基于迁移学习与多标签平滑策略的图像自动标注
2018-12-14张奥帆王利琴董永峰
汪 鹏,张奥帆,王利琴,董永峰
(1.河北工业大学 人工智能与数据科学学院,天津 300401; 2.河北省大数据计算重点实验室(河北工业大学),天津 300401)(*通信作者电子邮箱wangliqin@scse.hebut.edu.cn)
0 引言
随着多媒体技术的飞速发展和图像采集设备的日趋便捷,数字图像资源呈爆炸式增长,如何从海量的图像中快速检索出用户感兴趣的资源已成为图像处理领域重要的研究方向。图像自动标注技术实现对图像自动标注反映其语义内容的关键词,从而缩小图像底层视觉特征与高层语义标签之间的鸿沟[1],提高图像检索的效率和准确性,在图像与视频检索、场景理解、人机交互等领域具有广阔的应用前景[2]。但由于“语义鸿沟”问题,图像自动标注仍是一项具有挑战性的课题,一直是计算机视觉领域的研究热点。
图像特征是图像语义内容的一种重要表示,因此图像特征提取方法对于改善图像标注性能至关重要[3]。近几年,以卷积神经网络(Convolutional Neural Network, CNN)为代表的深度学习被广泛地应用于计算机视觉领域,取得了较浅层学习更好的效果。然而,在图像自动标注领域,普遍存在着标准数据集样本数量有限并且标签分布不均匀的问题,造成网络过拟合及标注性能不佳,因此本文通过迁移学习的思想解决图像数据集样本数量有限的问题,通过在网络中加入多标签平滑单元减轻标签分布不均匀问题,从而进一步提高图像自动标注的性能。
1 相关工作
在图像自动标注领域,学者们已提出大量的模型,这些模型大致分为三类:生成模型、最邻近模型以及判别模型。以多贝努利相关模型(Multiple Bernoulli Relevance Model, MBRM)[3]与跨媒体相关模型 (Cross Media Relevance Model,CMRM)[4]为代表的基于生成模型的图像标注方法,首先提取图像的视觉信息(如颜色、形状、纹理、空间关系等),然后计算图像的视觉特征与图像标注词之间的联合概率分布或不同标注词的条件概率分布,最后利用这些概率分布对标注词打分从而完成标注。最近, Moran等[5]提出一种改进的连续相关模型SKL-CRM (Sparse Kernel Learning Continuous Relevance Model),该模型通过学习特征核之间的最优组合,提升了图像标注性能。
最近邻模型以JEC(Joint Equal Contribution)方法[6]、基于度量学习的TagProp_ML (Tag Propagation_Metric Learning)方法[3]和2PKNN(Two-PassK-Nearest Neighbor)方法[7]为代表。这些模型的基本思想是找到与测试图片最相似的若干张图片,并利用这些图片对应标签为测试图片进行标注。其中2PKNN_ML(2PKNN_Metric Learning)方法[8]在找到测试图片的语义近邻图片后,通过度量学习优化特征间距离权重的方法获得较好的标注效果,成为近几年最近邻模型中较先进、较有代表性的方法。在2PKNN模型思想的基础上,文献[9]将CNN作为特征提取器,提出了NN-CNN(Nearest Neighbor-CNN)方法,取得了较好的效果。
判别模型将每一个标签作为一类,将图像标注任务看成是多分类任务,通过训练一个多分类器,将一张测试图片划分到某个标签所属的类别中去。近几年,随着深度学习的不断发展,基于深度CNN的判别模型在多标签图像自动标注领域取得了一定的成绩。文献[10]在CNN模型的基础上,设计了一种基于Softmax回归的多标签排名损失函数网络模型,与传统方法相比有较大提升; 文献[11]将CNN视为特征提取器,并将损失层替换为可进行多分类的支持向量机(Support Vector Machine,SVM)分类器,以适应多标签学习,在其特定的数据集上取得了一定的标注效果; 文献[12]提出了基于线性回归器的CNN-R(CNN-Regression)方法,该方法通过反向传播(Back Propagation, BP)算法优化模型参数,取得了一定效果; 文献[13]提出了CNN-MSE(CNN-Mean Squared Error)方法,该方法设计了基于多标签学习的均方误差损失函数,较传统方法在性能上获得了很大提高。然而,这些方法忽略了数据集普遍存在的标签分布不平衡问题,因此导致训练出的网络模型对于低频词的标注效果较差。
为了有效提取图像特征并减轻标签分布不平衡带来的影响,考虑到基于语义标签出现频率设置不同的权重可以改善标签数据集不平衡问题[14],本文在迁移学习的基础上,设计了基于标签平滑策略的多标签平滑单元(Multi-Label Smoothing Unit, MLSU),通过给标签分配不同的平滑系数,提高弱标签的标注效果,从而提升了整个模型的标注性能。
2 基于迁移学习的卷积神经网络
2.1 迁移学习
深度学习训练需要大量已标注的数据,然而在现实条件下根本无法获得大量已标注的数据, 因此,考虑通过迁移学习的方法,将已有的知识迁移到目标领域中,解决仅有少量已标注样本数据的学习问题[15]。迁移学习的数学模型[16]如下:
首先在源领域基础数据集DS和基础任务TS上预训练一个基础网络,然后再用目标数据集DT和目标任务TT微调网络。如果特征是泛化的,那么这些特征对基础任务TS和目标任务TT都是适用的,从而训练出来的模型fT(·)具有较好的泛化性能。
在图像处理领域,图像具有相同的底层特征,如边缘、视觉形状、几何变化、光照变化等,这些特征可应用于分类、目标识别、自动标注等不同的任务,因此,可以将经过大规模图像训练集预训练之后的网络模型视为一个通用的特征提取器,将提取到的通用图像特征应用到新任务上。目前通用的多标签图像标注数据集,如Corel5K,仅有4 999张图片、IAPR TC-12也只有19 627张,如果仅用这些数据进行深度模型的训练,由于网络参数数量较大,极易出现过拟合, 因此,基于迁移学习的思想,考虑将应用在其他图像分类任务上取得良好效果的模型迁移至多标签标注领域。目前,AlexNet模型[17]在ImageNet图像数据集上取得了空前的成功,该模型在卷积神经网络基础上使用了ReLU激活函数, 加入了局部响应归一化和Dropout,使其具有较好的特征提取与泛化性能, 因此本文将AlexNet作为基本模型,通过修改损失函数与输出层参数以适应特定数据集下多标签图像标注的要求,最后微调网络以获得深度卷积特征。
2.2 基于迁移学习的卷积神经网络
基于迁移学习的卷积神经网络结构如图1所示,由输入层、网络预训练和网络微调三部分组成。
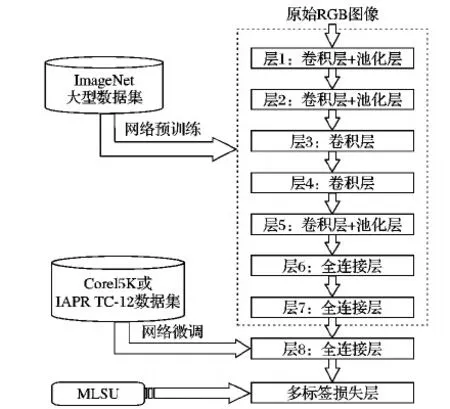
图1 基于迁移学习的卷积神经网络结构
输入层输入原始的RGB图像,大小为227×227。网络预训练模块基于AlexNet模型设计,包含5个卷积层(Convolution, Conv)、3个最大池化层(Max-Pooling)及2个全连接层(Fully Connected layers, FC);网络微调模块包含1个全连接层和1个多标签损失层,各层参数设置如表1所示。在表1中,F、S、P分别表示卷积核/池化窗的大小(Filter size)、滑动步长(Stride)、边界填充(Padding);而K(l)表示本层卷积核/池化窗的个数,K(0)表示输入层图像的通道数;Df表示由本层输出的特征图维数;为防止过拟合使用Dropout,概率设置为0.5;所有的激活函数均采用ReLU,学习率设置为0.000 1。最后一个全连接层输出节点的个数由微调网络的数据集决定,Corel5K数据集和IAPR TC-12数据集输出节点个数N分别设定为260和291。
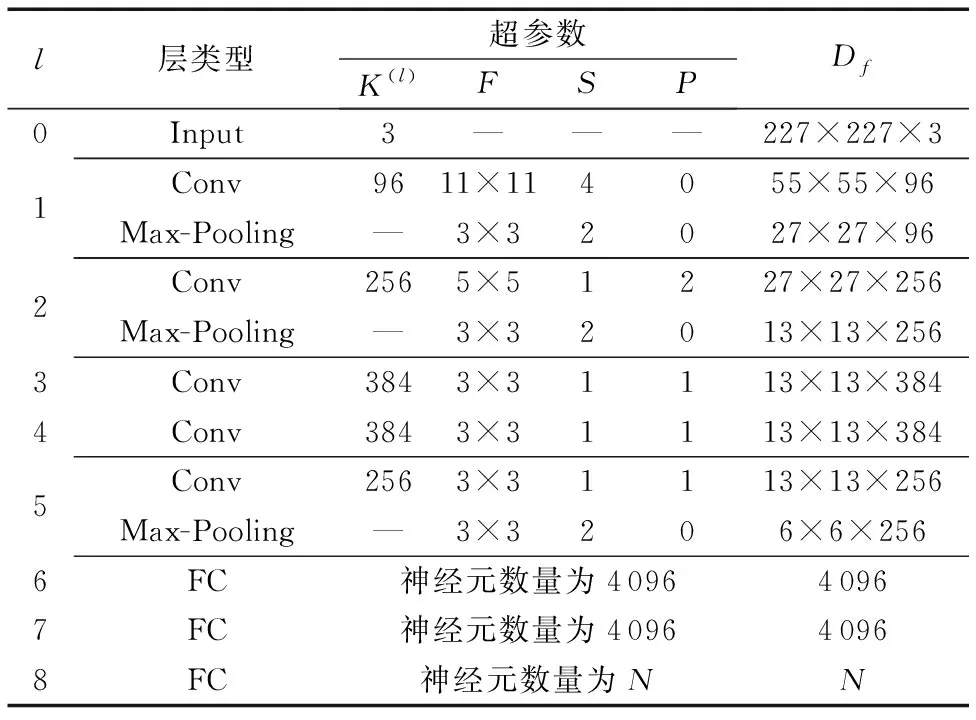
表1 模型各层参数设置
3 多标签平滑
3.1 基于多标签的Sigmoid交叉熵损失函数
基于迁移学习进行网络参数微调时,损失层的损失函数设计主要针对单标签分类,为适应多标签标注,需要将图片对应的标签从单个数值变为标签向量,并确定一个能够将某个标签向量中的每个标签元素对应的损失进行累加求和的损失函数[18]。本文将Sigmoid交叉熵损失函数应用到基于迁移学习的卷积神经网络中,并使其适应多标签分类任务,其公式表示如下:
(1)
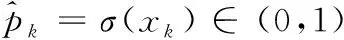
σ(xk)=1/(1+e-xk)
(2)
其中xk∈(-∞,+∞)表示网络模型最后一层第k个神经元的输出值。可以看出基于多标签的Sigmoid交叉熵损失函数可以分解成Sigmoid层与交叉熵损失层,即网络的输出值先通过Sigmoid函数层,然后在交叉熵损失层进行运算,从而得出最终的多标签损失。对式(1)利用梯度下降法求导,得到:
(3)
将式(3)化简后得:
(4)
3.2 多标签平滑单元
目前通用的图像标注数据集普遍存在标签分布不平衡问题,即不同的语义标签在图像集中出现的频率有较大的方差[2],例如,通常图像中标注词“sky”和“tree”在数据集出现的频率远远高于标注词“canyon”和“whales”。对于多标签图像数据集Corel5K与IAPR TC-12,其标签分布不平衡问题更为严重,如表2所示。可以看到,Corel5K和IAPR TC-12数据集中大约75%的标签出现频率低于平均标签频率。
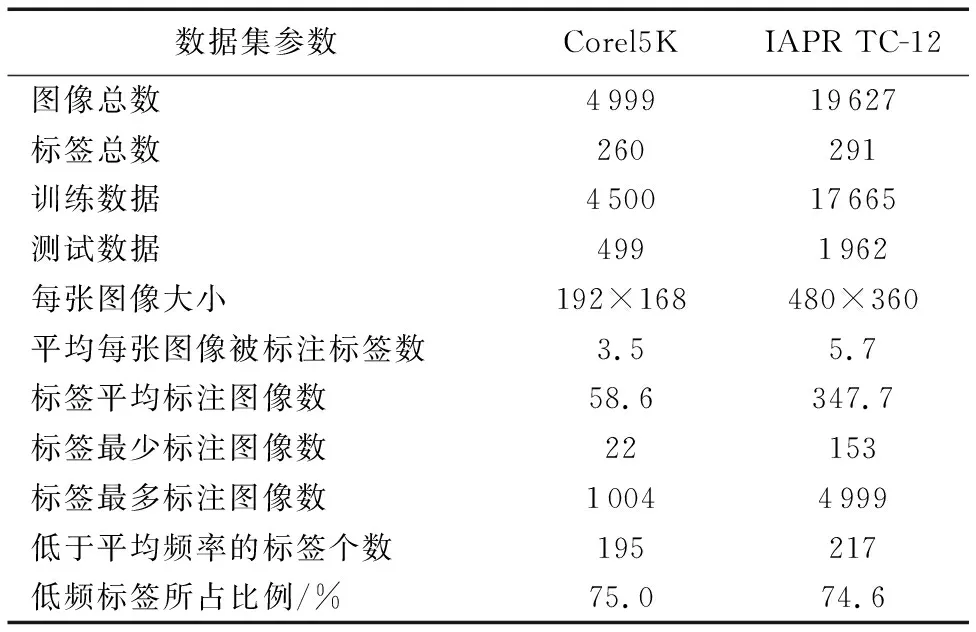
表2 图像标注数据集描述
在训练模型时,由于训练集的标签分布不平衡,高频词对应的网络输出值与低频词对应的网络输出值差距很大,即学习到的模型对高频标签比低频标签更敏感,从而使系统对高频标签标注具有较高的准确率,而对低频标签的标注性能偏低。由于低频标签数量很大,因此低频标签的标注准确性对模型整体的标注性能有重要影响。
为改善低频标签的标注性能,在高频标签中加入噪声,从而在训练过程中适当减弱模型对高频标签的偏好,在一定程度上相当于增强了那些原本被忽略掉的低频标签,使网络模型对低频标签的标注性能得到提升。基于以上思想,设计了多标签平滑单元(MLSU), 对于每张图片的多个标签,可以假设每个标签都是相对独立的,那么这些标签可以组成一个标签向量y∈R1×K,K为数据集中标签总数。yj=1表示对这张图片标注第j个标签;相应地,yj=0则表示没有标注第j个标签。向量Ω=[ε1,ε2,…,εK]表示为数据集标签的平滑参数,每个标签的平滑参数表示如下:
εj=nj/N
(5)
其中:nj表示标签j在训练集中被标注的次数,N为训练集样本总数。对于样本x所对应的标签向量y,通过定义一个新的标签yj′替换掉原来的标签yj,其中u(K)为一个固定分布。
yj′=εj×yj+ (1-εj)×u(K)×sign(yj)
(6)
式(6)表示将原始标签与分布u(K)进行混合,原始标签由其对应的平滑参数来调整权重,相当在原来的标签yj中加入噪声,使得yj有(1-εj)的概率来自分布u(K)。为了方便计算,u(K)一般取均匀分布,则式(6)可表示为:
(7)
多标签平滑单元处理过程如下所示:
输入:训练样本x及其对应的标签向量y=[y1,y2,…,yK],所有标签的平滑参数Ω=[ε1,ε2,…,εK]。
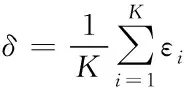
2)
Fori=1,2,…,K
3)
IFεi>δ
4)
根据式(7)计算yj′
5)
End IF
6)
End For
输出:经过平滑处理的多标签向量y′=[y1′,y2′,…,yK′]。
4 实验与结果分析
4.1 实验数据集与评价指标
为了测试本文方法的有效性,实验分别在两个通用的多标签图像标注数据集Corel5K与IAPR TC-12数据集上进行,数据集详细描述如表2所示。
评价指标使用平均查准率(Average Precision,AP)、平均查全率(Average Recall,AR)以及F1度量,计算公式如下所示,为了能够与其他方法进行比较,每张测试图片使用5个标签进行标注。
(8)
(9)
(10)
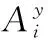
实验基于Caffe(Convolutional architecture for fast feature embedding)深度学习框架,使用NVIDIA K620 GPU进行计算,使用cuDNN库加速。实验参数如表3所示,其中,δ为多标签平滑阈值,Batch_size为批训练样本个数,Epoch为训练集迭代次数。

表3 实验参数设置
4.2 多标签平滑单元对标注性能的提升
为了验证本文提出的MLSU对标注性能的提升,将CNN-MLSU模型与只进行迁移学习而没有进行多标签平滑操作的模型CNN-TL(CNN-Transfer-Learning)进行标注性能的对比实验,实验结果如表4所示。从表4可以看出,在网络模型中加入MLSU后,在标注的各项评价指标都有较为明显的提升,其算法性能在通用数据集Corel5K和IAPR TC-12上均得到验证,从而证明了CNN-MLSU模型的有效性与普适性。
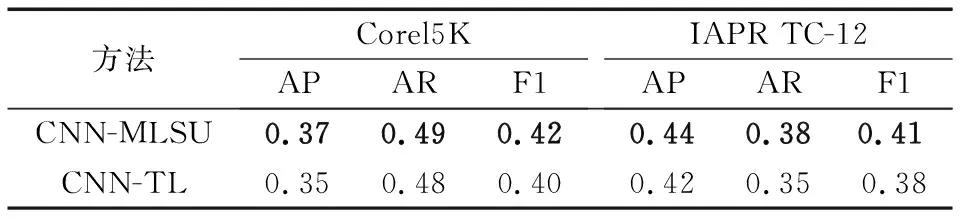
表4 CNN-MLSU与CNN-TL性能对比
此外,为了验证CNN-MLSU方法在低频词汇上的标注性能,本文对比了CNN-MLSU与CNN-TL在低频词汇的平均准确率AP、平均召回率AR、召回率大于0的低频词的个数N+,对于Corel5K有195个低频词汇,对于IAPR TC-12有217个低频词汇,实验结果如表5所示。
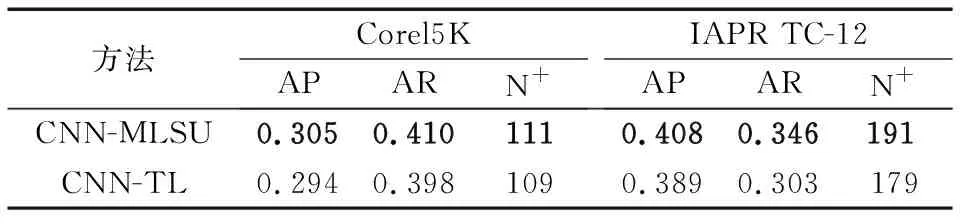
表5 MLSU对低频词标注性能的改善结果
综合表4与表5的实验数据可以看出,CNN的网络模型在加入MLSU多标签平滑单元后,在几乎不影响高频词汇标注性能的情况下,提升了低频词汇的标注性能。
4.3 与其他图像标注方法比较
为验证本文提出的基于迁移学习的卷积神经网络在多标签标注方面的标注性能,分别与传统的JEC方法、MBRM方法、改进的TagProp_ML方法、SKL-CRM方法、2PKNN方法以及较为先进的2PKNN_ML方法和NN-CNN方法进行了比较。并与同样使用深度卷积神经网络进行图像标注的CNN-R方法、CNN-MSE方法进行了对比实验,实验结果如表6所示。
表6在通用数据集上各图像标注方法的实验结果
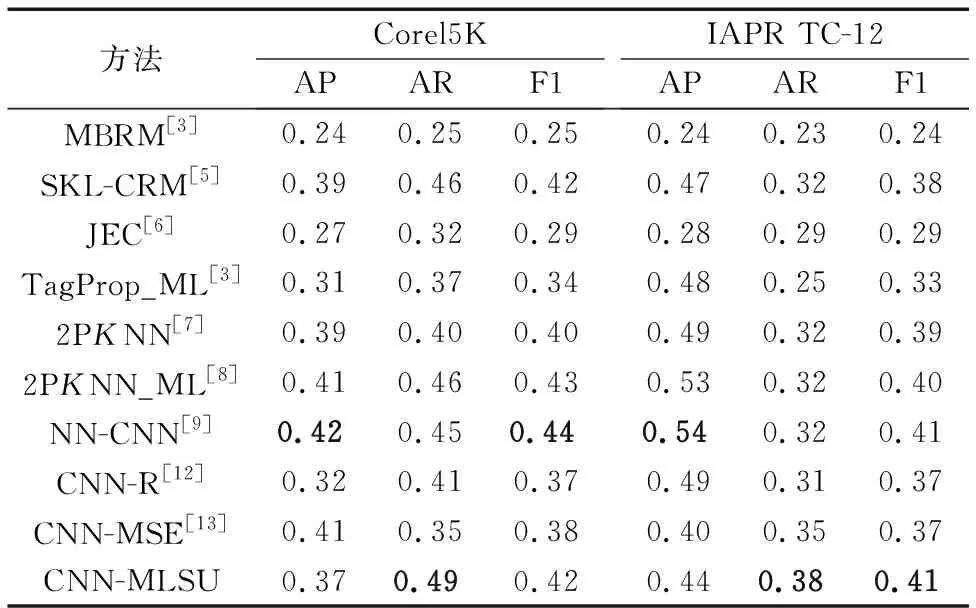
Tab. 6 Experimental results of image annotation methods on generic datasets
通过表6可以看出,在Corel5K数据集上,本文提出的CNN-MLSU方法较传统方法有较大的提高,平均准确率较JEC方法提高了10个百分点,平均召回率较MBRM方法提高了24个百分点。在使用卷积神经网络的模型中,CNN-MLSU的平均准确率较CNN-R方法提升5个百分点,平均召回率提升8个百分点。 另外,CNN-MLSU在平均准确率上虽然低于2PKNN_ML方法,但是在平均召回率上较2PKNN_ML提高了3个百分点,仍是可比较的。在IAPR TC-12数据集上,CNN-MLSU较传统方法及其他CNN方法在各项指标上均有较好的表现,与较为先进的NN-CNN相比,虽然在平均准确率上存在差距,但在平均召回率上性能要明显优于NN-CNN,综合指标F1值也与其不相上下。
图2给出了使用CNN-MLSU模型进行标注后部分图像的标注结果示例。通过图2可以看出,虽然模型预测出的某些词(用斜体表示)不是测试图片的真实标签,但是从图片的语义内容角度来说,这些词能够正确表达图像的部分内容。然而,这些预测出的标注词却在计算准确率和召回率的过程中被判定为错误的标签,不但没有提高召回率,反而导致了准确率的下降。结合表2中关于数据集的描述,IAPR TC-12数据集中平均每张图片被标注的个数为5.7,但是在Corel5K数据集中却只有3.5个,这种由于数据集标注不全面而产生的“弱标注”现象在Corel5K数据集中更为严重,在一定程度上导致了Corel5K数据集准确率不高。此外,本文提出的CNN-MLSU模型隶属于判别模型,较近邻模型而言,对训练数据样本数量的要求更高。在Corel5K数据集仅有4 500张训练样本的前提下,CNN-MLSU的综合指标略低于近几年较先进的近邻模型,但随着训练样本的增加,判别模型的优势逐步显现,因此在拥有17 665张训练样本的IAPR TC-12数据集下,本文提出的CNN-MLSU模型能够获得较好的综合标注性能。

图2 真实标签与模型预测标签对比
5 结语
本文在卷积神经网络模型AlexNet的基础上,利用迁移学习较优的通用特征提取能力与较强的泛化能力,改善了特定领域图像样本数量不足的问题,有效地防止了网络过拟合。同时引入多标签平滑方法,根据标签在数据集中的分布情况,自动对高频标签进行平滑操作,在一定程度上提升了低频标签的标注性能。在Corel5K数据集上,本文提出的CNN-MLSU模型较卷积神经网络回归方法(CNN-R)的平均准确率与平均召回率分别提升了5个百分点和8个百分点。在IAPR TC-12数据集上,较近几年表现较优的两场K最邻近模型(2PKNN_ML)的平均召回率提升了6个百分点。实验结果表明,CNN-MLSU与其他传统方法、普通卷积神经网络标注方法相比,具有更好的综合标注性能。
