一种基于ARIMA的FPGA系统级动态功耗预测建模框架
2018-12-15赵晖
赵 晖
(1.中国科学院上海微系统与信息技术研究所,上海200050;2.中国科学院大学北京100049;3.上海科技大学信息科学与技术学院,上海201210)
现场可编程门阵列,(Field-Programmable Gate Array,FPGA),作为芯片开发流程中的原型设计,近几年凭借灵活的可编程特性,在加速器、移动设备接口等直接应用上也日益受到关注[1-3]。随着芯片集成度的提高,以及移动应用等平台的特殊限制,FPGA应用在功耗控制和功耗安全上的设计要求也越来越高,其中尤以动态功耗最为显著[4,5,9]。在应用设计阶段,如何准确又快速地满足器件的功耗要求,成为设计人员需要面对的难题。
文献[7]中提出了在传统电路设计过程中,基于电路底层的信号仿真进行动态功耗预测的方法。然而,目前的FPGA平台仍然缺乏对应的自动化功耗采样框架以提高预测效率。由于仿真预测需要对电路信号进行实时记录、文件生成和功耗映射,在面对规模较大的应用以及长时间功耗预测的需求时,时间成本和文件存储成本都过于高昂[9]。
为了改善这一问题,本研究根据文献[7],首先提出了面向FPGA应用设计的动态功耗自动化采样框架,并在此基础上提出了基于ARIMA的预测模型的建模方法。
1 FPGA动态功耗自动化采样框架
1.1 基于仿真的动态功耗预测方法
FPGA的功耗主要分为静态功耗和动态功耗两部分。其中静态功耗主要指的是逻辑门在未发生翻转的情况下,晶体管漏电流引起的功耗消耗,与特定型号的FPGA产品有关,在功耗仿真中一般作为常数。动态功耗指的是逻辑门在发生翻转的过程中晶体管电容充放电引起的瞬时功耗[7-8,10]。在电路运行的过程中,由于逻辑门翻转的概率和数量存在较大的波动,因此不同时期的动态功耗存在较大的变化。随着电路设计规模的增大和集成度的提高,动态功耗在总功耗所占的比重不断上升,其不稳定性对功耗设计安全的挑战也愈发严峻。
文献[10]提出了FPGA的功耗构成模型以及动态功耗的门级模型:
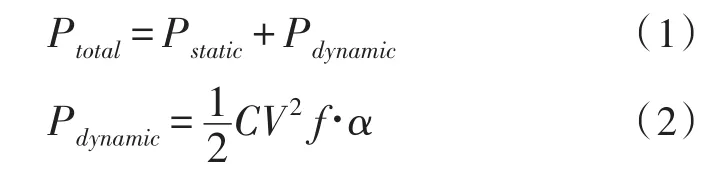
式中Ptotal代表总功耗,Pstatic和Pdynamic分别为静态功耗和动态功耗。C为晶体管电容,V为供电电压,f为时钟频率,α为信号翻转率(Toggle Rate)。
在传统基于仿真的动态功耗预测方法中,功耗库文件包含了寄存器级(Transistor Level)的动态功耗模型,包括C、V,f在内的电路参数都映射在库文件中[10-11]。由于α与电路内部的众多信号相关,同时受电路控制信号、电路状态、输入数据、电路运行时间等多方面因素的影响,为了得到精确的动态功耗数据,电路需要通过冗长的功能仿真,才能得到特定时间段内的信号翻转情况。
1.2 跨平台自动化采样框架的搭建
仿真预测方法虽然同样适用于目前的FPGA设计,但是缺乏自动化功耗采样的框架。由美国赛灵思(Xilinx)公司开发的FPGA仿真平台——Vivado,支持旗下绝大多数FPGA产品的编码、仿真、综合和实现等一些列设计环节。在具体的设计流程中,Vivado支持以精确的FPGA功能仿真结果得到信号活动信息格式(Signal Activity Information Format,SAIF)文件,记录下特定时间段内内部各个信号的翻转率,再以SAIF文件映射到动态功耗库,得到精确动态功耗数值的仿真预测法[7,12]。
其具体操作流程如下:
1)完成FPGA应用的功能设计,综合和实现;
2)创建SAIF文件记录信号,信号数量越多,功耗值越准确,相应的SAIF文件存储空间也越大;
3)设定仿真时间窗口(Time Window)并进行后实现功能仿真(Post-implementation Functional Simulation);
4)将产生的SAIF文件映射到系统功耗库,计算动态功耗。
虽然Vivado本身支持动态功耗的仿真预测,但是由于缺乏参数化、接口化、自动化的架构特质,因而并不支持针对连续功耗变化的功耗采样操作。为了进一步提高动态功耗仿真预测的效率,本研究基于Tcl语言,结合MATLAB平台的数据处理能力,搭建了FPGA动态功耗预测的跨平台自动化框架,如图1所示。在该框架内,功耗采样的参数设置在Tcl文件内完成,进而控制Vivado执行的,通过反复执行一步功耗预测得到功耗报告文件,最后经由链接的MATLAB程序处理得到整体的功耗采样曲线。
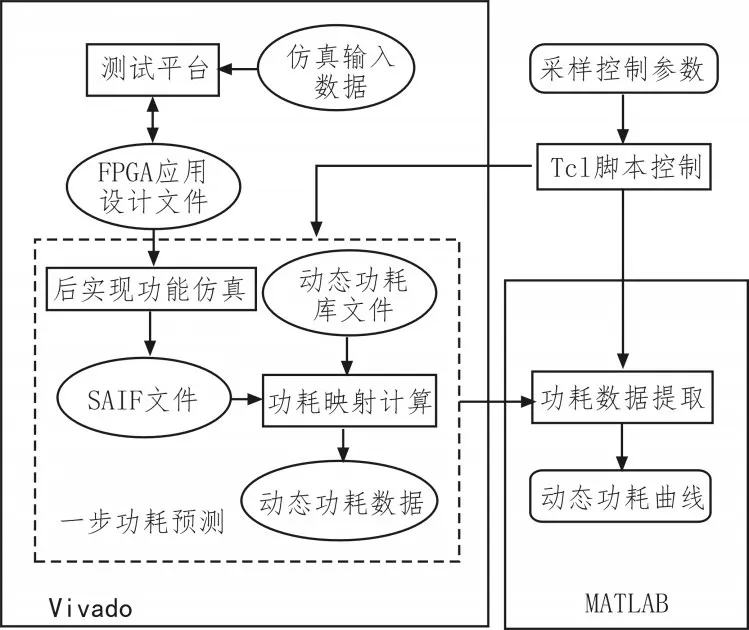
图1 跨平台FPGA动态功耗自动化预测框架
1.3 采样周期的设置
在实际的动态功耗预测中,为了得到符合要求的动态功耗预测曲线,上诉的功耗采样过程需要设置适宜的采样周期,也就是采样窗口。由于SAIF文件统计的是特定时间段内的信号翻转数,根据定义,翻转率可表示为:
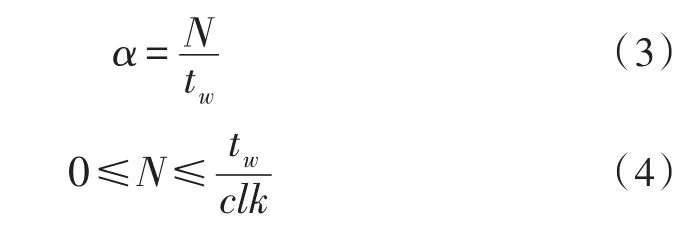
式中N为目标信号在时间窗口tw内的翻转数,clk为时钟周期。公式(4)说明,任一信号在采样周期内的翻转次数不能超过时钟翻转的次数[7-8,11]。
在不同采样周期下的动态功耗采样曲线如图2所示。从图中可以发现,当采样周期较小时,虽然曲线的瞬时变化趋势丰富,但是由于翻转数偏小,导致曲线偏向离散化,功耗均值偏低;而当采样周期较大时,动态功耗容易偏向平均功耗,导致曲线的瞬时变化趋势丢失,观察不到瞬时变化。因此,根据时钟周期选择合适的采样周期,才能得到具有参考意义的动态功耗信息,通过实验论证,一般建议采样窗口为时钟周期clk的20~40倍。

图2 不同采样周期下的FPGA动态功耗变化曲线,时钟周期为10 ns
2 ARIMA预测模型
2.1 ARIMA模型概述
基于仿真的动态功耗预测方法虽然能够提供精确的动态功耗变化曲线,但是缓慢的采样过程带来的时间成本,以及较大的文件尺寸带来的存储压力在大规模应用和长时间预测面前都是不适宜的。针对这个问题,求和自回归移动平均(Autoregressive integrated moving average,ARIMA)模型,能够利用时间序列的连续性和相关性,建立短期预测模型,从而快速地对时间序列进行预测[17]。
对于一随机不平稳时间序列X(t),其ARIMA(p,d,q)模型[13-14,16]如下:


式中,d代表序列差分后平稳的差分次数;B为延迟算子,Bxt=xt-1;p为自回归延迟阶数;φi为第i阶自回归系数;q为移动平均阶数;θj为第j阶移动平均系数;εt指白噪声。
由于动态功耗本身即是时间序列,本研究根据FPGA应用在上诉自动化跨平台框架下得到的历史动态功耗数据,构建了对应的ARIMA模型。该模型不涉及底层电路,因而属于抽象层次(Abstract Level)的模型,同时是对整个应用系统的动态功耗建模,因此是一个系统级(System Level)的模型。该模型能够跳过底层仿真,从而更加快速地对整个FPGA应用系统的动态功耗做出预测。
2.2 模型筛选
文献[14]给出了ARIMA建模的大致流程,如图3所示。其中,为了避免p,q阶数的定阶操作受主观人为影响,文中采用了基于最小信息量(An information criterion,AIC)准则,在多个ARIMA模型选取合适模型的方法[14-15]。其中AIC在ARIMA模型中的计算方法如下:

式中n为序列大小,为模型极大似然函数值。选取的主要操作步骤如下:
1)选取p∈[1,P],q∈[1,Q];
2)构建ARMA(p,q);
3)计算各个ARIMA模型的AIC;
4)筛选出AIC最小的模型。
当筛选模型的拟合残差通过白噪声检验,ARIMA模型即构建完成。在本研究中,对应的ARIMA建模流程均通过MATLAB完成。
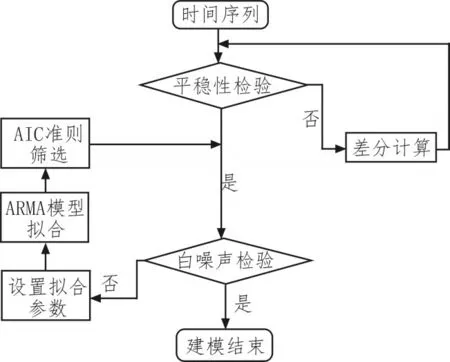
图3 ARIMA建模流程
3 实 验
本研究基于如下硬件平台和软件平台进行实验:Intel@Core(TM)i7-4790CPU3.60 GHz×8处理器;32 GB(31.3 GB可用)内存;Ubuntu Kylin 16.04 LTS操作系统;Vivado 2014.04;MATLAB R2016b。实验采用的FPGA应用设计为Vivado自带的小型CPU[12],对应的FPGA硬件平台为xc7k70tfbg676-2。
在时钟周期为10 ns的情况下,采样周期设为300 ns进行动态功耗采样,得到采样数为1000的动态功耗数据集。选取其中的前70%的数据点作为ARIMA建模的训练集,后30%的数据点作为测试集,如图4所示。
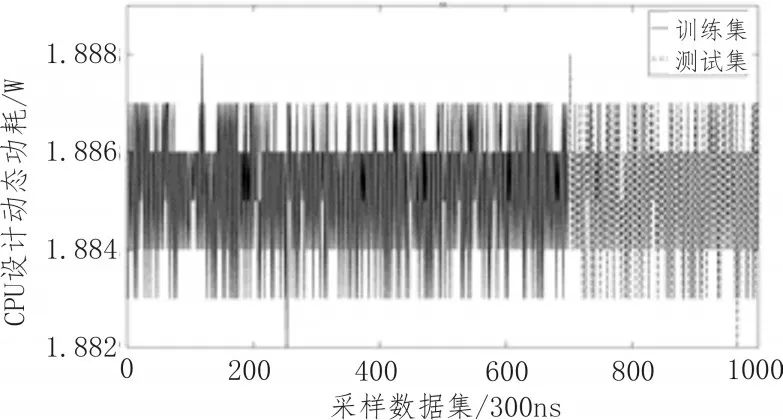
图4 CPU设计动态功耗采样曲线
构建得到的ARIMA模型为ARIMA(9,1,11),其进行1步预测的拟合曲线如图5所示。为检测预测精确度,本研究采用平均误差进行误差分析,如式(9)所示。
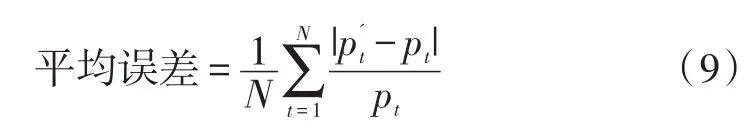
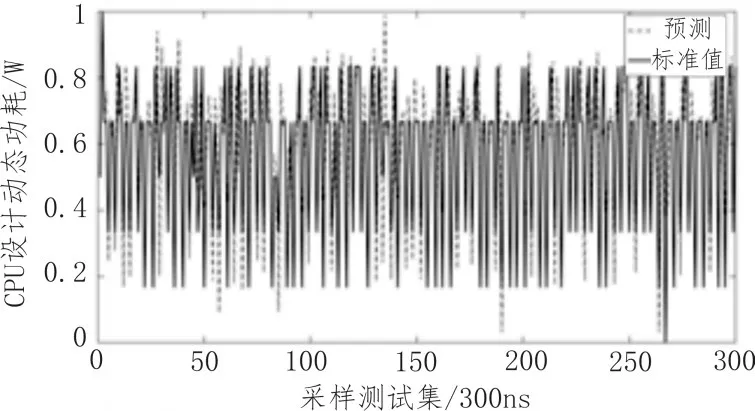
图5 ARIMA模型1步仿真预测结果对比
本研究将通过精确仿真得到的功耗采样值作为标准值,通过计算,平均误差仅为0.032,预测精度达到了96%。同时,表1详细对比了ARIMA模型预测和仿真预测对于动态功耗进行1步预测的性能参数指标。表中数据表明,ARIMA模型进行1步预测的速度是仿真预测的279倍,存储成本降低了263倍。通过分析,其根本原因在于ARIMA模型是经验模型,跳过了冗长的电路仿真和功耗映射阶段。
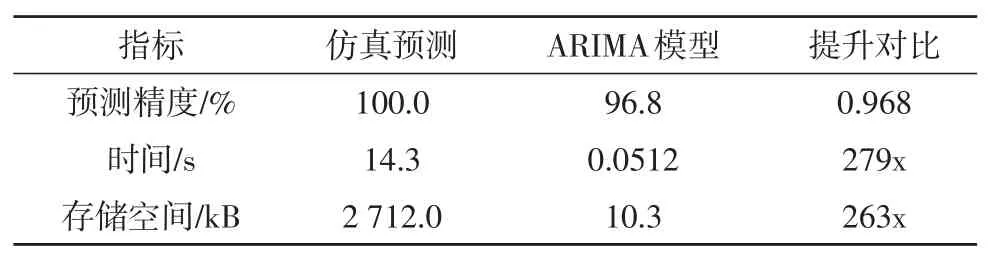
表1 动态功耗1步预测参数对比
4 结论
本研究针对FPGA应用在设计过程中的动态功耗仿真需求和预测需求,提出并实现了一种基于ARIMA模型的系统级功耗预测建模框架。该框架实现了跨平台的自动化动态功耗采样,并在采样数据的基础上建立了系统级、抽象层次的快速预测模型。该模型能在保证足够预测精度的前提下,极大地降低短期动态功耗预测所需的时间成本和存储成本,从而在大规模FPGA应用设计和长时间功耗仿真的情况下,提高功耗预测效率,进一步缩短应用开发周期。
