基于Relief特征选择的心衰死亡率预测
2018-12-04姚丽娟李冬冬
姚丽娟,李冬冬,王 喆
1.华东理工大学 信息科学与工程学院,上海 200237
2.苏州大学 江苏省计算机信息处理技术重点实验室,江苏 苏州 215006
1 引言
心力衰竭(简称心衰)是一种复杂的临床症候群,是各种心血管疾病的终末阶段[1-3]。根据心衰发生的缓急,临床可分为急性心力衰竭和慢性心力衰竭,根据心力衰竭发生的部位可分为左心、右心和全心衰竭,还有收缩性或舒张性心力衰竭之分[3]。心衰是指由于心脏的收缩功能和(或)舒张功能发生障碍,不能将静脉回血充分排出心脏,导致静脉系统血液淤积,动脉系统血液灌注不足,从而引发起心脏循环障碍症候群[4-5]。心衰是全球慢性心血管疾病的重要组成部分。大多数严重的心血管疾病都会引起心力衰竭,如冠状动脉疾病(CAD)、高血压、瓣膜性心脏病和糖尿病均可引起或导致慢性心力衰竭的失代偿[4-5]。
近年来,它的发病率和死亡率在不断地增加,尤其是老年人。据国内外报道,因受试人群的不同,心力衰竭患者1年的全因死亡率达30%,重症心力衰竭患者在确诊后第1年内全因死亡率超过20%[6]。随着年龄的增长,70岁以上的老年人患心衰的可能性高达10%。心衰是威胁人类生命的一大疾病,因此心衰死亡率的预测是重要的,在医疗领域有重大意义。心衰病人的预测死亡率提供了重要的决策信息去辅助医生治疗病人。医生可以根据心衰病人病情的严重程度选择合适的治疗方案以提高病人的存活率。对于高死亡率的病人,可以及时采取有针对性的措施,避免错过最佳治疗时机或不恰当的治疗;对于低死亡率的病人,也可避免药物的过度使用,有利于医院资源的合理分配[7]。
近年来,医院积累了大量心衰病人的临床诊断信息,包括专家诊断,检查,用药,手术等临床数据。这些数据原先分散在电子病历系统EMRS(Electronic Medical Record System)、医院信息系统HIS(Hospital Information System)、实验室信息系统LIS(Laboratory Information System)等不同的系统中[8]。近年来,大多医院也意识到这些临床信息的隐藏价值,构建临床数据中心CDR(Clinical Data Repository)将这些信息系统地集成在一起。通过CDR系统,研究学者们可以拿到较为全面、系统的数据,这对于分析挖掘数据中的有用信息是十分有益的。
2 相关工作
2.1 特征选择
早期专家学者们只是对患上心衰的原因和导致心衰病人死亡的因素做一些分析,期望找到决定性的因素来避免心衰的发生或降低心衰死亡率。文献[3]发现有多种因素参与了导致心衰发生的病理生理过程,并详细分析了多方面的因素,如心衰病因、临床因素、心率失常因素。本文中获取的心衰病人数据集涵盖了病人的很多信息,例如:基本信息、诊断信息、用药信息、检查信息,一共有1 302个特征。但并不一定所有的特征都是与心衰死亡相关的,因此对原始特征集进行特征选择。特征选择本质就是将重要的特征选择出来,将无关和冗余特征进行剔除,这样便于精炼模型和提高模型的准确率[9]。研究表示,有效的特征选择可以降低系统的计算时间,提高分类的精确度,降低对系统硬件的需求[9-13]。传统的特征选择方法有基于相关度的Correlation-based Feature Selection(CFS)[9]、Relief[11]等,基于特征信息增益的 Information Gain(IG)[10]等,本文选取了经典的Relief方法,选择出重要的特征,同时也在实验部分证明了该方法的有效性。
2.2 模型选择
本文获取的心衰数据集是不平衡数据集,死亡的病例相对较少,存活病例较多。不平衡问题会使分类界面往少数类偏移,少数类的识别率低。解决不平衡问题一般有两种方法,一种是基于数据层面,通过对多数类进行降采样,或者对少数类进行过采样,或者降采样和过采样两者同时进行,来解决不平衡数据的问题[14]。文献[15]提出了一种运用K-means原理进行聚类降采样方法。文献[16]提出SMOTE过采样方法,采用启发式的策略,有选择地复制少数类样本。另一种是从算法方面,例如代价敏感学习。赋予各个类别不同的错分代价,赋予少数类比多数类更大的错分代价来解决不平衡问题。文献[17]在SVM的基础上对其做了改进,通过增大少数类的权重,减少多数类权重,来解决不平衡问题,称为biased penalties SVM(bp-SVM)[17-18]。极限学习机(ELM)在不平衡问题上,忽略了样本的离散程度,可能导致局部最优结果。文献[19]对此做出了改进,提出了基于类依赖的代价规则极限学习机(CCR-ELM)。文献[20]提出了一种基于重力的局部近邻方法GFRNN。通过对少数类和多数类赋予不同的质量来解决不平衡问题。另一种算法层面的改进为集成学习,文献[21]提出了适用于不平衡数据分类的Adaboost算法(ILAdaboost)。原始的集成算法Bagging在不平衡数据集上仍然存在不足,文献[22]通过引入一种大致平衡的采样方法改进后得到RB Bagging模型,能较大地体现出多样性。
随着机器学习的快速发展,它也为医疗领域提供了有效的支持,一些学者将机器学习应用到心衰的诊断课题。心衰诊断的相关工作主要是采用传统模型:逻辑回归(Logistic Regression,LR)、支持向量机(Support Vector Machines,SVM)、决策树(Decision Tree,DT)。文献[23]运用决策树建立模型分析与充血性心衰相关的因素,提取出关键因素。文献[24]用决策树模型预测刚出院的心衰病人一年内死亡或心衰恶化的概率,起到提早监控病人病情的作用。实验中与LR算法做出了对比,实验表明决策树模型的性能比逻辑回归模型好。文献[25]结合SVM和Adaboost建立心力衰竭分期模型,提高了心力衰竭诊断和分期准确度。文献[26]用SVM建立模型从自主和复极化心电图标记中心源性猝死和泵衰竭死亡,它们是慢性心衰病人不同的死因。文献[27]构建模型去预测心衰病人死亡或再次住院率。实验结果表明,预测30天后再次住院或死亡率时,SVM效果最好。在这些分类器中,SVM的应用最为广泛并取得了优越的预测性能。另外,本文的心衰数据集为不平衡数据集,因此本文采用bp-SVM[17-18]分类模型来实现对心衰病人死亡率的预测。
3 数据描述
3.1 数据来源
本文心衰病人的数据来自于上海曙光医院。上海曙光医院是一所中西医结合的综合性医院,它拥有完善的临床数据中心CDR系统,记录了病人大量的临床信息,其中包括心衰病人的数据信息。本文基于心衰病人的临床数据去预测心衰病人本次住院后30天内的死亡率。根据医院提供的数据,筛选得到心衰病人的样本库。心衰病人的样本库包含2009年3月至2016年4月期间在上海曙光医院有住院记录的心衰病人。样本库是基于以下标准选择的:(1)至少要有以下ICD-10-CM编码中的一个作为病人该次入院的首要诊断(编码:I11.0,I13.0,I13.2,I50,I50.1,I50.2,I50.3,I50.4,I50.9);(2)心衰病人在该次住院的前两天内需要有至少一次有心衰用药治疗方案的记录。通过上述两个标准进行筛选,留下了4 682个心衰病人的信息,其中有539个在医院死亡,病人平均随访时间为0.96年。这4 682个心衰病人一共有10 203条住院记录,每条记录都记录了病人的一些基本信息,例如,年龄,性别和一些结构化的临床诊断信息,包括心率,用药情况,常规检查,诊断信息。
3.2 数据特征处理
心衰病人部分临床信息是以数值存储,如年龄;部分是以文本形式存储,如用药情况。这些非数值化的信息无法直接利用,所以需要对这些信息进行预处理,将这些信息全部转换为数值化的数据,以便后续可以用机器学习算法来处理。
对于年龄和心率,保留原始数值。性别转化为数字,男性用1表示,女性用0表示。为了使CDR数据中的临床事件可以被表示为可计算事件序列,为每一个心衰案例构建一个向量表示。向量的维度等于不同的特征出现在CDR系统中的数量。每个维度的值代表在特定时间段内对应医疗事件是否出现。根据挑选出来的心衰案例,不同的ICD-10-CM诊断编码有1 222种,所以诊断信息被转化为1 222维的向量。医院专家手动将中国61种广泛使用的药物挑选出来,并进一步根据功能将它分为11个大类,即药物被转化为11维的向量,如表1中的药物类别所示。同时专家选出了22个有关心衰的检查,如表1中的检查项目所示。 参照每项检查的参考值,将检查的结果分为三类,偏高,偏低,正常。每项检查被转化为三维的向量,所有的向量都是用0,1数值表示。
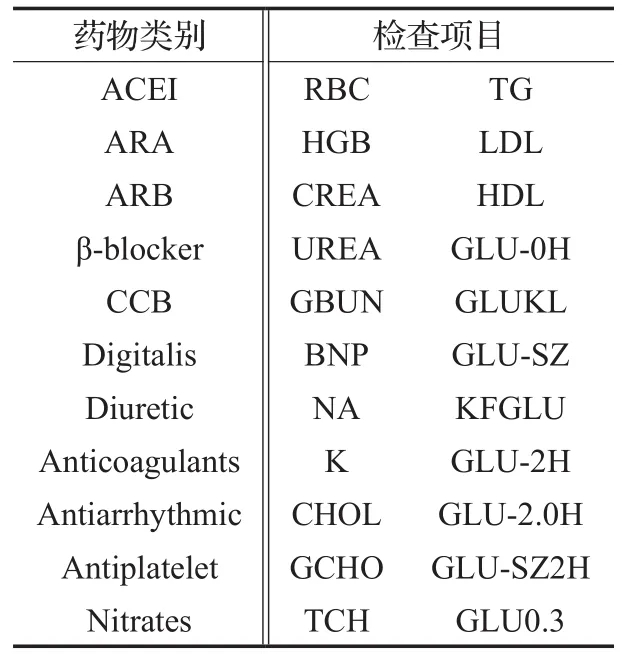
表1 11类药物和22项检查内容
经过上述的数据特征处理后可以得到一个数值化的数据集被命名为SSHF(Shanghai Shuguang Heart Failure)。SSHF数据集一共有10 203条心衰病人的住院记录,每条记录有1 302个特征。数据集对应的特征如表2所示。
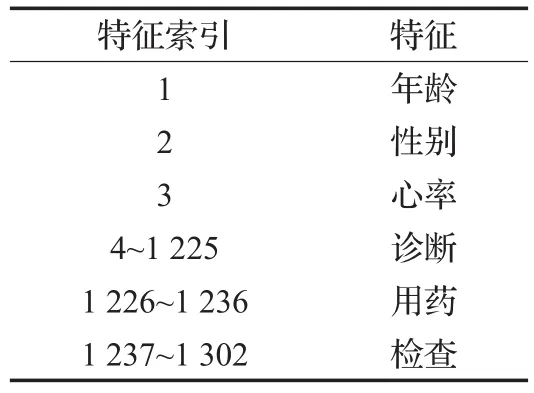
表2 SSHF数据集的特征解释
3.3 实验数据提取
由于本文预测的是心衰病人本次住院后30天内的死亡率,所以根据原始数据集SSHF,对数据进行筛选,将不能确定30天内是否死亡的案例剔除,最后留下6 260条住院记录。其中有562条死亡记录,5 608条存活记录,样本特征维度仍为1 302,特征与SSHF数据集一致。所提取的数据是不平衡的,不平衡率为9.98。将预测心衰病人30天后死亡率的数据称为SSHFmonth数据集以便区分。
4 特征选择和支持向量机
4.1 Relief特征选择
Relief算法是由Kira和Rendel首次提出来的[11]。算法的思想和K-NN分类算法有点相近。主要思想是:同一类中最近的样本比不同类中最近的样本更接近。假设这有N个训练样本:{F(1),c(1)},{F(2),c(2)},…,{F(N),c(N)}。其中,F(k)=[F1(k),F2(k),…,Fn(k)]表示样本k的特征向量,c(k)表示样本k的类标号。在Relief算法中,特征Fi的相关性s计算如下:
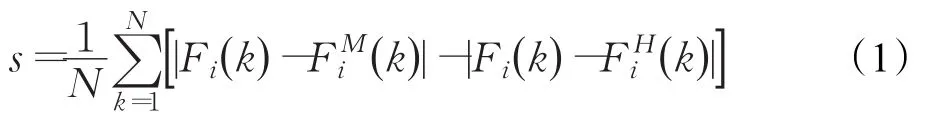
Relief算法为每个特征计算出一个分数,分数的高低代表该特征的相关性与可识别性,重要特征的特征得分会比较高。因此可以根据阈值来筛选特征,剔除特征得分不大于阈值的特征。
4.2 bp-SVM
支持向量机(SVM)是由Vapnik等学者提出的,支持向量机的目标是构造一个目标函数,寻找分割超平面ωx+b=0。
假定大小为N的样本集{(xi,yi),i=1,2,…,N},对于二分类问题,yi为样本类标号 yi∈{+1,-1}。对于线性可分问题,求最优超平面可转换为目标函数的优化问题。即:

参数C为惩罚系数,用于控制目标函数中两项的权重。
bp-SVM是为了解决不平衡问题对SVM做出的改进[17-18]。bp-SVM的模型为:
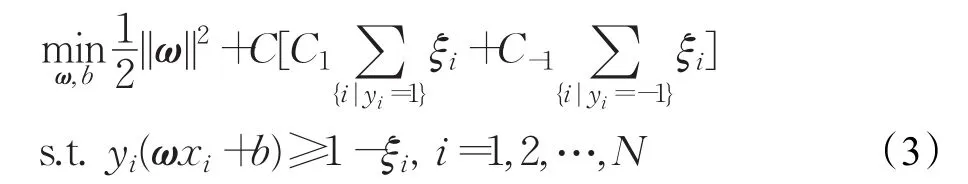
C1表示正类样本的权重,C1=N/(2×N1),C2表示负类样本的权重,C2=N/(2×N2)。N1和N2分别为正负类样本的数量,N为样本总数量。
当样本集线性不可分时,通过核函数可以将原样本集数据x映射到一个高维线性空间。不同的核函数可以对应不同的最优超平面。本实验中,选用径向基核函数(RBF)。公式如下:
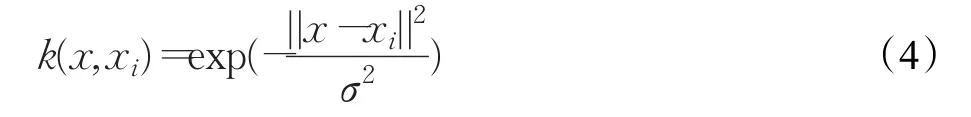
径向基核是一种局部性强的核函数,其可以将一个样本映射到一个更高维的空间内。该核函数是应用最广的一个,无论大样本还是小样本都有比较好的性能。
5 实验
5.1 实验设置
本实验中,bp-SVM模型选用径向基核(RBF)来预测心衰病人的死亡率,并采用5轮交叉验证作为超参数的选择,参数c与σ的范围都设置为[0.01~100]。因为SSHFmonth数据具有不同的量纲和量纲单位,这会影响后续的实验结果,所以采用Z-score归一化心衰数据,使各个特征处于同一数量级。考虑到数据的不平衡性质,选择三个度量标准来表示本文的实验结果:TPR(True Positive Rate),TNR(True Negatives Rate),AA(Average Accuracy metric)。TPR和TNR反映的是每一类的识别率,而AA反映的是整体性能。这三个度量标准的计算如下:

TP,TN,FP,FN分别为混淆矩阵的元素。所有的实验都是在载有英特尔四核的处理器,主频2.20 GHz,16 GB内存的Linux操作系统上,Matlab环境。
5.2 实验结果及分析
Relief特征选择的阈值,对应阈值下的保留的特征维度以及三个度量标准下的结果、对应的方差和SVM训练时间都被记录在表3中,最好结果加粗表示。

表3 特征维度,预测结果及对应的方差描述
由表3可知,Relief算法设置不同的阈值,就可以得到不同维度的数据。阈值越大,所保留的数据特征就越少。当阈值为0.02时,系统达到了最好的性能,AA指标可以达到80.81%。此时的维度被降为231,相比于原始的1 302维,特征维度大幅度减少。计算时间也由最初的49.46 s降低到15.48 s,系统速度有了很大的提升,而且,系统性能并没有因为维度的减少而降低,由78.3%提高到80.81%。这正说明了有效的特征选择可以降低特征维度,减少计算时间,提高系统性能。
TPR代表正类的识别率,当系统达到最好性能时,TPR为79.59%,与最高的80.36%相当。TNR最高可达91.65%,系统性能最好时的TNR为82.03%,并不是最高的。TNR只是反映了负例的识别率,并不代表整体性能。一般来说,TNR变高时,TPR会变低,因为TNR的提高是以牺牲TPR为代价,如图1所示。而对于心衰数据,在保证整体性能的前提下,更关心的应该是指标TPR,因为希望心衰死亡案例都可以被识别出来。如果将高死亡率病人识别为低死亡率病人,那可能会耽误病人的救治,使病人错过最佳治疗时间和治疗方案。所以指标TPR的准确度比TNR更为重要,这样更符合现实意义。

图1 特征维度与系统性能关系图
从图1中,随着特征维度的减少,TPR和TNR指标逐渐趋于稳定,平均精度AA也逐渐保持稳定。当特征维度降到20维左右,系统性能并没有下降很多,仍保持在一个较高的水平70%以上,TPR和TNR也没有大幅度下降的情况。根据图2,可以得知特征维度的降低与SVM训练时间的关系。随着特征维度的减少,系统训练时间会降低,最后趋于稳定。这也说明了特征选择可以减少计算时间。有效的特征选择会提高系统准确度,而且根据表3所示,系统维度降低到11维时,系统性能仍能达到72.38%,指标TPR也仍能达到73%。但并不是意味着特征可以无限度减少,当特征维度减少到一定值后,系统性能会下降。因为过少的特征会损失很多信息,导致分类结果准确度下降,影响系统性能。所以需要选择一个合适的维度,既能保证系统性能,又减少了计算时间和特征维度。所选特征的维度是根据Relief算法的阈值来设置的,可以根据实际情况来定义。
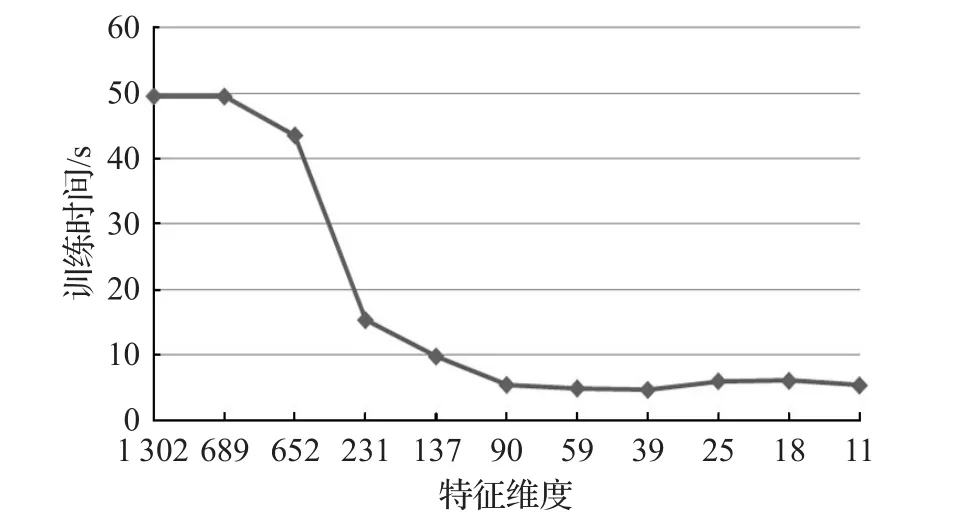
图2 特征维度与系统训练时间关系图
5.3 实验对比
在众多传统特征选择算法中,本文采用的是Relief特征选择方法,来对心衰数据进行特征选择。为了证明所选用的Relief特征选择算法的有效性,将Relief与传统的CFS和IG特征选择算法进行对比,对比实验基于bp-SVM分类模型。实验结果如表4所示,结果粗体表示每个指标下最好的结果。
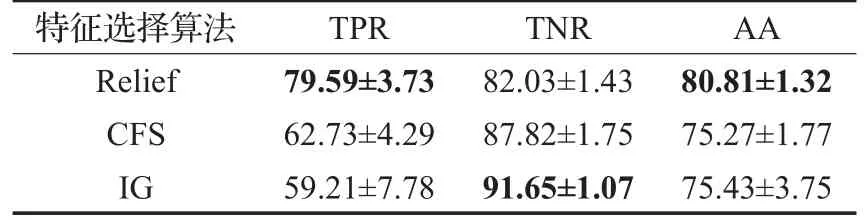
表4 Relief与其他特征选择算法效果对比%
在对心衰疾病的分析和预测中,最为普遍采用的预测模型是SVM、逻辑回归、决策树、K近邻,正如相关工作中所示案例,一般情况下,SVM模型更优。为了证明本文预测系统采用的bp-SVM模型的正确性和有效性,将bp-SVM与逻辑回归(LR)、决策树(DT)、K近邻(KNN)模型进行对比。bp-SVM和对比算法都是基于特征选择后的数据样本上,Relief阈值为0.02。算法参数如下:K-NN,K的取值集合为{1,3,5,7,9},取其中最好结果作为K近邻的最好结果,bp-SVM参数见5.1节中参数设置。结果如表5所示,粗体为最好结果。
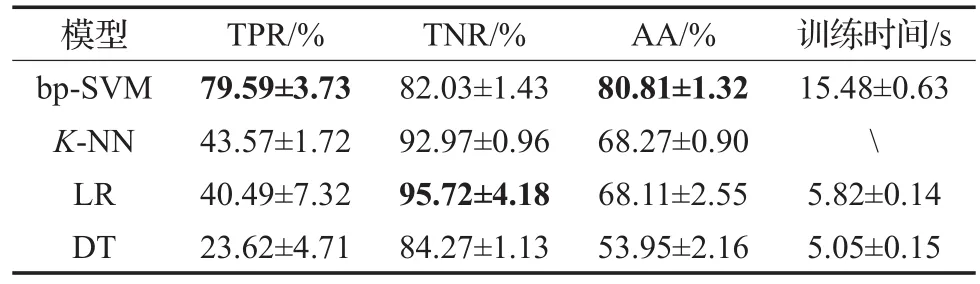
表5 bp-SVM与其他模型的效果对比
由表4可以看出,Relief特征选择方法相对于CFS和IG效果更好一些。虽然IG在负类识别率TNR上占很大优势,但是在TPR上表现不佳。在整体性能AA上,IG与CFS表现相似。而Relief方法在TPR和AA标准上都是表现最优。实验证明了Relief特征选择方法在心衰数据集上的有效性。此外,由表5可以看出,bp-SVM相比较于K-NN、LR、DT,预测效果最好。bp-SVM在平均分类精度AA上比K-NN和LR高出了约12%,比DT高出了26.96%,这体现了bp-SVM模型的优越性。而且,本文的实验数据是不平衡数据集,所以更加关注正例的识别率TPR,希望能识别出高死亡率的心衰病人,以便医生能及时采取医疗措施,提高病人的治愈率。虽然就负例识别率TNR而言,bp-SVM比K-NN和逻辑回归模型低了约10%,和决策树模型相当,但是bp-SVM较其他对比算法,在正例识别率更加准确,大大超越了K-NN、LR和DT。所以bp-SVM在总体性能AA上仍然保持了它的良好性能。实验证明采用bp-SVM模型构建心衰死亡率预测系统可以在一定程度上提高预测准确率。
6 结束语
本文根据真实数据和需求,提出了一个死亡率预测系统,可以预测心衰病人本次住院后的30天内的死亡率。系统性能可以达到80.81%,该系统可以应用到心衰死亡率的预测。系统预测心衰病人的死亡率,医生可以根据死亡率的高低,提出有针对性的治疗方案以便提高临床诊断。同时也避免了心衰病人潜在的死亡危险不能及时被发现而导致错失治疗时间。同时,该系统用少量的特征就可以达到较高的准确率,减少了计算时间,让系统预测更加快速。因此这个心衰预测系统在现实生活中是有价值和实际意义的。
