基于特征降维和DBN的广告点击率预测
2018-12-22杨长春梅佳俊
杨长春,梅佳俊,吴 云,顾 寰
(常州大学 信息科学与工程学院,江苏 常州 213164)
0 引 言
点击率预测是搜索广告产业的核心技术,有效提升点击率的预测效果不但能满足广告主推销产品与服务的要求,还能增加广告媒介的利益,并且可以提升网络用户的满意度。由此可以看出广告点击率预测无疑是计算广告学中的一个至关重要的问题,而本文的探索意义也在于此[1]。
目前比较主流的广告点击率预测模型方向的探索主要使用的都是传统的机器学习中分类算法。朱志北等针对广告和用户数据量大并且数据稀疏的问题,提出了一种基于LDA的方法[2],该方法按照主题,将数据分割,再对分割后的数据集建立各自的预测模型,根据各个主题的概率,分配权重,从而得出最终的预测结果。针对传统方法利用单个权重衡量特征的影响力不够全面的问题,潘书敏等提出了基于用户相似度和特征分化的混合模型[3]。Jahrer等[4]提出了一种综合利用了特征工程,协同过滤和贝叶斯网络等多种模型的混合式点击率预测模型。岳昆等采用贝叶斯网的概率图预测没有历史记录的用户对广告的点击率[5]。Rendle利用因子分解对变量间的交互进行建模,提出了因子分解机模型[6],该模型适合处理大量的稀疏数据。Trofimov等建立了一个综合运用多个决策树来对点击率预测的梯度提升决策树模型[7],该模型具有运算时间少,无需大量训练数据的优点,但同时该模型并不支持较多的特征,所以可提升空间还很大。Lee等[8]通过数据分层的方法来解决数据稀疏的问题。
上述模型还都还是仅仅在探索广告特征间的线性关系,并没有充分挖掘更深层次的非线性关联。本文在将深度学习中的深度置信网络运用到广告点击率预测领域挖掘深层次的特征关联的同时,还考虑到广告数据中的ID类特征具有高维性,不适合深度学习方法,所以对特征进行了降维处理。
1 基于特征降维和DBN的预测模型
1.1 特征选取
特征提取是广告点击率预测的重要过程。本文针对广告数据中的特点,选择了几类特征,列举如下:
(1)ID类特征。本文中使用的ID类特征包括用户ID,查询ID,广告ID。本文将ID类特征进行one-hot编码。例如本文中测试数据集中共有23 669 284位用户,用户ID会被转为23 669 284维的特征,仅当某用户ID出现时该维会置为1,其余则为0。这样处理是因为ID类特征不应该被分类模型当做具体的值,而是标称类的特征来处理。但是这样产生的ID类特征会变成上亿维的特征向量,深度学习难以处理这样高维的特征。所以本文为了降低ID类特征的维度,会在下两节中对ID类特征进行降维。
(2)广告特征。本文所涉及的广告特征有广告位置position和返回页中的广告数depth。搜索的返回结果中广告的展示个数和广告所在的位置,对于点击率均有影响。
(3)用户特征。本文包含的用户特征主要有用户性别gender和用户年龄age。根据计算广告学中的以往经验,性别的不同会导致对广告的不同反应,例如,女生对化妆品类广告更有兴趣,而男生对体育,汽车类广告有更多的点击欲望。同理,处于不同年龄段的用户的兴趣点也会更倾向于某几类相对应的广告。
(4)历史反馈特征。本文使用的历史反馈特征有广告历史展示次数ad-view,广告历史点击次数ad-click,广告位置归一化后的点击率COEC。历史反馈特征可以很好地评价广告的质量,对于点击率预测也有较好的作用。
本文选取的特征库见表1。
1.2 K-means聚类
上节中提到由于ID类特征维数过高,不能直接作为深度置信网络的输入,需要进行处理。而通过对广告数据的梳理观察,可以发现用户,查询,广告等对象间有着非常复杂的关系。对于某一对象,比如广告,其内部的成员间具有相似关系。针对这些对象间的相互性,本文选择使用K-means聚类,将相似的对象聚类到一起,从而起到降维的作用。
本文将广告的聚类作为例子,展示算法的具体过程。
(1)以数据集中的广告展示次数为权重,建立一个广告-查询矩阵Mi×j,该矩阵包含i个广告,j个查询;

表1 本文选取的特征库
(2)使I=1,从i个广告中随机选取出K个当作初始的簇的中心Zp(I),p=1,2,3,…k;
(3)计算每个广告xi与各个簇的中心点Zp(I)的距离D(xi,Zp(I)),若广告xi与簇的中心点Zp(j)的距离最短,即D(xi,Zk(I))=min{D(xi,Zj(I)),i=1, 2, 3,…n},则将xi划分给第j类;
(4)将所有广告划分好后,再一次计算各个簇的聚类中心

(1)
(5)直到聚类中心再也不发生变化,则聚类完成,否则退回到第(3)步重新计算。
上文中的聚类算法完成了对广告的聚类,同样的,我们也可以基于同一矩阵对查询进行聚类。两次聚类都是在原始的矩阵上进行,相互独立,互不影响。由于用户,查询这两个对象之间也具有相似性,进行类似查询的用户之间是有相似性的,所以,可以根据查询的聚类结果将处于同一类查询的用户作为一组。
1.3 张量分解
张量也可以称作多维的矩阵,向量即为一维张量,而矩阵则为二维张量。矩阵分解其实是一种特殊的张量分解。N阶张量可以定义成A∈RI1×…×IN,张量所包含的元素则可以表示成ai 1 , … , i N。
将上文中通过聚类得到的数据用“用户-查询-广告-权重”的四元组关系{u,i,t,w}的形式表现,根据本文中使用的数据的特点,权重选择聚类后的广告展示次数的总和,并以此建立三维张量模型。得到的张量以A∈RI1×…×IN表示。
本文选用高阶奇异值分解法(HOSVD)对张量A分解。
公式表示如下
A=S×1U(1)×2U(2)×3U(3)
(2)
核心张量S∈RI1×I2×I3是一个与张量A维数相同的张量,将张量A在3个模式(1-模,2-模,3-模)下进行n-模展开,生成A1,A2,A3。对A1,A2,A3分别进行矩阵分解,结果表示如下
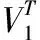
(3)

(4)

(5)
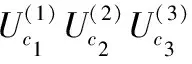
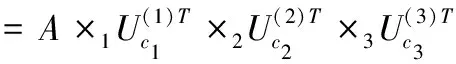
(6)
最后由近似核心张量和3个新的左奇异矩阵计算近似张量
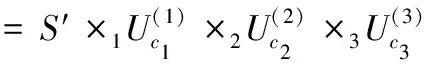
(7)
1.4 深度置信网络
本文选用深度置信网络来充分挖掘广告数据的特征之间的非线性关系,从而从低阶特征中获取高阶混合特征。
受限玻尔兹曼机(RBM):RBM是DBN的基本组成成分,它是具有一个显示层和一个隐藏层的两层结构,两层之间的节点进行全连接,层内节点无连接。RBM网络结构如图1所示,其中,v为显示层,用于输入数据,h为隐藏层,可以作为特征提取器,W为两层之间的权重矩阵,偏置量分为显示层的偏置量m和隐藏层的偏置量n。
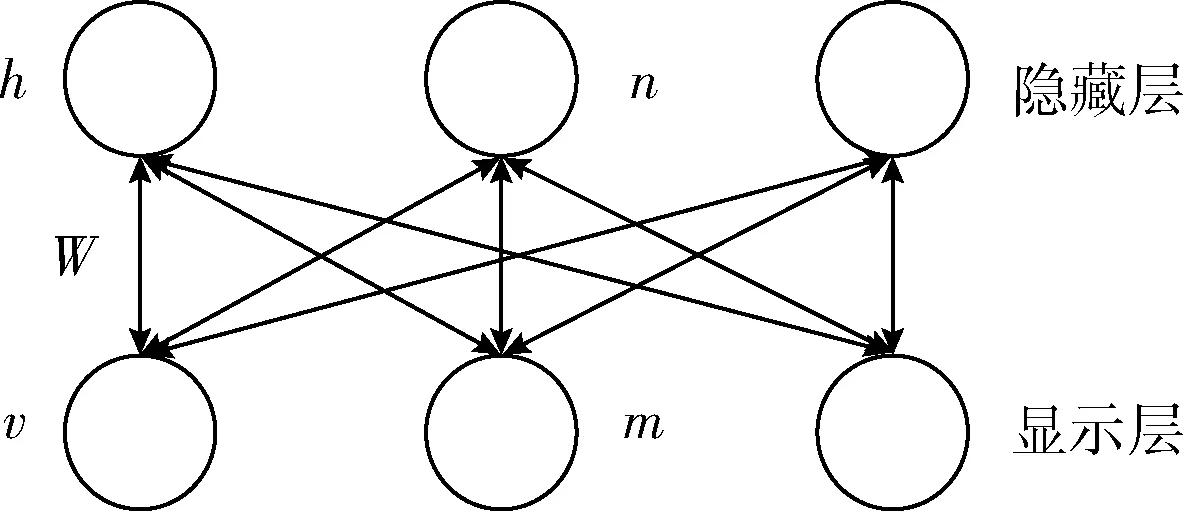
图1 RBM结构
RBM定义的能量函数为
E(v,h;θ)=-∑vmwnmhm-∑bmvn-∑cnhn
(8)
能量函数的具体定义参见文献[9]。
RBM采用对比散度(contrastice divergence,CD)算法进行训练,这是Hinton提出的一个RBM的快速学习算法[10],并提出了改进[11]。
深度置信网络(DBN):DBN是由数个RBM堆叠起来的网络结构,本文所用的深度置信网络是由数层RBM加上最后一层的BP网络所构成,BP层的激活函数选择sigmoid函数。本文的DBN训练采用贪心逐层非监督的学习方法,DBN的网络结构如图2所示,训练步骤分为模型预训练和参数微调两步。
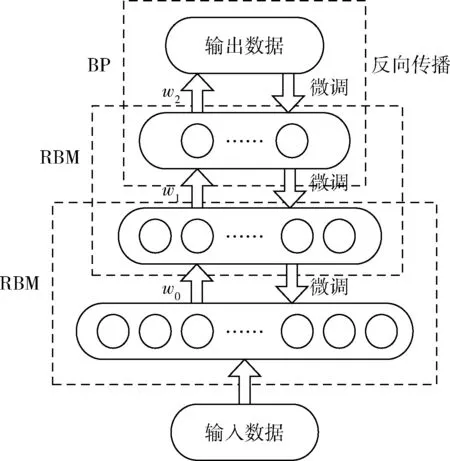
图2 DBN网络结构
预训练阶段:对于DBN的多层结构,将每相邻的两层作为一个RBM网络,使用处理好的特征作为输入层的输入,从最底层开始使用上节中的RBM无监督学习算法预训练每一个网络,每次只训练一层的网络参数,将其训练好的网络的输出作为下面一层RBM网络的输入,重复此步骤,将所有的RBM网络训练完。每层的RBM网络都会对输入的数据进行提取,抽象,挖掘更高层的特征,但是各层RBM网络训练的最好结果也仅仅是各层的网络参数达到最优,而并不能使整个网络达到最优,所以预训练完成后,本文使用有监督的BP网络将误差进行反向的传播,自顶向下微调整个模型。
参数微调阶段:最后一层的BP网络将充当模型有监督学习的分类器,对DBN模型的参数自顶向下进行微调。其训练过程共有两步:其一为前向传播,将输入信息送入第一层的RBM,经过几个RBM和BP层的计算,得出输出结果,其二为反向传播,计算输出结果和正确结果间的偏差,根据偏差从输出端向输入端反向传播,更新网络结构中的参数。
2 实 验
2.1 实验环境
硬件环境:中科曙光服务器一台,AMD Opteron(tm) Processor 6320@3.60 GHz 32核CPU,64 GB内存。
软件环境:Ubuntu 16.04操作系统,Anaconda 3 4.4.0开发环境以及TensorFlow工具包。
2.2 实验数据
本文使用KDD CUP2012比赛上track2任务的由腾讯的搜搜搜索引擎提供的广告点击日志作为实验数据。数据集包括9.8 G的训练数据集,1.2 G的测试数据集和243 M的测试数据的真实展示次数和点击数。训练数据集包含149 639 105行数据,测试数据则有20 217 594行数据。数据集中的一行数据代表的是某次检索中的返回页上的广告列表中的某一条广告的关于用户,查询,广告的所有信息。
2.3 实验评估方法
本文采用ROC曲线下面积AUC作为模型预测性能的评估方法。曲线下面积(AUC)就是ROC曲线下方的那部分面积大小,该值通常在[0.5,1)区间内,并且AUC值越大,表明模型性能越好。
2.4 实验结果与分析
实验一:隐藏层层数和节点数的确定
本文为了确定DBN模型对于广告数据最合适的隐藏层层数和节点数,选择在10万的数据集上,分别对不同层数和节点数的模型进行训练,然后比较在同一测试集上的AUC指标,见表2。从表2中可知,将模型层数从2层提高到3层,不论节点数怎么变化,预测效果都有了明显的提高,而当层数增加到4层,虽然预测效果还是比2层的模型有了提高,但是却并没有比3层提高多少,有些甚至比3层模型还差。5层与4层的模型表现类似。所以,本文选择3层作为DBN模型的隐藏层层数。而通过比较表中的3层模型的AUC值,本文选择将隐藏层的节点数自底向下分别设为50层,500层和100层。
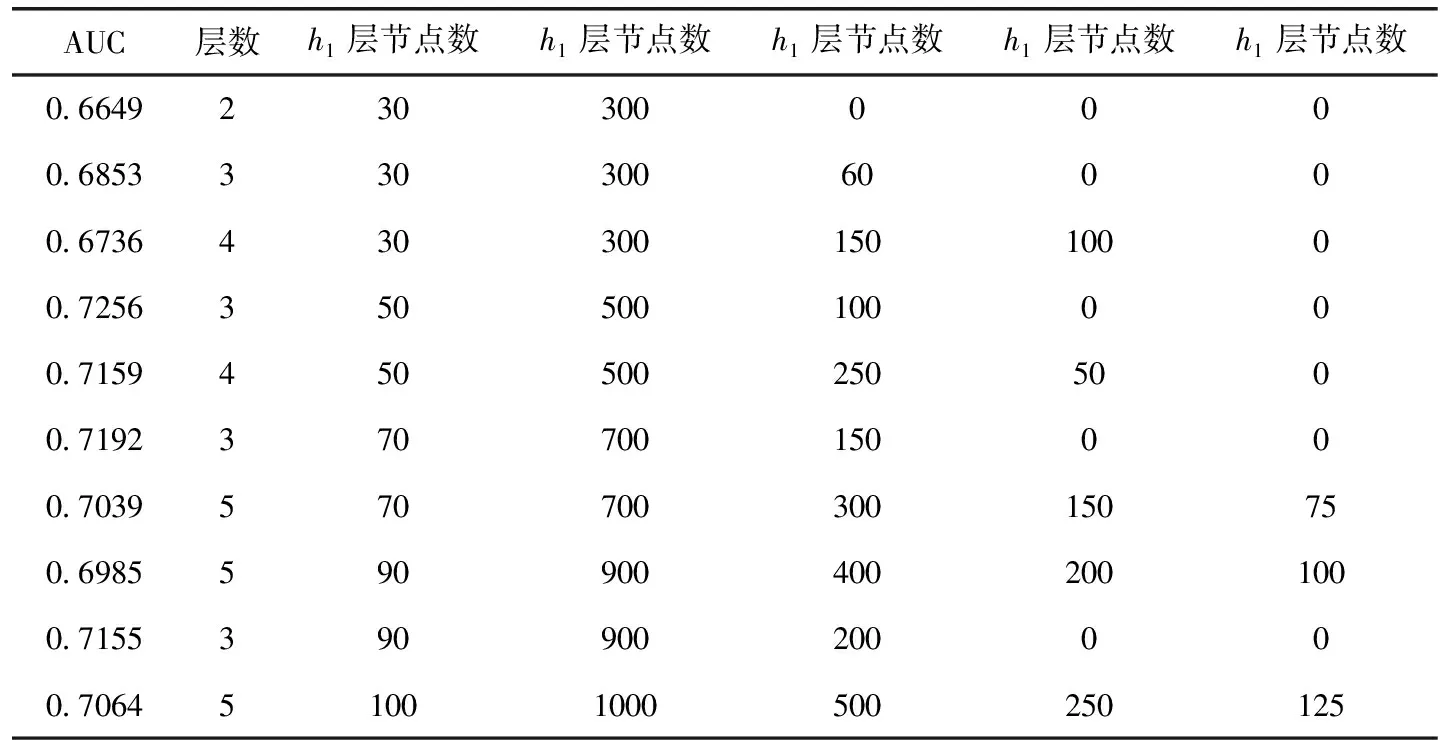
表2 不同隐藏层层数和节点数的深度置信网络模型的AUC值
实验二:预测效果的比较与分析
本文选择在5种数据规模的训练集上,并选用同一测试集对预测效果进行评价。既考虑了数据的规模对预测效果的影响,也比较了不同方法的预测效果。表3展示了不同模型在不同规模下的预测效果。在表中LR表示传统的逻辑回归模型,HPCM表示文献[12]中的矩阵分解和张量分解加EM算法的点击预测模型,KTDDBN表示本文的模型。

表3 3种模型在不同数据量下的预测结果
从表3可知,在不同数据量下3种模型的预测效果相比较,本文的KTDDBN模型要优于其它两种模型,并且当数据量逐渐增加,预测结果的提高也愈加明显,在数据量为10万时,相比于LR和HPCM模型,本文的模型分别只有0.0019和0.0009的提高,而随着数据量逐步增大,本文比其它模型的效果的提高愈加增加,当数据量提升到90万时,比其它两个模型的提高已经分别达到0.0614和0.0370。
为了更直观地看出不同数据量下3种模型的预测效果的变化趋势,图3展示了表3所对应的AUC折线图。

图3 3种模型在不同数据量时的预测结果对比
从图3中可知当数据量逐渐增大,各模型的预测性能均表现出上升的趋向,这表明随着训练数据的增大,各模型均得到了更充分的训练,获得更稳健的参数。然而,3种模型虽然在数据量增大时,预测效果均呈上升趋势,但他们变化趋势却不尽相同。刚开始,3种模型预测效果无太大差异,这说明此时,3种模型均处于过拟合状态,未得到充分训练。随着数据量逐渐增加,本文的KTDDBN模型的预测效果提升速度明显要优于其它两个模型。而当数据量达到50万之后,LR模型的预测效果已趋于平稳,HPCM模型也在数据量处于70万之后,预测效果不再有明显提升。相对的本文的KTDDBN模型在90万数据量之时仍有较明显的上升趋势。
3 结束语
本文针对广告数据中ID类特征的高维性,基于广告数据间的相似性,对其进行聚类,一定程度上降低其维度,再建立张量模型,获得低阶近似张量,并利用了广告数据的特征具有复杂的非线性关系的特点,引入了深度学习中的深度置信网络,对其深层特征组合进行学习。实验结果表明,本文模型的预测结果相比其它方法有一定的提高。然而,本文的模型虽有改进,但尚有不足,所以下一步的研究方向是如何在保证预测效果的同时,减小计算开销。
