并行效率敏感的大规模SVM数据分块数选择
2018-12-11廖士中
张 闯 廖士中
(天津大学计算机科学与技术学院,天津,300350)
引 言
支持向量机(Support vector machines,SVMs)是基本机器学习模型和有效的数据挖掘方法之一。核SVM通过引入核技巧实现应用线性方法来学习非线性关系的途径,但SVM的求解是一个二次规划问题,时间复杂度为O(n3),空间复杂度为O(n2),其中n为训练集规模[1-2],这成为发展大规模SVM 的主要瓶颈。
为发展大规模SVM,文献[3]提出基于核矩阵近似的并行SVM算法,引入核缓存策略来并行计算核矩阵,数据分块数设为l/d,其中,l为训练集规模,d为核缓存区大小。近年来,应用随机特征映射近似核方法的研究引起了广泛关注。Rahimi等人提出利用随机傅里叶特征映射近似高斯核函数,进而在显式随机特征空间中应用线性SVM来一致逼近核诱导特征空间中的高斯核SVM[4-5], 成为提升SVM可扩展性的有效方法。Feng等人提出一种新的随机特征映射方法[6],利用有符号循环随机矩阵代替无结构随机矩阵来投影数据。该方向的工作进一步发展了有效的近似方法,时间复杂度可降至与数据规模呈对数线性,同时也发展了大规模核方法[7]。文献[8]通过引入半宽因子,构造高斯区间核SVM模型,发展了针对区间型数据的高效分类方法。
交替方向乘子法 (Alternating direction method of multipliers, ADMM) 提供一个简单且强大的并行/分布式计算框架,可将大规模问题分解为多个小规模子问题,进而相互协调且并行一致地求解原问题[9]。在该框架下,文献[10]提出基于并行/分布式ADMM的线性SVM算法。该算法中的数据分块数依据经验来选择,没有探讨数据分块数对模型泛化性和计算效率的影响。文献[11]将随机特征映射与并行/分布式ADMM相结合,提出基于核方法统计模型的大规模训练框架。该框架适合多种统计学习任务,分块数目经验地取为D/d,其中,D为随机特征维度,d为训练数据维度。矩阵分解与填充广泛应用于推荐系统中,分布式矩阵分解得到了广泛关注。Yu等人[12]研究随机ADMM 框架下分布式求解矩阵分解问题,矩阵划分块数与集群节点个数相同,没有讨论分块数目对均方根误差的影响。Zhang等人[13]提出基于分解法的可扩展核岭回归算法,通过适当的参数调节,只要分块数目不是太多,该方法可以提高计算速度,保持统计最优性,进而得到有效的一致模型估计量。
已有的并行/分布式机器学习方法中,数据分块工作没有明确的分块数选择准则,也缺乏基本的理论保证。针对这一问题,提出大规模并行效率敏感的数据分块数选择准则。该准则以并行/分布式机器学习的泛化误差与数据分块数之间的关系为基础,折衷泛化误差与并行效率,可在保证并行/分布式机器学习测试精度的条件下,提高计算效率。在ADMM框架下的随机傅里叶特征空间中,采用所提出的数据分块数选择准则实现一个大规模支持向量机模型。实验结果表明,该准则在保证大规模支持向量机测试精度的同时,仍可进一步提高计算效率。
1 相关工作
1.1 交替方向乘子法
当目标函数满足可加性时,并行/分布式ADMM 等式约束问题[9]为
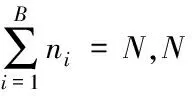
其中:ρ>0为惩罚系数,ui=y/ρ为缩放对偶变量,y为拉格朗日乘子向量。每个从进程并行更新局部变量ωi,ui。主进程汇聚ωi,ui,更新全局变量υ,并广播给从进程。并行/分布式ADMM交替优化过程见算法1。
算法1分布式交替方向乘子法(D-ADMM)
输入:函数f,g,矩阵A,分块数备选集B,惩罚系数ρ>0。
(1) 初始化:ω0,υ0,y0;
(2) repeat
(6) until 满足终止条件。
输出:ω*,υ*,y*。
D-ADMM 的终止条件为

其中:εpri>0,εdual>0分别为原问题和对偶可行性条件的误差, 定义为
其中:εabs>0,εrel>0分别为绝对误差和相对误差[9]。
满足如下两个假设的条件时, D-ADMM 收敛[9,14]。
假设1扩展实值函数f:Rn→R∪{+∞},g:Rm→R∪{+∞}是封闭、适定且凸的[15]。
假设2增广拉格朗日函数L存在鞍点。
1.2 随机傅里叶特征映射
高斯核函数是一种通用的平移不变核,定义为
(1)
式中γ=1/2σ2。
可通过高斯核函数的傅里叶逆变换得到ω的概率密度函数p(ω),ω~正态分布N(0,2γI), 其中I为单位矩阵。易知

可见,〈Tω,b(x),Tω,b(y)〉是高斯核函数(1)的无偏估计。通过标准蒙特卡洛积分近似高斯核,构造如下随机傅里叶特征映射[4-5]
(2)
式中:D为随机特征维度,高斯随机矩阵T∈RD×d,Ti~N(0,2γI),b为随机向量,bi~均匀分布U(-π,π),i=1,…,D。则k(x,y)=E〈Φ(x),Φ(y)〉。
2 并行/分布式机器学习模型泛化误差分析
本节推导并行/分布式机器学习模型数据分块数与泛化误差之间的关系。
不失一般性,界定以下假设条件:
假设3f*∈C(X)且‖f*‖∞≤M。其中,C(X)是X上的连续函数空间, ‖·‖∞为上确界范数。
假设4损失函数l(·)为非负L-Lipschiz 连续的凸函数。HK是一再生核Hilbert 空间 (RKHS)。对任意f1,f2∈HK,存在常数L>0,使得
假设5任意g∈C(X),ε>0,存在f∈HK,使得‖f-g‖∞<ε。令BR=f∈HK,‖f‖∞≤R,R>0。存在常数C0,s>0,使得
N∞(F,r)≤expC0r-s
其中:N∞(F,r)表示集合F半径为r球的覆盖数。
下面分析并行/分布式机器学习模型的泛化误差。可将泛化误差分解为采样误差、假设误差和近似误差3部分,则有
其中:f*∈C(X),f∈HK是在样本S上学习的结果,fB∈HK是把样本分成B块后学习的结果,ε(·)为期望误差,εS(·)为经验误差。令样本规模为N,基于以上假设和分析可给出如下泛化误差分析结果。
引理1[16]假设3—5成立,M′=max{2M,‖f-f*‖∞}。对任意0<δ<1,有
(3)

引理2[16]假设3—5成立,对任意0<δ<1,有
(4)
式中M′,G1和G2定义同引理1。
定理1假设3—5成立,当N足够大时,对任意0<δ<1,f∈HK,有
(5)
式中:‖f-f*‖∞≤1/N,G1和G2定义同引理1。
证明由假设3和假设5成立可知,对任意N≥1,存在f∈HK,有
‖f-f*‖∞<1/N
由假设4成立,损失函数l(·)是L-Lipschiz连续的,有
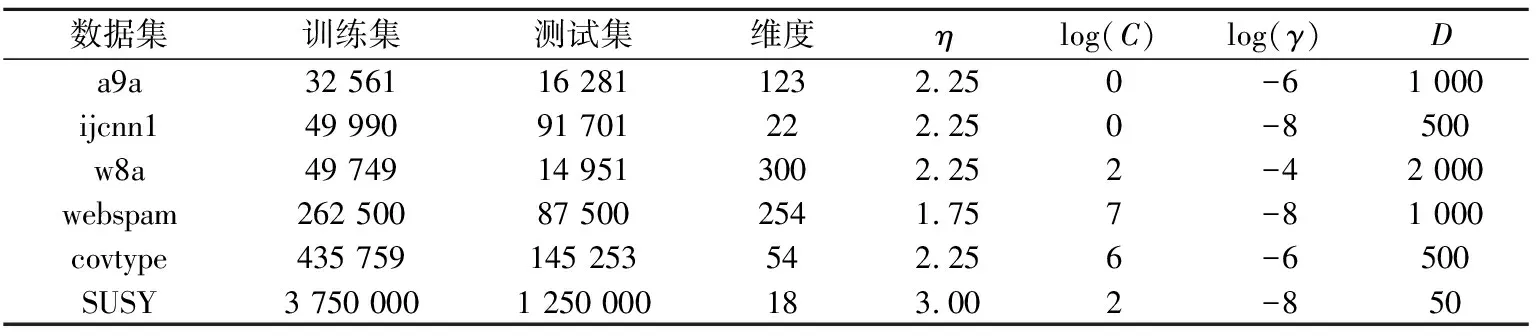
ε(f)-ε(f*)=Ez[l(f,z)-l(f*,z)]≤L‖f-f*‖∞ (6) 所以,近似误差上界为L/(N/B)τ。当N足够大时,‖f-f*‖∞<1/N→0。那么 M′=max(2M,‖f-f*‖∞)=2M (7) 将式(7)分别代入采样误差式(3)和假设误差式(4)并与近似误差式(6)求和,可得式(5)。 给定训练数据A={ri=(xi,yi),i=1,2,…,N},其中,xi∈Rd,d为训练数据维度,N为训练集规模。 由经验风险最小化[17]可得 其中:f为再生核希尔伯特空间HK中的任意假设,l(·)为非负凸损失函数。 定义分块经验风险最小化,可得 其中li(·)为第i个子数据块的平均经验风险。 并行算法效率[19]定义为 其中:Ts为串行时间,Tp为并行时间,B为进程数。 为了权衡模型的泛化性和并行效率,提出并行效率敏感的数据分块数选择准则 其中:B为分块数备选集,η为惩罚系数,δ≤E(B)<1,δ为并行效率下界。 本节采用所提出的数据分块数选择准则来构造一个大规模支持向量机模型。 在并行/分布式ADMM框架下的随机傅里叶特征空间中实现大规模支持向量机模型。给定标签数据集S={(x1,y1),(x2,y2),…,(xN,yN)}∈(X×Y)N,其中,X表示输入域,Y为输出域,xi∈Rd,标签yi∈{-1,+1},N为训练集规模。 由随机傅里叶特征映射式(2),得到随机特征映射矩阵Z∈RN×D,D为随机特征维度。将Z按行随机划分为B块[18],每个分块的样本规模为|Bj|。随机傅里叶特征映射显式地构造随机特征空间,可在该随机特征空间中应用线性SVM来一致逼近高斯核SVM[7]。 损失函数max(1-yiωTzi,0)2是L-Lipschiz连续的[20]。由分块经验风险最小化,可得 此时,D-ADMM 中g(·)为指示函数[21]。定义为 大规模SVM最优分块数选择为 ADMM 框架下随机傅里叶特征空间中数据分块数选择过程见算法2。 算法2分块数选择算法 (SNC) 输入:随机特征矩阵Z∈RN×D,分块数备选集B,且|B|=t, 惩罚系数η, 并行效率下界δ。 (1) 初始化:E(B)=1; (2) fork=1,2,…,tdo (4) 更新E(B); (6) end for 对D-ADMM 中的并行子问题利用对偶坐标下降算法[10,22]求解。要得到ε精确解, 迭代次数为O(log(1/ε)),时间复杂度为O(nDlog(1/ε)),其中,n为子数据块数据规模。算法SNC的迭代次数为t,所以总的时间复杂度为O(tnDlog(1/ε))。 D-ADMM框架下大规模SVM问题为 其中:C为超参数,o为全局变量,ωj是与第j个进程的局部变量。由D-ADMM可得 每个进程j处理一个子问题,各个并行子问题利用对偶坐标下降算法求解ωj[22]。 本节实现并行/分布式 ADMM 框架下随机傅里叶特征空间中的大规模 SVM, 并实验验证所提出的数据分块数选择准则。实验中使用6个标准数据集,如表1所示,其中,大规模 SVM 的超参数C和高斯核参数γ通过在11×11空间内进行格搜索的5-折交叉验证来选取,(C,γ)∈{2-9,2-7,…,27,29}。η为惩罚系数,并行效率下界δ设为0.25,D-ADMM 中惩罚系数ρ设为1,绝对误差εabs和相对误差εrel均设为10-4,ε设为10-3。实验环境: 曙光“星云”高性能计算集群。采用OpenMPI 1.4.5和C++实现并行算法。普通队列最多申请4节点,每个节点32个核,每个核分配内存2 GB,主频2.2 GHz, 操作系统CentOS 5.8,作业管理系统Torque 4.1.5。 表1 标准数据集及相关参数 对比实验结果如表2所示。其中, Acc表示测试精度, 计算时间和测试精度为重复10次实验的平均值。 表2最优分块数目、其他分块数目下并行计算时间(训练+测试)与测试精度比较 Tab.2Comparisonofparallelcomputationtime(train+test)andtestaccuracy(Acc)ofoptimalandotherblocks 数据集 时间 /sAcc/% 时间/s Acc/% 时间/sAcc/%时间/s Acc/%a9a B=2B=4^B=6B=1219.085.17±0.03 14.285.21±0.02 10.885.21±0.0312.885.17±0.02ijcnn1 B=2 ^B=8B=12B=1616.591.49±0.279.291.32±0.3410.7 91.24±0.2911.3 91.17±0.34w8a B=2^B=8B=12B=1437.498.87±0.2314.698.74±0.2618.5 98.68±0.1922.8 98.64±0.21webpam B=2B=6^B=12B=161 65792.79±0.1954292.86±0.29487 92.82±0.23508 92.75±0.25covtype B=2B=6^B=8B=141 37278.76±0.5656879.10±0.25292 79.11±0.63327 78.64±0.54SUSY B=2B=4^B=10B=1427079.16±0.0316279.16±0.0365 79.15±0.02101 79.15±0.03 实验结果表明,最优分块数相比于其他分块数下的并行模型预测精度相当,但计算时间大幅缩减。如在 webspam数据集上, 在最优分块数为12,相比于B=2而言,计算时间大幅缩短。 为了验证不同分块数对模型测试精度的影响,给出测试精度随着迭代次数的变化曲线,如图1所示。 图1 测试精度随着迭代次数的变化情况Fig.1 Test accuracy varies with respect to the number of iterations 结果表明,在相同迭代次数下,随着分块数的增多,模型的测试精度逐渐下降。这与第2节的泛化误差分析结果一致。 现有并行/分布式机器学习方法缺少有理论依据的数据分块数选择准则。针对这一问题,推导并行/分布式机器学习模型的泛化误差与分块数目的关系,折衷泛化性与并行效率,进而提出一个并行效率敏感的并行/分布式机器学习数据分块数选择准则。大规模支持向量机的理论分析和实验结果表明,所提出的数据分块数选择准则,可保证测试精度并提高计算效率。虽然所提出的数据分块数选择准则适用于ADMM框架下随机傅里叶特征空间中的大规模支持向量机,该数据分块数准则及分析方法也适用于其他并行/分布式机器学习模型,如大规模核岭回归等。
3 数据分块数选择准则

4 大规模支持向量机

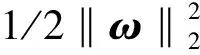
5 实验结果及分析

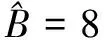

6 结束语
