基于卷积神经网络的多光谱图像多标签场景分类
2018-12-15李一松
李一松
(1.中国科学院上海微系统与信息技术研究所,上海 200050;2.中国科学院微小卫星创新研究院,上海201210;3.上海科技大学信息科学与技术学院,上海201210;4.中国科学院大学北京100049)
多光谱成像技术始于20世纪80年代,是光学仪器发展历史中的一次飞跃。该技术突破了传统相机的成像能力,传统的彩色相机只能记录红、绿、蓝3个通道的影像,而多光谱成像可以记录除可见光波段外的其他光谱影像,其光谱探测范围远远超过了人类肉眼的感知范围。由于许多地标物质的吸收特性都表现在400纳米到2 500纳米的光谱分辨率内,所以多光谱成像可以识别许多在可见光图像中不能识别的物质。利用多光谱成像信息能够在农业、森林、海洋、江河、湖泊以及地质勘探等领域中的不同物质成分光谱特征进行区分,为科学的进行资源管理、生态监测、环境保护、城市智能遥感提供新的技术手段。
与普通可见光图像场景分类问题相比,多光谱图像的多标签场景分类的难点有两个:一是输入的数据不再是三通道的图像数据,而是多维度的光谱数据,在提供了更多信息量的同时也带来的更高的计算量;二是由于一张多光谱图像往往包含多种地物,所以多光谱图像的多标签分类比单标签分类更能反映其所包含的地物信息,由于每种地物在整张多光谱图像中的比例不尽相同,如何处理这种不平衡性为多标签分类任务提出了新的挑战。
针对如上提出的多光谱图像的多标签分类任务面临的两大挑战,文中设计了一种卷积神经网络结构既能够处理大于三通道的多光谱图像数据,又能利用在其他大型数据集上预训练好的权重进行迁移学习。从而大大降低了计算量。通过计算数据集内所有标签的共现矩阵而得到的损失函数很好的解决了每种地物在整张多光谱图像中的比例不平衡问题,大大提高了分类结果的准确率和召回率。
1 基于CNN的多光谱图像分类
1.1 卷积神经网络
卷积神经网络由生物学家休博尔和维瑟尔在早期关于猫的视觉皮层的研究发展而来。最近几年,卷积神经网络在大规模图像和视频识别以及自然语言处理和语音识别领域取得了巨大的成功,这主要源自于两个重要因素:一个是大规模的高质量数据集,比如ImageNet[2];二是大规模并行计算系统,特别是图形计算单元(GPU)的快速发展和并行程序模型和软件环境比如Compute Unified Device Architecture(CUDA)。卷积神经网络通过堆叠卷积层、池化层、非线性激活函数层、批量归一化层,来进行特征抽取,利用参数共享机制相比于反向传播(Back Propagation,BP)神经网络大大减少了参数个数,其局部视野的特性保证了能够抽取不同层次的特征表达,相较于传统的人工精心设计的特征表达,实现了端到端的训练。
卷积神经网络最先取得成功是AlexNet[1]在2012年的ImageNet竞赛上,其以比以往最低错误率低10个百分点的成绩夺冠,网络一共有8层可学习层,包括5层卷积层和3层全链接层,并且引入了修正线性单元(Rectified linear units,ReLU)、池化、数据增强、Dropout的操作,在增强模型表达能力的同时很好避免了过拟合的发生。之后的VGGNet使用了更小的卷积核、更深的网络深度,直观上我们会觉得大的卷积核更好,因为它可以提取到更大区域内的信息,但实际上大卷积核可以用多个小卷积核代替,比如一个7×7的卷积核函数就可以用3个串联的3×3的卷积核来代替,这种代替方式在减少了参数个数的同时也引入了更多的非线性因素。所以VGGNet相比于AlexNet层数更深却可以更快的收敛。本文在设计网络结构时充分借鉴了小卷积核的优点。ResNet[3]是卷积神经网络发展的另一个里程碑,其通过引入残差的概念让网络不直接拟合输入和输出的映射而是去拟合残差,由于残差结构的特殊性,在损失对输入求导的时候,导数项会被分解为两个,而有一个直接对输入的导数项并不会消失,所以避免了梯度消失或者爆炸问题,从而网络可以设计的非常深。DenseNet[4]通过链接操作来结合特征图,使得网络中每一层都与其它层都有关系,这种方式使得信息流最大化,提升了网络的鲁棒性并且加快了学习速度。
1.2 多光谱图像的场景分类
目前学术界针对多光谱图像的场景分类问题大都集中在小训练样本并且类别较少的场景下,所设计场景分类器往往要求能在较小的训练样本下具有很好的泛化能力。
Peng J[5]等人利用理想归一化核(Ideal Regulization Kernel)来训练一个非线性的核函数表达,结合支持向量机(Support Vector Machine)进行分类。谭熊[11]等人利用梯度下降方法计算出多核的线性叠加权重,然后利用多核SVM进行多光谱图像的场景分类。冯逍等人[13]提出了一种基于三维Gabor滤波器进行特征提取然后用SVM进行多光谱图像的场景分类方法。由于核函数具有一定的非线性拟合能力,而且SVM本身良好的泛化能力,以上基于SVM的多光谱图像分类方法在小样本集上取得了不错的效果,但是随着训练样本数据的增加,核函数的越来越不足以表达数据与其标签之间的非线性关系,SVM本身的训练时间也大幅增长,所以基于SVM的核方法不适应较大规模的多光谱图像数据集。M.Lienous等人[15]把通常用于文本语义挖掘的主题模型应用到多光谱图像场景分类问题中。把图片中的某一块映射为文档中的某个单词,把整张图映射为文档主题,然而此方法只在场景类别较少的情况才有较高的准确率。W.Luo等人[16]改进了用于图像分类的主题模型,提出作者主题模型进一步提高了多光谱图像场景分类的准确率,但是任然没有突破只能在场景类别较少情况下才有比较高准确率的局限。M.Fang[7]等人提出了一种利用隐马尔科夫随机场(HMM)进行无监督多光谱图像分类方法,Yao X W[8]等人提出了利用堆栈自动编码机(Stacked Auto Encoder,SAE)对图像进行特征提取然后利用多层感知机(Mutilayer Perceptron,MLP)进行分类。以上两种非监督分类方法的其优点是不需要对图像数据做标注即可自动分类,缺点是无法预定义场景类别而且只在类别很少的场景下才能有较好的准确率。Penatti O A B[6]等人首次提出了利用在非多光谱图像数据集ImageNet所预训练的卷积神经网络在多光谱图像进行迁移学习的方法。刘杨等人[14]提出了一种媒体神经认知模型,其综合了图中上下文场景的语义信息进行预分类,利用预分类结构构造惩罚函数,然后用增量式集成学习获得最终的分类结果。许风晖等[10]人提出了利用多尺度卷积神经网络融合的方法进行多光谱图像的场景分类。以上3种方法使用的卷积神经网络层数都比较浅,使用的数据集的场景类别也较少。
随着计算机视觉的发展,更加复杂的卷积神经网络被提出并且在图像分类和自然语言处理等领域发挥出了巨大的作用,如何发掘卷积神经网络在多光谱图像场景分类任务中的巨大潜力是一个值得研究的问题。
2 实 验
2.1 数据集介绍
文中采用了由Planet公司的Flock2卫星于2016年1月至2017年1月拍摄的亚马逊雨林地区的高光谱影像,空间分辨率为3.7米,共计8万张图片。按照6:2:2的比例将此数据集划分为训练集、验证集和测试集。数据的标签由Planet Impact团队提供,多光谱影像包括红、绿、蓝和近红外共4个通道的光谱数据,共17个类别,包括有primary、haze、algriculture、clear、water、habitation、road、cultivation、slash、burn、cloudy、partly cloudy、conventional mine、bare ground、 artisinal mine、 blooming、 selective logging、blowdown。数据集中的每一张图片都包含了至少一个标签。
2.2 卷积神经网络结构设计
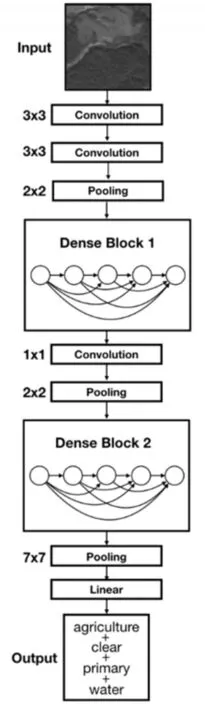
图1 本文设计的卷积神经网络结构图
文中设计的卷积神经网络如图1所示,为了保证模型的非线性,每个卷积层之后都跟着一个非线性激活函数层,本文所使用的是修正线性单元ReLU,ReLU可以加速网络的收敛[1]。为了进一步防止模型过拟合,每一步卷积操作之后都接一个批量归一化层(Batch Norm,BN)[9],BN层可以有效减轻模型的过拟合。网络的输入时256×256×4的多光谱图像经过填充为2,步长为3,卷积核大小为3的卷积之后特征图的大小为76×76×64,再经过填充为4,步长为3,卷积核大小为3的卷积之后得到的特征图大小为28×28×64,紧接着是步长为2的最大池化层操作,其后是2个Dense Block,中间加入1×1的卷积和步长为2的最大池化层。Dense Block共有5层,前四层的每一层都是批量归一化层、最大池化层和卷积核为3的卷积层的集合,并不改变特征图的大小,最后一层是卷积核为1的卷积层,用来降低通道数,即降低了模型的参数。对于Dense Block中的每一层来说,前面的所有层的特征图都被直接拿来作为这一层的输入。网络经过Dense Block2之后的特征图大小为7×7×16,接下来的步长为7的最大池化层得到16维的向量,16×17的全链接层输出每种类别的概率。

图2 训练集所有标签的共现矩阵示意图
由于在多标签分类问题中,一张图片可能对应几个标签,但这些标签所对应的物体在图片中所占的比例是不同的,为了处理这种比例的不平衡,与常规的Softmax损失函数不同,本文提出了一种新型的损失函数,计算方法如下:首先计算整个训练集上所有标签的共现矩阵如图2所示。
Softmax层的输出为:

损失函数定义为:

其中yj是根据训练集上所有标签的共现矩阵计算得出。假设一张多光谱图像的标签集合为L,查阅共现矩阵得出L中所有标签共同出现的概率集合P,则L中每一类标签的权重yi的计算方法为:

损失函数定义为:
2.3 实验环境设置
本文所设计的卷积神经网络的实现和训练、测试是基于Tensorflow深度学习框架。
为了防止网络过拟合,在训练集原始图像输入网络之前,进行数据增强,具体做法如下:原始256×256的图片的4个角以及中心区域截取224×224的区域加上自身经过缩放到224×224,然后经过水平和垂直翻转,这样我们的训练数据量是原始的6×2=12倍,在测试阶段只对图片做缩放以获得最完整的图像信息。
在训练阶段,网络的两个Dense Block采用在Imagenet上预训练的DenseNet 121的最后两个Dense Block的权重作为初始值,其余层的初始参数皆用标准正态分布生成。文中采用带动量的逐参数适应随机梯度下降算法Adam,设置网络的初始学习率为0.001,批处理大小为64,动量为0.9。
文中采用F值作为实验结果的评价标准:

其中:
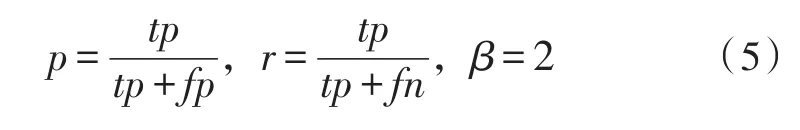
这里p为准确率,r为召回率,tp为真阳数,fp为假阳数,fn为假阴数。
2.4 实验结果与分析
文中同时实现了在多光谱图像分类任务中特征提取表现出色的尺度不变特征变换(Scale Invariant Feature Transform,SIFT)[12]+SVM以及文献[13]提出的Gabor滤波器+SVM和文献[8]提出的SAE+MLP与本文提出的方法进行比较,结果如表1所示。

表1 不同方法结果对比
由上述实验可以看到,结合复杂的卷积神经网络进行特征提取和重新定义的损失函数在Planet Amazon多光谱图像多标签分类任务中取得了最高的F值。与不加经过共现矩阵重新定义的损失函数的CNN相比,重新定义的损失函数让F值提高4个百分点,从而说明了本文提出算法的有效性。
3 结论
文中提出了一种基于卷积神经网络的多光谱图像多标签场景分类方法,在模型设计过程中多次用小的卷积核来减少参数个数,降低了模型的复杂度,减少过拟合现象的发生,模型中的直连操作保证了信息流的最大化,从而避免了梯度爆炸或是消失的问题。在训练集所有标签的共现矩阵基础上重新定义的损失函数进一步提高了模型的F值,在Planet Amazon数据集上的试验以及与其他文献中的方法进行对比验证了所提出的卷积神经网络对于多光谱图像多标签场景分类的有效性。
