多传感器融合的数控机床热误差回归建模新方法*
2018-12-26余文利姚鑫骅
王 胜,余文利,姚鑫骅
(1.衢州职业技术学院,浙江 衢州 324000;2.浙江大学机械工程学院,杭州 310027)
由内部和外部热源导致的机床热误差是影响机床加工精度的主要因素。内部热源包含直接由机床本身和切削加工所产生的热源,如主轴电机、轴承摩擦等。外部热源归因于机床所处环境,如相邻机床、机床防护罩的开合、环境温度昼夜的周期变化以及季节差异等。这些热源之间的相互作用导致了机床复杂的热行为。具统计,精密加工中,热变形引起的制造误差占总误差的40%~70%[1]。提高机床加工精度主要有3种途径:误差避免法、误差控制法和误差补偿法[2]。误差避免法和误差控制法代价高昂,并会带来其他诸如振动和加速度降低等问题,误差补偿法因其具有高效、经济且易于实现等优点,已成为高精度数控加工的一个热点研究方向[3]。
要实现有效的热误差补偿,除了依靠可靠的测量装置和高效的测量方法,还必须建立能够反映关键温度测点的温度数据同机床热误差数据之间内在关系的统计数学模型。目前国内外学者针对误差补偿模型做了大量的试验和研究,从不同角度揭示了机床构件温度与热误差之间的关系。许多理论被引入到热误差建模中,如回归理论[4-6]、人工神经网络[7-8]、灰色理论[9]、贝叶斯理论[10]、模糊逻辑[11]和支持向量机[12-13]。在热误差补偿中,回归分析因其结构简单和易于实现,成为当前最常用的热误差建模方法。目前,大多数热误差回归模型都是基于带有固定参数的前移回归,如多项式回归模型和多元回归模型。前移回归是一种典型的参数化模型,一旦基于实验数据确定了模型参数,则模型形式即固定下来。在长期预测中,如果自变量的趋势与建模开始时的趋势不一致,会导致预测精度下降。以此同时,如果经过热关键点选择后的优化温度输入仍具有共线性,则模型精度将受到影响。因此,前移回归模型的外推能力和泛化能力均存在不足。
本文首先基于模糊聚类建立一个评价模型来优化温度分类,然后根据温度变量与热误差的相关系数,在每一组温度中选择一个温度作为代表,将不同组中选出的多个代表性温度作为候选温度。然后,使用SIR模型来进行热误差预测。最后,在一台卧式精密加工中心上使用29个温度传感器和5个位移传感器测量了温度场和热漂移。基于相关性分析,确定5个候选温度作为SIR模型的输入。比较了SIR模型和逐步回归SR(Stepwise Regression)模型的建模结果,证明了本文模型的具有更高的预测精度和更好的鲁棒性。
1 温度变量的模糊聚类分析
由于温度变量没有明确的界限,因此其分类可以通过模糊集理论的软划分来实现。根据温度变量的相似度或亲疏性质,模糊聚类分析通过模糊相似关系来实现温度变量的分类。为了使处理过程简单直观,一般将相似关系转化为模糊矩阵,然后进行模糊聚类分析。
1.1 模糊等价矩阵
为描述温度变量的相关性,相关系数矩阵R构造如下:
R=(rij)p×p, 1≤i,j≤p
(1)
式中:p表示温度变量个数;rij为第i个温度ti和第j个温度tj的相关系数,定义如下:
(2)

根据最大-最小法则,进行以下的组合操作:
R∘R=R2,R2∘R2=R4,…,R2k∘R2k=R2k+1
(3)
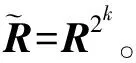
1.2 温度变量分类评价模型
假定阈值λ可以将所有温度变量分类到fλ个分组中,即u1,u2,…,ufλ。如果第i个分组ui包含q个温度变量,则在分组ui(i=1,2,…,fλ)中的每个温度变量序列可以表示为:
(4)
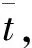
(5)
(6)
则温度变量分类评价模型如下所示:
(7)
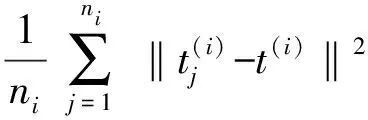
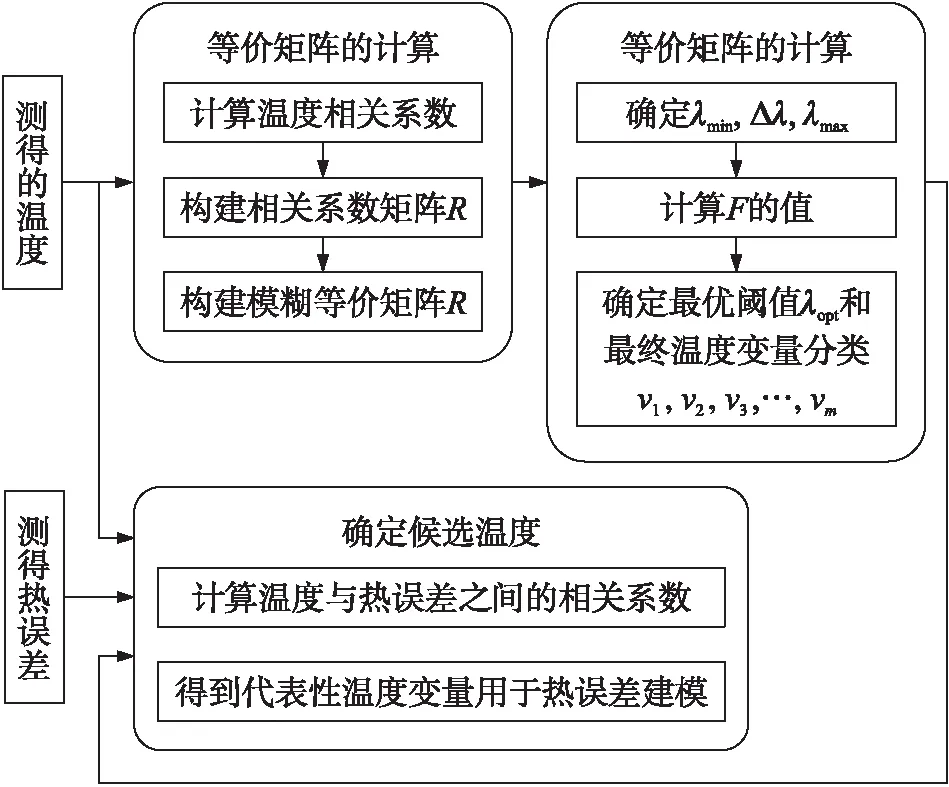
图1 最优候选温度变量的选择过程
1.3 候选温度的确定
评价模型F的最大值对应于最优阈值λopt,在最优阈值条件下,可以得到最终的温度变量分类v1,v2,…,vm。在分组vi(i=1,2,…,m)中,可以进行温度和热误差之间的相关分析。对应于最大相关系数的温度变量被认为是分组中的代表性温度,从v1,v2,…,vm中选择的m个代表性温度作为候选温度。最优候选温度的选择过程如图1所示。
2 热误差的前移回归建模
在热误差补偿中,回归理论因其结构简单和易于实现而被广泛应用于误差预测,大多数热误差的回归模型都是基于固定参数的前移回归,如多项式回归和多元回归。
定义独立变量X和y,在X中的温度变量数为p,数据集T可以描述为:T={(x1,y1),…,(xn,yn)},其中xi∈X⊆Rp,yi∈y⊆R1。
构建前移回归模型需要以下5个步骤:
①确定关系函数y=f(X);
②限定函数集F由f(X)构成;
③选择一个损失函数c(X,y,f)来确定yi与f(xi)之间的偏差;
⑤找出能够最小化F中经验风险Remp的f(X)。
从上述步骤可以看出,前移回归模型是一种参数化建模方法。一旦模型参数基于实验数据确定,则模型形式就固定下来。在长期预测中,如果自变量的趋势与建模初期的趋势不一致,预测精度将会下降。同时,如果作为优化温度输入的热关键点选择仍然具有共线性,建模的精度将会受到影响。因此,前移回归模型存在外推能力差和泛化能力低的不足。
3 数控机床分段逆回归热误差建模
3.1 SIR方法的原理简述
SIR方法[14]最早由Ker-Chau Li(1991年)提出,是一种非参数化的逆回归技术。在非线性模型假设下,SIR能够对高维独立变量系统进行综合降维,得到一个“有效降维空间”(Effective Dimension Reduction Space,简称e.d.r空间)。此外,在最小信息损失下,SIR将原始变量综合为主成分,可以避免信息重叠和高相关性,进一步优化模型输入。
给定自变量y⊆R1和自变量X⊆Rp,则SIR基于以下模型:
y=g(β1X,β2X,…,βkX,ε)
(8)
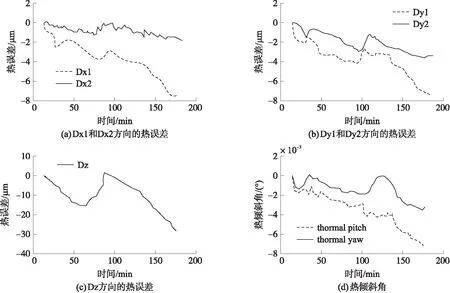
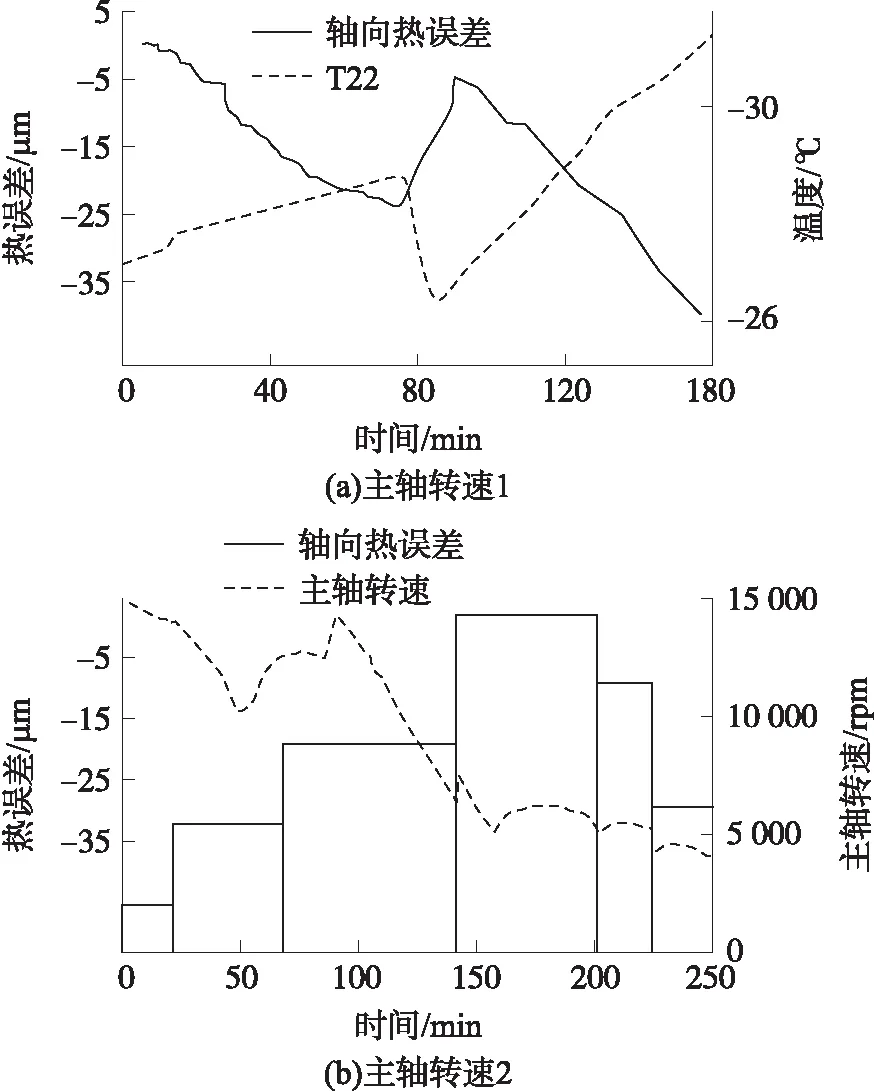
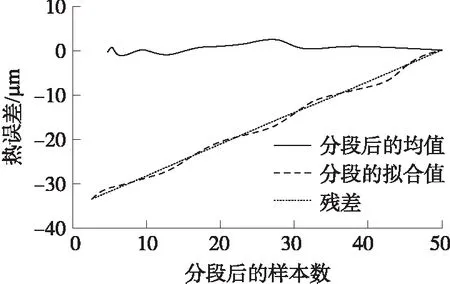
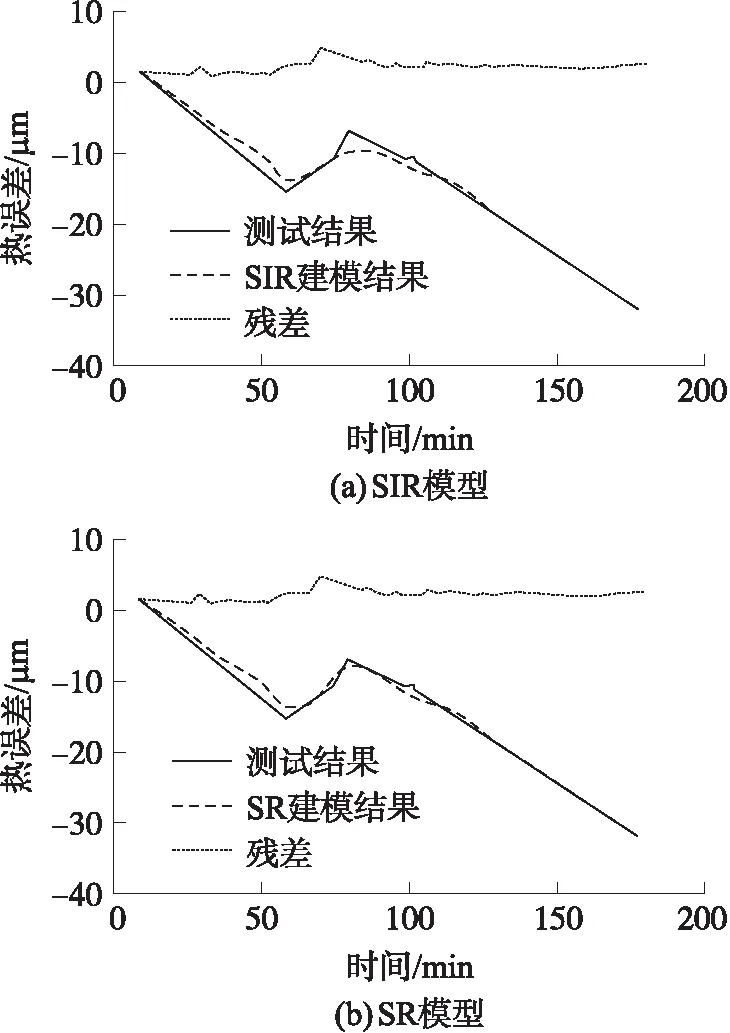
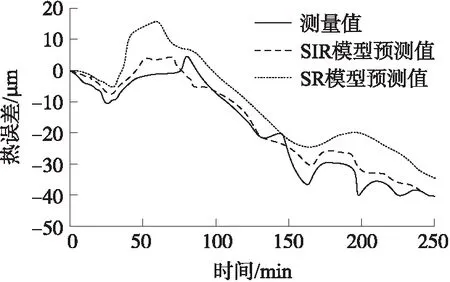
式中:g是空间Rk+1中的未知函数,β1,β2,…,βk是未知行向量。在最小信息损失情况下,通过βi(i=1,2,…,k)将p维独立变量X投影到k维子空间(β1X,β2X,…,βkX)T。当k 在热误差建模中,定义热误差y=[y1,y2,…,yn],温度变量X=[x1,x2,…,xn],其中xi=[xi1,xi2,…,xip]T(i=1,2,…,n)。基于SIR的建模步骤如下所示: ⑤投影值计算:在e.d.r空间中的投影Z={[z1,z2,…,zk]|zi=βiX,1≤i≤k}。 热误差实验在如图2(a)所示的卧式精密加工中心上进行。29个温度传感器分布在加工中心上,其中,T22和T29分别检测冷却液和环境温度,其他温度传感器在加工中心的连接位置如表1所示。 表1 温度传感器布置 根据ISO230-3标准,使用5个位移传感器来检测热膨胀,如图2(b)所示。 图4 位移传感器测量数据比对 图2 温度传感器布置和主轴热误差测量 图2中,Dx1和Dx2用于检测X方向的热误差,Dy1和Dy2用于检测Y方向的热误差,轴向热误差通过Dz来测量。 为了仿真不同工况条件下的加工过程,进给速度设置为3 000 mm/min,给出了两种类型的主轴转速,如图3所示。实验中,托架沿3个方向移动。 图3 随机转速分布 4.2.1 各方向热误差分析 在二种随机转速下,对主轴热误差进行检测。来自于两种实验条件下的检测结果表明轴向热误差要大于两个径向热误差。同时,通过4个径向热误差计算得到的径向热倾斜要小一些。在主轴转速1条件下所测得的5个方向的热误差如图4所示。本文在热误差建模时,选择轴向热误差作为自变量。 当机床通过冷却系统进行冷却时,流过主轴强制冷却液使得产生的热量和热膨胀达到最小。从图5(a)可以看出,机床工作75 min后开始进行强制冷却,热误差随着冷却液的温度降低而减小。从图5(b)可以看到,热误差的两个主要波动对应于冷却液温度的两次显著下降。此外,从图6可以看出,热误差会随着主轴转速的变化而波动。 图7 温度传感器测量数据比对 图5 两种主轴转速下热误差与冷却液温度 图6 两种主轴转速下的热误差 4.2.2 各测点温度分析 在主轴转速1情况下,29个温度传感器测得的温度曲线如图7所示。当强制冷却液流过主轴时,主轴的温度开始下降。 因此,从图7(a)可以看出,T4、T6、T21、T23、T24和T26测得的温度变化趋势与冷却液温度T22相似。与上述7条温度曲线相比,主轴箱的波动幅度较小。在进给系统,安装在电机上的温度传感器测得的温度较高。安装在导轨或立柱对称位置上的温度传感器具有接近的温度曲线。 基于上述实验数据通过式(7)计算得到最大的评价模型值为21.326 8,可以将温度变量分为5类:(1)T1~T3,T5,T7~T17,T19,T20,T25,T28(2)T4,T6,T21~T24,T26;(3)T18;(4)T27;(5)T29。则根据温度和轴向热误差的相关系数,最终选取5个候选温度分别为T18、T19、、T24、T27、T29。虽然评价模型确保每个温度分组内变量的紧密度和分组间的最大距离,但不能完全消除候选温度之间的共线性。为进一步消除共线性,在SIR建模时引入了主成份分析。 Z1=0.112 3t1+0.296 7t2+0.908 1t3+ 0.204 8t4+0.181 3t5 (9) Z2=0.606 1t1+0.296 5t2-0.361 6t3+ 0.385 4t4+0.515 2t5 (10) 通过用主成份Z1和Z2替换5个温度增量t1~t5,可以将5维的热误差模型简化为2维模型。使用式(9)和式(10),49段温度变量在第1和第2个主成份上的投影Zt1和Zt2分别如下所示: Zt1=[4.056 3,2.263 2,…,0.013 9] (11) Zt2=[-0.074 4,1.917 5,…,0.002 3] (12) 式中:Zt1和Zt2的长度均为49。 z=0.963 9-8.420 0Z1-7.043 9Z2 (13) 49个样本均值的拟合曲线如图8所示,显然49个数据的拟合精度非常高。 图8 SIR模型的拟合结果 4.4.1 拟合精度比对 在5.3节中,SIR使用主轴转速1条件下的49个样本均值进行热误差建模。通过式(9)和式(10)将所有温度数据进行投影,然后将投影数据作为式(13)的输入。建模结果如图9(a)所示,从图9(a)可知,残差在3.1 μm以内,模型决定系数为0.985。 图9 两种模型的建模结果 为了研究SIR模型的性能,使用SR进行温度变量优化和热误差建模,从3个备选模型中,可知由ΔT24、ΔT27、ΔT29所构建的模型具有最好的性能,其轴向热差z描述如下: z=0.705 9-8.118 6t3+1.134 5t4-6.083 2t5 (14) SR模型的建模结果如图9(b)所示,从图9(b)可以看出,SR模型的拟合曲线非常接近于测量曲线,残差在2.5 μm以内,模型决定系数为0.991。因为SR模型是基于主轴转速1条件下的所有样本进行热误差建模,而SIR模型是基于49个样本均值进行热误差建模,因此,SR模型的拟合精度要稍高于SIR模型。总的来说,两种模型均有较高的拟合精度。 4.4.2 预测精度比较 在热误差建模时,模型的鲁棒性是一项非常重要的性能,在某一工况条件下建立的模型可能不适合于另一工况下的补偿。为了验证本文提出模型的有效性和鲁棒性,在图3(b)的主轴转速2下进行了另一项实验。基于主轴转速1的所有数据所建立的两个模型被用于预测主轴转速2下的热误差,验证结果如图10所示,从图10可以看出,SIR模型的预测值比SR模型更接近于测量值,从而证明了SIR模型具有良好的鲁棒性。因为SIR模型具有较小的预测偏差,因此,SIR模型比SR模型更适合于热误差的补偿。 图10 两种模型的预测结果 本文提出了一种基于SIR模型的新的热误差建模方法,以建立热变形与温度之间的关系。在非线性模型的假设下,该方法可以在不损失变量信息的前提下有效地减少输入变量的维度。同时,该模型还进一步消除了输入变量之间的共线性。在建模前,使用基于模糊聚类的评价模型对温度变量进行分类,在模型最大评价值下,得到最优的温度分类。然后,根据温度与热误差的相关系数在每组中选择一候选温度变量。通过该方法,从16个温度变量中选择5个候选温度变量作为SIR模型的输入。实验结果表明,相比SR建模方法,基于不同试验样本个数的情况下,SR模型的拟合精度要稍高于SIR模型。但经过聚类分析和SIR降维处理的全新模型预测具有较好的鲁棒性和预测精度,能够准确描述各种工况下数控机床热误差的实际特性。3.2 基于SIR方法的热误差建模
4 仿真试验和结果分析
4.1 传感器元件的制备及热误差测量实验

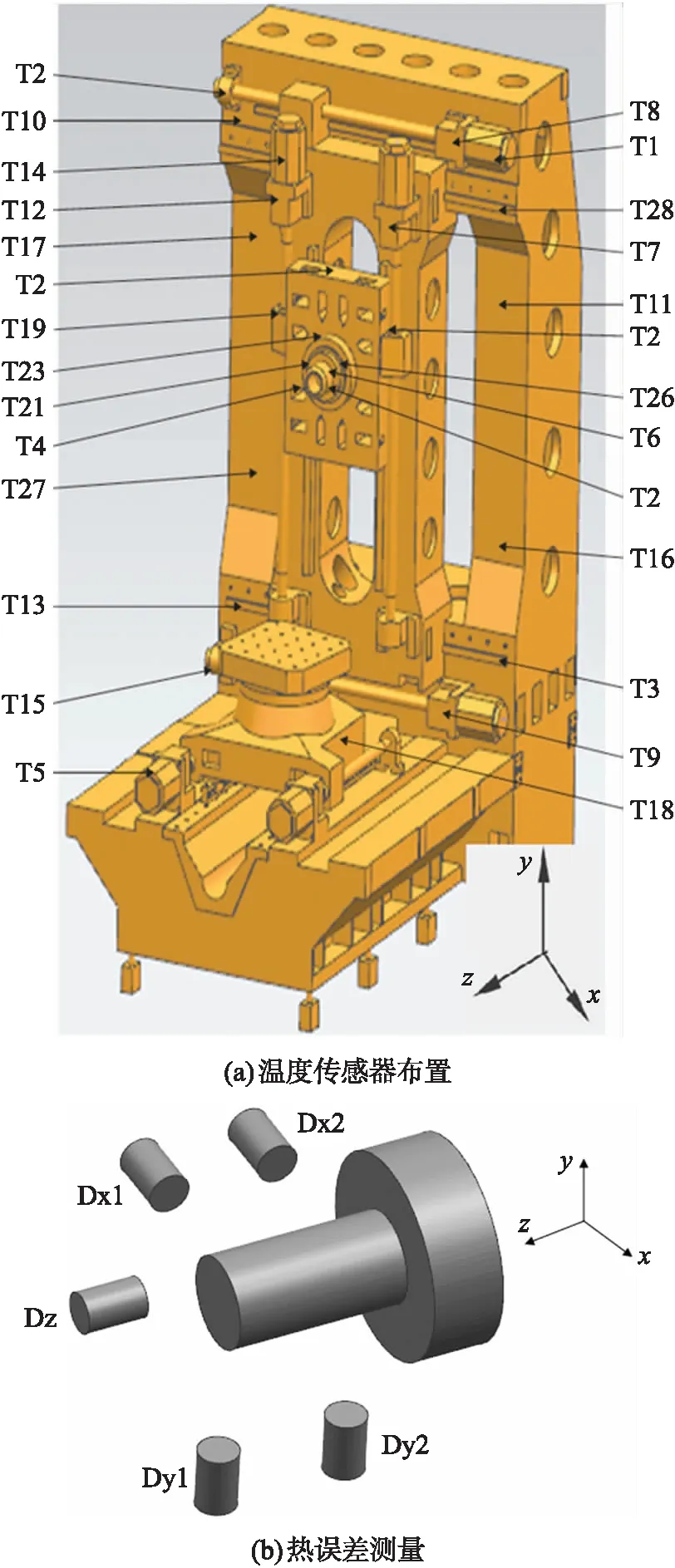
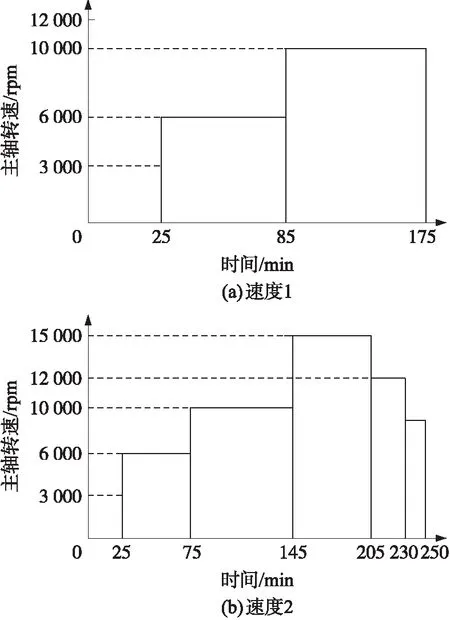
4.2 试验数据分析
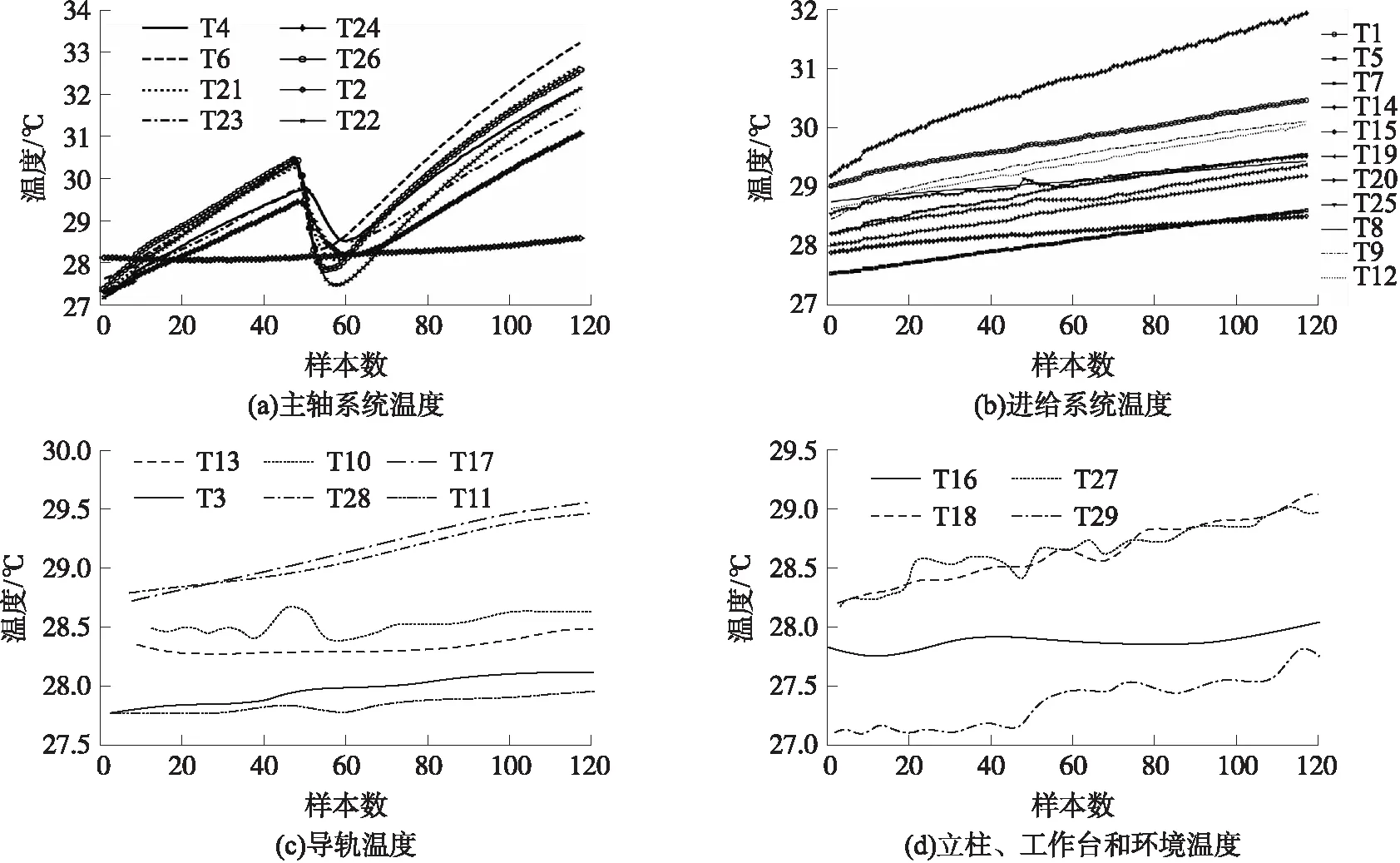
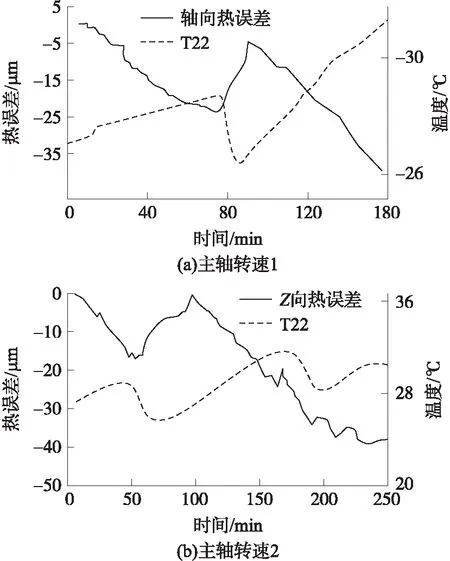
4.3 SIR建模分析方法
4.4 SIR与SR模型建模数据比对
5 结论
