融合高光谱和图像深度特征的腊肉分类与检索算法研究
2018-12-10,,,
,, ,
(北京工商大学计算机与信息工程学院,北京市食品安全与光谱大数据重点实验室,北京 100048)
腊肉以其独特的口味和口感,已经成为人们生活中必不可少的美食。然而,在腊肉制作的过程中,因为其生产环境条件不合格,致使腊肉品质无法满足国家标准,对于消费者来说,不仅是有害,而且致癌。目前的检测方法主要是依靠对腊肉进行理化实验和辅以感官等传统的检测方法,不仅效率低,而且成本很高。因而寻找快速、无损的肉制品品质检测方法变得非常迫切[1-2]。
高光谱成像技术已经成为食品安全无损、快速检测领域中一种不可或缺的方法[3-5]。高光谱图像中包含丰富的光谱和空间信息,充分利用高光谱图像中的光谱信息和空间信息是获得精确分类结果的前提。比如,章海亮等[6]采用最小二乘支持向量机作为对鱼的高光谱图像新鲜度分类模型,将90,31和49个特征变量作为LS-SVM模型的输入变量建立分类模型,基于SPA-LS-SVM和MCVE-LS-SVM模型预测集对鱼肉的新鲜度识别率达到了98%。董小栋等[7]通过光谱特征,利用SVM对其进行回归预测,实现菌落总数的预测。D.Madronal等[8]利用SVM的方法研究了一套实时的高光谱图像分类系统。
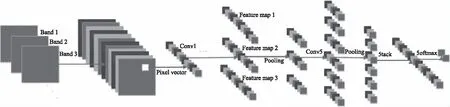
图1 CNN网络结构Fig.1 Architecture of CNN
然而,高光谱成像技术一直有两个难点:一是大部分研究学者的研究内容仅仅使用了高光谱图像的光谱信息,并没有结合高光谱图像中的空间信息;二是虽已有学者研究提取高光谱图像的空间信息的方法,例如纹理特征、结构特征等[9-10],但是提取特征的过程因为人工的干预、或者方法不当,导致结果有很大的不确定性,并不适应所有的数据集,即模型的泛化能力很差。如何提取高光谱图像的特征成为急需解决的问题。
深度学习在图像特征提取方面体现了卓越的性能。Yue等[11]研究,利用CNN融合堆栈光谱和空间特征,提出的深度学习框架中的DCNN-LR分类器比以前的高光谱分类方法提供了更好的分类精度。Chen等[12]提出一种基于FE的3D-CNN模型,通过多个卷积层、池化层和正则化方法提取高光谱图像的特征进行分类。罗建华等[13]对比传统的高光谱图像分类模型方法和深度学习分类的方法,表明深度学习卷积神经网络能够提高高光谱遥感图像的分类精度。马晓瑞等[14]借助基于深度网络提出适用于高光谱影像的特征提取方法和相似度学习获得全局信息实现全局决策,提高分类精度。然而对于高光谱在食品领域上的研究一直仅仅停留在光谱或者图像上的研究,并没有真正的达到“光谱合一”,主要还是在深度学习以前没有找到适合的特征提取的方法。本文以腊肉的高光谱图像为研究对象,将首次提出一种融合光谱信息的深度学习方法,并验证该方法的可行性和有效性。
1 材料与方法
1.1 材料与仪器
广式腊肠来源于北京市永辉超市。
SOC710VP高光谱分析仪光谱范围是400~1000 nm,共有128个波段,北京安洲科技有限公司。
1.2 实验方法
1.2.1 样品制备 一部分腐败的腊肉是在实验室培养箱(湿度>75%,温度大于50 ℃历时六个月)中制作的,将腊肉切块,每块腊肉厚2 cm,新鲜和腐败各选择50组,新鲜(挥发性盐基氮<25 mg/100 g)或腐败(挥发性盐基氮>25 mg/100 g),香肠是否腐败是根据GB2707-2005《鲜(冻)畜肉卫生标准》测定标准做理化值判断。
1.2.2 香肠光谱数据的获取 对采集得到的高光谱图像进行黑白板校正,以样本(去掉腊肉样本中的皮)的中心点向左右扩散,分别以半径为14、12、10、8、6 mm五个感兴趣区域等级,然后获取每个分等级的感兴趣区域的平均光谱曲线,然后对不同等级的感兴趣区域建立SVM分类预测模型,采用精确率和召回率来评价模型的预测的好坏。
为防止因为样品的不均匀性、光散射等因素造成的影响,在建模之前采用多元散射校正对光谱进行预处理。使用全波段进行SVM分类建模,因为数据的高维度和复杂度,不仅计算量多而且冗余的信息也比较多。利用PCA对预处理后的光谱进行降维,既能保证原始信息的完整性,还可以有效的去掉信息中相关性较高的信息。
1.2.3 高光谱图像数据的获取 深度模型使用的是三通道,获得样本的高光谱图像,新鲜和腐败各选择50组,利用ENVI软件选取256通道中三个通道,两两之间相隔25。在新鲜和腐败共100个原始样本上依次选择三个光谱通道Band10、Band35和Band60,Band11、Band36和Band61,如此交替共50次,共5000个原始样本,然后经过8种数据增广的方式裁剪、旋转和镜像等扩展至4万张数据样本。
1.2.4 高光谱图像特征 提取本文中使用的CNN结构如图2所示,共16层(只给出部分图),10个3×3的卷积层、3个5×5的卷积层、5个5×5的池化层、2个全连层和损失层。系统的输入是高光谱图像素的三个Bands[15-16],系统的输出是分类的标签,在本文中即新鲜或者腐败,它由几个卷积和堆叠层以及逻辑回归(Logical Regression)层组成。经过几个卷积和池化层之后,输入像素矢量可以转换成特征向量,它捕获输入像素矢量中的空间信息,最后,利用LR或其他分类器来完成二分类步骤。
1.2.5 逻辑回归 在本文中,模型参数被随机初始化,并通过误差反向传播算法进行训练,在进行参数更新之前,需要定义逻辑回归损失函数,概率值(Softmax)应用在多分类任务中,类别标签有两个以上的值。对于数据训练样本:
{(x^[(1)],y^[(1)]),…(x^[(m)],y^[(m)])},对应的类别标签有y^[(i)]∈{1,2,3,…k}。对于输入样本,设计针对每一个类别j的估算的概率值P(y^[(i)]=j│x^[(i)]),该值就是最终分为其中一类的概率。当为二分类时,可化简为逻辑回归。
在这之前,首先定义最大似然函数,训练样本相互独立,则公式为:
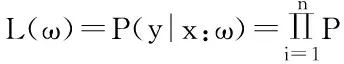
其中,P表示样本为正例的概率,取值范围为[0,1],在本文中,预测新鲜度,则新鲜为正例,ø(zi)腐败为负例。是逻辑斯蒂函数,有时简称为sigmoid函数,函数图像为S型:
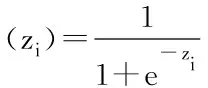
其中,z是网络的输入,及权重参数和特征的线性组合,z=ωTx=ω0+ω1x1+ω1x1+…ωnxn。
有了样本的预测概率P,在得到样本的类别就很简单了,如下:
通过上面的分析,对于最大似然函数,要找出的是最大值。则:
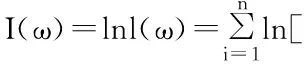
用梯度下降等优化算法来求解最大化似然时的参数。最大化和最小化本质上没有区别,所以将最大似然写成求最小值的损失函数形式:
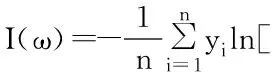
为了防止过拟合,加入L2范数,公式如下:
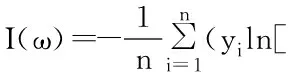
其中,m是权重的数量,λ是正则化系数,而1/2是为了公式方便推导。
1.2.6 光谱特征和图像特征 融合本文采用特征层融合。将CNN最后一层提取的深度特征与光谱信息特征融合,公式如下:
Vfusion=[Fspectral,Fhyper_image]
其中,Fhyper_image矩阵为CNN模型提取的1×n的矩阵,Fspectral即提取的腊肉高光谱图像的1×256维特征,Fspectra为光谱曲线提取的1×m的矩阵,即腊肉光谱曲线特征1×10维,Vfusion为融合后的特征矩阵1×(n+m),即1×266维。将融合的特征输入SVM网络中,本文采用的是RBF核,其中的C,g参数是通过粒子群算法进行优化后得到。
1.2.7 交叉验证 为了进一步测试模型的泛化能力,随机的将样本,此时的样本为输入的融合特征样本分成两份,如此操作十次,便可得到十份训练集和测试集,分别取十份训练集中的一份以及其对应的测试集,代入到CNN和SVM中训练[17],分别计算模型在其余剩下的九个测试集中的泛化能力。然后依次取一份对应训练集和测试集,则可完成十次,将计算十次的结果表现进行综合评价,涉及到的分类指标:
精确率:是针对预测结果而言,表示预测为正的样本中有多少是真正的正样本。有两种可能,一种就是把正类预测为正类(TP),另一种,将负类预测为正类(FP),如下:
召回率:是针对原来的样本,表示样本中的正例有多少被预测正确。也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN),如下:
F1 Score:是准确率与召回率的综合。可以认为是平均效果。百分百召回的算法不一定是最优算法,因此,F1 Score就显得尤为重要:
SVM分类的准确率公式如下:
2 结果与分析
2.1 光谱数据
以半径为10 mm获得样本的全波段原始反射光谱曲线如图2所示,图2(a)中是IDL83ENVI51(win64)软件选择band10、band35和band60后的图像数据,图2(b)中是感兴趣区域的平均光谱图,从图2中的光谱曲线可以看出,感兴趣区域的平均光谱曲线非常平滑,没有太多的噪声。
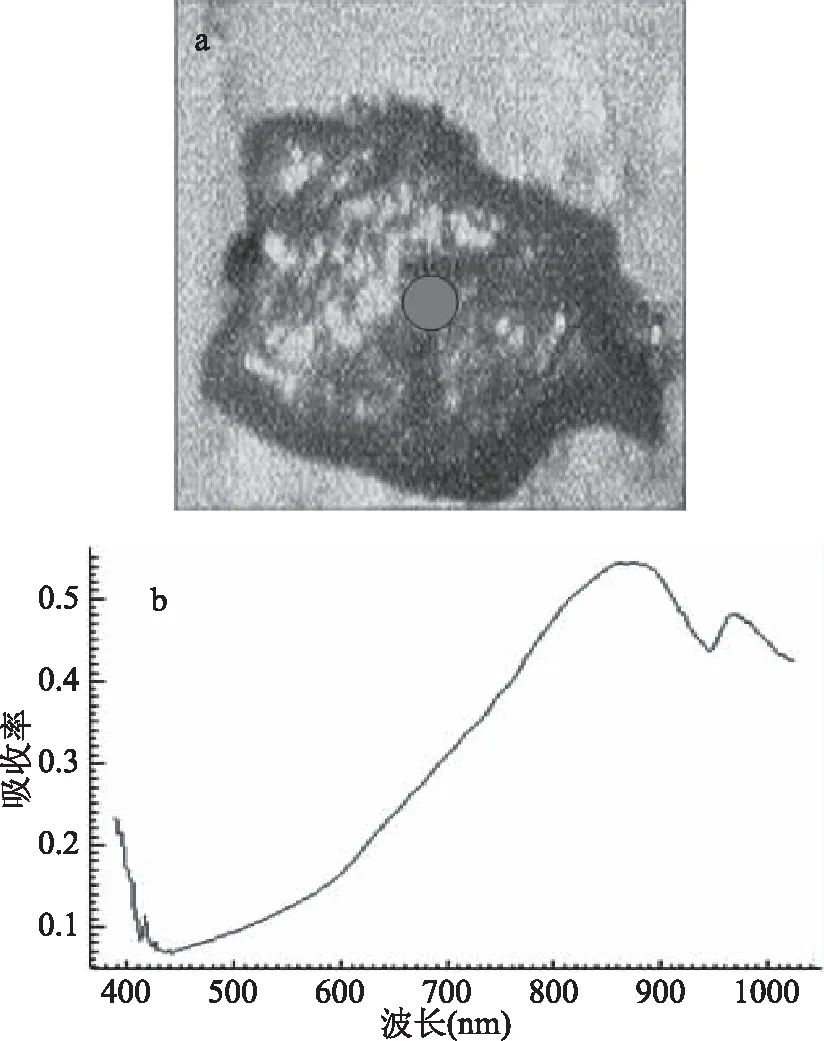
图2 样品原始光谱图像Fig.2 The original spectral image of the sample注:(a)样本的感兴趣区域;(b)感兴趣区域的平均光谱曲线。
2.2 光谱预处理和特征提取
如图3所示是预处理光谱经过PCA主成分分析后的结果图。
由图3可知,前10个主成分累计贡献率已接近100%,已经可以反映出样本的绝大部分所包含信息,所以在接下来的SVM分类模型中,选择前10个PCA主成分作为光谱特征和图像深度特征融合。
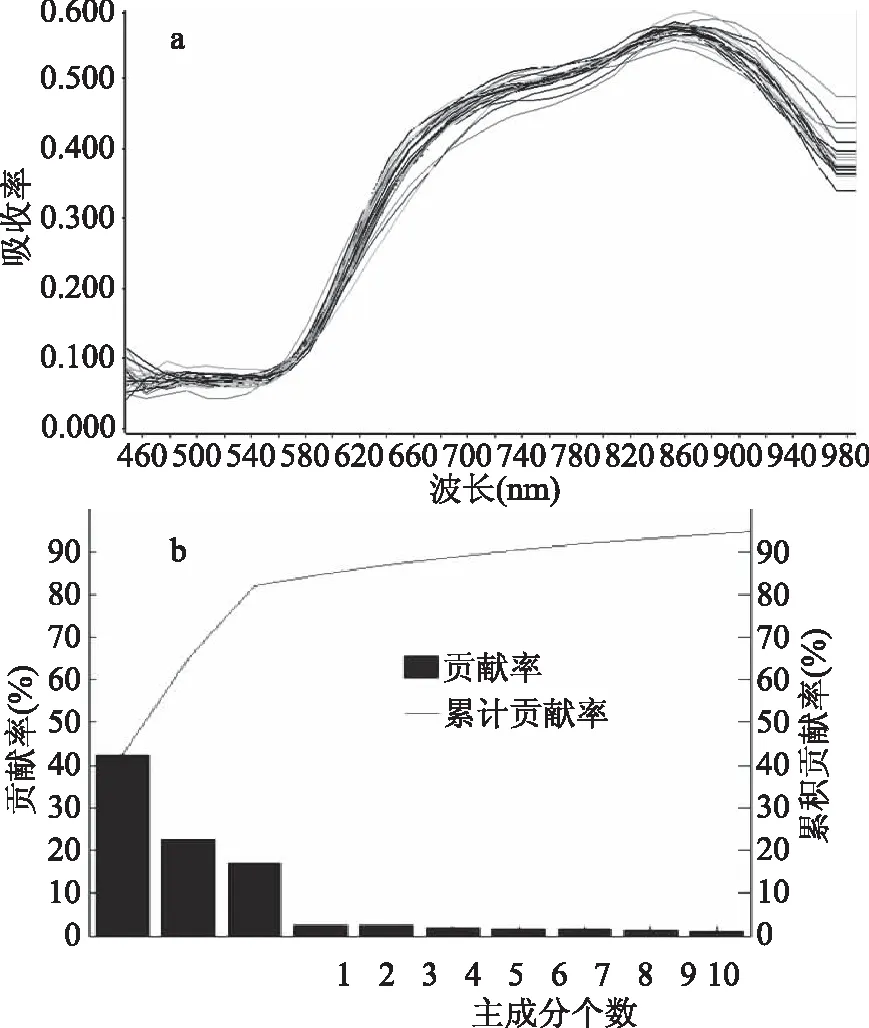
图3 主成分分析Fig.3 Principal component analysis注:(a)样本的原始光谱曲线;(b)感兴趣区域的平均光谱曲线。
2.3 光谱建模结果
表1是各个等级的感兴趣区域建立分类预测模型得到的预测结果。从表中可以看出,不同等级的感兴趣区域之间的预测结果,并没有很大的差距,所以,在采集时,采取了五个感兴趣区域的平均光谱后,在对五个等级的感兴趣区域的平均光谱进行平均,尽可能的将样本的整个面积都覆盖。
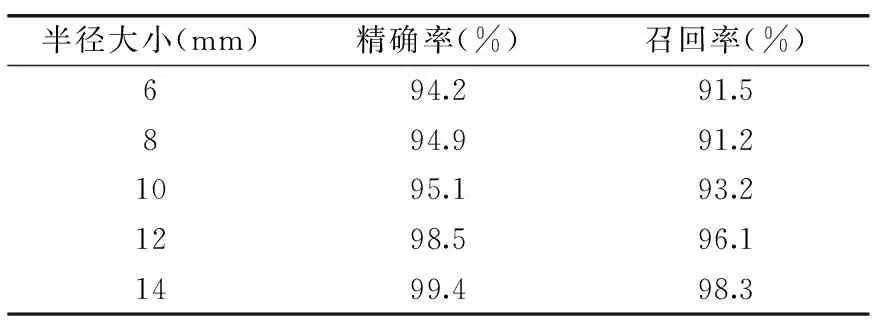
表1 不同大小感兴趣区域预测结果对比Table 1 The prediction results for different sizes of interest
2.4 高光谱图像增光结果
如图4所示,图4(a)中是实验过程中利用ENVI软件采集到的波段数为10、35、60的香肠高光谱图像样本,图4(b)中是经过增广的数据样本示例,包括利用旋转、裁剪、镜像等方法处理后的样本。在样本不足的情况下,进行增广可以防止网络的过拟合。
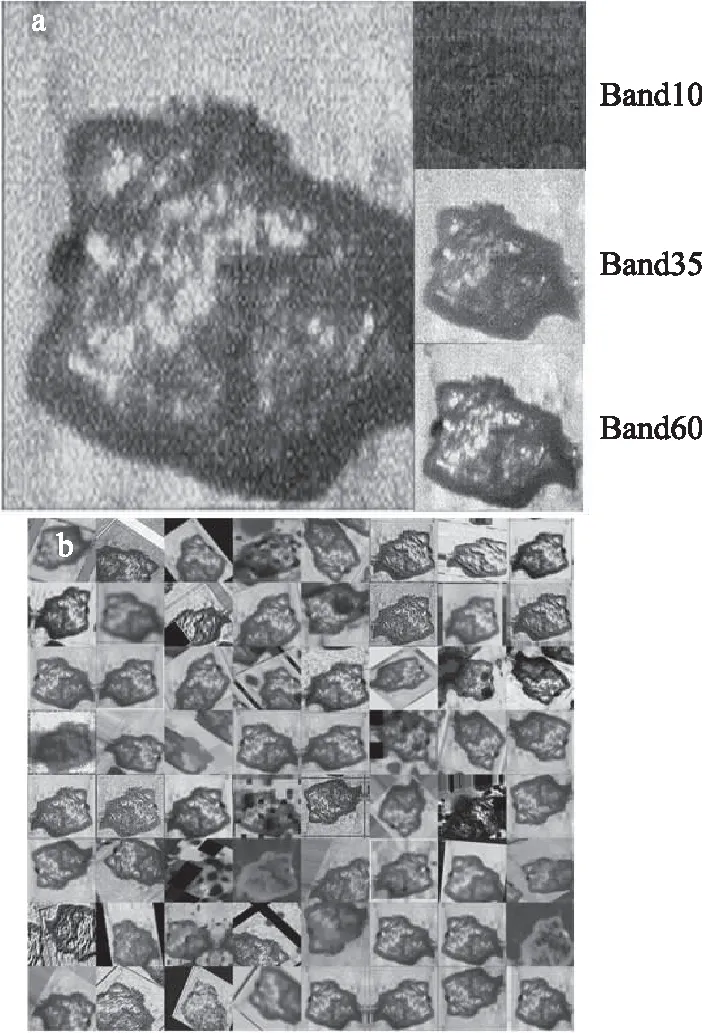
图4 样品原始高光谱图像Fig.4 Hyperspectral image of the samples注:(a)原始高光谱图像;(b)增广后的高光谱图像。
2.5 CNN图像特征分析
利用CNN提取特征,CNN学习到的特征可以很容易的可视化和理解[18-19],卷积网络学习到的特征并没有人为的干预,从而使得网络学习到的特征更能代表样本的特性,由图5可知深度学习到的特征为像素级、边缘、边缘的线性组合、深度特征,依次越深越抽象,越能对图像进行深度的表达,其实该过程可以简单的理解为将高维非线性的特征逐渐趋向于低维线性[20]。

图5 CNN特征图可视化Fig.5 Features visualization of CNN注:(a)高光谱图像原图,(b)~(f)分别为卷积第一层、第三层、第四层、第五层、第六层特征图。
2.6 CNN模型训练
样本图像调整为256×256×3像素,训练样本和测试样本的比例为3∶1。直接使用保存好的模型提取目标图像的特征性能难以满足要求,继续使用目标图像样本对训练好的CNN模型进行参数微调[21-23]。输入样本与训练过程一样,网络参数的初始化使用训练过程中得到的参数,得到损失(Loss)曲线和对应的ROC曲线如图6示,由图可知该模型损失函数的值在逐渐降低,并稳定到接近于零的值。
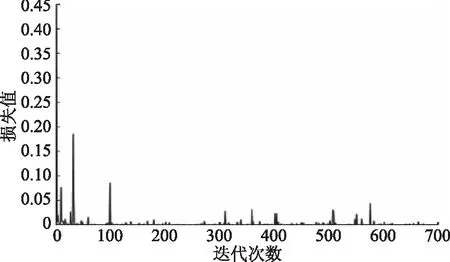
图6 CNN训练损失函数Fig.6 Training loss functionof CNN
由图6可知,损失函数值(Loss)明显趋于平稳,已经降到足够低(例如,Loss值已经降到0.00这个数量级),随着学习率(learning rate)的进一步降低,Loss还可能继续减小,说明该模型训练结果较好[24]。
2.7 CNN模型分类
以下是直接利用深度模型提取特征后,作为SVM的输入进行分类得到的结果,将结果用ROC曲线统计,结果如图7所示。
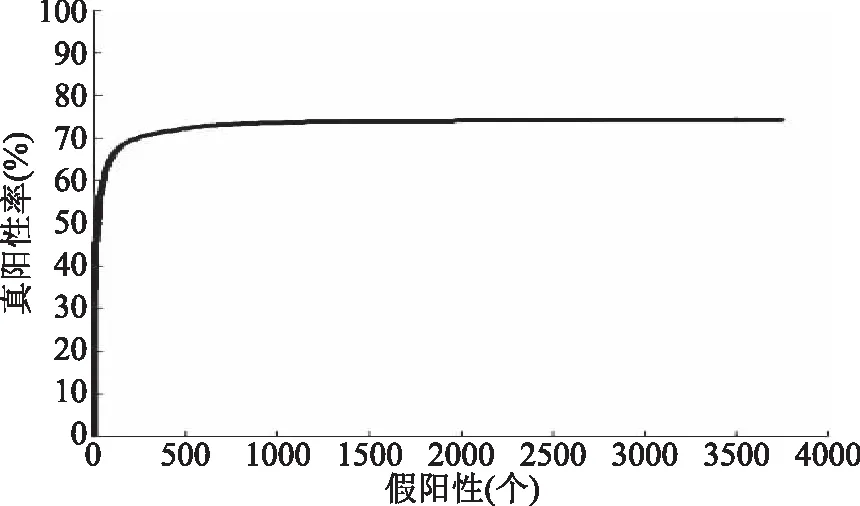
图7 测试样本ROC曲线Fig.7 ROC curve of thetest sample
由图7 ROC曲线可知,直接使用卷积神经网络训练好的模型提取特征后对样本进行分类,分类的准确率只有75.6%左右。
2.8 融合特征模型分类
考虑到以上分类的结果不理想,利用融合光谱特征和深度图像特征的方法得到的分类结果ROC曲线如图8所示。
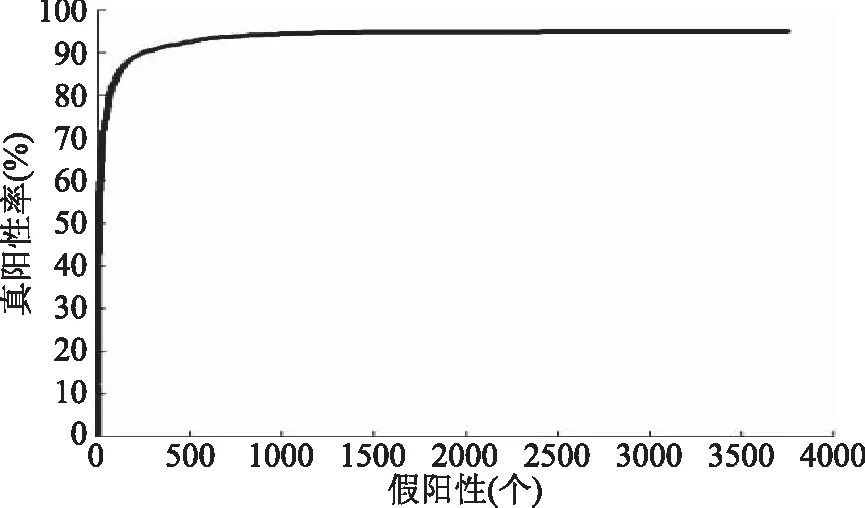
图8 测试样本ROC曲线Fig.8 ROC curve of the test sample
由图8可知,分类结果可以达到95.3%左右,说明加入的光谱特征更能体现样本特征的差异性。
2.9 融合特征模型交叉验证分类结果
由表2可知,利用该方法得到的模型的泛化能力高,SVM最终分类的准确度可以达到99.2%左右,并且真正地实现了“图谱合一”。

表2 分类结果Table 2 Results of classification
2.10 新鲜等级检索结果分析
在实际使用中,为了实现腊肉的快速检测,确定其新鲜度的等级,可以利用训练好的模型提取图像的深层特征,然后融合对应图片的光谱特征,采用欧式距离计算待检索样本与标准库样本的相似度,从而快速确定待检所样本的新鲜度等级,评级细则:
新鲜:相似度大于95%,则为标准新鲜(挥发性盐基氮<25 mg/100 g);
腐败:相似度大于95%,则为标准的腐败(挥发性盐基氮>25 mg/100 g)。检索实例如图9所示。
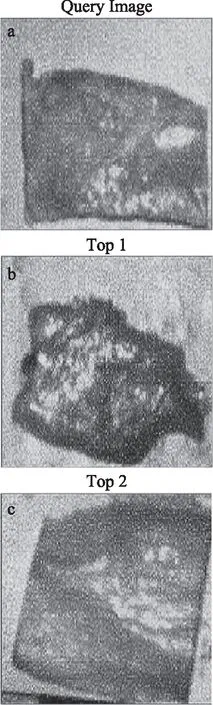
图9 检索样本和结果Fig.9 Results and thesearchsample注:(a)被检索腐败样本,(b)标准腐败样本,最高相似度Top1,(c)新鲜样本,最高相似度Top2。
检索结果对应相似度如表3所示,可知被检索样本最接近腐败,所以检索结果为腐败的腊肉:

表3 检索结果表Table 3 Results of the search
3 结论
利用CNN提取腊肉图像特征并融合光谱曲线特的方法,可以实现腊肉高光谱图像的分类和检索功能,该方法不仅充分利用了高光谱图像丰富的信息,自动学习和选择适合的特征,而且融合的样本的光谱曲线特征,可以大大提高样本的分类准确度。通过PSO+SVM分类算法,文中对比了图像深度特征方法、融合光谱特征和图像深度特征方法的分类结果,后者的分类结果准确率可以达到99.2%左右,可以满足最终的分类任务。另外,将CNN视觉特征应用于检索任务中有非常大的优势[17],利用欧氏距离方法计算被检索样本和标准等级样本的融合的特征向量,并按欧氏距离值从大到小排序,返回检索后的结果,既不破坏样本,也可以快速得到样本的新鲜度等级,完成检索任务。本文中下一步的改进之处则是对样本进行更精细的分类。
