基于科优先策略的植物图像识别
2018-12-14曹香滢孙卫民朱悠翔李晓宇
曹香滢,孙卫民,朱悠翔,钱 鑫,李晓宇,业 宁
(1.南京林业大学 信息科学技术学院, 南京 210037; 2.江苏省住房和城乡建设厅住宅与房地产业促进中心,南京 210009)(*通信作者电子邮箱yening@njfu.edu.cn)
0 引言
植物是生命的主要形态之一,与人类的生活密切相关,对其进行分类识别在生物多样性保护、生态农业、生物安全中有着重要的意义。目前,对植物种类的识别大部分仅依靠有经验的专家和相关行业从业人员进行人工识别,识别结果与领域专家的知识和实践密切相关,这种方法费时费力、效率低下。计算机自动识别一直是计算机视觉的一个重要应用,植物图像识别也备受关注。
传统的植物图像识别方法主要是通过人工干预,由人提取特定的特征,如叶片、花的形状、颜色、叶脉纹理、边缘轮廓等,然后根据这些特征或它们的组合,使用各类分类器进行分类。王丽君等[1]基于叶片图像多特征的融合,提取颜色、形状和纹理特征,使用支持向量机(Support Vector Machine, SVM)算法[2-5],识别率为91.41%; 邓立苗等[6]针对玉米叶片单独进行了 48 个叶片特征的提取,使用SVM算法,识别率达到了96%; Naresh等[7]运用改进的局部二进制模式(Modified Local Binary Pattern, MLBP)提取叶片的纹理特征,在4个单一背景数据集上分别获得了93.62%、97.55%、90.62%、96.83%的识别率; Chaki等[8]将叶片纹理、形状特征结合起来,对多个实验测试识别效果, 最高获得了67.7%的识别率; Jin等[9]分割了叶片图像的背景,检测叶片的轮廓、边缘和叶片锯齿特征,在自然环境数据集上获得了76.3%的平均正确率; Olsen等[10]提取植物叶片的纹理特征,并自己建立植物图像数据集,获得了86.07%的正确率; Ghasab等[11]使用蚁群优化(Ant Colony Optimization, ACO)作为特征选择算法对2 050种树叶图像获得95.53%的识别率。
尽管传统的植物图像识别方法的研究取得了许多进展,但事实上用人工选择的特征不一定能很好地进行植物识别,因为人在选择特征时都是靠经验的,具有很大的盲目性,而且这些特征都是针对特定数据和特征提取技术设计的,如果用同样的特征来处理不同的数据集,结果可能大相径庭,因此这种特征具有不可迁移性; 同时传统方法对于复杂背景拍摄下的自然环境图像识别率明显降低。随着深度学习[12]的发展,基于深度学习的方法在图像识别领域取得了很好的结果。基于卷积神经网络(Convolutional Neural Network, CNN)[13]的深度学习算法可以自动提取图像特征而不需要人工干预,很好地克服了传统的植物叶片识别人为提取特征的缺陷。
近年来,许多研究基于深度学习方法,利用植物的叶片、花朵等图像对植物进行识别。Liu等[14]利用5层卷积层及3层全连接层(Fully Connected layers, FC)的CNN自动学习优秀的特征来进行花朵分类,在两个自然环境数据集上分别获得了76.54%和84.02%的识别率; Grinblat等[15]建立了5层的CNN模型,自动识别叶片纹理图像,获得了92.6%的平均正确率; Barré等[16]建立了14层的CNN,从树叶图片学习特征取代手工特征,对单一背景数据集识别率达到了97.9%;Pawara等[17]提出将不同分类器的视觉词与深度卷积神经网络相结合,在多个植物数据集上均获得比使用SVM更高的识别率; Jeon等[18]提出基于GoogleNet[19]的多维度分类模型,在纯叶片的数据集上获得了94%的识别率。这些研究中,对单一背景图像的识别取得了很高的识别率, 然而,对复杂识别背景的自然环境图像的识别准确率比较低。
为了提高精度和改善深度卷积神经网络的过拟合问题,本文借鉴现代植物分类学理论,提出科优先(Family Priority,FP)的植物分级识别方法,学习关键性的特征。首先判断植物所属的科,进一步得到它的种类, 将其与卷积神经网络MobileNet[20]相结合,搭建科优先植物识别模型(Family Priority MobileNet, FP-MobileNet); 然后利用迁移学习[21]的方法,对MobileNet网络的结构进行微调,通过训练网络权重获得植物识别模型。实验使用了单一背景植物叶片数据集flavia[22]和自然环境花卉数据集flower102[23]。实验结果表明,对于flavia,卷积神经网络VGG16[24]和MobileNet的识别率分别为 97.3%和99.8%,均高于传统方法的识别效果;而对于更具挑战的自然环境数据集flower102,FP-MobileNet模型获得了最高的识别率99.56%,并且该模型同时保持了较小的权重大小,适合推广到移动设备应用。
1 相关工作
植物识别领域包括两类问题:单一背景图像识别和自然环境图像识别问题。由于拍摄照片时模糊、噪声、复杂背景等问题的存在,自然环境图像识别难度更大。基于CNN的深度学习方法发展迅速,应用在植物识别领域也取得了很好的效果。
为了提高识别精度,当前卷积神经网络的发展趋势主要有增加网络的深度和宽度,以及构造新的模型结构,如VGG16[24]、GoogleNet[19]、ResNet[25]等。VGG16是由Simonyan等提出的用于大型图像识别的深层卷积网络,网络结构如图1。VGG16由AlexNet[26]发展而来,网络共16层,提出使用小滤波的组合,加深了网络的层次。
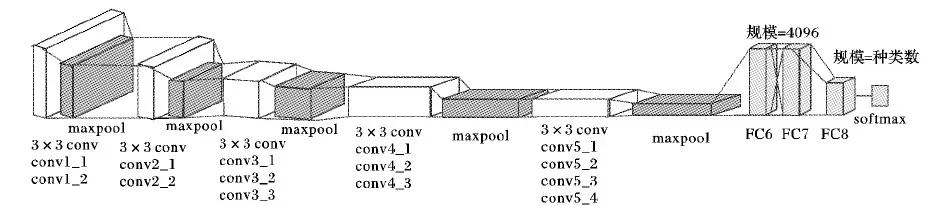
图1 VGG16模型结构
GoogleNet网络共22层,为了在扩大网络的同时尽可能地发挥计算性能,使用稀疏网络结构,提出加大网络宽度的Inception模块,结构如图2所示,既保持了网络结构的稀疏性,又能利用密集矩阵的高计算性能。

图2 Inception模块
网络深度的加深带来的退化问题会导致系统优化困难。ResNet提出引入深层残差学习框架来解决退化问题。网络提出Residual结构,如图3,将拟合目标函数H(x)转换为拟合F(x)+x, 通过残差结构起到优化训练的效果,改善了深度网络退化的问题。

图3 Residual结构
虽然随着研究的发展,深度卷积神经网络在提高精度和改善网络性能上取得了很大的进展,但是深度网络结构复杂,训练耗时长,模型规模巨大,并且在训练集规模不够大时容易出现过拟合的问题。轻量级网络模型MobileNet兼顾了资源和精度,在保证较高精度同时,优化延迟,降低模型的大小。为了改善过拟合的问题和提高模型对自然环境植物图像的识别率,本文提出基于科优先策略的植物识别方法,并将其与MobileNet模型相结合,搭建FP-MobileNet模型,得到植物识别模型。
2 科优先的植物识别模型
2.1 交叉熵损失函数
本文采用交叉熵(cross-entropy)作为损失函数对目标网络进行优化。由于激活函数Sigmoid在上边界和下边界斜率值下降得很快,传统的方差损失函数使得模型的收敛速度变得非常慢; 而交叉熵为对数函数,使得在接近边界时,模型的收敛速度不会受到影响。将网络的n个输入图像记为{X1,X2,…,Xn},对应的正确标签为{y1,y2,…,yn},共k类。交叉熵公式为:
(1)
其中σi表示激活函数sigmoid的值:
2.2 科优先的植物分级识别方法
科优先的植物分类方法首先由Jean Baptiste Lamarck[27]在1778年提出。按照现代植物分类学,植物的逐级分类如图4所示,植物学家按照“门纲目科属种”分级方式对植物进行分类,其中植物所属的科对于区分植物种类十分重要,因此植物学家首先根据植物关键特征找到它所属的科,然后确定物种。事实上,属于同一科的植物往往形态上比较相似,如图5,同属锦葵科的朱槿和木槿在形态上极为相似。

图4 现代植物逐级分类方法
Fig. 4 Modern plant classification gradual strategy
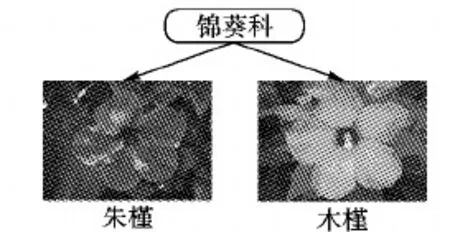
图5 同属于锦葵科的朱槿和木槿
为了改善深度卷积神经网络存在的过拟合问题,获得更好的识别效果,除了在网络中引入dropout[28]以外,本文借鉴植物学家的植物分类学理论,提出科优先策略(FP)模型,优化网络结构,该模型可以应用于深度学习模型。引入植物的科标签作为监督学习的另一个学习目标来学习,搭建FP-MobileNet网络模型。实验证明引入科优先方法后模型的识别精度提升,泛化能力提高。
FP模型通过CNN得到科标签的预测结果。由于单独训练各科的CNN资源消耗巨大,提出运用多任务学习[29]的方法,降低网络规模。模型结构如图6所示,通过一个CNN得到两组预测输出:科标签和种标签。网络训练时,同时完成对科标签和种标签两个维度的预测。科标签的引入有助于进一步对种标签训练的优化。在优化时,网络同时最小化科标签和种标签的交叉熵损失函数。由于有的植物科标签的关键特征易得到,有的植物则是种标签的关键特征易得到,两个任务同时进行优化,可以实现相互促进,进而使模型识别精度提升。
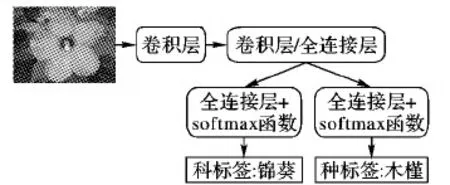
图6 FP模型结构
然而,由于网络打破了植物分级结构,可能存在科标签与种标签结果矛盾的情况,如某植物图像的预测结果中种标签为朱槿而科标签不是锦葵。为了解决这一问题,优化时对于科、种相一致的情况,使用标准的交叉熵损失函数,如式(1);否则将该交叉熵损失函数值赋值为0,忽略它的输出结果。将第i个输入图像记为Xi,yci表示预测的种标签,yfi表示预测的科标签,则交叉熵值为:
具体的科优先策略模型算法如下所示。
算法 科优先策略模型算法。
输入 图片X;
输出 预测结果y。
1)
forXiinXdo
2)
tmpi= model.train(conv+conv/fc)(Xi)
3)
yfi= model.train(fc+softmax)(tmpi)
4)
yci= model.train(fc+softmax)(tmpi)
5)
end for
6)
forXiinXdo
7)
ifycimatchesyfithen
9)
else
10)
Hi= 0
11)
end if
12)
updateW
13)
end for
2.3 FP-MoblieNet模型的建立
MobileNet是谷歌提出的一个适用于移动嵌入式的高效模型。它基于流线型架构,使用深度可分离卷积来构建轻量级深度神经网络,将标准卷积分解成一个深度卷积和一个点卷积(1×1卷积)如图7所示, 其中:K为卷积核的长和宽,M为通道数,N为卷积核的数目。深度卷积将每个卷积核应用到每一个通道,而1×1卷积用来组合通道卷积的输出。MobileNet模型引入了两个简单的全局超参数宽度乘数α和分辨率乘数β,因此可以平衡延迟和精度。
本文使用预训练的MobileNet模型,根据使用的数据集,运用迁移学习的方法建立了MobileNet植物识别模型。FP模型与卷积神经网络是兼容的,如图6,将CNN模型MobileNet转换为科优先的方法形式,建立FP-MobileNet,每个图像输入得到科标签和种标签两个输出,根据交叉熵损失函数进行优化,训练网络。

图7 标准卷积分解过程
3 实验与分析
3.1 植物图像数据集
flavia[22]是一个单一背景植物叶片图像数据集, 包括32种植物共1 526幅叶片图像,每类包括51到76张图像,均为白色背景上有唯一的叶片图像。在数据集中随机选择1 103幅图像作为训练集,423幅图像作为测试集。
flower102[23]是一个自然环境花卉图像数据集,包括102种花卉,每类包括40到258张图像,共8 189张图像,均在自然环境下拍摄。按两种方案进行训练集和测试集的划分:方案一在数据集中随机选择6 149幅图像作为训练集, 2 040幅图像作为测试集; 方案二随机选择2 040幅图像作为训练集,6 149 幅图像作为测试集。当训练集的图像数量少于测试集时,研究具有更大的挑战性,从而进一步验证模型的识别率和泛化能力。

图8 数据集图像示例
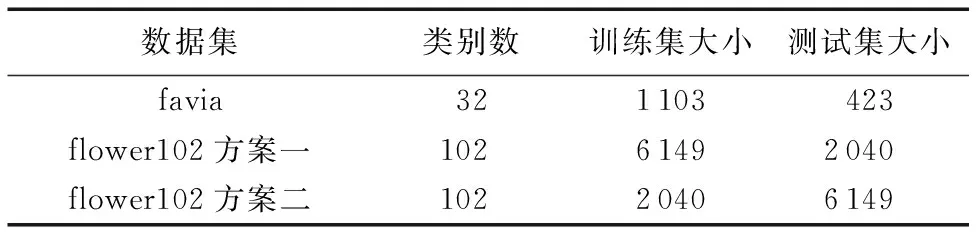
数据集类别数训练集大小测试集大小favia321103423flower102方案一10261492040flower102方案二10220406149
3.2 卷积神经网络对单一背景植物的识别
验证深度卷积神经网络对单一背景植物图像的识别率,将卷积神经网络VGG16和MobileNet对flavia数据集进行识别,进行对比的传统方法有两种,分别是:概率神经网络(Probabilistic Neural Network, PNN)[22]和结合灰度共生矩阵(Gray-Level Co-occurrence Matrix, GLCM)、空隙度(lacunarity)和Shen特征的模型[30]。从表2可以看出,目前传统方法与深度学习方法对单一背景植物图像的识别研究已经达到了较高的水平,并且卷积神经网络通过对图像端对端的学习,可以达到比传统方法更好的结果。

表2 数据集flavia上各方法的识别结果
3.3 FP-MobileNet模型对自然环境植物的识别
表3给出了FP-MobileNet和MobileNet在flower102数据集上的识别结果。由于图像背景复杂,flower102数据集的识别挑战性更大。按照方案一和方案二不同的数据集划分方法,FP-MobileNet的识别率分别为99.56%和95.56%,均高于单纯使用MobileNet模型的识别结果。在训练集规模小于测试集的方案二划分方法下,FP-MobileNet仍取得了95.56%的识别率,表明该模型具有很好的自然环境植物识别效果和泛化能力;同时,比较两种模型的权重发现,FP-MobileNet保持了MobileNet权重规模小的特点。实验结果表明,FP-MobileNet作为轻量级网络,具有较低权值和较高识别率的优势,适合推广到移动设备上使用。

表3 数据集flower102上各方法的识别结果
4 结语
本文利用迁移学习的方法,借鉴现代植物分类学理论,提出了科优先的植物分级识别方法,并与MobileNet相结合,搭建植物图像识别模型FP-MobileNet。在相对容易的单一背景数据集上,深度学习模型MobileNet获得了比传统识别方法更好的识别结果。对于更具挑战的自然环境植物图像, FP-MobileNet模型在训练集规模小于测试集的情况下,仍取得了95.56%的正确率,高于单纯使用MobileNet网络。该模型改善了卷积神经网络的过拟合问题,降低了权重大小,提高了对自然环境植物图像的识别率和泛化能力。在数据集flower102上FP-MobileNet模型的权重仅占13.7 MB,在保持较高识别率的同时有效降低了模型的权重空间,适合向需要轻量模型的移动设备推广。
下一步将进一步研究如何提高卷积神经网络对具有复杂背景的自然环境图像的识别准确率,并研究更高效的科优先植物识别方法。
