基于深度卷积神经网络的色素性皮肤病识别分类
2018-12-14何雪英韩忠义魏本征
何雪英,韩忠义,魏本征
(山东中医药大学 理工学院,济南 250355)(*通信作者电子邮箱hxy0104@163.com)
0 引言
皮肤作为人体最大的器官,通常直接暴露在空气中,使得皮肤病成为人类最常见的疾病之一,全世界30%~70%的人有与皮肤有关的健康问题[1],仅在美国,每年就有540万新的皮肤癌病例[2]。黑素瘤(melanoma)作为一种致死率最高的恶性皮肤肿瘤,每年导致的死亡人数就超过9 000[3]。早期发现可以将黑素瘤的5年存活率由14%提高至99%左右, 因而皮肤病的早期诊断、早期治疗至关重要。
临床上,皮肤病的早期诊断除一般的视觉筛查外,基于皮肤影像的皮肤病诊断是最常使用的一种诊疗手段。相比其他皮肤影像,皮肤镜通过消除皮肤表面的反射,可以将更深层次的肉眼无法辨别的病变特征可视化,和肉眼检查相比,可以将诊断敏感性提高10%~30%[4],在一定程度上降低了活检率。但基于人工的皮肤镜图像分析不仅耗时、费力,诊断结果易受医生经验等主观因素影响。借助于计算机辅助诊断(Computer-Aided Diagnosis, CAD)系统,实现基于皮肤镜图像的皮肤病的自动识别分类,可以提高诊断的效率和准确率。而精准地细分类,使得医生可以根据不同病变的特殊临床表现有针对性地制定最佳治疗方案, 因而具有重要的现实意义和临床研究价值。
然而,基于皮肤镜图像的皮肤病的自动识别分类是一项非常有挑战性的工作:一方面,各种分类识别算法模型存在一定的局限性,总体识别率还有待进一步提高;另一方面,皮肤镜图像会包含诸如光照不均、黑框、毛发、皮肤纹理等噪声,也在一定程度上影响了皮肤病变的识别,但更重要的是,皮肤病变的临床和病理类型繁杂,病灶外观的类间相似度高,类内差异性大,如图1所示, 而且当病灶发生病变时,外观变化比较大,甚至可以演化为其他病变类型,给皮肤病的识别分类带来了巨大的困难。
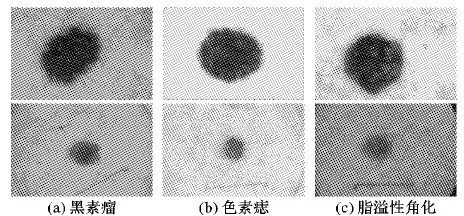
图1 三类色素性皮肤病变
色素性皮肤病是由于黑素细胞和黑素生成异常造成的一类常见皮肤疾病,色素的减少或增多会引起皮肤颜色的改变,因此,色素性皮肤病的识别分类难度更大。本文自动分类的三类色素性皮肤病变:黑素瘤、色素痣(nevus)和脂溢性角化病(seborrheic keratosis),就是三类临床上极易混淆的病变类型,如图1所示。它们均属于皮肤表面发生的色素性损伤,其中黑素瘤属于恶性程度极高的一类肿瘤,色素痣属于良性肿瘤。由于二者均是来源于黑色素细胞的一类肿瘤,临床表现往往非常相似,尤其是当色素痣发生病变时,更加难区分。脂溢性角化病也是一种良性肿瘤,但由于增生的表皮细胞内常常有黑色素的沉着,发生炎症或受刺激的损害与恶性黑色素瘤非常相似,临床上通常需要通过组织病理检查来鉴别。
有关自动分类色素性皮肤病变图像的研究早在1987年就已出现在文献[5]中。随着皮肤镜技术和机器学习算法的发展,基于皮肤镜图像分析和传统机器学习算法的皮肤病分类逐渐成为了一种趋势:文献[6]在分割病灶后,提取形状、颜色、纹理等特征信息,运用集成分类器实现黑素瘤的检测; Barata等[7]对比说明了颜色和纹理特征在黑素瘤检测中的不同作用; Sheha等[8]从分割的感兴趣区域提取几何和色度特征,利用Fisher和t检验方法选取最优特征用于人工神经网络和支持向量机分类,实现了色素性皮肤病的诊断。值得注意的是,这些方法涉及一系列的图像预处理、特征提取和选择等繁杂且效率低下的问题,特征的设计受限于领域专家的专业知识,要提取出具有区分性的高质量特征往往存在一定的困难,有意义和有代表性的高质量特征是皮肤病识别分类成功的关键因素。
随着深度学习的发展,尤其是卷积神经网络(Convolutional Neural Network, CNN)在计算机视觉领域的成功应用[9],为CNN在医学图像处理领域中的应用奠定了基础。深度学习是“端到端”的模型,直接学习从原始输入到期望输出的映射,避免了传统机器学习算法中复杂的特征提取过程,而且能够提取具有代表性的高层特征,尤其在细粒度图像识别方面具有极大的优势和潜力。斯坦福大学人工智能实验室采用深度学习方法对皮肤镜图像和临床皮损图像进行自动分类,充分利用细粒度标签的优势训练CNN-PA(CNN-Partitioning Algorithm)模型,对129 450幅皮肤镜和临床皮损图像进行3分类和9分类,精度分别可达72.1%和55.4%,利用3类和9类标签训练的CNN粗分类结果分别为69.4%和48.9%,而两位皮肤病专家在相应分类任务上的平均识别结果分别为65.8%和54.15%,代表了皮肤图像自动分析领域的最新研究进展,相关研究成果[10]2017年1月发表在Nature上,本文的研究在一定程度上受到该研究的启发。文献[11]结合深度学习和机器学习方法,设计了一个用于皮肤病灶分割和分类的系统; Mishra等[12]在总结对比基于皮肤镜图像的各种分割算法的基础上,进行了黑素瘤的检测; 文献[13]利用VGG16网络,采用三种不同的迁移学习策略,实现了皮肤镜图像的二分类任务,取得了较好的结果; Li等[14]利用两个全卷积残差网络同时实现了皮肤病灶的分割和分类; 文献[15-17]采用常用的深度学习模型实现了黑素瘤的检测。然而,这些方法大都集中在皮肤病发病率较高的国家,且主要针对黑素瘤检测相关的二分类识别,我国在这方面的研究相对较少,还缺少一个完整的针对色素性皮肤病的识别分类系统。
基于以上问题,本文训练了一个结构化的深度卷积神经网络模型,实现了基于皮肤镜图像的色素性皮肤病的自动识别分类。通过给不同类别设置有差异的损失函数权重来缓解数据集中存在的类别不平衡问题,提高模型的识别率,算法流程如图2所示。采用数据增强方法[18]和迁移学习[19]来避免深度学习模型在受样本量限制时易出现的过拟合问题。

图2 模型流程
1 数据增强和迁移学习
缺乏大规模的训练数据,是CNN应用于医学图像分类面临的主要挑战之一。深度卷积神经网络强大的表达能力,需要大规模的有标记样本来驱动模型训练,才能防止过拟合。本文所采用的数据集中,训练集仅包含2 000幅标记图像,为避免过拟合,本文采用了常用的两种解决方案:
1)数据增强。使用不小于0.5倍原图大小的正方形在原图的随机位置处抠取图像块;对图像进行随机的水平和垂直翻转及镜像。通过数据增强扩充了训练样本的数量,增加了训练样本的多样性,不仅能够避免过拟合,还可以提高模型的识别性能。
2)迁移学习。通过迁移学习,模型可以获得优化的初始参数,从而加快训练的速度,提高模型的识别率和泛化能力。本文使用ImageNet(约128万幅自然图像,1 000种类别)上预训练好的VGG19模型,迁移到我们的数据集上进行微调训练。本文将模型输出类别数设置为3。
2 深度卷积神经网络架构
卷积神经网络是一类特殊的人工神经网络,作为最常使用的深度学习模型之一,被广泛应用于图像处理相关领域。以二维或三维图像直接作为网络的输入,通过多个隐层结构的变换,实现高层次特征的提取。这种端到端的自动学习特征的过程,避免了人工提取特征的繁杂和局限。相比全连接的神经网络,训练更简单,泛化能力更好。
通过初步实验,对比目前常用的深度卷积神经网络模型AlexNet、ResNet、GoogLeNet等,以VGGNet[20]作为本文模型的基础架构,如图3所示。该模型在ILSVRC2014竞赛中获得定位任务的第1名和分类任务的第2名,具备良好的稳定性和泛化性,被广泛应用于细粒度图像定位与检索[21]。

图3 VGG19结构
2.1 网络架构设计
输入层 负责从数据集载入图像,产生一个输出向量作为卷积层的输入。本文模型加载增强后的数据集,RGB3通道皮肤镜图像,图像进行归一化预处理,减去训练集图像像素均值,自动缩减为224×224大小,以适应VGGNet。
卷积层 卷积层的单元组织为特征图(feature map),每个单元通过一定大小的卷积核作用于上一层特征图的局部区域,局部区域的加权和经过ReLU非线性单元处理,获取图像的局部特征。同一特征图的所有单元共享一个卷积核,而同一层的不同特征使用不同的卷积核。
本文的VGG19模型包含5个卷积块(block),第1、2块内有2个卷积层,其余3块内有4个卷积层,所有卷积都使用ReLU非线性激活函数。5个block的卷积核数量分别为64、128、256、512、512,每块内的卷积核数目相同。卷积层全部为3×3的小卷积核,采用保持输入输出大小相同的技巧(stride、padding均设为1),在增强网络容量和模型深度的同时减少了卷积参数的数量,降低了计算复杂度。
池化层 通过将语义上相似的特征点合并,实现特征降采样,以减小下一层的输入大小,从而减少网络的参数个数,减小计算量。常见的策略有最大池化(Max-pooling)、平均池化(Mean-pooling)和随机池化(stochastic pooling)。本文模型中每个block后面都连接一个最大池化层,大小为2×2。
此外,学习率为0.001,训练epoch为100。
2.2 加权Softmax损失函数

(1)

Softmax分类器的损失函数如式(2)所示:
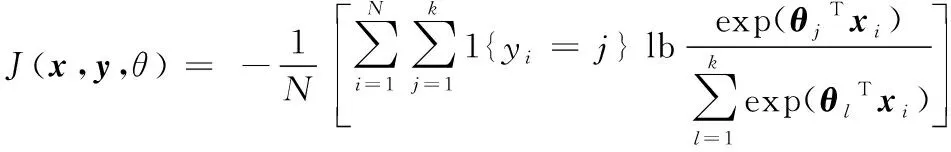
(2)
其中1{yi=j}为指示性函数。其取值规则为:
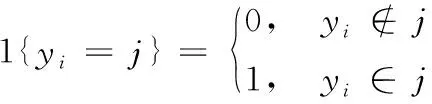
由于不同类别的训练样本数目之间的偏差造成的数据不平衡,是医学图像处理过程中普遍存在的问题。不平衡的训练样本会导致训练模型侧重样本数目较多的类别,而“轻视”样本数目较少的类别,这样模型在测试数据上的泛化能力就会受到影响。
本文通过在Softmax损失函数中设置权重系数w,让小类样本乘以较大的权重,大类样本乘以较小的权重,来缓解本文数据集中存在的类别不平衡问题,从而提高模型的识别率。加权Softmax损失函数可表示为式(3):
(3)
其中:wj=M/Mj表示损失函数的权重,M表示训练样本的总数量,Mj表示训练样本所属类别的样本数量。最后通过随机梯度下降法最小化误差函数。
3 实验与结果
3.1 数据集
本文采用ISIC(International Skin Imaging Collaboration)Archive公开数据集ISIC2017 (https://isic-archive.com/),该数据集包括3个独立的皮肤镜图像数据集:训练集(2 000幅)、验证集(600幅)和测试集(150幅),每个数据集包含三种类型的色素性皮损图像:黑素瘤、色素痣和脂溢性角化病。三种类型的皮肤镜肿瘤图像在三个数据集中的具体分布情况见表1, 实验在数据增强后的数据集上开展。

表1 3种类别的肿瘤图像在三个数据集上分布情况
3.2 评价标准
为全面衡量模型的分类性能,除了采用识别正确率(accuracy)这一常用评价标准外,同时考虑皮肤病识别的召回率,即敏感性(sensitivity)。
敏感性的计算公式:
其中:q表示类别个数,TP表示真正例(True Positive),FN表示假反例(False Negative)。当accuracy和SE的取值都较大时,说明模型具有较好的识别分类性能。
3.3 实验和结果
为保证模型对未知数据的泛化能力,增强后的训练集、验证集和测试集仍为三个独立的数据集,互不交叉。训练过程中利用验证集实时评测模型的预测性能,调节参数,优化模型,最后选取验证集准确率最高的那一轮训练结果作为最终的模型,用于测试集数据的预测。
为验证本文模型的有效性,另外选择ResNet-34[22]和GoogLeNet[23]两种模型作对比实验。为验证设置类别权重对缓解类别不平衡问题的效果,在各个模型上分别采用设置权重和不设置权重两种训练策略。本文模型在Lenovo ThinkStation,Intel i7 CPU,NVIDIA Quadro K2200GPU上训练,使用PyTorch框架。
本文模型与其他深度学习模型在两种训练策略上的实验对比结果见表2,其中w表示训练过程中设置的不同类别的权重。由表2可知本文方法的识别正确率和敏感性值均高于其他方法的对应值,并且在不设置权重时,本文模型的识别正确率和敏感性结果也均高于其他模型的对应结果,表明本文方法的有效性。对比每类方法设置权重和不设置权重的结果可知,敏感性均有所提高,识别正确率除ResNet外也均有所提升,表明设置权重能够一定程度上缓解类别不平衡问题。

表2 不同模型在两种训练策略下的对比结果
三种模型采用两种训练策略时,每一类的具体识别结果对比见图4。由图4可知:本文方法大幅提高了黑色素瘤识别的正确率,同时在均衡另外两类的识别正确率的基础上,提高了它们的平均识别正确率,进一步表明本文方法的有效性。另外,由图4还可以看出,黑素瘤的总体识别正确率偏低,溢脂性角化病和色素痣的识别正确率普遍较高,这和本文数据集的分布有一定的关系,同时也说明黑素瘤与另外两类病变的极度相似性。并且,所有方法的识别正确率均普遍偏低,也表明了色素性皮肤病变的区分难度较大。
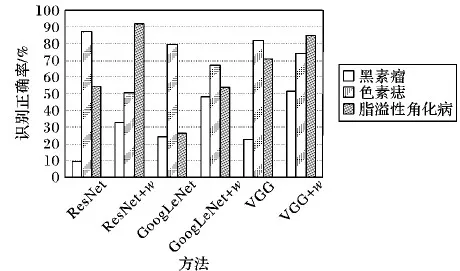
图4 不同方法下每类的识别正确率比较
4 结语
本文研究了色素性皮肤病的计算机辅助诊断,训练了一个结构化的深度卷积神经网络,实现了基于皮肤镜图像的色素性皮肤病的自动识别分类。本文的深度学习模型准确率更高,同时避免了人工提取特征的复杂性和局限性。通过给不同类别样本设置不同的损失权重系数,在一定程度上缓解了数据不平衡带来的问题,提高了模型的性能。采用的数据增强和迁移学习方法有效避免了模型在训练样本不足时易出现的过拟合问题。实验证明本文方法具有较高的识别正确率和敏感性,在一定程度上满足了更高要求的临床需求。
