基于偏微分分类数学模型的关联挖掘改进技术研究
2018-12-15曹西林
曹西林
(西安铁路职业技术学院陕西西安710026)
目前,数据库已经渗入到社会各行业数据处理中,并且数据技术的发展及数据量的增长使现代人们进入了信息及数据大爆炸的时代中。对于大量的信息及数据,如何实现有效处理,从而找到其中蕴含的知识,是现代相关研究人员的主要研究方向[1]。只是根据数据库查询检索技术已经无法满足人们对于数据信息处理的需求。数据挖掘技术属于能够自动且智能的将未知数据及数据中的隐藏信息转变成为有用知识及技术,并且帮助人员从数据库提取人们感兴趣的知识,对数据进行分析,从而充分使用大量数据中的价值[2]。在对数据不断挖掘的过程中不仅能够掌握传统数据发展的过程中,并且还能够实现未来数据发展趋势的预测。数据挖掘属于全新的学科,其融合多种技术。关联规则属于知识模式中较为活跃的分钟,其在数据挖掘中具有重要的作用,属于数据挖掘技术的研究方向,被广泛应用到行业中[3]。
1 关联挖掘的过程
数据的关联挖掘目标就是利用大量具有噪声及不完全数据集合寻找具有用处的知识及信息处理过程,其主要包括准备数据、挖掘数据及知识评估3个步骤[4]。图1为关联规则挖掘基本的模型。
1.1 数据准备
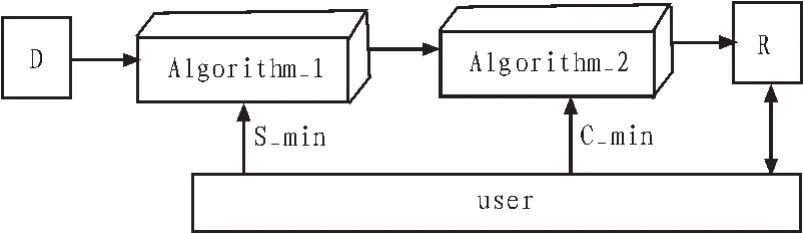
图1 关联规则挖掘基本的模型
此过程主要包括准备数据并且进行整理的过程,比如就业数据具有大量属性,在研究数据模型的过程中,学生的就业信息主要包括性别、民族、专业等,以描述数据库模型,就能够得到学生的就业信息[5],详见表1。

表1 学生的就业信息数据
因为此研究对象源于某三本院校,其中女生较多,所以学生属性主要包括性别及专业,处理不相关的和数据,表2为处理之后的就业数据。

表2 处理之后的就业数据
1.2 算法
关联规则算法属于数据挖掘算法中主要的分析方式,其能够实现数据关联的重点挖掘,寻找满足条件的多个领域依赖关系,广泛在行业领域中使用,尤其包括制造业、零售业及保险业。关联算法的思想就是寻找支持度比最小支持度要大的频繁项集,从此项集中寻找期望规则,此规则要能够满足最小置信度及支持度[6]。在实现关联挖掘的过程中,首先要对事务集记录进行扫描,寻找频繁候选集,然后算出频繁项,以此产生与用户感兴趣的关联规则,图2为关联规则的算法流程。
2 偏微分分类数学模型
2.1 微分方程稳定解
通过Bochner空间实现二阶滞偏微分方程的创建:
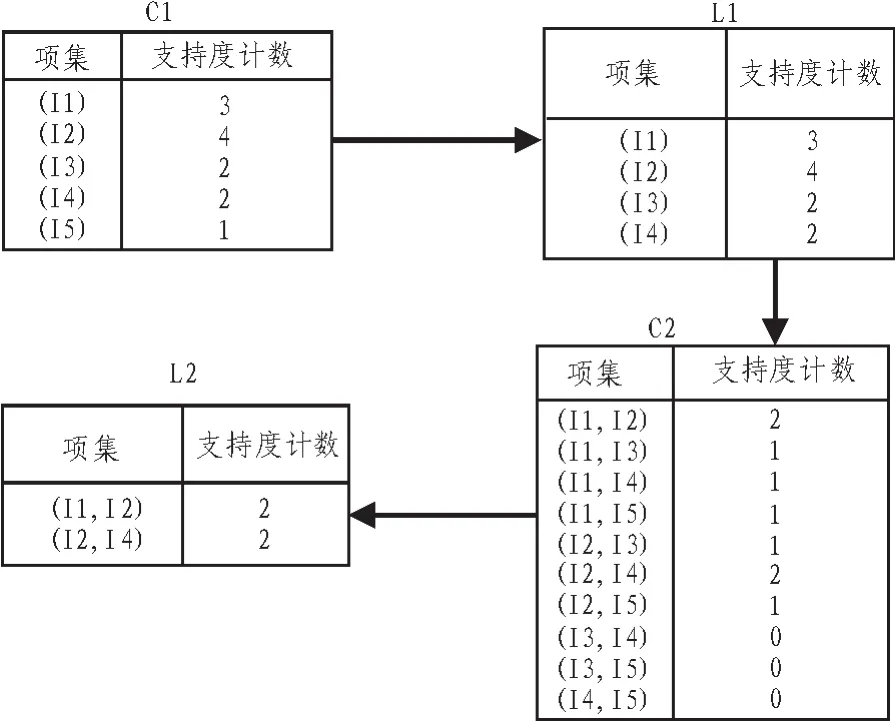
图2 关联规则的算法流程
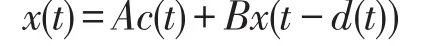
二阶时滞偏微分方程的边界稳定平衡点特征向量为:

基于双边界条件平衡约束,将原点领域N(0)解向量作为初始条件[7],得出二阶时滞微分方程稳定解的参量:
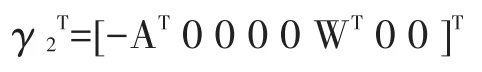
全面考虑二阶时滞微分项双周期性孤立波解,通过稳定解心凉属于大数据分类聚类中心矢量,实现数据分类数学模型的创建。
2.2 约束条件
使用基于偏微分分类数学模型实现关联挖掘,创建关联规则集数学模型,使用渐进有理积分逼近的方法[8],得出偏微分分类一阶偏导函数:
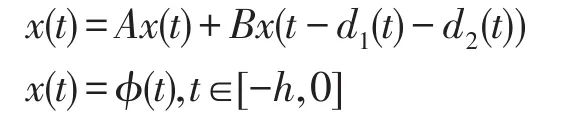
通过二项-泊松模型实现全局渐进稳定性泛涵,以支持向量机模型相互结合实现二阶时滞偏微分数学分类。以凸优化定理,使用随机泛函函数实现一阶导数的求解,从而得出自回归线性的最优解。
利用以上规则集约束能够得出偏微分分类数学模型规则集约束条件,从而降低在大数据分类过程中出现漏分及错分的情况[9]。
3 关联挖掘的改进技术
遗传算法属于高效全局搜索的方法,其具有一定的鲁棒性、随机性及隐含并行性,能够有效实现全局优化搜索。在关联挖掘优化过程中使用遗传算法及偏微分分类数学模型,能够缩短大项集寻找的时间[10],图3为改进关联挖掘的模型结构。
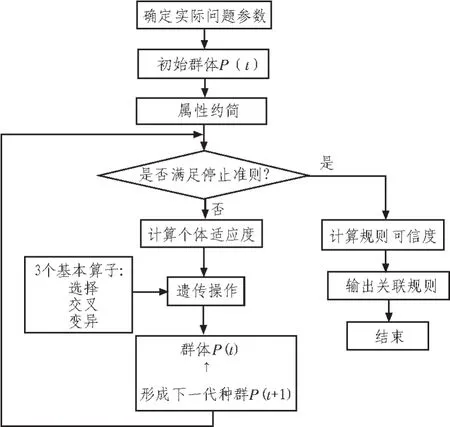
图3 改进关联挖掘的模型结构
关联挖掘改进的主要问题就是编码,基于实数的编码较为简单,并且便于实现,本文以事务数据库实现数据编码,表3为决策信息表。
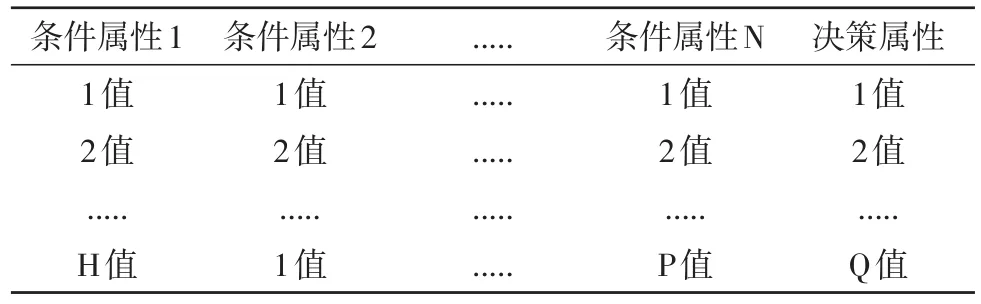
表3 决策信息表
在改进关联规则挖掘的约简属于创新点,但是只是根据关联规则有效性及重要性指标无法实现精准数据挖掘。所以就要提出改进属性约简方式实现属性约简,删除对结论没有效果的属性,之后实现数据关联规则挖掘[11]。
适应度函数属于关联挖掘改进过程中的接口,其是面向应用问题进行设计,其根据不同的解决问题实现不同适应度函数的选择。因为支持度属于关联规则中的主要衡量指标,其表示了规则所有事物中的代表性意义,那么将关联规则支持度实现其适应度函数的定义[12]。
在确定适应度函数之后就要计算个体适应值,之后以适应值为基础从目前群体中对个体进行选择实现交配池的生成。为了避免因为选择误差导致群体最佳个体丢失,可以使用精英保留轮盘赌的方式进行[13]。
4 改进结果
表4为多种挖掘算法的结果,通过表4表示,本文所研究的关联挖掘改进技术能够解决传统算法效率较慢的问题,并且在最小支持度阈值增加的过程中,规则数在不断的降低。

表4 多种挖掘算法的结果
利用Quset实现大型综合数据库的生成,之后从中取样实现区分数据库的取样,为了能够降低不同实验过程中的依赖性,取样数据库规模要比原始数据库小。为了避免挖掘过程中出现危险,就要实现minFreq值的扫描,对通信负载进行测量,假设支持数编码为4字节,项项目集数编码为2字节[14]。图4~6为不同数据库通信负载,以此表示,3个算法的对比,其中两个使用通信比较少。对于负载数据库,DDM和PDDM行为相同,并且DDDM最好。
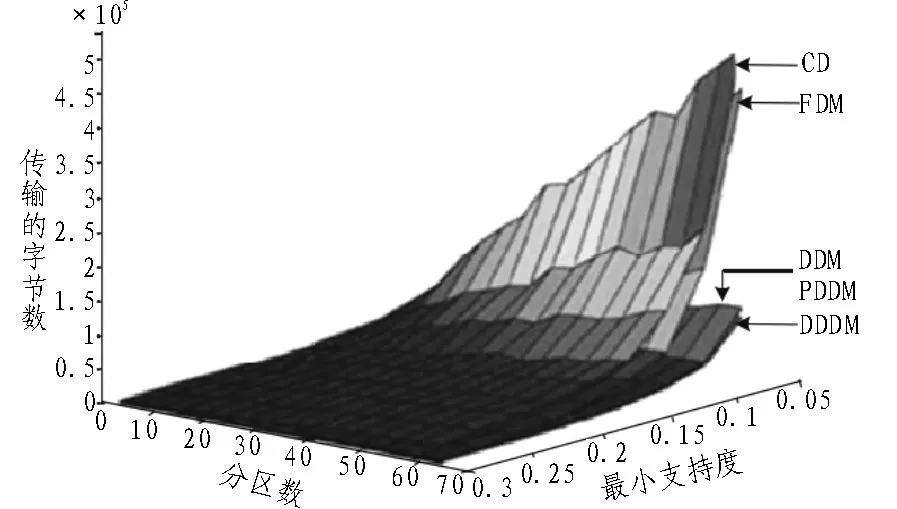
图4 传输字节数、分区书、最小支持度和通信负载的联系
首先对缓冲区大小变化进行检查,通过结果表示其和理想网络环境和缓冲区中的网络结果没有太大的差别。结果表示,算法在字节数发送方面良好[15]。
图6中表示了缓冲区发小和字节数发送的关系,对缓冲区来说,假如具有大量的候选基,那么算法发送字节及信息要低于FDM。假如候选基集小,那么发送信息为半空,FDM就会具有一定的竞争力。
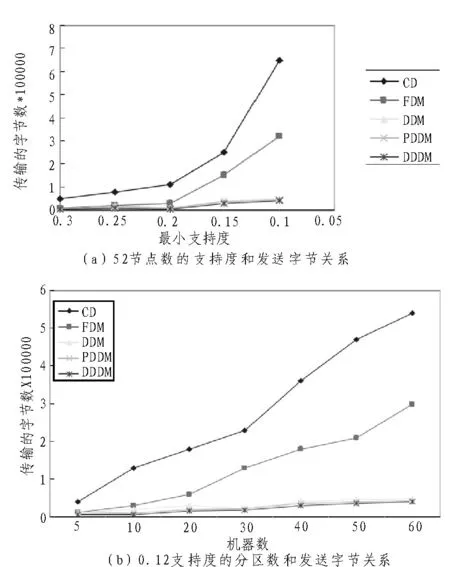
图5 支持度、节点数、分区书和发送字节的关系
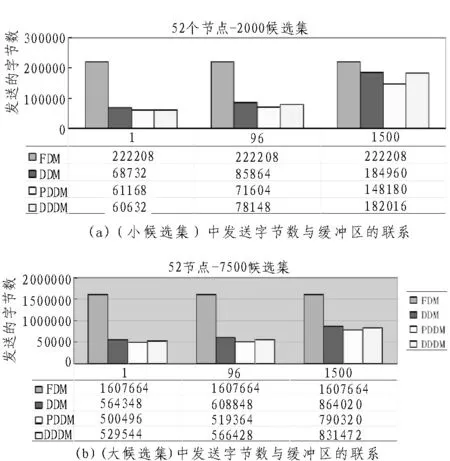
图6 发送信息数、字节数和信息使用率与缓冲区的变化联系
通过实验结果表示,本文提出的基于偏微分分类数学模型的关联挖掘改进技术能够解决通讯复杂性问题,此算法和其他算法相比,能够保证同一增长率。
5 结束语
在现代信息不断增加的过程中,网络数据域数据库创建的需求也在不断的增加,以此扩大了数据信息处理的规模。所以,如何实现高效其快速的数据挖掘,属于现代领域中需要解决的问题。本文所设计的关联规则挖掘优化,能够提高算法的效率,降低对象扫描数据集的共工作量,能够在企业删选评估中使用。
