘算法[6]作为一种高级挖掘算法,利用一种类似因果网表示法进行描述,并在构建过程模型时考虑事件和序列频次,其设计思想是只将频繁路径纳入模型中。因果网表示偏好和频次使用,使得该算法比其他多数算法更加健壮。模糊挖掘[7]提供一种新的方式来发现模型,其利用一种路线图表示可视化过程模型。遗传算法[8]不同于其他挖掘算法,其不是以一种直接、确定方式提供过程模型,而是通过演化方法,使用一个迭代过程模仿自然演变,并通过精英主义进行筛选。基于区域挖掘算法[9]包含基于状态区域过程发现和基于语言区域过程发现。基于状态区域过程发现可以从一个变迁系统中发现一个Petri网[10],基于语言区域过程发现可以从语言中发现一个Petri网。
上述算法在运行过程中均对日志的完备性有较高要求。对不完备日志进行挖掘,主要有2种方法:
1)归纳挖掘算法,即IM算法[11]。归纳挖掘处理不完备日志时将其看作一个优化问题。对活动间的关系进行统计,并搜索这些关系的概率估计,将其与设定阈值作比较,然后确定活动间的关系。这种方法需要大量日志来统计分析,在生成的模型中存在精确度问题。
2)针对块状并发结构的α‖算法[12]。该算法可以挖掘因果完备日志,但并不能挖掘因果不完备日志,包括并发完备日志。
2 基本概念
Petri网是一个三元组,表示为N=(P,T;F)。其中,P是库所的有限集合,T是变迁的有限集合,且P∩T=Ø,F⊆(P×T)∪(T×P)是有向弧的集合,也称为流关系。
工作流网是Petri网的一个子类,可表示为WN=(P,T;F,i,o),其是一个以i为输入库所、o为输出库所的Petri网。工作流网的合理性必须满足安全性、正确完成性、可完成性以及无死锁[13]。
块状工作流网[11]是一个分层的工作流网,可递归地分为工作流网。在块状并发过程模型中仅含有并发结构和顺序结构。
迹是活动的有序序列,例如,σ=
定义1(基于日志的次序关系) 用L表示事件日志,a,b∈L为L中任意2个活动。
aLb当且仅当σ=
aLb当且仅当σ=
a→Lb当且仅当aLb并且不存在bLa也不存在bLa。
a⟹Lb当且仅当aLb并且不存在bLa也不存在bLa。
a#Lb当且仅当不存在aLb,不存在bLa,不存在aLb,也不存在bLa。
a‖Lb当且仅当aLb∧bLa,或aLb∧bLa,或aLb∧bLa,或bLa∧aLb。
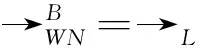
定义3(因果完备日志) 因果完备日志指满足基础因果关系的日志。WN=(P,T;F,i,o)为合理工作流网,当Lc满足以下条件时,日志Lc为WN的因果完备日志:
2)∀t∈T,σ∈Lc使得t∈σ。
定义4(α‖算法) α‖算法基于因果完备日志被提出,其可以挖掘因果完备日志得到块状并发过程模型。L为事件日志,T为事件集合,α‖算法定义如下:
1)TL={t∈T|(σ∈L)t∈σ}
2)TI={t∈T|(σ∈L)t=first(σ)}
3)TO={t∈T|(σ∈L)t=last(σ)}
4)XL={(A,B)|A⊆TL∧A≠φ∧B⊆TL∧B≠φ∧(∀a∈A)(∀b∈B)(aLb)}
5)PL={p(A,B)|(A,B)∈XL}∪{iL,oL}
6)FL={(a,p(A,B))|(A,B)∈XL∧a∈A}∪{(p(A,B),b)|(A,B)∈XL∧b∈B}∪{(iL,t)|t∈TI}∪{(t,OL)|t∈TO}
7)α‖(L)=(PL,TL,FL)
α‖算法的输入为因果完备日志,输出为Petri网。
3 α‖+算法
根据前文所述,不完备日志是关系不完备日志。根据不完备定义,本节给出并发完备日志的定义,并提出一种挖掘并发完备日志的α‖+算法。并发完备日志是一种不完备日志,含有完备的并发关系和不完备的直接因果关系。


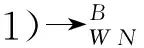
3)∀t∈T,σ∈Lp使得t∈σ。
在并发完备日志中,存在潜在的因果跟随关系,因此不能发现活动间所有的因果跟随关系。为解决该问题,针对并发完备日志,本文利用层次树的相关属性来发现活动间潜在的关系。
定义7(层次树) 层次树是一种特殊的树,每个父节点拥有至多一个子节点,在层次树的每一层中只有一个节点,每个节点中含有多个活动。在同一节点中,任意2个活动都为并发关系。LTL={l1,l2,…,li,…,lm}为层次树,则LTL具有如下性质:
1)|LTL|表示树的深度,|LTL|=m。
2)li表示第i层所有活动,li={a1,a2,…,aj}。|li|表示第i层中的活动个数,|li|=j。li(k)表示第i层的第k个元素,k∈{1,2,…,|li|}。
3)每一层中的任意2个活动间为‖L关系,即∀li(j),li(k)∈li,li(j)‖Lli(k),k≠j,k,j∈{1,2,…,|li|},i∈{1,2,…,|LTL|}。
日志L1={
层次树根据已有足迹和日志中的迹构造,依据活动之间关系将迹中活动按层次放入层次树中。层次树构造算法描述如下。
算法1层次树构造算法
输入足迹Footprint,迹Trace
输出层次树LayerTree
1.初始化LTL={},i表示当前的活动位置,j表示当前的层次树位置。
2.if (LTL==null) {
i=0,j=0;
LTL.add(lj);}
3.while(i<|Trace|){
4.if(lj==null){
lj.add(Trace(i))}
5.else {
j=|LTL|-1;
6.while (Trace(i)‖Llj){
j--;}
7.j++;
8.if(lj==null){
LTL.add(lj)}
9.lj.add(Trace(i));}
10.i++;}
11.return LTL.
在算法1中:步骤1、步骤2进行初始化;步骤3循环遍历Trace中所有活动;步骤4判断层次树当前层为空时,则添加当前活动;步骤5判断层次树当前层为非空时,将标识置于最后;步骤6判断当前层中所有活动与当前活动全部平行,层次树向上取值;步骤7层次树向下取值;步骤8判断当前层为空,将当前层添加到层次树;步骤9将当前活动添加到当前层;步骤10将当前活动向后取值;步骤11返回构造之后的层次树。
算法1中存在2层循环,算法的时间复杂度为O(n2)。本文利用层次树的性质和日志足迹发现潜在的因果跟随关系。发现潜在因果跟随关系的算法描述如下:
算法2发现潜在因果跟随关系算法
输入足迹Footprint,层次树LayerTree
输出潜在因果跟随关系集合TP
1.初始化ps={},fs={},nc={},nf={},Ts={}
2.for (each a→Lb in Fp){
ps.add(a);
fs.add(b);}
3.for (each active A){
4.if(!ps.contains(A)){
nc.add(A);}
5.if(!fs.contains(A)){
nf.add(A);}}
6.for (each active A in nc){
7.int pos = LTL.get(A);
8.for(;pos<|LTL|;pos++){
9.for (each active C in lpos){
if(A ⟹LC){
TP.add((A,C));
break;}}}}
10.for (each active A in nf){
11.int pos = LTL.get(A);
12.for(;pos>=0;pos--){
13.for (each active C in lpos){
if(C ⟹LA){
TP.add((C,A));
break;}}}}
14.return TP.
算法2利用层次树和足迹发现潜在因果跟随关系集合:步骤1初始化所有集合;步骤2遍历所有因果跟随关系;步骤3~步骤5寻找不在因果跟随关系前集和后集的活动,并放入集合,但不包含第一个活动和最后一个活动;步骤6~步骤13通过层次树为缺少前集或后集的活动发现前、后集;步骤7、步骤11分别表示当前活动所在层次树的位置;步骤8、步骤12分别表示向下和向上遍历层次树;步骤14返回TP集合。
算法2中存在3层循环嵌套,其时间复杂度为O(n3)。α‖算法可以挖掘因果完备日志,但挖掘并发完备日志时存在缺陷。对于并发完备日志的挖掘,本文提出α‖+算法。算法定义如下:
定义8(α‖+算法)L为事件日志,T为事件集合。α‖+算法定义如下:
1)TL={t∈T|(σ∈L)t∈σ}。
2)TI={t∈T|(σ∈L)t=first(σ)}。
3)TO={t∈T|(σ∈L)t=last(σ)}。
4)XL={(A,B)|A⊆TL∧A≠φ∧B⊆TL∧B≠φ∧(∀a∈A)(∀b∈B)(aLb)}。
5)XL=XL∪TP。
6)PL={p(A,B)|(A,B)∈XL}∪{iL,oL}。
7)FL={(a,p(A,B))|(A,B)∈XL∧a∈A}∪{(p(A,B),b)|(A,B)∈XL∧b∈B}∪{(iL,t)|t∈TI}∪{(t,OL)|t∈TO}。
8)α‖+(L)=(PL,TL,FL)。
α‖+算法根据活动在层次树中的位置发现潜在的因果跟随关系,在得到正确的因果跟随关系集合后挖掘出正确的过程模型。
定理1对于块状并发过程模型的并发完备日志,α‖+算法可得到正确的过程模型。
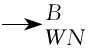
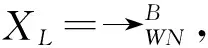
α‖+算法通过发现潜在的因果跟随关系集合Ts,扩展了α‖算法中的因果跟随关系集合,因此,可得到更准确的Petri网。
证毕。
α‖+算法中第5步的时间复杂度为O(n3),其余步骤为O(n1),因此,算法整体复杂度为O(n3)。
4 实验结果与分析
4.1 α‖+算法实验示例
本节通过一组日志展现α‖+算法的实现过程。算法的输入为并发完备日志,输出为Petri网。
日志L=[
‖L={(b,d),(b,e),(b,f),(b,i),(c,b),(c,e),(c,f),(c,g),(c,i),(e,d),(f,d),(g,d),(g,b),(g,f),(h,b),(h,c),(h,d),(h,f),(h,g),(i,d)}
→L={(a,b),(a,e),(b,j),(c,d),(e,f),(e,h),(f,i),(h,i),(i,j),(j,k)}
⟹L={(a,c),(a,d),(a,f),(a,g),(a,h),(a,i),(a,j),(a,k),(b,k),(c,j),(c,k),(d,j),(d,k),(e,g),(e,i),(e,j),(e,k),(f,j),(f,k),(g,i),(g,j),(g,k),(h,j),(h,k),(i,k)}
#L={(a,a),(b,b),(c,c),(d,d),(e,e),(f,f),(g,g),(h,h),(i,i),(j,j),(k,k)}
根据日志L和足迹,构造层次树过程如下:
执行步骤1、步骤2,LTL={{}}。
执行步骤4、步骤10,LTL={{a}}。
执行步骤6~步骤10,LTL={{a},{e}}。
执行步骤6~步骤10,LTL={{a},{e},{h}}。
执行步骤6、步骤7、步骤9、步骤10,LTL={{a},{e},{g,h}}。
执行步骤6、步骤7、步骤9、步骤10,LTL={{a},{e},{f,g,h}}。
执行步骤6~步骤10,LTL={{a},{e},{f,g,h},{i}}。
执行步骤6、步骤7、步骤9、步骤10,LTL={{a},{c,e},{f,g,h},{i}}。
执行步骤6、步骤7、步骤9、步骤10,LTL={{a},{c,e},{d,f,g,h},{i}}。
执行步骤6、步骤7、步骤9、步骤10,LTL={{a},{b,c,e},{d,f,g,h},{i}}。
执行步骤6~步骤10,LTL={{a},{b,c,e},{d,f,g,h},{i},{j}}。
执行步骤6~步骤10,LTL={{a},{b,c,e},{d,f,g,h},{i},{j},{k}}。
通过层次树LTL和足迹,Tp集合的构造如下:
ps={a,b,c,e,f,h,i,j}
fs={b,d,e,f,h,i,j,k}
nc={c,g}
nf={d,g}
Tp={(g,i),(a,c),(d,j),(e,g)}
α‖+算法的执行过程如下:
TL={a,b,c,d,e,f,g,h,i,j,k}
TI={a}
TO={k}
XL={(a,b),(a,e),(b,j),(c,d),(e,f),(e,h),(f,i),(h,i),(i,j),(j,k)}
Tp={(g,i),(a,c),(d,j),(e,g)}
XL=XL∪Tp={(a,b),(a,c),(a,e),(b,j),(c,d),(d,j),(e,f),(e,g),(e,h),(f,i),(g,i),(h,i),(i,j),(j,k)}
PL={start,p(a,b),p(a,c),p(a,e),p(b,j),p(c,d),p(d,j),p(e,f),p(e,g),p(e,h),p(f,i),p(g,i),p(h,i),p(i,j),p(j,k),end}
FL={(start,a),(a,p(a,b)),(p(a,b),b),(a,p(a,c)),(p(a,c),c),(a,p(a,e)),(p(a,e),e),(b,p(b,j)),(p(b,j),j),(c,p(c,d)),(p(c,d),d),(d,p(d,j)),(p(d,j),j),(e,p(e,f)),(p(e,f),f),(e,p(e,g)),(p(e,g),g),(e,p(e,h)),(p(e,h),h),(f,p(f,i)),(p(f,i),i),(g,p(g,i)),(p(g,i),i),(h,p(h,i)),(p(h,i),i),(i,p(i,j)),(p(i,j),j),(j,p(j,k)),(p(j,k),k),(k,end)}
α‖+(L)=(PL,TL,FL)
以上描述了α‖+算法的执行过程,最后输出结果为Petri网。
4.2 实验数据分析
本文模拟数据总共分为12组不同日志,日志信息如表1所示。其中,日志规模代表日志中迹的多少。日志都为并发完备日志,以保证算法输入的正确性。

表1 实验日志信息
表1中的12组数据具有不同的规模,随着编号的增加,日志中轨迹的条数也增加。表1中数据的生成过程如下:
1)利用ProM中Perform a simple simulation of a (stochastic) Petri net插件,输入块状并发结构Petri网,控制日志中迹的条数参数,生成轨迹条数不同的完备日志Lc,Lc的格式为XES文件,然后将Lc导出并保存。
2)利用ProM中提供的XES文件读写功能,编写轨迹删除插件ChangeLog。
3)利用ChangeLog插件对Lc删除指定(例如删除含有fLi、gLi或者cLd)的轨迹,生成新的日志Lc。
4)检测新生成的Lc是否为并发完备日志,将非并发完备日志删除。
5)选择不同规模的并发完备日志用Lp命名(L1~L12)并保存导出。
4.3 实验结果分析
本节对比几种不同算法的挖掘能力。α‖+算法在ProM中实现,可在http://pan.baidu.com/s/1o8KC H8e网站下载源码和实验数据。
在进行合规性检测(也称为一致性检测[14])时,将事件日志中的事件与过程模型中的活动关联,并且将两者进行对比,目标是找到模型的行为并观察行为之间的共性和差异。合规性检测技术可以被用来度量过程发现算法的效率。本文利用ProM中Check Precision based on Align-ETConformance插件生成精确度,并比较过程模型与日志的精确度[15]。
4.3.1 α‖+算法和α‖算法对比
对于本文实验数据,α‖+算法的挖掘结果如图1所示。从图1可以看出,Petri网不存在死锁和悬点,是合理的工作流网。在网中一共有16个库所和11个变迁,其中,Start库所表示开始库所,End库所表示结束库所。

图1 α‖+算法挖掘结果
对于本文实验数据,α‖算法的挖掘结果如图2所示。从图2可以看出,Petri网中一共有15个库所和11个变迁,变迁i缺少后继库所,使得挖掘结果中存在悬点,即该Petri网不是合理的工作流网。比较图1和图2可以看出,图1的挖掘结果比图2更准确。

图2 α‖算法挖掘结果
2种算法挖掘结果的精确度比较如图3所示,其中,精确度取值为0~1。从图3可以看出,随着日志规模的增大,α‖+算法和α‖算法的精确度都变大,且α‖+算法的精确度一直比α‖算法高。

图3 α‖+算法和α‖算法精确度比较
4.3.2 α‖+算法和IM算法对比
对于本文的实验数据,α‖+算法和IM算法能得到相似的过程模型,IM算法挖掘结果如图4所示。其中,加粗线表示无声变迁。相比图1,图4存在多余的库所和变迁,使得模型存在多余结构,最终会增加模型的复杂度,降低精确度。
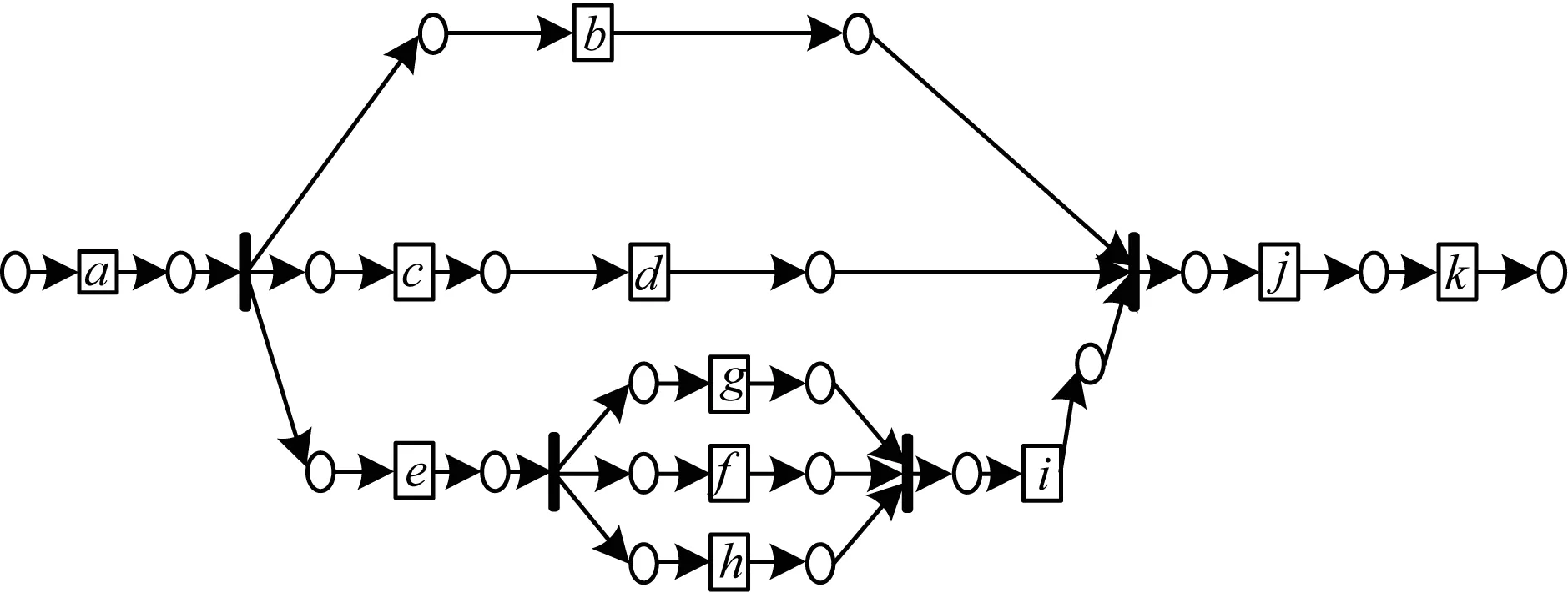
图4 IM算法挖掘结果
图5所示为2种算法挖掘结果的精确度比较。从图5可以看出,随着日志规模的增大,α‖+算法和IM算法的精确度都变大,但α‖+算法的精确度一直比IM算法高,且精确度差值呈现增加趋势。

图5 α‖+算法和IM算法精确度比较
5 结束语
本文针对并发完备日志挖掘,提出一种α‖+算法,通过发现潜在因果跟随关系挖掘得到合理工作流网,实验结果验证了该算法的准确性。但本文算法在实验数据选择以及适应范围上仍存在局限性,导致算法应用不够广泛。下一步考虑将实验从模拟数据扩展到实际数据,将算法应用范围从特殊结构扩展到一般结构,以提高本文算法的通用性。
