基于词典和弱标注信息的电影评论情感分析
2018-12-14张振豪韩美琪
樊 振,过 弋,2,张振豪,韩美琪
(1.华东理工大学 信息科学与工程学院,上海 200237; 2.石河子大学 信息科学与技术学院,新疆 石河子 832003)(*通信作者电子邮箱guoyi@ecust.edu.cn)
0 引言
近年来,随着我国经济快速发展以及国家对文化产业的大力支持,我国电影市场环境日益改善。2017年上半年,中国内地票房规模为271.2亿元,相比2016年上半年总票房规模248.1亿元,增长9.3%;同时第二季度,用户在线购买电影票占比达78.2%,较上一季度有小幅上升,在线电影购票市场渗透率趋于稳定[1]。大量用户通过电影平台表达自己对电影的观点和看法,这些评论中包含着大量用户对电影及其相关内容的评价,包括演员、剧情、演技、特效等。合理地利用这些用户评论可以为用户消费决策、商家营销规划、电影制作方内容优化等提供帮助, 因此挖掘用户评论文本中的情感信息有着重要的价值。
Hu等[2]认为评论的情感极性主要通过评论中的形容词来判定,提出根据形容词建立情感词典,再根据一定的规则来计算评论的情感极性;但是该方法太依赖于情感词典和规则的质量,需要一定的经验知识,推广能力差。Pang等[3]首次提出利用机器学习的方法来进行情感分类,将文本表示成不同的特征组合,并在不同的分类算法下进行对比实验;但是利用机器学习的方法需要对数据进行标注,这会耗费大量的人力资源和时间。近年来,研究者开始从用户产生的信息中训练数据,如用户评分。Qu等[4]使用用户评分信息作为标注数据训练模型来解决文本情感分类问题,但是这部分标注数据具有随意性,容易产生数据噪声(如低评分的正面评论)。
针对上述问题,本文提出了基于词典和弱标注信息的电影评论情感分析方法,利用评论的评分数据和基于情感词典的情感倾向来标注数据。本文的工作主要有:
1)对知网的中文情感词典(HowNet)和台湾大学的简体中文极性情感词典(National Taiwan University Simplified Dictionary, NTUSD)整合,并构建符合现有数据的情感词典。
2)设计基于情感词典的评论情感计算规则,并对数据自动标注。
3)利用支持向量机(Support Vector Machine, SVM)算法对数据进行情感分类。
1 相关工作
目前情感分析研究技术主要分为基于情感词典的方法和基于机器学习的方法[5]。
基于情感词典的研究方法主要是根据情感词库来匹配计算评论的情感倾向。Liu等[6]在文献[2]的基础上考虑了主题词与情感词之间的距离对评论情感倾向的影响,距离越远影响越弱。基于词典的方法没有办法识别文本中隐含的观点,Zhang等[7]认为基于词典的方法只能通过显式的情感词提取观点。此外,本文还常常出现上下半句情感倾向出现转折、同一情感词在不同环境下极性不一样的情况。
基于机器学习的研究方法主要是将评论情感分析转化为一个分类问题。目前主流方向是二分类问题,即将评论分成正面情感和负面情感。通过人工设计代表评论文本的特征,然后抽取评论特征并表示成文本向量,即可对文本进行分类。Pang等[3]首先提出使用机器学习的方法来解决情感分类问题,该工作选取了Unigrams、bigrams、POS(Part of Speech)等特征进行不同组合并在分类算法朴素贝叶斯(Naive Bayes, NB)、支持向量机(SVM)和最大熵模型下进行实验。在使用Unigrams特征的情况下,SVM的效果最好。李婷婷等[8]在前人工作基础上提出使用词性、情感词、否定词、程度副词来构建特征,并选用不同的特征组合进行多组实验。实验结果显示选用词性、否定词和情感词组合时,SVM效果最好;而使用情感词、程度副词、否定词和特殊符号组合时,条件随机场(Conditional Random Field, CRF)模型效果最好。
基于机器学习的方法需要人工去标注数据集,花费大量人力资源:Qu等[4]曾尝试使用包含用户评分信息的评论数据作为弱标注信息对模型进行训练,最终对评论进行情感分析;Tang等[9]使用评论中的表情符号作为标签值来训练模型,从而对文本进行情感分类。但是这类方法的标注具有较大随意性,容易对数据产生噪声。
2 词典构建
2.1 预处理
从豆瓣电影采集的评论数据包含两部分内容,用户评论和用户评分。在对数据整理后发现,部分数据中用户评分缺失,所以先要将这部分数据过滤。在对数据进行情感分析之前,先要对评论数据分词和词性标注,本文选取结巴分词作为自然语言处理工具完成数据预处理工作。
2.2 领域情感词典构建
目前,中文领域使用较多的情感词典包括知网提供的HowNet和台湾大学的NTUSD。HowNet包含情感词语和评价词语两个部分,其中情感词语中含有836个中文正面情感词和1 254个中文负面情感词语,评价词语中含有3 730个中文正面评价词语和3 116个中文负面评价词语。NTUSD包含2 810 个正面情感词语和8 276个负面情感词语。将这三部分词典去重后得到新的情感词典构成基础词典,正向情感词极性为1,负向情感词极性为-1。
但是在文本评论中,存在基础词典未包括的情感词也有情感倾向。比如“这电影好搞笑啊”,搞笑就是积极情绪的词,因此,只靠基础词典来识别电影评论的情感词是不够的,特定的领域还需要领域词典,本文通过互信息(Point-wise Mutual Information, PMI)来构建领域情感词典[10],PMI可以计算词语之间的相似度。计算两个词w1和w2的PMI公式:
(1)
其中:p(w1,w2)表示词w1和词w2一起出现的概率,p(w1)表示词w1出现的概率,p(w2)表示词w2出现的概率。在使用过程中,w1是语料中切分出来的情感词,w2是核心情感词,通过PMI来计算两个词相似度:如果相似度高则认为两个词情感极性相同; 反之亦然。
核心情感词的词性必须非常明确,比如积极词有“好”,消极词有“烂”,但是单个核心情感词在PMI计算时容易造成较大的误差,因此本文进行多词考察。本文通过统计基础情感词在评论文本里的词频,挑选出最高的正、负核心情感词各30个。
在计算了新词和正负核心情感词之间PMI之后,就可以得到新词的情感倾向,其计算公式[11]为:
(2)
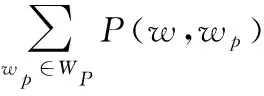
2.3 否定词构建
一条评论中的否定词往往会改变评论的情感极性,因此本文整理了一些常用的否定词用来判定评论情感极性。常用否定词包括:不、没、无、非、未、否、勿、不是、并非、没有、绝不。
2.4 程度副词构建
程度副词可以改变情感词的情感强度,如“我非常喜欢”,非常就是程度副词,增加了喜欢的强度。本文使用的是HowNet里的程度副词表,该表包含219个程度级别词语。按照级别不同,分为6个类别,分别是“极其/最” “很” “较” “稍” “欠” “超”。本文按照其语气强度不同分别赋予不同权值,如表1。

表1 程度副词及其权值
3 情感分析与计算
本文提出基于词典和弱标注信息相结合的机器学习方法来对电影评论进行情感分析,在用户评分的基础上,通过领域词典对评论进行情感倾向分类,挑选出评分和分类结果情感一致的训练数据进行模型训练。图1显示了本文方法的整体流程。
在数据标注部分,本文首先对采集数据进行过滤、分词及词性标注等预处理;然后利用基础词典在语料中提取出核心情感词,进而构建领域情感词典;接着利用基于词典的情感分类和用户评分相结合的方式对数据进行标注。在SVM模型训练部分,先对评论数据提取特征,然后对训练数据训练模型,最后利用训练好的模型对测试数据进行情感分类。

图1 系统整体流程
3.1 基于词典和弱标注信息的数据标注
目前,基于机器学习的文本情感分类问题主要是有监督的分类问题,需要人工去标注数据,但是标注数据会花费大量人力资源。本文采集的数据中包含着用户评分,可以根据用户评分简单来标注数据,但是用户打分具有随意性,容易对数据产生噪声(用户评分与评论情感不一致),这种标注称为弱标注信息[12],因此本文采用词典和弱标注信息相结合的方法对电影评论数据进行情感分析。
对于单条评论,本文先对它进行分词和词性标注处理,然后根据前文构建的领域情感词典查找评论中的情感词。若找到情感词,标记该情感词位置,然后向前查找修饰该情感词的否定词和程度副词,这样,每个情感词及其相关的否定词和程度副词称之为情感词类。其情感分析算法描述如下:
机房当中的监控设备能够在一定程度上防止其事故的发生,还能够在某种层面上让电网自动化技术得到充分的运用。因此,为了能够让供电企业更好地安全运行,就必须要增加监控设备技术的使用,要将那些技术落后的,设备性能较差的全部淘汰掉,要将先进设备技术进行完善、安装。对不同的监控设备进行不同的安装方式,要在后期对其进行定期或者不定期的日常维护,与此同时,还需要将那些出现故障的设备,进行问题的分析,要找到出现问题的原因,如果是人工导致的,那么就会追究其责任,对工作人员进行处罚,让其能够更深地认识到供电设备维护的重要性,从而去实现供电的安全稳定性的提升,促进经济可持续发展[3]。
1)评论预处理,包括分词和词性标注
2)While 情感词 do
寻找修饰情感词的否定词、程度副词,计算情感词类情感值
3)计算评论情感值,情感值大于等于0,评论情感倾向标记为1,否则标记为-1
每个情感词类的情感值计算公式为:
s(w)=n(w)×d(w)×p(w)×l(w)
(3)
其中:s(w)表示情感词类w的情感极性;n(w)表示否定词的情感权重。一个否定词表示情感反转,但是双重否定情感就没变化,当否定词个数为奇数时,n(w)为-1,为偶数时,n(w)为1,其计算如式(4):
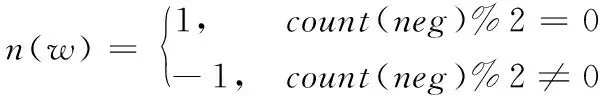
(4)
其中count(neg)表示否定词个数。d(w)表示修饰情感词的多个程度副词权值累加和,其计算如式(5):
(5)
p(w)表示情感词的极性,正面情感词为1,负面情感词为-1;l(w)表示否定词和程度副词的相对位置,它们之间位置不同,情感也不一样,比如评论“这部电影很不好看”和“这部电影不很好看”,表达情感完全不同;当否定词在程度副词前面时,l(w)设置为0.5,反之l(w)设置为-1,其计算如式(6):

(6)
其中:loc(neg)表示情感词类中否定词的位置,loc(dg)表示情感词类中程度副词的位置,“<”表示相对位置在前,“>”表示相对位置在后。
单条评论由多个情感词类组成,因此单条评论的情感极性计算如式(7):

(7)
其中:r表示单条评论中所有的情感词类,sen(r)表示单条评论的情感极性。利用式(7),本文可以计算得到每条评论基于词典的情感值,sen(r)≥0表示评论正面情感,反之为负面情感。
用户评分中,评论情感值分为1、2、3、4、5一共5个等级,本文设定用户评分大于等于3为正面情感,小于3为负面情感。最后,本文挑选出二者情感倾向一致的数据作为训练数据。
3.2 特征选择
基于机器学习的情感分析的核心就是特征选择,它关系着情感分类的准确度。目前常见的特征选择有:一元词(unigram)特征、二元词(bigram)特征、三元词(trigram)特征、词频、词性、情感词等[8]。其中一元词特征、二元词特征、三元词特征的特征维度与语料量有关,当语料很大时,特征维度会达到千维级别,很难处理;词频可以反映一个词语的重要性,但是并不是所有的词都与文本情感相关,引入词频会导致数据产生噪声。本文选择词性、程度副词、否定词、正面情感词以及负面情感词这五个特征维度,其中一个文本是由多个词及其词性构成的,词性在其中起很大作用;情感词是一个文本情感分类的关键核心,而否定词通常会使一个文本的情感极性发生反转;与此同时,程度副词能改变情感词的强度,当一个文本中既出现正面情感词又出现负面情感词时,如果只依靠情感词的极性,是很难判断文本的情感倾向的,而程度副词可以帮助抉择。比如说评论“电影很不错,就是情节有点拖。”中,“很”比“有点”程度强,可以判断评论情感倾向为正面。
在选择文本特征时,对于每个维度具体含义如表2。

表2 特征维度含义
以评论“电影非常好,但不喜欢女主角”为例提取特征,首先采用结巴分词进行分词和词性标注,得到结果如下:
电影/n 非常/d 好/a ,/x 但/c 不/d 喜欢/v 女主角/n
其中:n表示名词,d表示副词,c表示连词,a表示形容词,v表示动词。从上可知,词性个数为5,正面情感词个数为1,负面情感词个数为0,否定词个数为1,程度副词权值为2。
3.3 SVM模型
SVM是近几年发展起来的新型分类方法,主要解决文本分类问题[11]。SVM的原理是通过将一个样本通过某种映射关系映射到高维空间或者是无穷维特征空间,使原来在样本空间中非线性化可分的问题转化为在特征空间中线性可分的问题[14]。目前应用最为广泛的SVM分类器主要有LibSVM和SVMLight两种[15],本文采用台湾大学林智仁教授开发的LibSVM进行分类测试。
4 实验结果及分析
4.1 实验准备
本文利用爬虫工具Pyspider在豆瓣电影平台上抓取了关于电影《捉妖记》《战狼2》的用户评论及评分,在经过去重、过滤后,分别剩下23 605,23 415条数据作为实验数据。由于本文使用的是基于情感词典的方法和用户评分情感倾向相结合来标注数据,因此不需要人工标注数据。
将数据随机分成5组,然后每次取4组数据作为训练数据,剩下1组数据作为测试数据进行交叉实验,最后将每次测试结果累加在一起作为最终测试结果。每组数据基于词典和用户评分相结合标注的情况如表3所示(表中第一个字母P表示基于词典的计算结果为正面情感,N表示为负面情感;第二个字母P表示用户评分情感倾向为正面情感,N表示负面情感)。
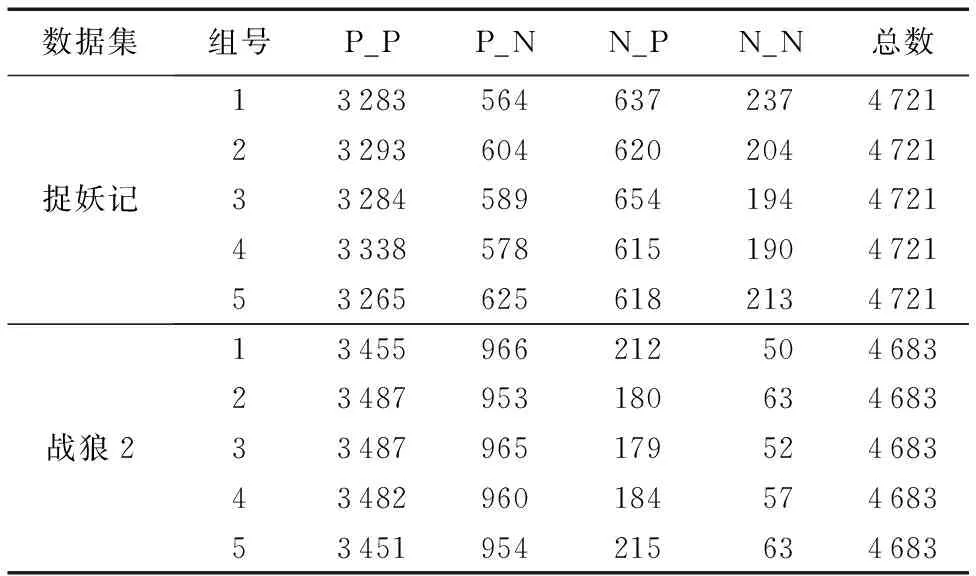
表3 数据分组以及标注结果
在每次交叉实验中,取4组数据为训练数据,其中每组数据只取标记为P_P和N_N的数据;取1组数据为测试组数,包含该组所有数据。
4.2 实验结果与分析
本文使用的分类器是LibSVM,为了避免不同的参数对分类效果产生影响,本文利用LibSVM的工具包grid.py通过交叉验证的方法求最优核函数的参数c和gamma。表4列出了不同数据集的最优参数c和gamma以及交叉验证的准确率rate,rate最大值对应的c和gamma即是最优参数。
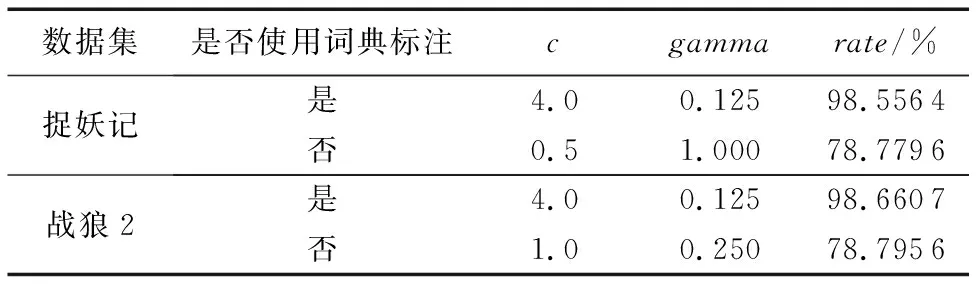
表4 LiSVM最优参数
为了评价最终的分类效果,本文采用分类准确率(Accuracy),即文本分类正确数占文本总数的比例,作为评价指标,其公式为:
(8)
其中:ncorrect表示文本分类正确数,nall表示本文总数。
本文在两种不同类型电影数据集上分别进行了三组对比实验,分别为:
1)Lexicon。 基于词典的方法。
2)WT。 使用弱标注信息作为数据的标注,并在SVM分类器上进行情感分类。
3)WT+Lexicon。 使用基于词典的方法和弱标注信息标注数据,并在SVM分类器上进行情感分类。
最终实验结果如表5所示。

表5 3种方法分类准确率对比
从表5可以看出,基于机器学习的方法在准确率上比基于词典的方法高,准确率分别达到了75.5%和75.7%,而本文方法在准确率上分别达到了77.2%和77.8%,相比单一基于弱标注信息的机器学习方法,分别提高了1.7个百分点和2.1个百分点,证明了本文算法的有效性,本文方法也更加适合于评论文本的情感分析。本文方法与基于机器学习的方法相比,在数据训练部分,利用基于情感词典的分类方法和用户评分相结合的方式去除了部分数据噪声,使得模型训练更加准确,因此本文方法在准确率上才会提高。
同时,从三类实验的结果看,三种方法的准确率都有待提高。考虑到基于词典的方法是基于词典和规则的算法,同时也对分词工具有一定的要求,因此要提高基于词典的方法的准确率就需要分词工具能准确分出评论的词语和词性,其次要扩充现有的词典以满足现在的互联网评论语句,最后应设定更加合理的情感匹配规则。而本文方法与特征选择和标注信息相关,要提高准确率就需要在特征选取方面加以改进;在不考虑人工标注的情况下,本文方法是有一定的适用性的。
5 结语
本文提出了一种基于词典和弱标注信息相结合的文本情感分析方法,实验准确率相比传统的基于词典的方法和基于弱标注信息的机器学习方法有了一定的提升,在不同类型的电影数据集上准确率分别达到了77.2%和77.8%,分别提升了1.7个百分点和2.1个百分点,验证了本文方法的有效性。评论语料的初始预处理到进一步的特征选择都会影响最终的分类结果,因此本文方法在分词工具选择和特征选择方面可以进一步对比和优化,选择最适合本领域的分词工具和特征组合。
