基于Python爬虫技术的IT类毕业生求职数据抓取与分析研究
2018-12-28席一


摘要:在分析網络时代爬虫技术的基础上,介绍了基于python语言爬虫技术的基本情况及其特性,并列举了利用python语言编写爬虫程序对前程无忧网的IT类求职数据行了爬取,对爬取的数据进行了统计分析, 得出相关结论。
关键词:Python;Scrapy;爬虫技术;数据分析;就业推荐
1.引言
随着大数据时代的发展,网络上有价值信息的读取和解析渐渐成为成功挖掘数据的基础性工作。面对互联网上各种格式的网页和网页开发者不同的设计思路,网络爬虫技术在近年来获得了人们越来越多的关注和研究,爬虫技术的发展驱动了现代的大数据网络时代。爬虫技术是一把利用网络上庞大的数据资源的利器,通过构造爬虫,不仅可以连接数据和解析数据,还可以将这些数据进行分析并将分析结果利用图表进行展示。爬虫可以实现网页之间的连接,构建整个网站的地图映射。除此之外,爬虫不会遗漏扩展的链接,会继续对其进行跟踪。
中国IT产业在过去5年的时间里,经历了28%的年增长速度,比同期的国家GDP增长速度的3倍,IT产业占全国工业比重达到12.3%,占GDP的9.1%,成为第一大产业。伴随着行业的发展,IT人才的短缺现象将会越来越严重。据估计,目前中国市场对IT人才的需求每年超过50万人。而国内目前的IT教育主要是高等学校计算机、电子、电信、信息技术等相关专业的学历教育,每年培养的大学毕业生约为5万,远远不能满足市场的需求。
前程无忧网作为国内最大的招聘网站之一,所拥有的信息极其庞大,令人眼花缭乱、无从选择。在大数据的时代下,Python语言充分的展示出了它的优势,在科学计算、文件处理、数据分析等领域越来越凸显其价值。使用Python对前程无忧网IT类招聘信息中的薪资数据、职位信息、工作经验等信息的搜集,利用Scrapy抓取这些招聘信息并用Pandas对数据进行清理,通过对这些数据的分析,可以为IT类求职者推荐求职岗位和就业城市,让IT类求职者对选择求职岗位和就业城市有一个大致的判断。
2.求职网站面临的问题
2.1招聘信息鱼龙混杂
求职者打开招聘网站会发现,求职信息太多以至于不知道如何取舍。比如选择IT类的职位,应该选择哪个岗位呢?是JAVA开发工程师,亦或是前端开发工程师?选择岗位无非最关心的就是薪资待遇,不仅仅是目前的薪资待遇,还有在未来几年薪资的上升空间。这些东西是招聘网站所不能直接体现的。
2.2岗位需求量
当求职者寻找工作时,往往会关心自己在这份工作中到底具有多少竞争力,抛开求职者本身的能力,竞争力的另一个体现就是这份工作到底需要多少人,需要的人越多,竞争就越小,就越容易找到工作。就招聘网站而言需要数据为求职者提供选择工作的依据
2.3各城市的同一岗位的比较性
对于求职者来说,除了薪资的增长起伏和竞争力,还有一个重要的因素,那就是求职者希望的工作城市,虽然网络上总是有报道说这个城市收入水平达到多少,物价达到多少。但是,求职者不仅仅关心收入水平,也希望知道自己选择的岗位更应该去哪个城市工作。
3 解决方案
3.1 解决思路
获取到前程无忧网IT类的招聘信息后,针对IT类毕业生遇到的求职信息获取等问题,提供以下解决思路:
(1)薪资增长情况:将获取到的招聘信息以城市和岗位为条件分组,计算每一组在不同工作经验的最低薪资和最高薪资的平均水平。
(2)岗位需求量:将获取到的招聘信息以城市和岗位为条件分组,计算每一组的岗位需求人数总和。
(3)同一岗位在不同城市的比较性:将获取到的招聘信息以城市和岗位为条件分组,然后计算一个比较性的期望值,这个比较性的期望值通过公式“1/工作经验年限对应的数值*平均工资*需求人数(满足工资高,需求人数多,工作经验低,推荐指数越高的原则)”计算而得。
3.2 数据获取
本文通过基于Python的Scrapy框架编写爬虫,编写爬虫前先去前程无忧网站分析页面的url请求序列,方便整理出编写爬虫逻辑。然后根据页面信息和研究目的设计数据库字段。再根据数据库字段,配置item、根据页面请求到的数据配置Field()进行数据存入前处理。接着根据url请求的序列设计不同的回调函数,并发起不同的请求获取返回item。然后创建Proxy、UserAgent下载器实现动态浏览器头、随机代理ip,失败后更换ip继续请求,提高爬虫的存活率和数据采集完整性。最后使用线程池获取数据库连接并保存数据到mysql数据库。以下时获取数据的关键代码:
allowed_domains = ['51job.com']
start_urls=[‘https://search.51job.com/list/030800%252C230300%252C230200%252C070300%252C250200,000000,0000,01%252C37%252C38%252C40%252C32,9,99,%2520,2,1.html']
def parse(self, response):
post_urls=response.css("#resultList .el .t1").xpath('.//a/@href').extract()
for post_url in post_urls:
yield Request(url=parse.urljoin(response.url,post_url),callback=self.parse_detail)
next_url = response.css(".dw_page ul li:last-child a::attr(href)").extract_first('')
if next_url:
yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse)
def parse_detail(self, response):
item_loader = TempDataItemLoader(item=TempDataItem(), response=response)
url = response.url
salary_id = re.match(r'.*/(\d*).html', url, re.I)
item_loader.add_value('salary_id', salary_id.group(1))
3.3 數据处理
当数据获取成功后,就需要把这些数据形成直观的的图表了,这里使用了Echarts.js插件。Echarts.js这个开源可视化库提供的一系列图表,为此爬虫的数据展示提供了良好的支持。首先使用Django的ORM查询数据库中的数据,这里只对就业推荐功能做以下说明:
当使用Django查询出数据后发现,Django的ORM对复杂查询与计算的支持并不好,于是采用了Pandas库。
# 将数据库查出的数据转换为Pandas的数据格式
df = pandas.DataFrame(list(salary_data))
# 使用pandas提供的函数对数据进行清洗,将将复杂数据替换成数字。
df = df.replace({'1年经验': '1', '2年经验': '2', '3-4年经验': '3', '5-7年经验': '4', '8-9年经验': '5', '10年以上经验': '6'})
# 将数据以城市分组
grouped = df.groupby('city__name')
#遍历每一个城市下,求出平均薪资和平均需求人数
for city__name, group in grouped:
experience_value = 0
for experience, s in group.groupby('experience'):
# mean()函数用来计算平均数(计算平均薪资 和平均需求人数)
s = s.mean()
# 就业推荐指数
experience_value += round(1 / int(experience), 6) *int(s['avg_salary']) * int(s['people_count'])
3.4 处理结果
首页会每过5秒就随机更换一个城市各IT职位的需求人数以及某城市某一职位不同工作经验的薪资增长情况,如图1所示。
薪资起伏页面,展示的是搜索某一城市的某一职位,如苏州的python职位就会呈现这个职位的不同工作经验的薪资增长情况,如图2所示。
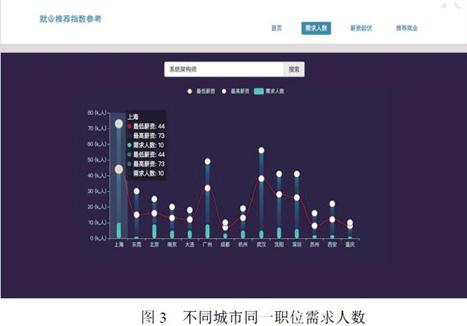
需求人数页面,展示了搜索某一职位呈现这个职位在不同城市的需求人数以及平均最高薪资和平均最低薪资,如图3所示。
推荐就业页面展示的是搜索某一职位会出现这一职位在不同城市的推荐指数。这个指数根据公式:1/工作经验年限对应的数值*平均工资*需求人数(满足工资高,需求人数多,工作经验低,推荐指数越高的原则),如图4所示。
4 结语
在大数据时代,数据分析往往能得到一些事物的规律,在大数据的分析结果下,人们往往能依据其中的某些规律,为自己的选择提供一定的参考。通过爬取前程无忧招聘网站的数据,分析出IT类行业的不同职位的一个招聘状况,在一定程度上有效为IT类应届毕业生的就业选择提供了直观的数据参考,帮助IT类应届毕业生选择自己的工作城市和职位。
参考文献:
[1]王全胜.Python在校园数据分析中的应用--以一卡通消费为例[J].电脑知识与技术,2017(3)1-2.
[2]涂小琴.基于Python爬虫的电影评论情感倾向性分析[J].研究与开发,2017(12)52-54.
[3]魏冬梅,何忠秀,唐建梅.基于Python的Web信息获取方法研究[J].软件导刊,2018(1)41-43.
[4]陈智,梁娟.基于Python的微博发表意向预测研究[J].智能处理与应用.2018(4)56-59.
[5]熊畅.基于Python爬虫技术的网页数据抓取与分析研究[J].数字技术与应用.2017(2)12-14.
[6]赵丽娜.基于Python爬虫的借阅数据获取[J].北华航天工业学院学报.2018(8)61-62.
作者简介:席一(1979~),男,山东聊城人,重庆第二师范学院数学与信息工程学院,讲师,硕士。
基金项目:重庆第二师范学院首批辅导员工作精品项目:“三源整合,六室联动”,探索“互联网+”形势下高校创新创业教育模式(项目编号201604);2018年重庆市教育委员会人文社会科学研究项目:思想政治教育角度下的大学生创新创业教育研究(项目编号18SKSZ042)。
