AI学习的秘密
2018-12-25习翔宇
习翔宇
人工智能已经成为一个具有众多实际应用和活跃研究课题的领域,并且正在蓬勃发展。尤其是近几年深度学习发展迅猛,取得了很好的效果。很多基于深度学习的应用也进入我们生活中,例如图像目标识别、机器翻译、自动驾驶系统等。今天就让我们一同走进深度学习的世界,看看拥有如此强大能力的深度学习是如何工作的吧!
深度学习之路
神经网络是深度学习的基础,深度学习的发展也是以神经网络模型的发展为基础的,而神经网络的发展可谓经历了漫长的过程。
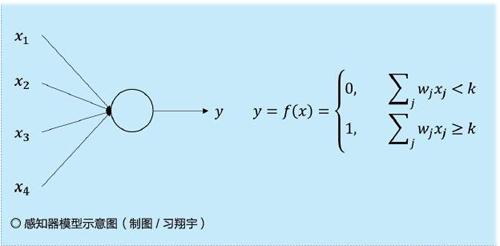
1958年,计算机科学家弗兰克·罗森布拉特(Frank Rosenblatt)提出了两层神经元组成的神经网络,称之为感知器。一个感知器接受若干个二进制输入,并产生一个二进制输出,因此能够对输入的多维数据进行二分类。其中的计算方法为通过加权与阈值比较,如果加权大于阈值,就输出1,否则输出0。该方法使用梯度下降法从训练样本中自动学习更新权值。
但感知器本质上是一种线性模型,只能处理线性问题,就连最简单的异或问题都无法进行正确分类。例如,小红和小丽是好朋友,有一天老师让她们一起打扫教室。我们用x1=1来表示小红打扫教室,x1=0表示小红没打扫教室,x2=1来表示小丽打扫教室,x2=0来表示小丽没打扫教室;用y=1表示只有一个人打扫了教室,否则为0,那么结果只有四种情况如右页表1所示。但是采用感知器模型却无法对此进行正确分类,因此神经网络的研究也陷入了20年的停滞,直到“神经网络之父”杰弗里·辛顿(Geoffrey Hinton)在1986年发明了适用于多层感知器的反向传播算法,并且引入了Sigmoid函数对加权结果进行非线性变换,才解决了这个问题。
2012年,亚历克斯参加ImageNet图像识别比赛,构建了基于卷积神经网络(CNN)的AlexNet模型并取得了冠军,且准确率远超第二名,使得CNN成为在图像识别分类的核心算法模型,带来了深度学习的大爆发。从此,深度学习吸引了学术界和工业界的关注,在不同领域内逐渐开始应用,不同的神经网络模型和架构也层出不穷,并取得了极好的效果。
图像分类之谜
我们用全连接神经网络进行图像分类的例子,来说明深度学习是如何工作的。比如在寄快递的时候,人们会写电话或者手机号码(均由数字0~9组成),如果我们能让电脑识别出人手写的数字是什么,就能够自动通知收件人来收取快递。
假设对图像进行扫描切割,每次都对包含一个数字的图像进行识别,可能是1,也可能是8,总共有0~9十个数字。若每个图片长、宽均为28个像素,并且是黑白图像,则该图片包含28×28=784个像素点,每个像素点范围在0和1之间,0表示白色,1表示黑色,0~1之间表示灰色。
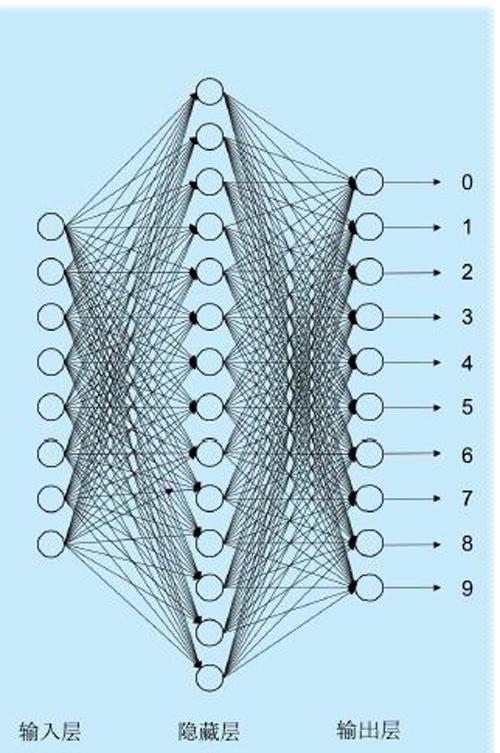

全連接的前馈神经网络(人工神经网络的一种)通常包括三层:输入层(input layer)、隐藏层(hidden layer)和输出层(output layer)。其中,输入层是接收原始输入;隐藏层可能有多层,每层隐藏层都对输入进行非线性运算,然后输出给下一层隐藏层,作为下一层隐藏层的输入继续运算,直到遇到输出层;输出层对隐藏层进行运算分类,得到最终的分类结果。每一层都包含了多个神经元(神经元是一个运算单元,执行最基本的运算操作),通常每个神经元对自己的输入进行非线性运算,并将结果传递给它连接到的所有下一层神经元。
具体到我们的图像分类任务中,输入层的输入是每幅图像,也就是784个像素点;中间是一个隐藏层,包含了15个神经元来进行非线性运算;输出层包含了10个神经元,对隐藏层的输出进行运算和分类,第n个神经元就代表这个图片是第n个数字的概率。例如,输出层第一个神经元的输出表示这个图像包含了数字0的概率,第5个神经元的输出表示该图像包含了数字4的概率。其中哪个神经元输出值最大,就作为模型预测到的结果。若输出概率如下表2所示,那么就认为图像包含数字为5,概率最大为0.6。


延伸阅读
图像由像素点组成,一般用长、宽所具有的像素点来描述图像,例如一张黑白图片长为900像素(即px),宽为700像素,则该图片共有900×700=630000个像素点。如果该图片是彩色图片,每个像素均由R、G、B三个分量组成,则该图像共有900×700×3=1890000个像素点。
AlphaGo的秘密:卷积神经网络
在卷积神经网络出现以前,人们使用全连接网络处理图像,但它存在一些问题,比如参数数量太多导致计算速度减慢、没有利用像素之间的位置信息、网络层数限制等。而卷积神经网络有效减少了这些问题,因此在图像处理上有非常突出的表现。
人观察图像时,往往会只关注局部信息,例如我们观察一张猫的照片,看到猫的额头或者猫爪就能够知道这是猫的照片了,而不需要每个部分都看完了才知道,因此图像的局部信息能够提供大量的有效特征。基于这个基本概念,卷积神经网络采用卷积层和池化层两种计算来提取相关信息。
卷积层采用一个小的矩阵窗口来对图像进行处理,例如长和宽均为3像素的矩阵,我们称之为过滤器或者内核。每次在图像中选择长为3像素、宽为3像素的区域,总共有3×3=9个像素点,然后进行按位乘法之后相加。在卷积完第一个局部信息之后,卷积核往右挪一位,然后继续进行该操作,继续往右挪动,直到挪动到了最右边;然后挪动到下一行,从左往右继续进行卷积操作,如右页上图所示。
右页上图中左边为图像信息,中间为卷积核矩阵,两者计算之后得到新的矩阵如图右边所示。大家可以手动计算一遍哦!
在卷积层之后,得到融合了局部信息的隐藏层,然后我们需要挑选最优的局部信息,一般采用最大池化(max-pooling)或者平均池化(average-pooling)来进行操作。假设我们采用最大池化操作,并且过滤器大小为2×2,那么对于一个5×5大小的矩阵我们最大池化之后得到4×4大小的矩阵,如右二图所示。例如蓝色部分中,包括四个点分别是0、1、1、2,那么最大的就取2;再比如红色部分中,包括四个點是1、3、1、0,那么取最大就是3。
池化操作与卷积操作类似,也是需要从左往右、从上往下进行移动,这样遍历完了整个卷积结果。随后池化的结果会往后传播,进行分类、识别等操作。采用多个卷积层+池化层的方式来提取特征,最后将提取到的特征“喂”给一个分类层进行图像识别,例如AlexNet就是采用了多层卷积神经网络来进行图像识别,并在ImageNet上取得了非常好的效果。
在AlphaGo中,卷积神经网络就起到了很大的作用,这款人工智能围棋程序由DeepMind公司开发,战胜了众多人类围棋高手,包括曾获世界围棋冠军的李世石和排名人类围棋世界第一的柯洁。
AlphaGo主要由卷积神经网络和蒙特卡洛树搜索组成。其中卷积神经网络如上介绍,对棋盘进行卷积运算,并采用蒙特卡洛树进行评估,得到当前应该下的棋的位置。通过机器和机器对弈的方法来创造足够多的棋局,在这个过程中,AlphaGo越来越强大,也就从丝毫不会下棋,成长到可以轻松战胜人类中最顶尖的棋者。
