互联网金融企业用户流失预测特征提取方式对比研究
2018-12-17,
,
(中国科学院大学 经济与管理学院,北京 100190)
1 引言
近年,互联网金融经过快速发展,用户流失问题变得与银行业和电信业类成熟型行业一样越来越重要。一是因为精准的用户流失预测能为企业制定用户策略提供有效的决策依据甚至是决策方案;二是因为获取用户的成本是留住用户成本的5倍以上。在行业竞争越来越激烈的情况下,有效的用户管理是一柄重要的竞争利剑,影响企业生存。目前互联网金融企业正面临用户获取成本高和用户流失率高等问题,所以如何提高用户流失预测的效果,从而在用户管理方面提高资金利用率是一个值得研究的问题。一些学者的研究为企业在用户流失方面提高资金利用率提供了理论支持,如Bhattacharya[1], Athanassopoulos[2], Slater和Narver[3]发现:获取一个新用户的成本是留住一个老用户成本的5到6倍甚至更多;He等[4]的研究提到:哈佛商业评论研究表明降低5%的用户流失率能够提升25%到85%的企业利润。
用户流失预测效果好坏主要取决于特征变量的好坏。特征提取和选择的相关研究主要聚焦在特征工程方面,如:Titele[5]通过从用户的个人信息、信用卡信息、风险信息和交易信息为用户流失预测模型设计了135个变量;Huang等[6]提出了一种多目标特征选择方式;Castro和Tsuzuki[7]通过TFPD方式提取游戏类用户的日志行为特征从而对用户的流失行为进行预测;Coussement和Poel, Coussement等[8,9]通过对某电信企业的研究揭示数据展现形式对流失预测的影响;周静等[10]运用社交网络分析方法,通过构造与网络结构相关的变量进行影响因素的探讨,运用LR方法构建客户流失预警模型。本文主要采用RFM(recency-frequency-monetary)和TFPD(time-frequency plane domain)方法提取特征。RFM是一个经典的基于用户生命价值理论研究用户行为的模型,以零售业为例,该模型提取用户的最近购买时间、消费频率以及消费金额三类数据来衡量用户对企业的忠诚度和购买力,相关研究[11,12]以及拓展研究[13~16]较多。Castro和Tsuzuki[7]提出TFPD方法用于提取特征的趋势信息,其研究结果表明该类方法应用于在线游戏领域用户流失预测问题可比RFM方法平均提升23%的企业收益。
用户流失预测文献资料丰富,包含管理学方面的文献[17~20]和计算机科学方面的文献[21~24],研究领域主要为电信业和银行业,其中互联网金融领域用户流失预测问题的研究较少,且尚未发现基于用户基本信息、日志行为和交易类信息这三类能较全面刻画用户特征的数据进行流失预测的相关研究,本研究将基于这三类数据展开。且相关文献较少涉及针对用户的行为类数据和交易类数据系统考虑特征提取的优化方案,本文通过RFM和TFPD两类方法针对相关数据提取特征,并对两类特征提取方式在不同数据类型和模型上的表现进行评估,从而为用户流失管理提供建模技术和管理两方面的启示。
2 基于RFM和TFPD特征的用户流失预测模型与方法
2.1 数据和特征
本文研究对象是案例企业账龄3个月以上的最后一笔定期到期用户,针对该类用户群体,本研究采用案例企业的流失用户定义:最后一笔定期到期后若持续30天以上平台资金量小于150元则为流失用户。据此,本研究的流失用户标记依据为:以用户最后一笔定期到期日(定期购买时间2016年10月31日之前)为开始日期,到统计日期2016年12月31号截止,如果一个用户此期间连续30天以上账户总金额小于150元则被认为是流失用户。
本文研究数据包含用户的基本信息、日志行为信息和交易信息。为对RFM和TFPD特征提取方式进行对比,基于以上数据的特征分成三类:一是基本信息,包含用户的性别、年龄、所在城市等级等人口学信息和活期定期投资金额等不通过RFM和TFPD方式提取的交易和行为信息;二是日志行为信息提取的RFM和TFPD类特征,日志行为信息包含用户对企业移动端app页面的访问日志;三是交易类信息提取的RFM和TFPD类特征,交易信息包含用户在企业移动端app转入资金、购买理财产品、赎回资金等信息。
本研究共获得13831名符合条件的用户作为样本数据,其中4507名为流失用户,9324名为留存用户,流失率32.6%。以上数据随机选取70%采用五倍交叉验证法同时作为分类器的训练集和测试集,通过网格搜索确定分类器的最佳参数,另30%数据作为验证集衡量分类器在新样本上的表现。另外该数据集类别分布不均衡,本文采用代价敏感参数法对少数类别进行补偿。对不平衡数据的处理方法将作为未来工作,本文不再讨论。
2.1.1 基本特征

表1 用户的基本特征及其解释
案例企业提供了19个运营环境下与用户流失关系密切的变量供参考,这些变量包含用户人口学特征、行为特征和交易特征。表1展示了这些特征及其对应的解释:人口学特征包含用户的年龄、性别等信息;交易类特征包含用户优惠券的使用率和定期投资总额等信息;行为类信息包含用户最后一次登录到统计截止日的时间差等信息。
2.1.2 RFM和TFPD类特征
RFM和TFPD是两种对时间序列格式的数据进行信息提取的方法。RFM中R代表用户最近一次购买时间距统计截止日天数;F代表用户某一行为在统计时间范围内发生的频率;M代表用户在统计时间范围内付出的成本(金钱、时间等)。本研究的RFM特征提取方式为:通过对M变量求F的均值得到R时间范围内的平均值特征,如:R-最后一笔定期到期前一周,F-用户访问移动端app频率为5次,M-总访问时长为40秒,则RFM变量为用户最后一笔定期到期前一周每次访问app平均时长8秒。TFPD是Castro和Tsuzuki[7]提出的一种频数分析法,首先使用小波分解(wavelet packet decomposition schema)获得变量每一时间段的频数信息,然后将按时间顺序排列的频数类数据每两对分别相加和相减求均值将数据分成父类和母类因素,对父类和母类因素分别重复上述操作直到父类和母类因素无法再按相同的方式进行分割。TFPD法通过对成对变量的加和求均值和相减求均值实现对变量短期变化趋势的捕捉。
交易和日志行为数据均通过RFM和TFPD方法提取特征。交易数据为用户在平台的资产总额即资金存量信息,日志行为数据为用户登录app频率以及对收益类页面的平均访问时长。其中交易信息的时间窗口为用户最后一笔定期到期前推16周(TFPD算法收敛的条件是时间周期为2n),统计用户16周内每周在该企业移动端理财app的资金平均存量。由于行为数据时间有效性较短,时间窗口设置为用户最后一笔定期到期前推8周,统计用户每周访问APP平均时长和收益类页面平均访问时长。
2.2 分类模型及其效果评估方法
本研究使用二分类模型对企业用户是否流失进行预测,包含LR、RF和SVM三类二分类算法。对于每一个用户,二分类模型会根据其特征产生一个0到1范围内的概率值用以表示一个用户为流失用户的概率,本研究中当概率值大于0.5时,用户为流失用户,否则为留存用户。以用户流失与否的实际情况为参照,根据分类模型对用户流失概率的预测可计算用以衡量模型分类准确度的AUC值,根据模型对用户流失与否的判断可获得分类模型混淆矩阵,进一步计算分类的精准度和召回率。
2.2.1 分类模型
本文的流失预测模型中,假设样本为{X,Y}n,则:目标变量Y为用户是否流失,Y=1表示流失用户,Y=0表示非流失用户;X为m维的样本特征向量;n表示样本数。
LR算法是比较常用的二分类算法,具有速度快、简单易理解等优点,适合处理线性可分的二分类问题。在LR模型中,用户被预测为流失用户的概率如(1)式所示,其中wi为通过样本学习的逻辑回归对应变量的最优参数,对于本研究P(Y=1|x)>0.5,则用户被判定为流失否则为留存用户。
(1)
SVM算法可以通过核函数将特征映射到高维空间解决线性不可分问题,在处理小样本、非线性和高维模式识别中具有优势。SVM可以通过支持向量构造最优分类平面将正负样本分开,超平面的公式为wx+b=0,SVM通过优化问题(2~3)确定超平面参数向量w和b,其中ξi和C是为了解决线性不可分问题引入的松弛变量及其系数,允许数据点在一定程度上偏离超平面。对于本研究若wx+b>0,则用户被判断为流失用户否则为留存用户。
(2)
subjectto:yi·(w·x+b)≥1-ξi∀i,ξi≥0
(3)
RF是由众多决策树组合而成的分类器,具有准确率高、学习过程快等优点。RF算法的输出结果由全体决策树投票决定。决策树的核心算法为分裂规则,常用算法有ID3、C4.5和Gini系数。本研究选取目前最通用的Gini系数作为分裂规则,如(4)式所示,分裂规则可计算每次分裂不同特征的重要性和最优分裂点,如(5)式所示,其中A表示特征,k表示A特征的类别数,如性别特征k=2,D表示计算该特征Gini指数时划分样本的样本数。通过(4)式和(5)式可以确定一颗决策树,对于随机森林而言,可通过随机选择总样本的多个子集、所有特征的多个子集训练多颗决策树,新的样本则根据多颗决策树从训练样本中学习到的规则进行投票分类。
(4)

(5)
2.2.2 分类模型效果评估
二分类预测模型效果评估常用指标包含准确率、召回率、精确度、F-score和AUC(the area under ROC curve)。其中准确率、召回率等指标要求样本为平衡数据,因为本研究采用的是不平衡数据,所以对比RFM和TFPD特征提取方式的流失预测效果时采取AUC作为评价指标;最终模型效果解释选择精确度、召回率和混淆矩阵三类指标。
ROC(receiver operating characteristic)曲线用于衡量分类模型区分好坏样本的能力[25],通常用AUC即ROC曲线下的面积表示分类器性能好坏,AUC越大,分类器效果越理想。混淆矩阵是可视化分类器在正负样本上具体表现的工具,矩阵的每列代表类的预测值,每行代表类的实际值。TP表示分类器将实际流失用户预测为流失用户的数量;FN表示将实际流失用户预测为留存用户的数量;FP表示实际为留存用户预测为流失用户的数量;TN表示实际为留存用户预测为留存用户的数量。通过混淆矩阵可分别计算正负样本分类的精确度和召回率,以正样本为例:精确度指预测结果为正样本时预测正确的比例,计算公式为TP/(TP+FP),召回率指预测结果为正样本且实际为正样本占实际正样本的比例,计算公式为TP/(TP+FN)。
3 结果分析与讨论
本研究首先使用RFM和TFPD方法从用户的日志行为信息和交易信息中提取特征,包含RFM类日志行为特征、RFM类交易特征、TFPD类日志行为特征和TFPD类交易特征;然后利用以上特征建立不同的流失预测模型,模型使用LR、RF和SVM三类算法,对案例企业最后一笔定期到期用户流失与否进行预测,以0.5为用户流失与否的判断标准,即流失概率大于0.5为流失用户,否则为留存用户;最后以AUC作为上述模型优劣的评价指标,模型结果如表2所示。
通过表2对比三类模型五倍交叉验证的AUC评分可以发现:对比日志行为信息beh_TFPD和beh_RFM在三类模型上的表现,beh_RFM的AUC均值均大于beh_TFPD的AUC均值,因而针对日志行为类信息通过RFM方式提取特征建模优于TFPD方式;对比交易类信息trade_TFPD和trade_RFM在三类模型上的表现,对于RF和SVM算法,trade_TFPD的AUC均值大于trade_RFM的AUC均值,此时交易类信息通过TFPD方式提取特征建模优于RFM方式,而LR算法的结论与之相反。基于以上描述,本研究的数据对于基于LR算法的流失预测模型以RFM方式提取交易特征,基于RF和SVM算法的流失预测模型以TFPD方式提取交易特征,RFM提取行为特征较为合理。

表2 各分类模型结果数据
最后,本研究以用户基本特征、RFM方式构建的交易特征和行为特征训练基于LR算法的流失预测模型,以用户基本特征、TFPD方式构建的交易特征以及RFM方式构建的行为特征训练基于RF和SVM算法的流失预测模型,过程与各类特征单独建模一致,从精确度、召回率以及AUC三类指标衡量模型在验证集上的表现,包含精确度、召回率和AUC的评价结果如表3所示。
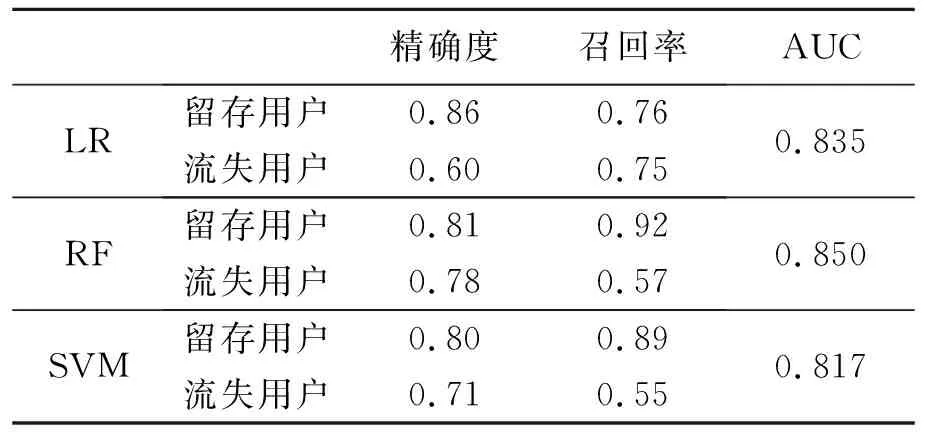
表3 流失预测模型分类结果
从表3可以看出用户流失预测模型对流失用户的预测效果:基于LR算法的模型召回率最大为0.75,预测出的流失用户包含75%真正会流失的用户;基于RF算法的模型精确度最高为0.78,能以78%的准确性预测出流失用户,优于随机猜测的30%。以上结果是以阈值0.5为流失与否判断依据,实际运营环境下,可以根据企业的业务需求判断哪一类指标更重要,调高阈值以提高精确度,调低阈值以提高召回率。现假设案例企业最后一笔定期到期用户1000名,这些用户的流失率为30%,现需要采取行动避免用户流失。如果企业不了解这些用户具体流失倾向,一是对1000名用户均采取运营优惠活动挽留可能流失用户;二是不采取任何措施放弃将会流失的用户。在企业不了解用户具体流失倾向时采取行动将变得缺乏目标且成本巨大。如果企业对用户进行流失预测,预测具体的流失用户群体,以基于RF算法的模型为例对流失预测分类器的效果进行解释,用混淆矩阵展示模型效果如表4所示。

表4 基于运营假设的混淆矩阵
从表4看出,1000名用户中实际流失用户为336名,流失率33.6%,其中模型预测总共245名用户为流失用户,预测正确191名,预测正确率为78%,召回率57%。运营环境下,案例企业本需对1000名用户都采取策略从而挽留即将流失的用户,但通过该流失预测模型,案例企业可针对模型预测的245名流失用户采取挽留策略。与对1000名用户采取相同的挽留策略相比,对预测为流失的245名用户以及根据其流失可能性的大小采取不同程度的挽留策略能为企业节省可观的用户关系维护成本。实际运营环境下,案例企业可根据用户维系的目标选择具有不同表现的模型,如果倾向于留住更多用户则可使用召回率较高的LR模型;如果更倾向于降低用户关系维系成本则可使用精确度较高的RF模型。
4 结论与启示
用户流失预测的技术相对成熟,本文认为优秀的流失预测方案有两个重要的因素:一是对具体流失问题的认知程度;二是数据的质量和从中提取的信息量。本文以互联网金融企业用户流失问题为背景,通过案例企业的真实用户数据研究用户流失预测建模问题,针对互联网金融用户的流失特点,选取用户基本信息、日志行为信息以及交易信息中对用户流失有预判作用的信息作为建模数据,其中基本信息一定程度上刻画用户的人口学特征,如年龄、学历和投资偏好等;用户的交易信息可刻画用户的投资偏好和倾向,如购买量的变化;用户的日志行为类信息则刻画用户的投资态度,如对平台收益的关注度,这些信息组合在一起可以大致知道用户是否有投资意愿、目前在平台投资的资金是增加还是减少以及对自己的投资产品或其他产品的关注程度等。针对以上数据,本文进一步比较不同的特征提取方式优劣,采用RFM和TFPD两类方法从行为数据和交易数据中分别提取特征,对比两类特征提取方法在不同数据即日志行为数据和交易数据与不同模型即LR、RF和SVM上的表现,发现对于LR模型RFM提取的特征表现优于TFPD,对于RF和SVM模型,行为类信息通过RFM提取特征表现优于TFPD,交易类信息通过TFPD提取特征表现优于RFM;最后本文将用户流失预测模型应用于企业的用户流失管理过程,可帮助企业定位潜在流失用户,为其开展对应的流失用户挽留策略提供数据支持。本研究旨在为用户流失管理提供建模技术和管理两方面的启示,流失建模技术方面可为数据类型选择和特征提取方式提供参考思路与方案;流失管理启示方面,本研究的研究成果首先可为企业定位流失用户群体从而提升运营效率,其次可依据用户流失的概率大小差异化设计用户关系维系成本节省企业预算。未来我们将对用户行为和交易信息的特征处理进行更深入的分析与研究,一方面研究更多基于数据类型的特征提取方式,另一方面尝试挖掘数据类型与适用特征提取方式背后的联系机理,以取得更好的预测效果和更有深度的发现。
