基于任务聚类的IABC云计算资源调度方法
2018-12-22张曦煌
郑 洲,张曦煌,张 伟
(1.无锡工艺职业技术学院 信息中心,江苏 无锡 214206;2.江南大学 物联网学院,江苏 无锡 214122)
0 引 言
云计算是全球信息通讯技术行业公认的发展核心,随着技术的发展,云服务慢慢发展成为“自来水”式的服务,个人或企业无需关心计算存储资源从何而来,只需按需付费,就可以获得想要的数据存储处理资源[1]。但是云资源的有限性和云计算需求的快速增长是当前云计算急需解决的问题,云资源不同的分配调度方法,使云服务的质量也大相径庭,因此挖掘更优的云资源调度方法,对于提高云服务质量、提高用户云服务体验具有重要意义。
云计算资源调度是一个NP完全问题。Hadoop平台的资源调度方法有先进先出调度方法、公平份额调度方法[2]、计算能力调度方法。传统的调度方法有Min-Min算法、Max-Min算法、Sufferage算法、HEFT算法等。当前研究的热点是基于群智能算法的调度方法,文献[3]基于混沌扰乱策略提出了自适应蚁群算法,应用于云计算资源调度时收敛速度快、搜索能力强;文献[4]融合了粒子群算法和蚁群算法用于云计算资源调度,使用粒子群算法的最优解用于初始化蚁群算法,克服了蚁群算法收敛速度慢的问题;文献[5]提出了改进人工蜂群算法,成功避免了算法“早熟”问题,此方法可以缩短任务平均执行时间,但是当前对云计算资源调度的优化目标较单一,且对云计算资源调度的优化方法仅仅局限于对算法的优化。
本文从两个方面改进了人工蜂群算法,一是改进了跟随蜂蜜源选择概率,二是改进了雇佣蜂蜜源搜索策略,此改进方法在偏好的优化目标上均具有最优表现;提出了任务聚类方法,将任务分为计算型、通信型、存储型3类,从而有针对性地分配虚拟资源,此方法在任务完成时间和资源利用率上优势明显,且任务量越大优势越明显。
1 云计算资源调度问题建模
1.1 云计算任务模型
从实际情况来讲,任务之间是具有时序关系的,某一任务执行完毕之后才能执行另一任务。为了直观表达任务之间的时序约束关系,本文使用有向无循环图(direct acyclic graph,DAG)建立任务模型,如图1所示。
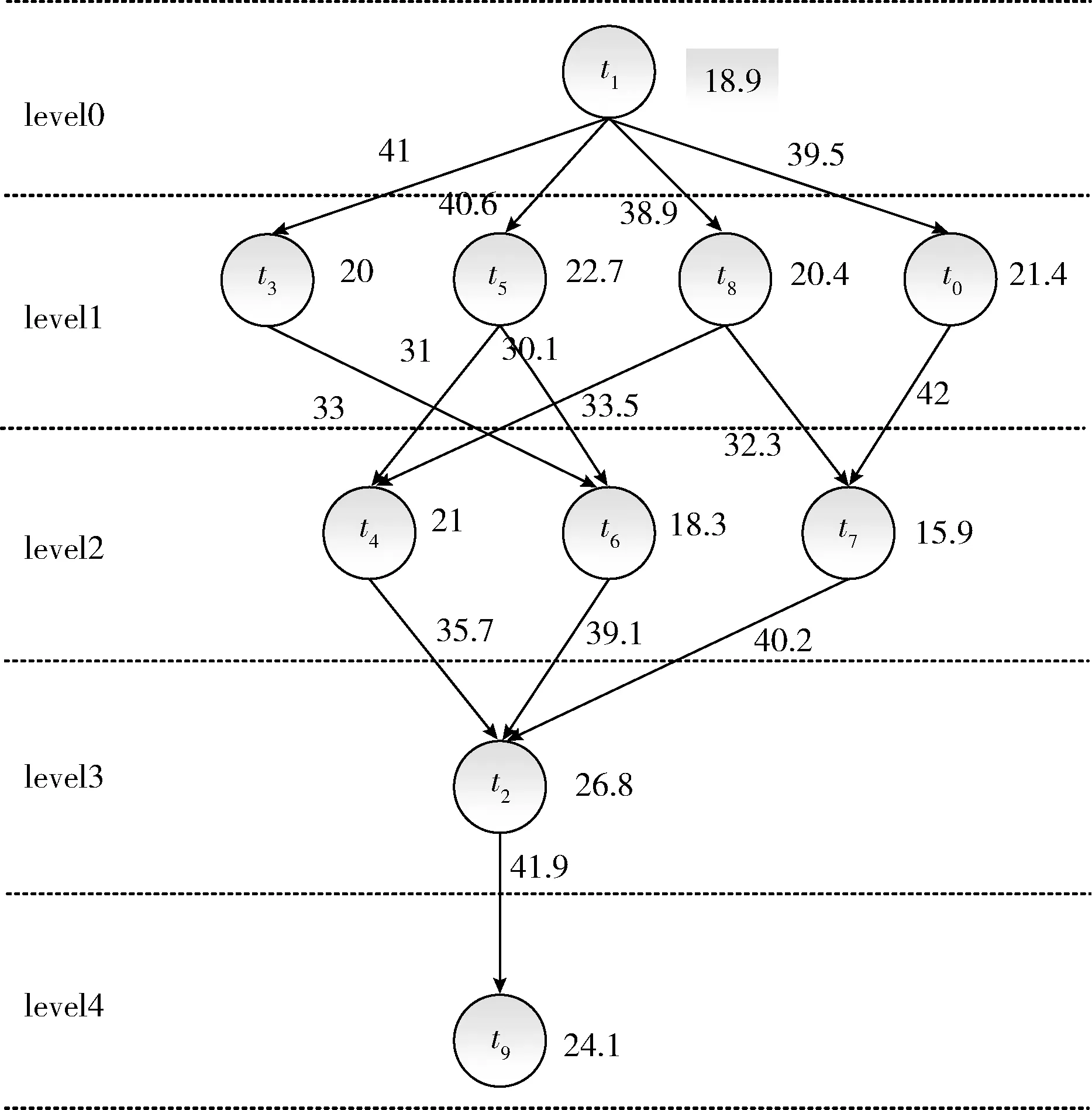
图1 任务的DAG模型
图1中任务t1为起始节点,任务t9为结束节点。对DAG模型定义两个集合,分别为集合T和E,T为所有任务的集合,E为任务ti与tj之间边eij的集合,eij表示任务ti与tj之间存在时序关系,任务ti执行完毕后才能执行任务tj。
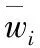
1.2 云计算资源模型
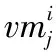
1.3 云计算约束模型
本文考虑费用约束、完成时间约束、可靠性约束等3个方面的约束条件。
费用约束就是完成任务产生的费用不能高于用户的费用要求。假设任务ti分配到了虚拟机资源vmki上,费用约束即为

(1)
式中:S.C为完成所有任务的费用,n为任务数量,U.C为用户给出的费用上限。
完成时间约束就是所有任务最终的完成时间不能超过用户给定的截止时间。即对∀ti,有

(2)
式中:S.T为完成所有任务的时间,U.T为用户给出的任务完成截止时间。
可靠性约束就是所有任务使用的虚拟机可靠性要大于等于用户的可靠性要求,即
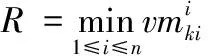
(3)
式中:S.R为所有虚拟机的可靠性最小值,U.R为用户给出的可靠性值。
1.4 云计算服务质量模型
本文资源调度的优化目标包括费用、完成时间、可靠性等3个方面,因此服务质量模型需要分别建立费用、完成时间、可靠性的适应度函数。
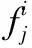
(4)
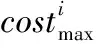
(2)完成时间适应度函数的建立。将任务ti的最早开始时间记为EST(ti,vmj),则EST(ti,vmj)
EST(ti,vmj)=maxavail(vmj),EFT(tk)+cki
(5)


(6)

(4)服务质量模型的建立。根据以上分析,使用传统的加权方式将多个优化目标综合为一个优化目标,即
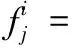
(7)
式中:α、β、γ分别为权值系数,其值的大小反应优化目标的偏好,那么通过调整权值就可以改变优化中心。要求0≤α,β,γ≤1,且α+β+γ=1。
2 改进人工蜂群算法的任务调度
人工蜂群算法是模拟蜂群采蜜行为的群体智能算法,每个蜜源位置代表一个可行解,蜂群找到最优蜜源的速度代表算法的收敛速度,蜂群寻找最优蜜源的过程就是算法寻优的过程[6]。
2.1 人工蜂群算法原理
在人工蜂群算法中使用到的参数包括种群数量SN、算法最大迭代次数MaxCycle、蜜源停留最大次数Limit。
(1)初始化蜜源,随机生成N个蜜源[7],每个蜜源记为xi=(xi1,xi2,…,xid),d为任务的数量,xij表示第j个任务在虚拟机xij上执行。蜜源初始化为
xij=lbj+rand(0,1)(ubj-lbj)
(8)
式中:i=1,2,…,N,ubj、lbj分别为可行域维度j上的最大值和最小值,rand(0,1)为(0,1)间的随机数。若xij为非整数,则通过取整转化为整数。
(2)对蜜源收益度进行评价,评价函数为
(9)
式中:fi为优化问题的目标函数。
(3)雇佣蜂进行邻域搜索。每只雇佣蜂在原蜜源附近搜索新蜜源,比较新蜜源和原蜜源的适应度值,保留适应度大的蜜源。蜜源搜索方式为
Vij=xij+rij(xij-xkj)
(10)
式中:Vij为雇佣蜂搜寻到的新食物源,xij为当前食物源,xkj为随机选取的异于当前食物源的另一食物源,rij为[-1,1]的随机数。
(4)跟随蜂的蜜源选择。雇佣蜂选择蜜源后通过摇摆舞将信息传递给跟随蜂,跟随蜂依据各蜜源适应度值选择蜜源,即
(11)
式中:pi为跟随蜂选择某一蜜源的概率。跟随蜂进行蜜源选择后变为雇佣蜂。
(5)侦查蜂搜索策略。若雇佣蜂在某蜜源邻域搜索次数超过Limit次,则放弃此处,雇佣蜂转换为侦查蜂,按照式(8)产生新蜜源弥补放弃的蜜源。这样可以使人工蜂群算法跳出局部极值。
2.2 改进人工蜂群算法(IABC)
2.2.1 改进跟随蜂蜜源选择概率
在传统的人工蜂群算法中,跟随蜂的蜜源选择依据轮盘赌方式进行,这种方式能够引导跟随蜂快速收敛于较优解,增加了在较优解附近的细致搜索,但是即使最差解也有被选择的可能,这样就造成了跟随蜂资源的浪费,产生了一些极差解附近的无效搜索。为了解决这一问题,本文对跟随蜂的蜜源选择概率进行改进,即
(12)
式中:fitmin为所有蜜源适应度最小值。从上式可以看出,跟随蜂的蜜源选择概率引入了适应度最小值,选择概率正比于适应度跨度,极大地减小了跟随蜂选择“劣质解”的概率,使更多的跟随蜂能够选择较优解,产生有效搜索。
2.2.2 改进蜜源搜索策略
在传统的人工蜂群算法中,雇佣蜂的蜜源搜索策略为式(10),这种搜索策略具有很强的随机性和盲目性。本文对雇佣蜂的搜索策略提出改进,前期使雇佣蜂具有很大的搜索范围,后期使雇佣蜂快速收敛至最优解,提高收敛速度,即
(13)
其中
(14)
式中:Vij为雇佣蜂搜寻到的新食物源,xij为当前食物源,xkj为随机选取的异于当前食物源的另一食物源,rij为[-1,1]的随机数,c∈[cmin,cmax]为学习因子,xbest为当前最优食物源,fitbest为当前最优食物源适应度,fitgoal为目标适应度。上式表示,当最优适应度值为目标值的95%之前,使用随机搜索方式,且学习因子较大,实现了算法的大范围搜索,随着迭代次数Cycle增大,学习因子逐渐减小,有利于较优解附近的细致搜索,当适应度值增加大95%目标值时,算法开始向全局最优解xbest靠近,增加收敛速度。
2.3 改进人工蜂群算法的任务调度
首先介绍任务初始化的方法,而后给出基于改进人工蜂群算法的任务调度步骤。
任务的初始化包括任务的分组和组内的优先级排序。任务的分组就是根据DAG图,将没有依赖关系的任务分为一组,便于任务的并行执行。如图1所示将10个任务分为了5组。组内任务的优先级排序依据下式给出
(15)
式中:rank(ti)为任务ti的优先级,tj为ti的直接后继节点,Succ(ti)为任务ti所有直接后继节点的集合。分析式(15)可以看出,计算任务优先级从最后一个组开始,逐渐计算至第一组。
使用改进人工蜂群算法对计算资源进行调度的步骤为:
步骤1 初始化参数。给出虚拟机的运行价格、可靠性;人工蜂群算法最大迭代次数Maxcycle、蜂群规模SN,食物源最大停留次数Limit;
步骤2 初始化任务。就是将任务进行分组和优先级排序;
步骤3 初始化蜜源。根据式(8)对蜜源进行初始化;
步骤4 雇佣蜂的蜜源搜索。雇佣蜂使用改进的搜索方式,前期进行大范围搜索,后期快速收敛至最优解;
步骤5 跟随蜂的蜜源选择。使用改进的选择方法,增加跟随蜂对优质解的选择概率;
步骤6 侦查蜂搜索策略。在某一蜜源附近搜索次数超过Limit次而没有更新时则放弃此蜜源,随机生成一蜜源进行补充;
步骤7 达到搜索精度要求或者达到最大搜索次数时,算法结束,输出最优解。
3 基于任务聚类的IABC调度方法
当前对云计算资源的调度策略研究主要集中在对调度算法的优化上,而对云任务缺少足够的分析。本文使用模糊C均值聚类方法对任务进行预处理,对具有相似资源需求的任务进行聚类,从而有针对性地分配云资源。
3.1 任务聚类方法
本文将任务分为计算型、带宽通信型、存储型任务3类,因此选择任务的计算量需求tcomp、任务期望带宽tbw、任务期望存储空间tstor作为任务的特征向量T=(tcomp,tbw,tstor),其中计算量需求为tcimp=tlength/tPE,tlength为任务长度,tPE为任务期望的PE数量。

对任务的特征向量归一化处理后,使用模糊C均值聚类方法[8,9]对任务进行分类,将任务分为计算型、带宽通信型、存储型任务3类,然后根据任务分类有针对性地进行资源调度,模糊C均值聚类原理简单,这里不再赘述。
3.2 虚拟机评价方法
对任务聚类后,为了有针对性地分配虚拟资源,也需要给出虚拟资源的评价方法。与任务的分配类型相对应,需要对虚拟资源的计算能力、带宽通信能力、存储能力进行评价,即第j个虚拟资源的特征向量为vmj=(vmjcomp,vmjbw,vmjstor),以计算能力为例给出评价公式,另外两个属性与计算能力的评价公式一致,即
(16)

3.3 基于任务聚类的IABC调度步骤
对任务进行分类、虚拟机资源进行评价后,使用改进人工蜂群算法进行针对性的资源分配,其步骤为:
步骤1 初始化参数。给出虚拟机的运行价格、可靠性;人工蜂群算法最大迭代次数Maxcycle、蜂群规模SN,食物源最大停留次数Limit;
步骤2 初始化任务。就是将任务进行分组、优先级排序、聚类,将任务分为计算性、通信型、存储型3类;
步骤3 初始化蜜源。根据式(8)对蜜源进行初始化;
步骤4 雇佣蜂的蜜源搜索。雇佣蜂使用改进的搜索方式,前期进行大范围搜索,后期快速收敛至最优解;
步骤5 跟随蜂的蜜源选择。使用改进的选择方法,增加跟随蜂对优质解的选择概率;
步骤6 侦查蜂搜索策略。在某一蜜源附近搜索次数超过Limit次而没有更新时则放弃此蜜源,随机生成一蜜源进行补充;
步骤7 达到搜索精度要求或者达到最大搜索次数时,算法结束,输出最优解,否则转至步骤4。
4 仿真实验验证
4.1 实验设计
使用CloudSim云计算平台仿真模拟器作为实验平台,在jdk7.0和eclipse环境编程,增加了DAG生成模块作为扩展。本文的创新点包括两大方面,一是改进了人工蜂群算法,二是提出了基于任务聚类的调度方法,因此验证实验分为两个实验。
实验二:验证任务聚类在资源调度中的作用。任务参数设置为:任务长度在[500,4000]范文内取值,带宽取值范围为[1000,4000],任务期望存储空间取值范围为[500,3000],输入输出数据量范围为[10000,50000]。虚拟资源参数设置为:虚拟机CPU数量在{1,2,3,4}中选取,处理速度范围为[500,1000],带宽范围为[500,3000],存储空间取值范围为[512,2048]。实验分两组进行,一是任务量较少时,将聚类IABC调度结果与无聚类IABC算法、Min-Min算法、K-Min算法调度结果进行比较;二是任务量较多时,上述算法的调度结果对比。
4.2 实验结果及分析
实验一:分别使用异构最早完成时间算法(HEFT)、传统人工蜂群算法(ABC)、优秀种群引导的人工蜂群算法(GABC)、NIABC算法[10]及本文的改进算法进行资源调度,比较资源调度性能。偏好于花费的调度结果如图2所示。
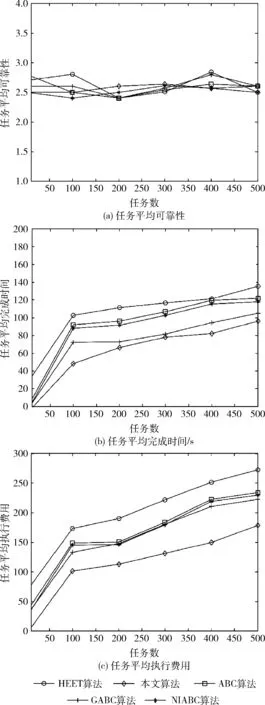
图2 偏好执行费用时各算法调度结果
从图2中可以看出,本文提出的改进人工蜂群算法在平均完成时间和平均执行费用上均少于其它算法,这是因为改进了跟随蜂蜜源选择策略,增加了优质解被选择概率,改进了雇佣蜂蜜源搜索策略,兼顾了算法前期的大范围搜索和后期向最优解收敛,这样极大地节约了任务完成时间。另外由于在参数设置时偏好于执行费用,所以资源调度时选择费用较低的虚拟机,但是费用低的虚拟机一般可靠性较差,所以改进人工蜂群算法在平均可靠性上没有优势。
偏好于完成时间的调度结果如图3所示。

图3 偏好完成时间时各算法调度结果
从图3中可以看出,本文提出的改进人工蜂群算法相比于其它算法在平均完成时间和平均执行费用上具有优势。因为偏好于任务完成时间,所以会挑选执行速度快的虚拟机,但是处理能力强的虚拟机未必可靠性就高,其随机性较大,因此改进人工蜂群算法在平均可靠性上没有优势。
偏好于可靠性的调度结果如图4所示。

图4 偏好可靠性时各算法调度结果
从图3中可以看出本文提出的改进人工蜂群算法具有最高的平均可靠性,但是由于偏好于可靠性,使得任务等待可靠性高的虚拟机执行,使任务完成时间增加,所以本文改进算法在完成时间上不再具有优势;而且虚拟资源可靠性和价格成正相关关系,所以高可靠性导致了高花费,所以改进算法的花费也最高。
分析以上3个实验,可以看出本文提出的改进算法在偏好方面均能取得最优解,且优势明显,所以根据任务实际调整优化参数,就可以调整优化中心,实现不同目标优化问题。
实验二:任务量较少时,任务量取为10-150递增,相应地虚拟机数量由3-20递增,使用聚类IABC算法、无聚类IABC算法、Min-Min算法、K-Min算法进行多次资源调度,统计运行结果的平均值,结果如图5所示。
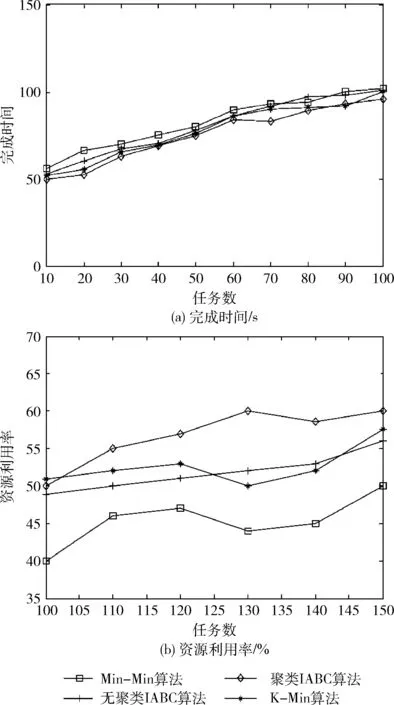
图5 任务较少时的调度结果
从图5(a)中可以看出,本文的聚类IABC算法相比于其它算法在完成时间上具有优势,但是这种优势非常不明显,这是由于任务量过少,改进人工蜂群算法的快速搜索能力未能完全表现,而且任务聚类也会消耗一些时间,使优势更加不明显。从图5(b)中可以看出,聚类IABC算法的资源利用率最高,且非常稳定,相比于其它算法优势明显。
任务量较多时,任务量由100-1000递增,相应地虚拟机数量由8-50递增,使用聚类IABC算法、无聚类IABC算法、Min-Min算法、K-Min算法进行多次资源调度,统计运行结果的平均值,结果如图6所示。

图6 任务多时的调度结果
从图6(a)中可以看出,本文的聚类IABC算法相比于其它调度方法在完成时间上优势明显,而且随着任务量的增加这种优势愈加明显,这是因为任务聚类和虚拟资源评价,使虚拟资源相对于任务分配时更具有针对性,使计算型、通信型、存储型资源能够相应分配到计算型、通信型、存储型任务上;从图6(b)可以看出,本文的聚类IABC算法调度的资源利用率最高,充分使用了虚拟资源,能够减少虚拟资源的占有。
5 结束语
本文在提出改进人工蜂群算法的基础上,提出了基于任务聚类的改进人工蜂群资源调度方法,具体地讲,本文完成了以下工作:
(1)改进了跟随蜂蜜源选择概率,增大了优质解被选择的概率,从而增加了在优质解附近的“有效搜索”概率;
(2)改进了雇佣蜂的蜜源选择策略,使算法前期大范围搜索,达到一定精度后快速收敛至最优解附近,兼顾了搜索范围和收敛速度;
(3)经仿真实验验证,改进人工蜂群算法在所“偏好”方面均取得最优解,所有只需要调整优化重心,就可以使用本文的改进方法进行不同方面的优化;
(4)在改进人工蜂群算法基础上增加了任务聚类算法,通过对任务进行聚类,将任务分为不同类型,使得在资源分配时具有很强的针对性;
(5)经仿真验证,在任务量较大和较少时,聚类IABC算法在完成时间和资源利用率上均具有优势,但是任务量较少时优势不明显,而任务量较大时优势明显,且任务量越大优势越明显。
