深度迁移模型下的小样本声纹识别方法
2018-12-22孙存威贺建飚
孙存威,文 畅+,谢 凯,贺建飚
(1.长江大学 计算机科学学院,湖北 荆州 434023;2.长江大学 电子信息学院,湖北 荆州 434023;3.中南大学 信息科学与工程学院,湖南 长沙 410083)
0 引 言
声纹识别(又称“说话人识别”)是一种生物特征识别技术[1],它通过人特有的语音特征来识别说话人的身份。随着深度学习的出现,卷积神经网络(convolutional neural network,CNN)在语音识别领域得到广泛的应用。深度神经网络通过对大量语音数据的学习能够自动地学到多方面的声学特性(例如:共振峰、基音、倒频谱等),从而提高说话人识别的准确率。若仅用小样本的声纹数据训练,声纹识别的准确率并不理想。原因在于训练一个深度卷积神经网络需要足够的训练样本来学习数百万的网络参数[2]。
1 研究背景
目前语音识别分为传统的机器学习和深度学习,对于传统的机器学习,决定识别精度的重要因素在于特征选择。如今被广泛应用的特征有:线性预测倒谱系数[3]、Mel频率倒谱系数[4]、i-vector[5]。机器学习方法中主要有Gaussian mixture model[6]、HMM[7]、SVM[7],这些方法的缺点是提取的特征不具有多样性,而且不能保证提取的某一声纹特征的质量,导致识别的效果差。与传统的机器学习方法相比,深度卷积神经网络在语音识别领域取得很大成就。但是,在实际工作中,很难获得大量的声纹数据。
迁移学习是指将某个领域上学习的知识应用到不同的但相关的领域中[8],迁移学习正是利用大样本解决小样本问题的关键技术。在迁移过程中,不可避免源数据集和目标数据集之间的差异,导致声纹识别率低。
受限玻尔兹曼机[9]是由Hinton和Sejnowski提出的一种生成式随机神经网络,具备强大的无监督学习能力,能够从极大似然的角度快速学习输入声纹的高阶抽象特征。因此本文想通过利用RBM来解决声纹数据集间的差异性。此外,受Batch Normalization[10](简称BN)的启发,提出了FBN算法,可以在迁移学习的基础上利用小样本声纹训练使网络加速收敛。到目前为止,在小样本声纹识别领域,鲜有学者注意到迁移学习的重要意义。因此,我们提出了一种基于深度迁移混合模型的小样本声纹识别方法。
2 小样本说话人识别算法
小样本声纹去训练CNN模型时,由于声纹的数据量较小且声纹数据集之间存在差异,导致直接提取的声纹特征识别率很低。为提高小样本声纹识别性能,本文提出迁移预训练的改进CNN模型(加入快速批量归一化)。在此基础上,为了提高特征识别力,用RBM替换CNN网络的全连接层,该层不仅全连接卷积后的所有声纹特征图,还可以从特征图中进一步学习小样本特有的高阶声纹特征,从而提取更多的声纹特征,提高识别率。其算法流程如图1所示。

图1 基于深度迁移模型的小样本声纹识别流程
2.1 大样本声纹数据预训练卷积神经网络
2.1.1 数据预处理
在使用音频训练或测试模型之前,本文首先将音频分割成4 s音频段。在以快速傅里叶变换[11](FFT)进行处理之前,根据Nyquist-Shannon采样定理,本文以8000 Hz的帧速率对4 s音频段进行采样,在时域中会得到一个1×32000维的离散语音信号。FFT是将音频信号从时域转换为频域的有效方法,本文用它来使特征更加突出。由于FFT后得到的频谱的振幅是均匀对称的,本文取频率的正部分,于是得到一个1×16000维的离散频谱作为卷积神经网络的输入。
2.1.2 预训练改进的CNN网络
本文使用的CNN网络由两个卷积层和两个全连接层组成,在卷积层中融入FBN,位于激活函数之前,该模型用于处理1×16000维的声纹频谱。卷积层Conv1使用了3个1×3的卷积核滑动处理1×16000维的输入声纹频谱图像,滑动步长为1个像素。卷积层Conv2使用了3个3×3的卷积核处理Conv1输出的3个特征图,最后得到3个1×15996维的特征图,将特征图展开成一列之后通过全连接层来实现声纹分类。网络结构如图2所示。

图2 基于声纹识别的CNN网络结构
(1)前向传播调整网络参数
输入数据在各层神经元中的卷积如式(1)、式(2)所示,x(l)表示卷积层l,x(l+1)表示卷积层(l+1),W(l+1)表示层间权重、b(l+1)表示卷积层(l+1)的偏置,s(·)表示RELU激励函数
vector(l+1)=W(l+1)x(l)+b(l+1)
(1)
x(l+1)=s(FBN(vector(l+1)))
(2)
其中,FBN(·)为本文提出的FBN算法,具体方法如下所述:
设CNN网络模型的任一卷积层的输出包含t维,vector={e(1),e(2),…,e(t)},将归一化独立应用于每一个维度,下面以任一维度为例说明:在一个小批量数据样本中,数据样本容量为s,可表示为:Be={e1,e2,…,es},归一化后的样本数据为:Bg={g1,g2,…,gs},gi(i∈[1,s])服从N(0,1)分布。
小批量的均值为

(3)
样本方差为

(4)
归一化后的样本值为
(5)
更新全局平均值为
μB=(1-γ)*μB+γ*μ
(6)
更新全局方差为

(7)


(8)
(9)
(10)
(2)BP算法反向传播调整网络参数
对于含N个声纹的样本集x={(x(1),y(1)),…,(x(N),y(N))},网络输出层误差函数定义为
(11)


(12)

(13)
其中,ρ为学习率,Eτ为当前批次训练声纹样本数目为τ的误差。
2.2 模型迁移与二次改进
将预训练的CNN模型(融入快速批量归一化)迁移到小样本目标声纹数据集上。在此基础上,本文用RBM层和新的softmax层去替换预训练的CNN网络的全连接层,保留卷积层。在卷积Conv2之后输出3个1×15996维特征图,将3个特征图合并输入RBM层,R3层含3×15996个可视节点,含6000个隐藏节点,R4层含1000个隐藏节点,将得到的1000维向量输入softmax层中计算,找到概率最大所对应的声纹。基于迁移和二次改进的新网络如图3所示。

图3 基于迁移和二次改进的新模型
2.3 小样本声纹数据重训练卷积神经网络
2.3.1 小样本声纹重训练RBM层
RBM网络由若干可视节点和隐藏节点组成,对于∀ij,vi、hj∈{0,1},vi、hj分别表示可视节点和隐藏节点,0和1代表节点是否被激活。RBM可视节点和隐藏节点联合的能量可定义为
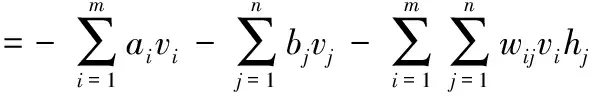
(14)
其中,θ=(wij,ai,bj),wij表示可视节点和隐藏节点之间的权重,ai表示可视节点的偏置,bj表示隐藏节点的偏置,m表示可视节点的个数,n表示隐藏节点的个数。由给定参数模型可得(v,h)的联合概率分布
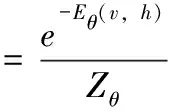
(15)

当RBM模型的参数确定时,第j个隐藏节点的激活概率可表示

(16)
第i个可视节点的激活概率可表示

(17)
由式(15)可得关于v的边缘分布

(18)
各参数的迭代公式可表示为

(19)

(20)

(21)
其中,λ表示预训练的学习率,L(θ)可表示
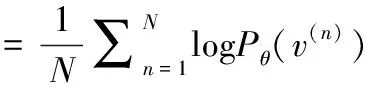
(22)
RBM中各网络参数更新如算法1所示。
算法1: RBM基于对比散度的快速学习
RBM快速学习算法
Input: RBM(w,a,b),可视层初始状态v1=x0
output: 参数a,b,w更新
fort= 1:T//最大训练周期T
forj= 1:n//对所有隐藏单元
P(h1j=1|v1)=sigmoid(bj+sum_i(v1i*wij))
EndFor
fori= 1:m//对所有可见单元
P(v2i=1|h1)=sigmoid(ai+sum_j(wij*h1j) //重构可视层
EndFor
forj= 1:n//对所有隐藏单元
P(h2j=1|v2)=sigmoid(bj+sum_j(v2i*wij)) //重构隐藏层
EndFor
w=w+alpha*(P(h1=1|v1)*v1-P(h2=1|v2)*v2)
a=a+alpha*(v1-v2) //学习速率alpha
b=b+alpha*(P(h1=1|v1) -P(h2=1|v2)) //参数更新
EndFor
2.3.2 新网络的自适应
为了使声纹识别模型适用于特定的识别任务,本文运用BP算法反向微调网络的权重和偏置。由于考虑到方差损失函数权重更新过慢。因此本文采用交叉熵代价函数[12],其优点:网络输出误差越大,权重更新越快。交叉熵代价函数定义为

(23)
其中,N为声纹训练样本数,y(i)表示输入数据的期望输出,y(i)∈{1,2,3…q},网络的权重w和偏置b的反向传播梯度的公式如下
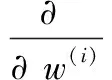
(24)

(25)
然后利用式(12)和式(13)调整网络各层的参数。
2.4 声纹识别结果
对于给定的输入数据x在第i类的概率Pi,Zi作为Softmax分类器的输入,在Softmax中运用式(26)计算得到max{P1,P2,…,Pq}所对应的说话人即为测试结果

(26)
3 实验设计与结果分析
3.1 实验运行平台与实验数据
本文实验的运行平台:操作系统为ubuntu1404,GPU为NVIDIA GEFORCE GTX 970,内存大小为16 GB。开发的应用由python3.5、深度学习框架tensorflow和跨平台界面软件Qt实现,基于本算法的说话人识别软件如图4所示。

图4 基于本算法的说话人识别软件界面
声纹识别软件Label_top显示输入待测声纹;Label_bottom显示与之匹配成功的人脸图像。TextBroswer_left显示声纹各种属性;TextBroswer_right显示标签信息。
本文实验采用在Kaldi平台上开源的178小时的中文普通话数据库(AISHELL-ASR0009-OS1)作为预训练的大样本声纹数据集,其中该数据库含400个来自中国不同区域的人,截取每个人大约350个4 s的wav格式语音片段。自采集语音库作为小样本声纹数据集,其中该语音库含20位来自中国不同区域的发音人,人均大约95个4 s的wav格式语音片段。
3.2 实验评估指标
本实验采用3种评价指标:声纹识别的准确率、Loss函数值和网络训练时间来验证算法的性能,声纹识别率的定义如下
(27)
其中,R表示声纹识别率,Nt表示测试总声纹的数目,Nr表示识别正确的声纹数目。
3.3 3种方案下的小样本声纹识别的比较
对于本文提出的说话人识别的方法,该实验先将AISHELL-ASR0009-OS1数据库作为预训练集训练融合快速批量归一化的CNN网络,预训练集的样本容量约为140 000。迁移模型后再从自采语音库选取20人的小目标声纹数据(人均50个语音片段)作为训练集(样本容量为1000)来验证下述第三种方案的有效性。从上述20人中任选10人(人均35个语音片段,样本容量为350)作为测试集,按以下3种方案做对比实验。
方案一:仅用小样本声纹数据去训练改进的CNN网络;
方案二:用大样本声纹数据预训练改进的CNN网络;之后迁移模型到目标集中,用小样本声纹数据微调迁移网络。
方案三:用大样本声纹数据预训练改进的CNN网络,迁移模型到小目标集中,将全连接层更换为两层RBM,再用小样本声纹数据重新微调新模型。
3种方案下的平均识别率见表1。
实验结果表明:方案三的平均识别率相对于方案一提高了41.3%,相对于方案二提高了9.7%。由此可得出本文所提出的第三种方案的识别性能显著高于其它两种方案。

表1 3种方案对小样本声纹识别率的比较
3.4 训练声纹样本容量对识别准确率的影响
上述3种实验方案被用于评估训练样本容量对说话人识别精度的影响,从自采语音库选取20人的小样本声纹数据(人均10、20、30、40、50、60个语音片段)作为训练集,从自采集语音库中任取10人(人均35个语音片段)作为测试集。不同训练样本数目下的识别准确率如图5所示。

图5 基于不同训练样本数目的说话人识别准确率
由实验结果可知:3种方案下的说话人识别准确率在一定程度上与训练样本容量成正相关。在不同训练样本容量下,方案三的识别率均高于方案二、方案一。
3.5 反向调整参数的次数对识别率的影响
本实验在上述3种方案下测试反向调整参数的次数对识别率产生的影响,如图6所示。

图6 不同BP调整次数下的声纹识别率
随着反向调整网络参数的次数增加,3种方案下的小样本声纹识别率均有提高,但是二次改进的迁移模型比单一迁移模型平均声纹识别率高10.1%,比未预训练的CNN模型平均声纹识别率高40.3%。
3.6 网络预训练时间的对比实验
在本实验中,采用AISHELL-ASR0009-OS1数据库预训练CNN网络,在相同的条件下,评估FBN算法在加速网络训练上的性能。设定网络的基础学习率为0.01,网络整体代价误差(Loss)为0.01。实验中做了3组对比实验:Conv+FC、Conv+BN+FC、Conv+FBN+FC(最优模型)。表2中实验结果是通过5次实验得到的平均值。

表2 比较3种模型下的预训练时间
3.7 网络收敛速度的对比实验
在本实验中,设置两组对比实验,比较在相同的训练集下,快速批量归一化对网络收敛速度的影响。用AISHELL-ASR0009-OS1语音库预训练CNN模型(加入FBN与未加入FBN),迁移模型之后,用20人的自采集语音库(人均50个语音片段,样本容量1000)重新训练新网络。在重训练过程中,根据Loss的误差值判断网络的收敛速度,实验结果如图7所示。

图7 两种模型收敛速度的比较
实验结果表明:训练两种方法下的模型时,在达到相同的Loss值时,加入FBN的模型所需时间明显比未加入FBN的模型少,从而验证了卷积过程中加入FBN会加速网络收敛。
3.8 实验分析
3.8.1 声纹识别率分析
在迁移预训练好的CNN模型时,将其全连接层改成两层玻尔兹曼机层,该层不仅全连接所有特征图,还能通过无监督训练进一步学习特征图的高阶抽象特征。除此之外,还通过使用交叉熵损失函数反向传播调整网络参数,使训练的神经网络自适应目标声纹集,从而提高了小样本说话人的识别率。
3.8.2 收敛速度和训练时间分析
BN能较好解决卷积神经网络中学习率低等问题并能优化网络训练速度。基于此更进一步的做了改进,FBN位于激活函数之前,其目的是将每个网络节点的输出归一化到零均值和单位方差,加速收敛。与BN不同的是,FBN省去了恢复操作,使得计算量降低、速度更快。
4 结束语
本文提出的一种深度迁移模型下的小样本声纹识别方法,用大样本声纹预训练CNN网络,在卷积的过程中引入快速批量归一化,加速了网络训练。此外,在迁移预训练模型时,将全连接层改为RBM,RBM不仅全连接卷积后的所有特征图,而且还能进一步提取声纹的高阶抽象特征,消除了数据集之间的差异性,提高了声纹识别率。本文还通过自适应的方法调整网络的权重和偏置,使声纹识别网络模型对小样本的目标声纹数据集具有良好的自适应性,为小样本说话人识别提供一种有效的方法。但对于复杂背景噪声等情况下,本文方法的声纹识别会有所影响,后续将会对这些复杂情况进行深入研究。
