基于图像矢量的恶意代码分类模型*
2018-12-19蒋永康邹福泰
蒋永康,吴 越,邹福泰
(上海交通大学 网络空间安全学院,上海 200240)
0 引 言
如今,随着多态、变异和反分析技术的发展,恶意软件在数量和质量上都呈现爆发性增长。文献[1]提到,海量数据的恶意性检测任务正逐渐成为当下反病毒引擎的主要挑战之一。文献[2]表明,尽管攻击者开发移动平台恶意软件的兴趣与日俱增,但windows依然是被攻击的主要平台。2017年第一季度检测到的4.8千万个恶意样本中,来自windows平台的占到77.2%。这表明传统的基于特征匹配和行为分析的恶意代码分析技术已经很难满足海量样本的恶意检测任务。如何实现大规模数据的高效分析,已经成为恶意代码研究的主要课题之一。
因此,本文主要研究基于图像矢量的恶意代码分类模型在大规模PE(Portable Executable)格式恶意代码分类任务中的应用和效果。第1章介绍恶意代码的矢量化技术;第2章介绍构建的深度学习模型;第3章给出模型在微软数据集上的实验结果;第4章分析模型的意义,给出进一步的研究方向。
1 恶意代码矢量化
恶意代码矢量化是一种将恶意代码样本映射为图像矢量的编码技术。恶意代码矢量化的最终目标是用一张全局唯一的图像矢量来表征恶意代码,从而将恶意代码的检测问题转化为图像的分类问题。恶意代码矢量化的核心在于编码源、编码长度和编码量的选择。
1.1 Nataraj矢量化
2011年,Nataraj[3]提出了基于二进制文件的恶意代码矢量化方法。Nataraj矢量化选择恶意代码二进制文件作为编码源,将8-bit二进制映射为8-bit整型数值。通常来说,编码量为整个PE文件或者PE文件中包含可执行代码的.text节。图1为Nataraj矢量化的具体步骤。
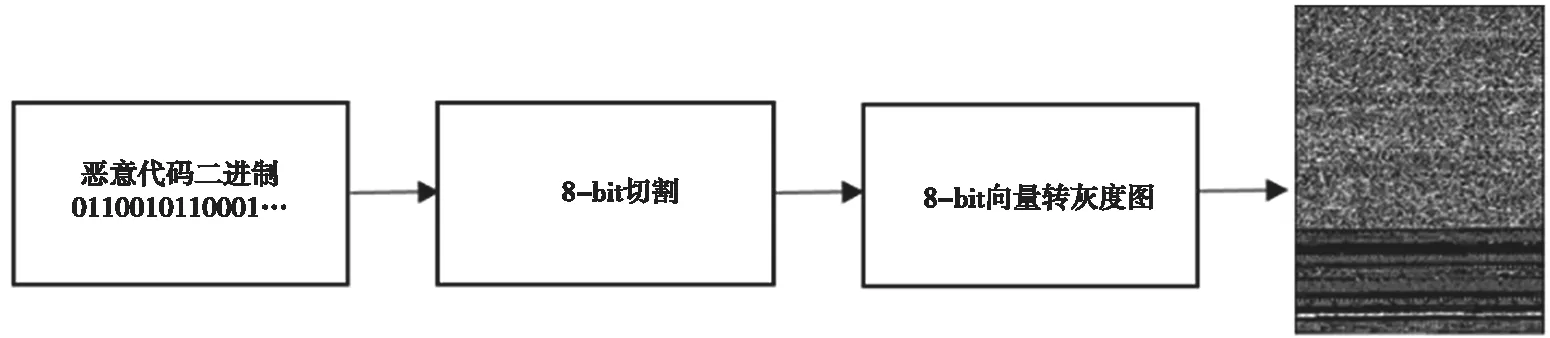
图1 Nataraj矢量化编码方法
Nataraj矢量化是恶意代码分析技术的一种新思路,打开了基于图像矢量的恶意代码分析的大门。文献[4-6]中构建的恶意代码分析模型都将Nataraj矢量化作为重要的输入特征。然而,加壳和混淆技术能使恶意代码的二进制文件发生显著变化,直接导致输出的图像矢量产生巨大差异,使得Nataraj矢量化面对加壳和混淆技术时鲁棒性很差。同时,文献[4]也表明,在Nataraj矢量化下,不同恶意代码家族的图像矢量也有可能十分相似。因此,Nataraj矢量化对于攻击者来说十分脆弱。
1.2 Andrew矢量化
2015年的黑帽大会上,Andrew[7]提出了另一种基于反汇编文件的恶意代码矢量化思路。Andrew矢量化选取反汇编十六进制机器码作为编码源,将4-bit的十六进制机器码映射成4×8-bit的整数值,再进行填充。如图2所示,Andrew矢量化具有很好的视觉可解释性,图像矢量的每一行对应一条机器码。
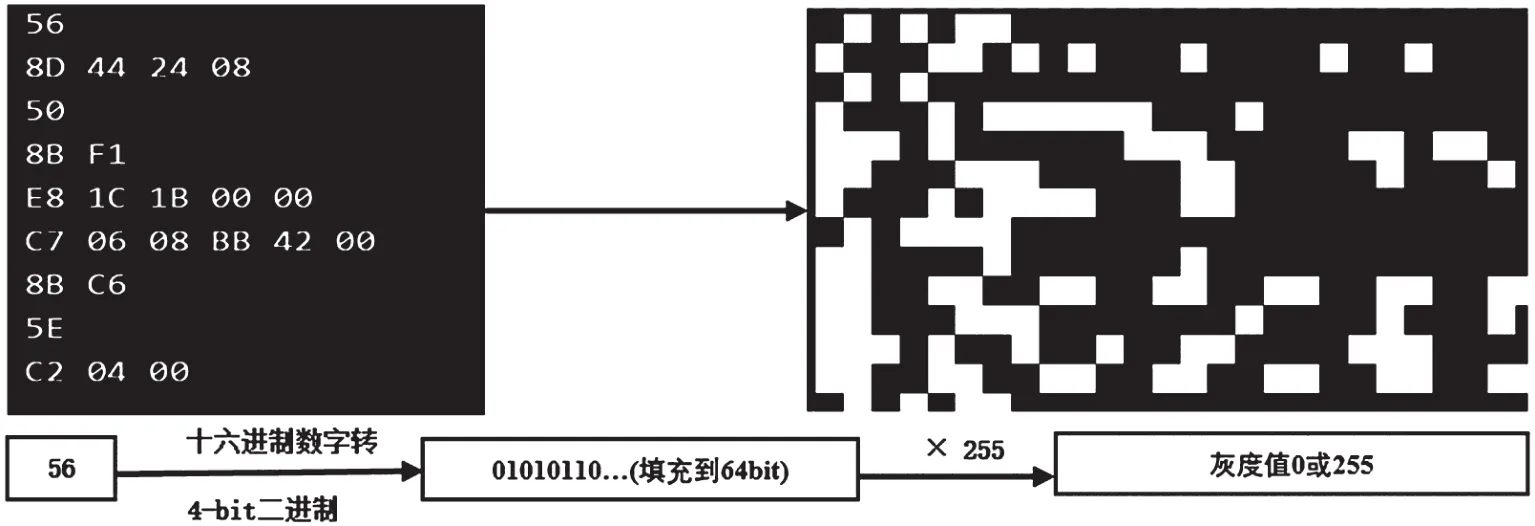
图2 Andrew矢量化编码方法
Andrew矢量化不仅编码了恶意代码的机器码信息,还通过填充保留了汇编指令的空间信息。因此,Andrew矢量化对于加壳和混淆技术具有较好的鲁棒性。遗憾的是,Andrew并没有给出详细的分析和具体的深度学习模型。因此,本文将详细阐述Andrew矢量化中编码长度、编码量选择问题,并给出具体的深度学习模型。
1.3 64-bit矢量填充
Andrew矢量化中的一个关键问题在于,为什么选择64-bit矢量填充。
一方面,如图3所示的Intel 64和IA-32架构指令编码格式[8]规定指令的最大长度为15 Bytes。更一般地,指令长度不会超过11 Bytes。

图3 Intel 64和IA-32架构指令格式
另一方面,通过对微软恶意代码数据集(BIG2015)[9]的研究发现,99%的恶意样本的指令长度都不超过64 bit,结果如图4所示。
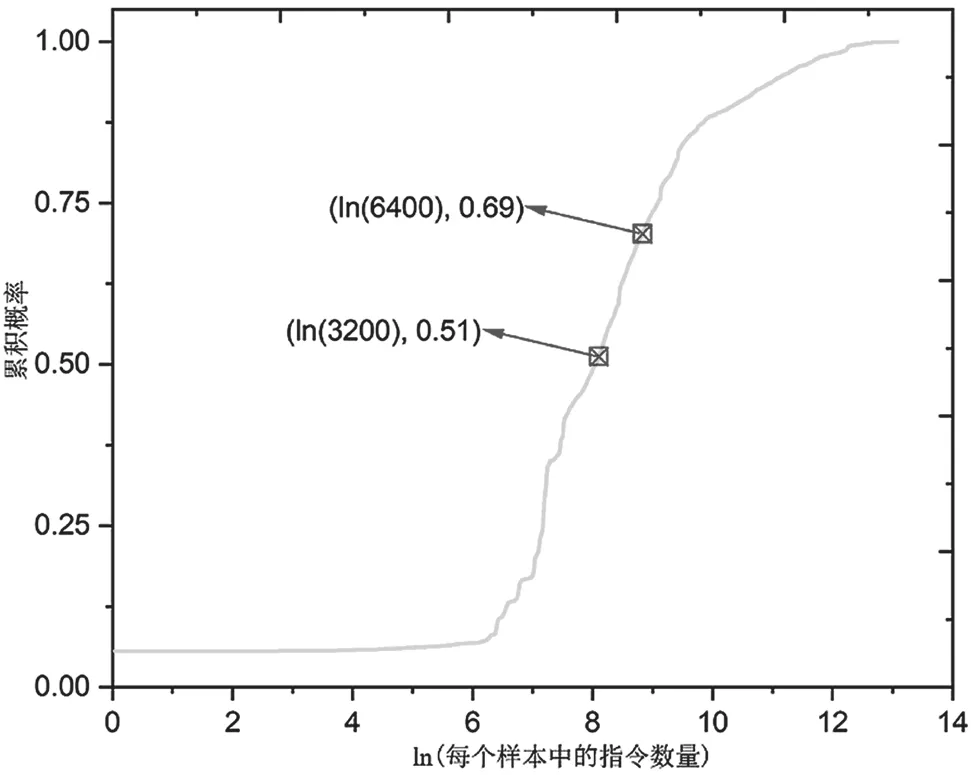
图4 BIG2015指令长度累积概率分布
因此,Andrew矢量化选择64-bit矢量填充,以最大程度地保留恶意代码的指令信息。
1.4 编码量的选择
为了加速矢量化过程和深度学习网络的训练时间,需要在保证模型准确率的前提下,选择一个合适的、较小的编码量。
研究BIG2015时发现,不同恶意代码反汇编文件包含的指令数量差异很大,如图5所示,51%的样本包含的指令少于3 200条。结合深度学习中图片大小的选择经验,3 200是一个合理的编码指令数量。
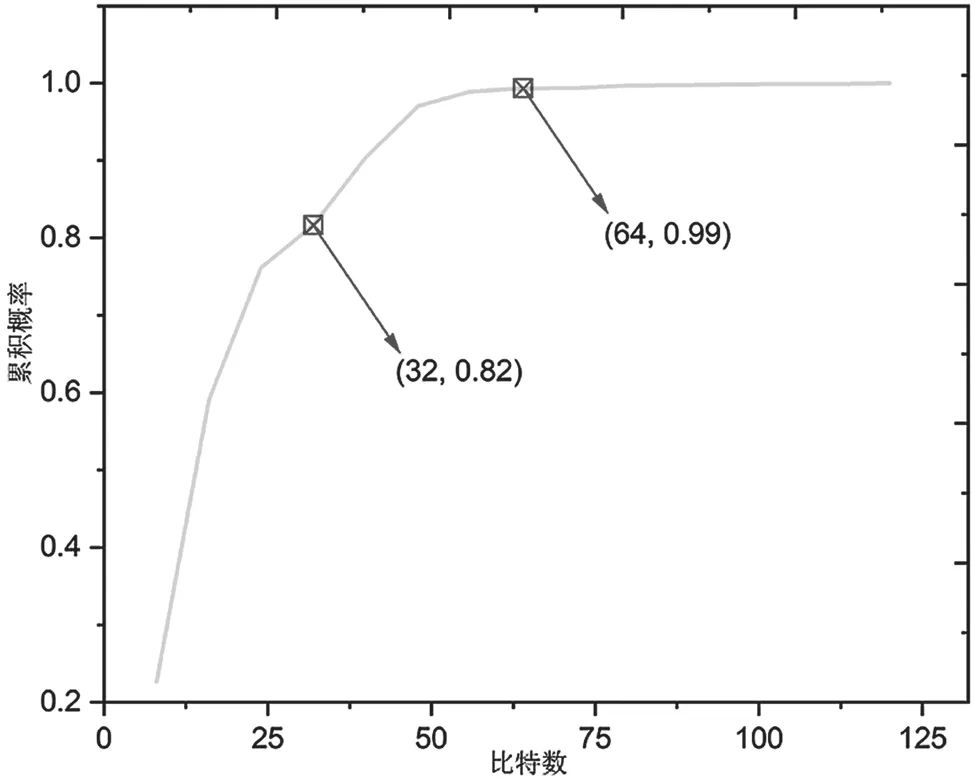
图5 BIG2015指令数量累积概率分布
2 深度学习模型
2014年,Kim[10]提出了一个适用于语句分类的单层卷积神经网络(CNN)架构模型。受Kim研究的启发,本文提出了如图6所示的基于图像矢量的恶意代码分类模型架构。
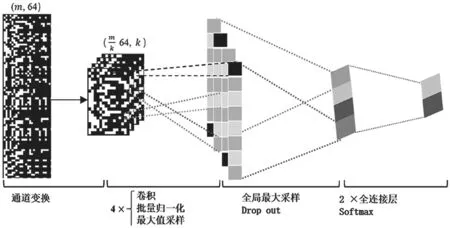
图6 基于图像矢量的恶意代码分类模型架构
模型输入矢量化的恶意代码图像,大小为(m,64),其中m代表编码的指令数量。通道变换模块输出大小为的图像矢量,其中k代表通道数,是待确定的超参数。下面将以k=1为例,给出模型的详细描述。
首先,记Sj∈R64为64维图像矢量,对应m中的第j条指令,则恶意样本Xi可以表示为:

记每个卷积层的过滤器为fr∈Rhq,其中h、q表示过滤器的尺寸,每次卷积窗口移动都将h条指令的q/64矢量映射成新的特征矢量。例如,记ci,t表示由指令Xi:i+h-1(t:t+q-1)经过滤器移动到位置t得到的新特征矢量,则:
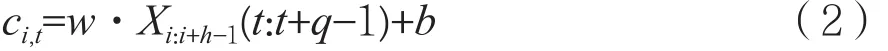
其中b∈R为偏置项参数。
因此,当一个行卷积操作完成时,一个新的特征矢量便产生了:

当一层卷积的所有操作完成时,便得到了一个新的图像特征矢量:

对c进行批量归一化(Batch Normalization)。批量归一化允许深度学习模型使用较大的学习率进行训练,能一定程度上抗过拟合,对于加速模型的训练具有显著的意义[11]。mini-batch上的批量归一化算法的详细过程如下:
输入:每个mini-batch上的c值φ={c1…n}
1:需要学习的参数γ,β
输出:ei=BNβ,γ(ci)
5:缩放与位移ei←β ≡ BNβ,γ(ci)
批量归一化后,对得到的矢量进行激活和最大值采样,得到新的特征矢量:
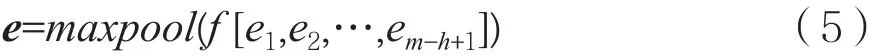
其中f为非线性函数。
至此,已经描述了模型中单个CNN模块的特征提取过程。模型堆叠四个CNN模块进行抽象特征提取,因此全局最大采样(Global Max Pooling)层的输入为:

其中g由具体的CNN模块参数决定。为了进一步降低模型输出的特征向量维度,并同时保留重要特征,对整个CNN模块输出进行全局最大采样,输出恶意代码的抽象特征矢量=max{e}。

其中yi表示恶意样本属于家族i的概率,n表示恶意样本的家族数量。
基于图像矢量的恶意代码分类模型利用上述方法对恶意代码的指令矢量进行层层变换,提取出高纬度抽象特征,从而实现恶意代码的分类。
3 实验结果与分析
3.1 数据集
BIG2015数据集包含9个恶意家族的21 741个样本,其中10 868个样本为带标签的训练集,其他为不带标签的测试集。训练集中,每一个样本包含一个20字符的哈希ID和一个整数值得家族标签,分别为 Ramnit(F1)、Lollipop(F2)、Kelihos ver3(F3)、Vundo(F4)、Simda(F5)、Tracur(F6)、Kelihos、ver1(F7)、Obfuscator.ACY(F8)和 Gatak(F9)。每个恶意样本包含两个文件,分别为十六进制表示的、去除PE头的二进制文件和反汇编工具IDA生成的包含恶意样本机器码、汇编指令等的元数据文件。
因为BIG2015中只有训练集带有标签,所以选取训练集中的恶意样本作为模型验证的基准,其分布如图7所示。
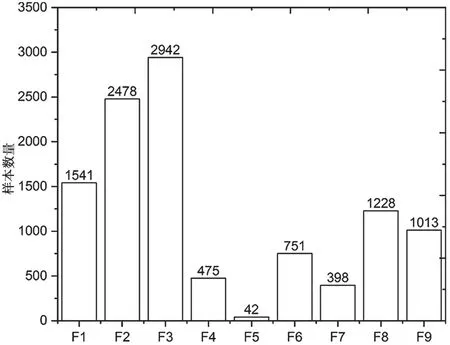
图7 BIG2015训练集样本家族信息分布
3.2 模型实现
实验使用的平台信息如表1所示,具体的模型参数见表2。

表1 实验平台信息
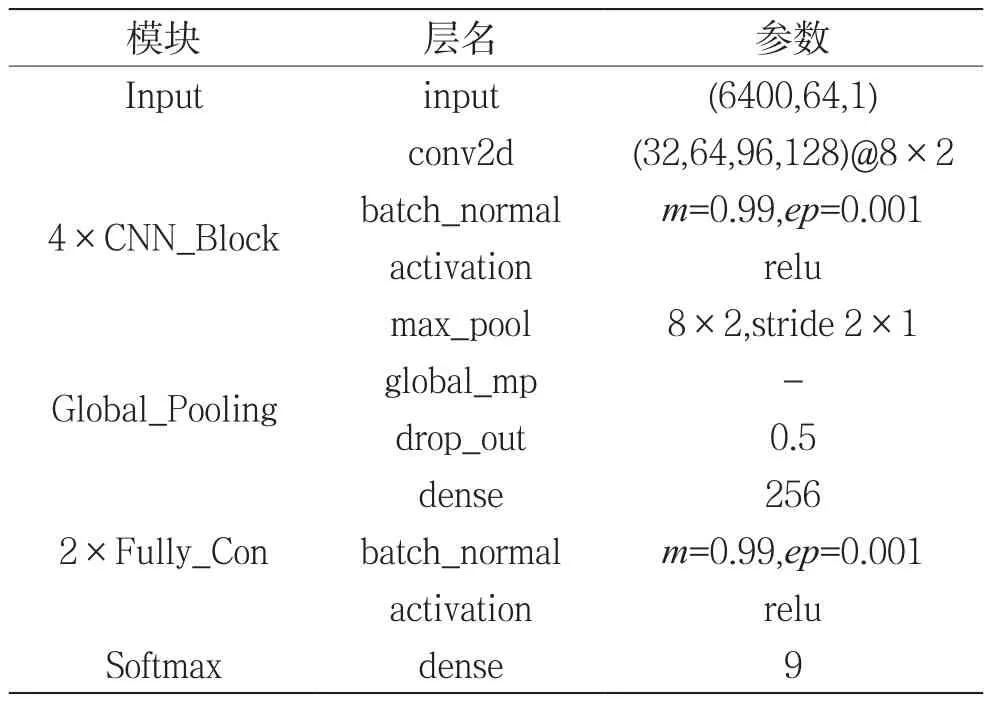
表2 基于图像矢量的恶意代码分类模型参数
3.3 评估标准
模型使用交叉熵损失函数,定义如下:
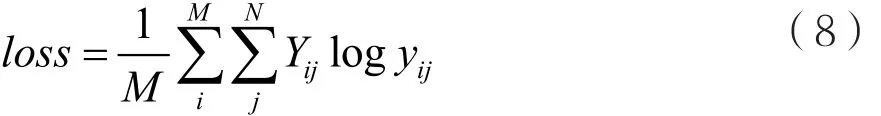
其中M表示mini-batch的样本数量,N表示恶意家族的数量。Y为样本标签值,如果样本i在家族j中,则Yij=1;反之,Yij=0。y为模型的预测输出,yij代表样本i在家族j中的概率。
同时,模型使用准确率(accuracy)、精确率(precision)、召回率(recall)和f1_socre来进行模型性能的评估,其定义如下。
记S为数据集中的样本数量,i表示S中的第i个样本,y表示预测值,Y表示真是值,l(x)为指示函数,则:
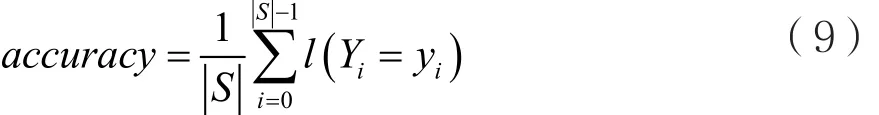
其次,定义:
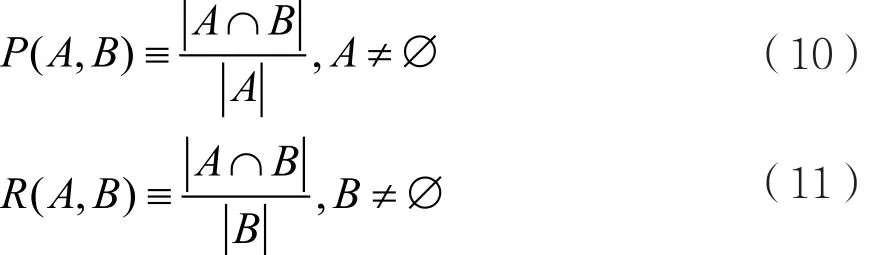
记η为S的子集,则:
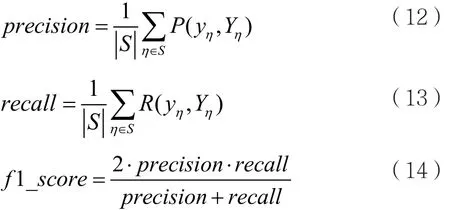
综上,accuracy反映模型分类正确的样本占总样本的比例;precision体现的是模型不将一个负样本标记为正原本的能力,recall反映的是模型找到所有正样本的能力,f1_score是两者的加权体现。
3.4 结果与分析
实验中,使用10-fold交叉验证方法对模型进行评估,结果如表3所示。结果表明,基于Andrew图像矢量的恶意代码分类模型在BIG2015训练集上,能实现97.87%的准确率和0.094的损失,其他详细性能评价指标详见表3。平均来看,模型的训练时间为1.7 h,训练好的模型检测1 024个样本的时间为5.11 s。
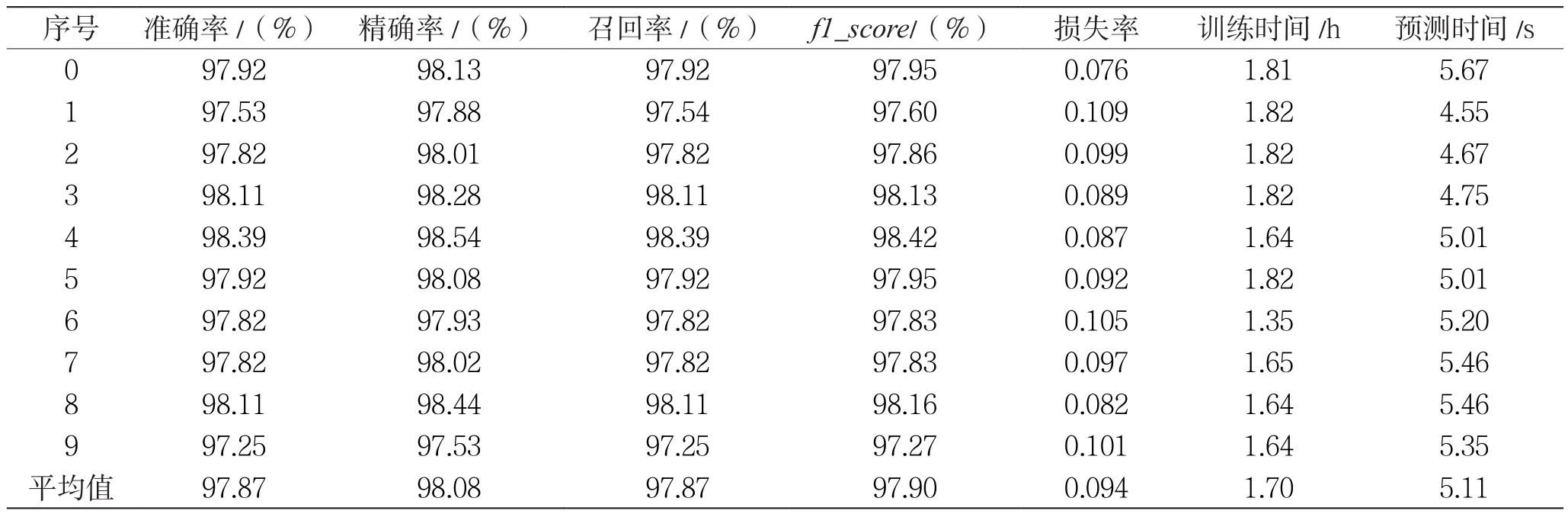
表3 BIG2015 10-fold交叉验证结果(k=1,m=3 200)
与相关研究对比来看,如表4所示(预测时间为1 024个样本的检测时间),本文提出的基于图像矢量的恶意代码分类模型的准确率只比文献[12]和文献[4]中模型的能达到的准确率略低,主要原因在于后两者都是基于复杂、耗时的特征提取和融合技术。因此,本文提出模型的预处理时间、训练时间和预测时间相较于文献[12]和文献[4]都是成倍减少的。同时,相较于文献[13-14]的方法,本文的模型在准确率上也有明显优势。
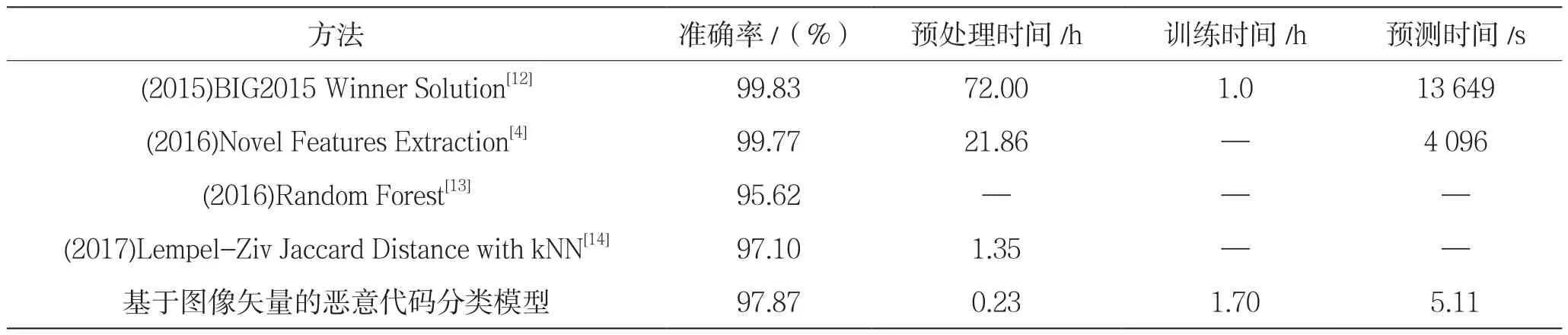
表4 相关研究工作比较
4 结 语
本文主要研究了基于图像矢量的恶意代码分类模型在大规模PE(Portable Executable)格式恶意代码分类任务中的应用和效果,详细阐述了Andrew矢量化技术的相关细节,设计和训练了基于Andrew矢量化的恶意代码分类的深度学习模型。模型在BIG2015数据集上的交叉验证结果表明,虽然模型的准确率比冠军模型(基于复杂特征提取和融合技术)的准确率略低,但是实现了显著的性能提升。同时,实验结果也表明,与其他相关研究相比,本文的模型在准确率上优势明显。
综上,基于图像矢量的恶意代码分类模型成功将恶意代码的分类问题转化为图片的分类问题,且模型具有较好的理论鲁棒性,对于大规模恶意代码的分类任务具有实际意义。然而,Andrew矢量化使用了大量的无效填充,使得图片矢量的编码效率很低。因此,如何提高恶意代码图片矢量化的编码效率是今后进一步的研究方向。
