基于高铁沿线用户分类的LTE专网优化
2018-12-27AlexisHuet徐珊珊王计斌金栋梁许正
Alexis Huet,徐珊珊,王计斌*,金栋梁,许正
(1.南京华苏科技有限公司,江苏 南京 210000;2.南京邮电大学自动化学院,江苏 南京 210000)
1 引言
随着高铁的快速发展,之前配置的高铁网络出现了很多问题。考虑到高铁的特殊环境,移动运营商为高铁沿线配置了专网小区来保障高铁用户的通信体验。但随之而来的一个关键问题是——如何对高铁专网的使用及性能情况进行评估。
目前,已经有一些文章对高铁专网的覆盖和优化进行过研究,但主要是直接分析该小区用户网络质量的相关指标,并针对列车车体穿透损伤、多普勒频移和站址的规划与布局等方面提出了优化方案[1],而对于文中提到的区分用户以实现对高铁专网性能进行监控的研究尚属空白。因此,本文通过将高铁沿线用户分为高铁用户和大网用户来检测并评估高铁专网的服务质量。
2 数据简介
本文中所研究的数据来自中国江苏省某地市移动通信公司。由于数据源中缺乏分类样本集,因此从50 万个用户中随机抽取2 000个用户进行人工分类。文中共涉及到经过该地市的3条高铁线路,途径3个高铁站点,分别为:京沪、宁杭、沪宁高铁,且这三条线路总长度均超过了150 km,对于4G网络均有针对性的专网覆盖。
高铁小区(专网小区)是指高铁沿线专门用于高铁用户使用的小区。大网小区(非高铁小区)是指非高铁小区的其他小区,通常为非高铁用户提供服务。同样的,高铁用户是乘坐高铁的用户,而大网用户则是指非高铁用户的任何其他用户。
本文共用到小区信息数据和用户数据这两种数据。小区信息数据主要包括当前高铁线上高铁小区的位置数据(经纬度)和1 km内大网小区的ECI编号及位置;用户数据主要包含用户信令切换信息以及相应的时间标识。
图1显示的是高铁小区的一个切换示意图(图片来自互联网上,华为武广高铁4G网络)。在图中的高速铁路线上,绿色区域表示专网小区信号覆盖区域,灰色表示大网小区信号覆盖区域。

图1 高铁小区示意图
3 实验设计
文中将高铁沿线用户进行分类,有两个要点:
(1)鉴别出使用高铁专网的大网用户,这部分人在使用高铁专网的总人数中占比应该很低,以防高铁专网的超负荷连接;
(2)鉴别出使用大网的高铁用户,高铁小区和大网小区信号的快速切换,会导致高铁用户上网体验的下降。
整个实验设计阶段分为两部分:训练阶段和自动化阶段,如图2所示:

图2 训练阶段流程图
首先收集有关高铁线路周围的小区信息,从这些信息中可得到高铁线路图;同时,收集用户的信令切换数据,该数据可推出高铁专网用户及大网用户的网络连接行为。然后在做分类模型前,手动地区分高铁用户和大网用户,创建信号切换速度等行为特征指标。最后选择合适的分类算法鉴别出两种用户。
训练阶段存在手动分类部分,对于样本量不大的数据集可以进行操作,如果数据集比较大,则自主分类的可操作性不强,所以本文设计了一个自动化阶段,如图3所示:

图3 自动化阶段流程图
首先从数据中提取用户行为特征指标;然后利用分类算法区分出高铁用户和大网用户;最后通过总结用户使用小区网络的情况来评估小区的服务质量。
3.1 训练阶段
本文对收集到的数据进行挖掘分析。第一步根据高铁小区经纬度信息刻画出高铁轨道线路,利用主成分分析方法[2]对小区经纬度信息进行合适的旋转,接着通过广义加性模型(GAM)[3]刻画出高铁线路,得到如图4所示的高铁沿线和覆盖小区图。第二步创建模型数据集。该数据集在用户数据的基础上增加了两个变量:第一个是类别变量,标记小区是高铁小区还是大网小区;第二个是距离变量,表示小区离高铁出发站的距离(单位为km)。
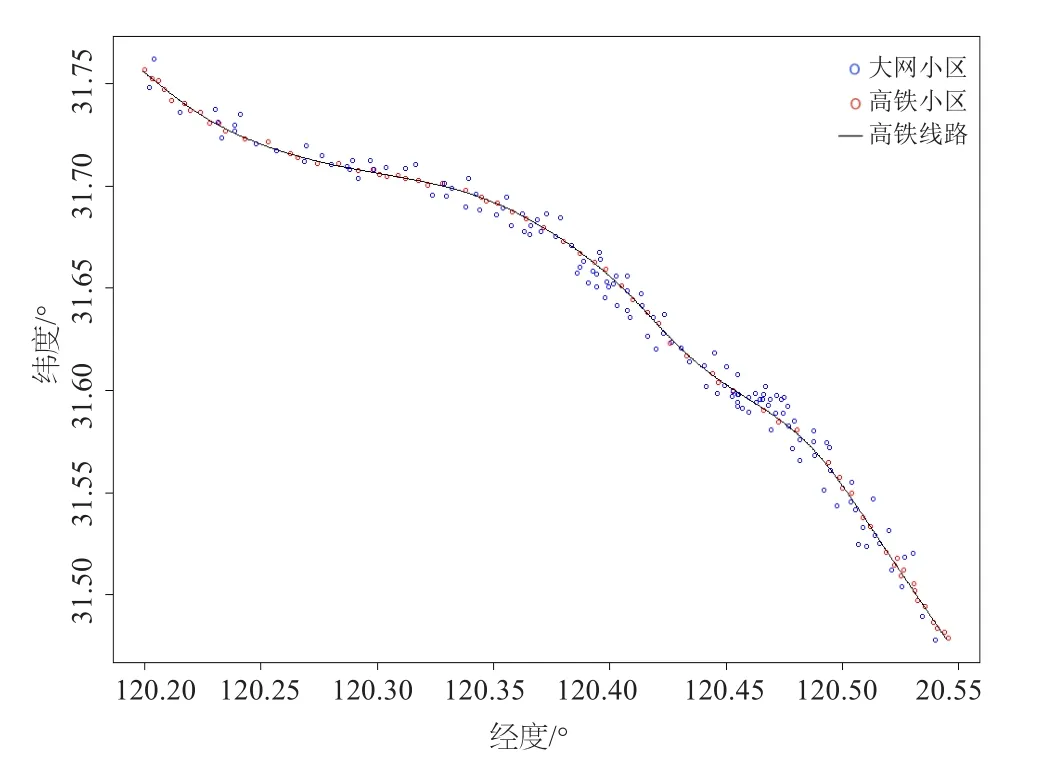
图4 高铁沿线和覆盖小区图
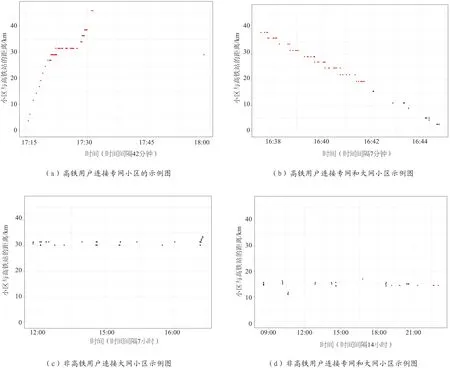
图5 典型用户小区移动图
图4中,蓝点表示距高铁小区1 km内的大网小区;红点表示高铁小区;黑色曲线代表高铁路线。从高铁路线可推测出每个小区和高铁线路的距离,进而推导出目标小区和高铁出发站之间的距离。
图5是对用户当天在高铁小区的时间及小区距离进行可视化呈现,其中只画出了部分用户的信息图,图中每个点表示用户和小区之间发生的网络连接。(a)中红色点表示高铁用户仅连接到专网小区的示例;(b)中红色点表示高铁用户连接到专网小区,黑色点表示高铁用户连接到一些大网小区的示例;(c)中黑色点表示非高铁用户连接到大网小区的示例;(d)中黑色点表示非高铁用户连接到大网小区,红色点表示非高铁用户连接到一些专网小区的示例。
3.2 自动化阶段
每个用户都有信令切换时间及切换小区离高铁出发站的距离信息,且时间是不规则的。在做完特征指标提取后,每个用户的小区切换信息、移动速度、移动距离都可以用固定的时间来表达。其中较重要的特征是用户的移动速度。移动速度是根据小区离高铁出发站距离及切换至该小区网络的时间与出发时间计算所得。在时间较短且切换小区较近的情况下,瞬时速度可达600 km/h,为了避免计算出这样不可用的高铁速度数据,考虑按照秒、分钟、小时等不同时间段计算平均速度。具体可以计算一天内特定持续时间段(例如30分钟)的用户最大移动距离。在本系统中,用如下指标来计算最大移动距离:1 s移动速度、5 s移动速度、25 s移动速度、2 min移动速度、10 min移动速度、15 min移动速度、20 min移动速度、25 min移动速度、30 min移动速度、35 min移动速度、40 min移动速度、45 min移动速度、50 min移动速度、55 min移动速度、1 h移动速度、4 h移动速度和24 h移动速度。对于每个用户,还可以创建和小区数关联的特征变量,这些附加特征包括如下条件:
(1)连接到专网小区的总次数;
(2)连接小区的总次数;
(3)定义专网小区连接次数占比(a)/(b);
(4)用户连接到小区的数目(1个小区有多次连接只计数一次)。
提取所有特征指标后,每个用户有21个特征指标,基于该指标数据对用户进行分类。在机器学习领域,已有很多成熟的分类算法,其中一个较简单有效的算法是随机森林[4],可以在分类的同时提取出重要的特征变量。
定义1:随机森林是一个由一组决策树分类器{h(X, θk), k=1, 2, …, K}组成的集成分类器,其中{θk}是服从独立同分布的随机向量,K代表随机森林中决策树的个数,在给定自变量X的情况下,每个决策树分类器通过投票来决定最优的分类结果。
随机森林算法涉及对样本单元和变量进行抽样,从而生成大量的决策树。对每个样本单元,所有决策树依次对其进行分类。假设训练集中共有N个样本单元,M个变量,则随机森林的算法如下:
(1)应用bootstrap方法从训练集中随机有放回地抽取K个新的自助样本集,并由此构建K棵分类树,每次未被抽到的样本组成了K个袋外数据;
(2)在每一棵树的每个节点处随机抽取m<M个变量,通过计算每个变量蕴含的信息量,然后在m个变量中选择一个最具有分类能力的变量进行节点分裂;
(3)完整生成所有的决策树,无需剪枝;
(4)终端节点的所属类别由节点对应的众树类别决定;
(5)对于新的观测点,用所有的树对其进行分类,其类别由多数决定原则生成。
定义2:给定一组分类器h1(X), h2(X), …, hk(X),每个分类器的训练集都是从原始的服从随机分布的数据集(X,Y )中随机抽样所得,余量函数定义为:

式中,I(·)是示性函数。余量函数用于度量平均正确分类树超过平均错误分类树的程度,余量值越大,分类预测则越可靠。
4 结果分析
文中为了确保结果的可靠性,将人工分类的数据集分成两部分:随机抽取80%用户为训练集;剩下的20%用户为验证集。用训练集对模型进行训练,接着在训练集和验证集上同时测试。结果显示,该模型可以高效地区分出高铁用户及大网用户。在训练集上,准确率达到99%;在验证集上,准确率为98%。每个新用户可以通过该模型提取的重要特征指标进行分类。具体分类如图6所示。

图6 分类结果
分类结果如表1所示:

表1 相关高铁线路每日小区服务性能的全局概要
表1给出了该地市沪宁线上某天的所有高铁小区服务性能的全局概要,从表中可以看出在这一天,所有高铁小区中高铁用户为4 751人,高铁脱网人数为218,非高铁用户占用高铁网络人数为278。
经实验发现有些高铁小区中存在较多高铁用户使用大网的情况,具体结果如表2所示。
表2给出了该地市沪宁线上存在问题的专网小区中高铁用户使用网络情况,从表中可以看出四个专网小区中高铁脱网用户数较大,需要对这些小区进行网络优化。经过优化后,各小区RSRP均值比优化前有所提高,因此可以看出通过鉴别高铁用户对挖掘高铁小区网络质量有着重要的意义。
5 结束语
高铁的商业化运营,给铁路运输行业带来新鲜血液的同时也带来了移动网络优化的新问题。本文对信令数据在时间序列上进行时间、频率、速度等特征的提取,并对提取的特征通过机器学习算法进行分类得到如下结论:
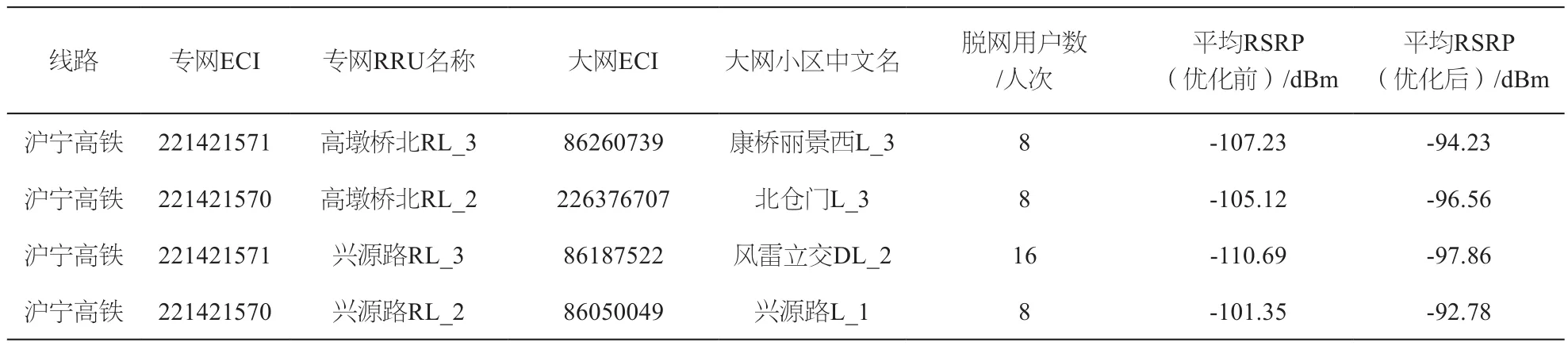
表2 各小区高铁用户情况分析表
(1)通过随机森林算法对用户进行分类,区分出高铁/非高铁用户,且验证得到高铁用户识别准确率达到90%以上;
(2)基于高铁沿线用户判别分析算法,对高铁专网进行业务质量评估与故障定位,对重点问题小区进行性能评价与网络优化。
由于高速铁路运行环境的不规则性,高铁轨道存在隧道、弯道、桥梁等各种场景,之后可以针对一段不规则轨道对本文中的算法进行验证及优化。
