基于地面激光雷达点云数据的树种识别方法
2018-12-04张隆裕吕春东牛利伟
王 佳 张隆裕 吕春东 牛利伟
(1.北京林业大学精准林业北京市重点实验室, 北京 100083; 2.北京林业大学测绘与3S技术中心, 北京 100083)
0 引言
森林在维持生态平衡中发挥着重大作用,为了保护森林资源,树种识别是其中重要一环,而传统意义上的人工实地调查方法费时费力,激光雷达作为一种主动遥感技术,近年来在国际上发展迅速,使得遥感技术用于树种分类和识别的效率大大提高[1-3]。通过激光雷达进行数据扫描,运用点云数据软件处理,可以提取一系列基于激光雷达点云数据的森林参数和变量,进而实现树种识别。在提取森林参数方面,LIANG等[4]通过将分离出来的树干点云数据分割成切片,达到自动识别树干位置的目的。STRAHLER等[5]利用红外激光雷达获取林分影像,从中识别单木树高及胸径提取叶面积指数,效果良好。KOUKOULAS等[6]使用LiDAR和多光谱遥感数据对阔叶落叶林的单木位置、高度和树种进行制图,采样间隔约为2 m。CLARKM等[7]用小光斑LiDAR系统估测热带雨林的地形高程和树高,采样密度为每平方米9个回波点。刘清旺等[8]利用机载激光点云数据提出了一种双正切角树冠识别算法,获取树冠和树高数据。树种识别方面,余超[9]使用分类回归树、神经网络和支持向量机算法进行研究区内主要风景林树种的分类,分类回归树的总体分类精度可以达到87.1%,支持向量机算法为76.91%,神经网络法只有73.85%。魏田[10]从三维点云数据提取单木信息,选用树干收缩度为树种分类的因素之一,基于核函数三次多项式的支持向量机的算法分类,并用单因素分类、双因素分类与多因素分类的正确率进行对比,得出单因素和双因素的分类精度低的结论。PLAZA等[11]从光谱特征角度出发,利用波谱角的不同对城区中的树种进行识别,分类效果较好;GEORGE等[12]基于Hyperion影像,采取支持向量机法和面向对象分类法对树种进行识别,结果显示,面向对象分类法的精度高于支持向量机法。文献[13-15]均是利用高光谱和机载雷达相融合的方法对复杂森林树种识别,发现总体分类精度和树种分类精度比单一高光谱数据有所提高。ALONZO等[16]利用激光雷达数据在基于冠层尺度上对常见树种进行分类,分类精度提高了4.2%。李永亮等[17]建立了BP神经网络模型,输入高光谱特征参数,输出森林树种类别,分类综合精度可达93.3%。
从上述研究可以看出,目前大多数树种识别研究主要集中于利用多光谱、高光谱遥感结合机载激光雷达,对大区域森林垂直结构的获取能力较强,但对林冠下层结构描述不详细,树种识别精度也有待提高,而地面激光雷达的研究仍主要集中在森林参数的提取方面,主要包括树高、冠幅、郁闭度和生物量等。本文通过地面激光雷达获取树木点云数据,利用机器学习较为主流的3种方法,通过对样木学习生成分类器,依照校园立木的形态参数对其进行树种的分类识别。
1 立木特征因子提取方法
1.1 胸径提取算法
胸径为树干距地面1.3 m处的直径。设单木点云中Z坐标最小的为Zmin,在点云数据中检索出Z坐标为Zmin+1.3 m的所有点,设为集合P。求出P中所有点的重心O,对于∀Pi∈P,求其到O的距离,最大的距离则为胸径DBH(Diameter at breast height),单位为cm。
(1)
1.2 枝下高提取算法
枝下高位置是树木主干与树冠的分割点,对枝下高的测量一般是测量离地面最近的明显大枝的高度,枝下高即为树木的主干高度。如果树木从1.3 m以下分叉,则认为是两棵树,1.3 m以上分叉就认为是枝干。所以枝下高大于1.3 m。对于每棵树,监测不同高度处树干的干径和重心位置。在每棵树的点云中取出该树从1.3 m至最高处的点云。从1.3 m处开始对点云数据水平分层,单层厚度10 cm。采用Hough变换和圆拟合方法得到该层树干圆心和半径。以获取的圆心为圆心,提取半径为2r范围内点云数据(r为每层树干处拟合圆的半径),将该薄层数据体元化,体元尺寸为5 cm×5 cm×10 cm,若体元内回波点个数n>2,则认为该体元被覆盖。遍历所有层,得到各层的覆盖体元个数,即为树干处垂直剖面。在树干处点云分布比较集中,而且各层的覆盖度变化不大,到枝下高处,覆盖度明显变大。根据这个特点,可以得到枝下高位置。该位置所在高度与树干最低端所在高度之差即是要提取出的枝下高BH,单位为m。
BH=Zmaxb-Zminb
(2)
式中Zmaxb——第1分枝树干位置坐标
Zminb——立木底部坐标
1.3 冠高提取算法
冠高的提取过程比冠幅的提取更方便。冠高定义为树冠顶端到树冠最低端间的竖直距离。在传统测量当中,冠高的测量难点在于分辨树冠最低端。在冠层底部较复杂的情况下,找到最低端的过程需要进行仔细观测。利用地面激光雷达可以对单木的点云进行三维检视,可以有效解决枝叶间互相遮挡的问题,方便寻找树冠最低端,准确地提取冠层部分点云。
在树冠点云数据中,树冠顶部即是其Z坐标最大值Zmaxc,树干第1分枝的位置是Z坐标最小值Zminc,其二者的差值即是树冠的冠高CH,单位为m。
CH=Zmaxc-Zminc
(3)
1.4 树高提取算法
在完整的立树点云数据中,立木顶部即是其Z坐标最大值Zmaxt,立木底部的位置是Z坐标最小值Zmint,其二者的差值即是树高TH,单位为m。
TH=Zmaxt-Zmint
(4)
枝下高为从地面算起的第1个分枝与地面之间的竖直距离,冠高为冠层顶端到冠层最低端的竖直距离,树高为树的顶端到地面的距离。三者的关系如图1所示。
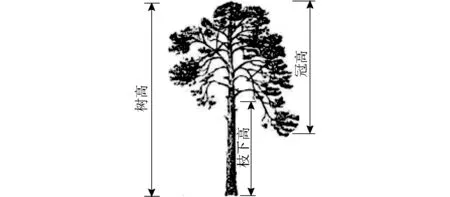
图1 枝下高、冠高、树高的关系Fig.1 Relationship between heights of branch, crown and tree
1.5 最长冠幅和垂直最长方向冠幅提取算法
点集的凸包是指一个最小凸多边形,满足点集Q中的点或者在多边形内或者在多边形上。本文中提取冠幅的先导步骤是采用二维凸包的快速算法获得树冠的外轮廓,如图2所示。
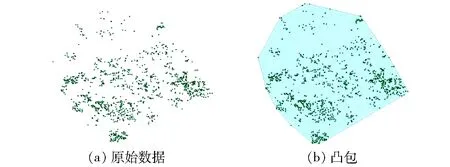
图2 冠层点云的凸包Fig.2 Convex hull of canopy point cloud
设凸包顶点的集合为V。对于凸包的每一个顶点Vi,计算其在二维坐标内与其他顶点Vj的欧氏距离,距离最长的两个顶点之间的距离就是该树的最长冠幅LS,单位为m。

(5)
式中XVi、YVi、XVj、YVj——顶点Vi、Vj的坐标
设直线l:y=kx+b,令l穿过最长冠幅的2个顶点,将顶点Vi、Vj代入l中,有
(6)
直线l过Vi、Vj中点的垂线l′可表示为
(7)
设凸包内的点的集合为P,对于∀Pi∈P,判断其是否在l′上。设在l′上的Pi的集合为P′,P′中欧氏距离最长的两点的距离即为需要求的垂直最长方向冠幅LCS,单位为m。
(8)

最长冠幅(LS)与垂直最长方向冠幅(LCS)的关系如图3所示。

图3 最长冠幅(LS)与垂直最长方向冠幅(LCS)Fig.3 The longest spread of crown cover (LS) and the longest cross-spread of crown cover (LCS)
2 树种识别方法
2.1 支持向量机方法
支持向量机产生自在线性可分前提下最优分类面的发展,分类线的方程是xω+b=0,对分类线方程进行归一化处理,得到样本的集合(xi,yi),i=1,2,…,n,x∈Rd,y∈(-1,1),该样本集线性可分,且满足
yi[|(xi,ω)|+b]-1≥0 (i=1,2,…,n)
(9)
支持向量机的核函数有3类,分别是神经网络核函数、径向基核函数和多项式核函数。每一种核函数对应不同类型的非线性映射问题。
2.2 分类回归决策树方法
分类回归决策树方法(CART)是BERIMAN等[18]在1984年提出的一种非参数方法。分类回归决策树依用途可以分为分类决策树和分类回归树两种。本文中根据多种测树因子对样地中选取的4种树种进行分类,主要用到的是分类决策树。分类决策树将分类变量的情况作为因变量(又称目标变量、输出变量)。假设自变量(又称输入变量、属性)是随机向量Xn×m(X1,X2,…,Xm),Xi既可以是连续变量,也可以是离散变量,设它的定义域为Dom(Xi) 。Y是随机变量,作为因变量,如果Y为分类变量,设其定义域是Dom(Y)={1,2,…,J},那么由自变量Xi和因变量Y构建的决策树就是分类决策树。分类决策树将分类变量的情况作为因变量。CART是非参数方法,它不需要假设总体服从先验分布。CART在计算过程中充分利用二叉树结构,是一种二分递归的分割方法。样本集在一定的分割规则下被分割为2个样本集,生成的决策树每个非叶子节点都有2个分支。此过程在样本集上始终重复进行,直到不可再分成叶子节点。
2.3 随机森林方法
BREIMAN[19]在随机决策森林方法的基础上提出了把分类树组合成随机森林再汇总分类树的随机森林算法。不同的CART决策树由投票决策组合成随机森林[20],随机森林算法对训练集的随机性策略分为训练样本选择和特征属性选择。随机森林的抽象表示如下:假设有K棵CART树组成随机森林,产生第i棵决策树的函数表示为:fi(x,θi):X→Y,i=1,2,…,K,这里x为输入向量,θi为随机向量(独立同分布),这个向量是作用在训练样本的机制,因此随机森林可以表示为
F={f1,f2,…,fK}
其中K为森林的规模。在构造完学习器之后,使用随机森林对样本数据进行分类,并且随机森林和多数集成学习算法一样,均在决定类别的过程采用投票机制,表示为
(10)
式中I(·)——示性函数,取值为0和1,括号中条件成立时,示性函数值为1,条件不成立时,示性函数值为0
投票最多的类别被随机森林选为样本的最终类别。
2.4 树种识别精度评价方法
为了评价几种模式分类模型的精度,采用准确率、召回率和F值3个指标。准确率和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用于评价结果的质量。准确率为提取出的正确信息条数与提取出的信息条数的比值,召回率为提取出的正确信息条数与样本中的信息条数的比值,两者取值在0和1之间,数值越接近1,查准率或查全率就越高。F值为准确率、召回率的乘积与准确率、召回率之和比值的2倍,也是正确率和召回率两者之间的调和平均值。
为了避免验证样本影响模型精度的偶然性,本研究中采用交叉验证的策略选取验证样本。交叉验证的过程为:将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用K个模型最终验证集分类准确率的平均数作交叉验证下分类器的性能指标。K一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取2。
3 实验结果及分析
3.1 实验数据获取与处理

图4 FARO Photon 120型地面激光雷达Fig.4 Picture of FARO Photon 120 model ground-based LiDAR
在北京林业大学校园内选取树木,利用FARO Photon 120型地面激光雷达(如图4所示,主要参数如表1所示)对研究区内树木进行了激光扫描,获取树木的点云数据。对同一树木进行了多次设站扫描,首先需要对多次扫描的点云进行拼接。拼接后的点云图像中除目标树外还存在许多噪点,在立体视图中删除多余噪点。研究共采集到26棵银杏、20棵鹅掌楸、26棵臭椿、20棵西府海棠的激光点云数据。

表1 FARO Photon 120型地面激光雷达的主要参数Tab.1 Parameters of FARO Photon 120
数据采集方法:在树干胸高处朝南或朝北方向贴标靶纸,在样木周围无遮挡的地方均匀放置3个参考球,选择能同时见到3个参考球的均匀分布的3个位置设站,理想的测站位置间隔角度为120°(以待扫描树为参考),安装上地面激光雷达并连接好相关设备,对扫描范围、扫描分辨率等参数进行设置之后,就可进行树木扫描。本研究设置扫描区域为水平方向360°,垂直方向155°,扫描分辨率每一圆周10 000点,每株样木需从不同角度扫描至少3次,完整扫描一株样木需10 min左右,扫描场景如图5所示。

图5 点云数据处理Fig.5 Process of point cloud data
将地面激光雷达扫描数据导入计算机中,通过其配套软件Faro Scene,对点云数据进行加载、套准、过滤、剔除、导出等内业处理。打开Faro Scene软件,直接把测站数据加载到软件中,第一次打开软件时,扫描数据的Mio扫描点数值默认为62,这个数值是根据计算机的内存自动显示的,本文所涉及的点云提取使用的计算机内存为8 GB,经过在不同内存的计算机中进行点云数据提取实验,结果显示默认的Mio扫描点的数值均能满足精度要求。图5为加载的测站点云数据显示。
当对图5示例的立木扫描的3站数据都加载到统一的工作空间的窗口下,当窗口的显示标记为绿色的3个公共参考球,表示3站数据已经很好地拟合。在3D模式下,手动选取单木点云数据,剔除冗余数据,最终提取结果如图6所示,然后导出所需要后处理的数据格式.xyz。

图6 单木数据提取结果Fig.6 Extraction results of single tree for four species
3.2 测树因子提取结果及精度分析
为了验证点云数据提取的测树因子精度,将点云数据提取的测树因子和传统方法进行了对比,对比结果见表2~5。其中表2中给出了银杏的各测树因子的绝对精度与相对精度。从总体来看,各测树因子中枝下高的相对误差均值是最小的,这主要是因为枝下高与胸径的量纲有所不同。从绝对精度来看的话,胸径的绝对精度误差分析最小,为1.72 cm,枝下高的绝对精度均值为0.17 m,比胸径绝对精度均值大一些,可以满足实际测量需求的程度。对于涉及高程的测量,常用的其他测量手段也会产生比较大的偏差,高密度的三维点云在高程提取上可以比其他手段有更好的效果。枝下高的误差最低,冠高的误差其次,树高的误差最大,产生该现象的原因主要有:①立木的最高点的确定有难度。②在单木最高处的点云密度较小,在前期点云预处理和后期树高提取的过程中都有被忽略掉的可能。另外,两个冠幅相关的测树因子的误差都要大一些,主要是因为冠幅会受风速、风向等环境因素影响产生变化,而且冠幅传统测量方法也是目视的方法,方法本身也有很大的不确定性,同时目视确定最长冠幅的方向有难度。垂直最长方向冠幅的误差相对最长冠幅误差大,主要原因是提取过程涉及垂直方向的确定,并且有可能遇到多棵树树冠相互遮挡的情况。
表3为臭椿的测树因子误差统计。各个测树因子的误差之间的相对规律与银杏测树因子的误差大致相同。皆为胸径的绝对误差最小,除了胸径外,枝下高和冠高的相对误差最小,树高相对误差相比而言较大,两个冠幅因子的相对误差最大,而其中垂直最长方向冠幅的相对误差比最长冠幅的相对误差大。不过与银杏不同的是,臭椿胸径的相对误差最小。

表2 银杏测树因子误差统计Tab.2 Measuring factor error statistics of Ginkgo biloba

表3 臭椿测树因子误差统计Tab.3 Measuring factor error statistics of Ailanthus altissima
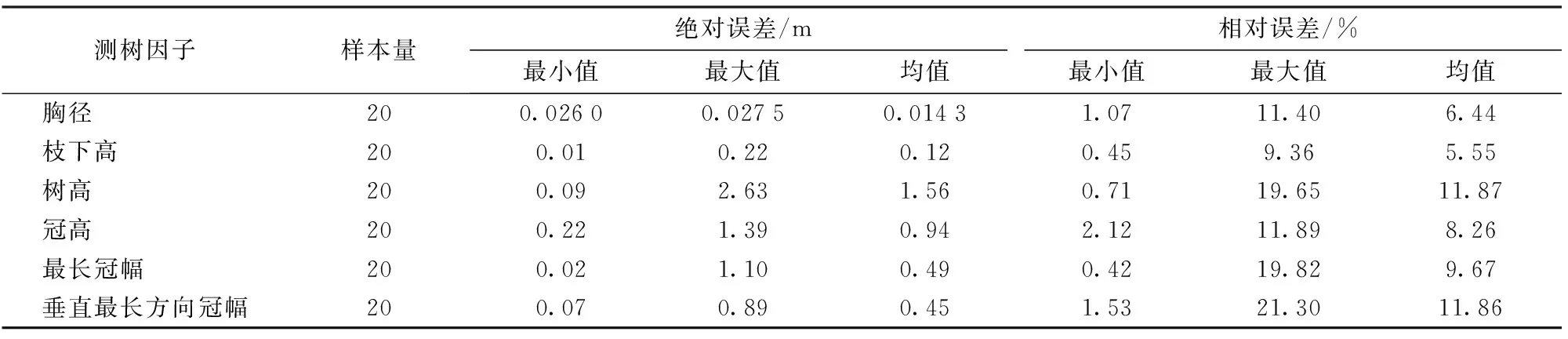
表4 鹅掌楸测树因子误差统计Tab.4 Measuring factor error statistics of Liriodendron chinense

表5 西府海棠测树因子误差统计Tab.5 Measuring factor error statistics of Malus micromalus
表4是鹅掌楸测树因子的误差统计。鹅掌楸的胸径相对误差没有枝下高相对误差小。冠幅的相对误差要小于树高的相对误差。
表5是西府海棠测树因子的误差统计。西府海棠测树因子中,相对误差最大的是树高和最长冠幅,达到了9%以上,而胸径和枝下高相对误差最小,在5%左右。
3.3 树种识别结果及精度分析
选取训练样本的胸径、树高、枝下高、冠高、最长冠幅、垂直最长方向冠幅这6个参数,使用训练样本的多个属性训练分类器,可以使分类器兼顾样本的各方面特征,而不是像只是用一个属性时分类器只考虑一个属性中的特征,忽略其他特征。样本的属性越多,其特征被描述得越全面,越能更好地训练分类器,从而使分类器可以产生更好的分类效果。本研究采集了立木的6个测树因子,较为全面地描述了样本立木的形态特征。将所有属性全部参与分类器的训练,分别采用支持向量机、分类回归树和随机森林方法进行树种分类。检验分类准确性时,采用交叉验证。分树种取样本的80%为训练样本,剩余20%的样本留作验证样本,在检验分类效果时使用。使用精准率和召回率评价分类的效果。结果如表6所示。

表6 多参数分类评价指标(测树因子)Tab.6 Multi parameter classification evaluation index (tree measurement factor)
从表6中可以看出,从总体准确率、召回率和F值来看,分类效果最好的是分类回归决策树法,其次是随机森林法,但两者相差不大,最差是支持向量机法;具体分析每个树种,3种方法对臭椿的识别都较好,准确率都在0.9以上,而鹅掌楸的识别差异较大,最好的分类回归法准确率可以达到0.938,而最差的支持向量机只有0.125。银杏、鹅掌楸和西府海棠的情况均类似。
本文除了采用常见的6个测树因子之外,还通过组合2个常见测树因子得到更多的树形参数。组合而成的特征参数可以归结为5个类别,分别反映出立木的树干、树枝、树冠和全树的形态结构特征。其中全树的特征参数1个,树干的特征参数2个,树枝的特征参数2个,树冠的特征参数1个。具体见表7。表中Lc为冠长,D为胸高直径,LHB为在一定高度处的树枝长度,LHS为在相同高度处的树干长度。
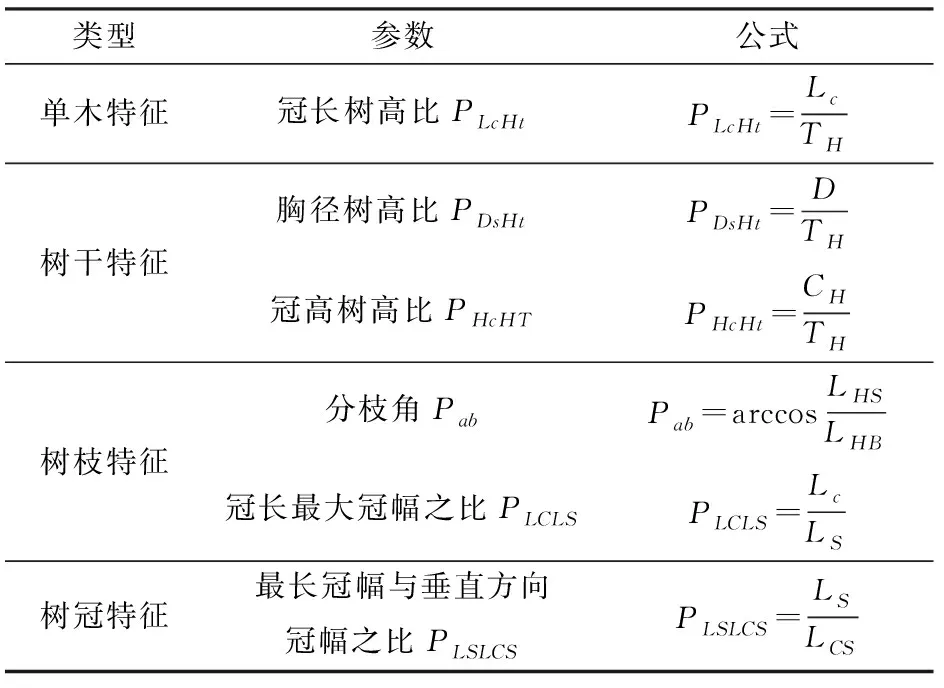
表7 组合特征参数Tab.7 Combined feature parameters
参照陈国定等[21]和刘镇波等[22]提出的鲁棒性分析的方法,将提取的测树因子和组合特征参数分别在SPSS 17中进行识别分析,结果输出如图7所示。从图7a可以看出,利用测树因子的方法,4个树种识别质心(图中质心1、2、3、4分别表示西府海棠、臭椿、鹅掌楸、银杏)聚集度高,树种之间辨识难度增加,特别是鹅掌楸和银杏,2个树种基本混在一起,大大增加了识别难度。而组合特征参数可以很好地解决这一问题,从图7b可以看出相对于测树因子,4个树种质心相距较远,树种识别容易,减少识别错误发生的几率,同时也说明了组合特征参数鲁棒性要优于测树因子。

图7 鲁棒性分析结果Fig.7 Results of robust analysis
4个树种样本数据的冠长树高比、胸径树高比、冠高树高比、分枝角、冠长最大冠幅之比、最长冠幅与垂直方向冠幅之比6个指标,各参数对全部样本,分别采用支持向量机、分类回归决策树和随机森林方法进行树种分类。分树种取样本的80%为训练样本,剩余20%的样本留作验证样本,在检验分类效果时使用。使用准确率和召回率评价分类的效果。
从表8可以看出,采用组合特征参数进行树种识别,3种分类识别方法均取得了较为满意的结果,其中随机森林和支持向量机,总体准确率、召回率和F值都在0.9以上,而分类回归决策树略低于0.9。其中臭椿识别效果最优,准确率达到0.96,最差的鹅掌楸是0.792,相对于单一特征参数分类而言,平均准确率、召回率和F值均大幅提高,识别效果相对更优,这主要是因为多参数可以使分类器依据全面的立木结构情况对其进行分类,而不是只依据单一的结构情况。
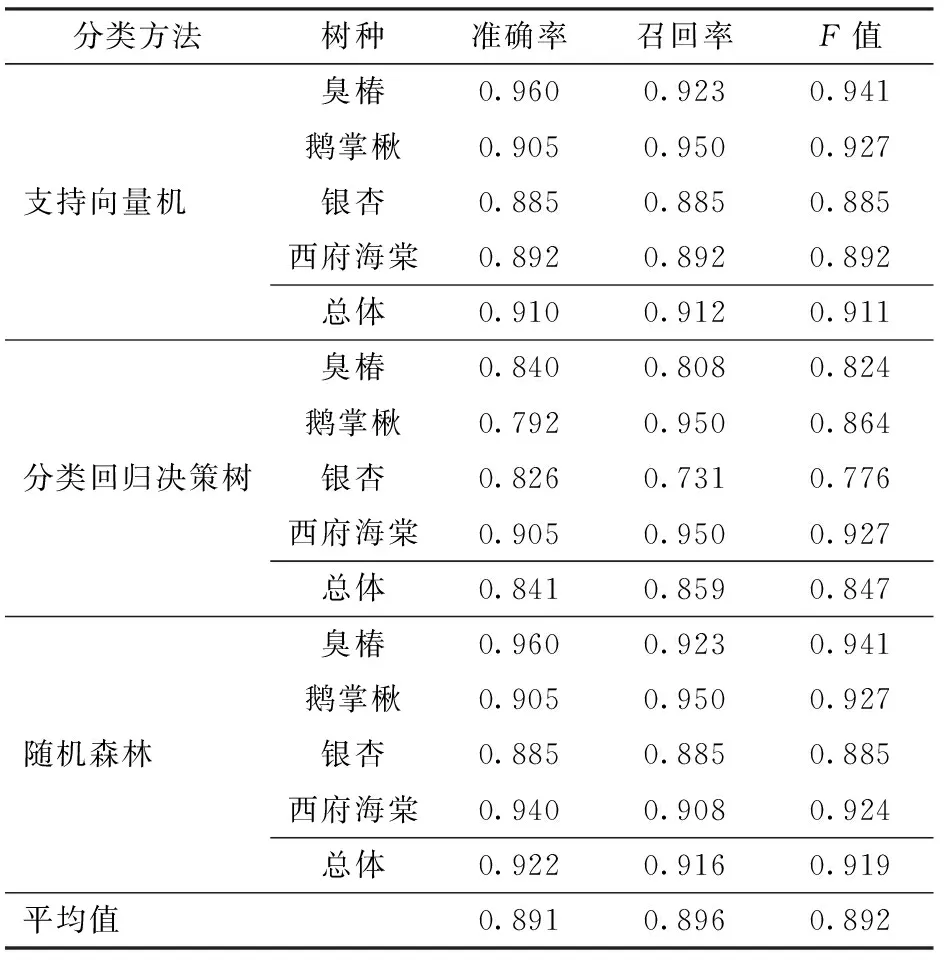
表8 多参数分类评价指标(组合特征参数)Tab.8 Multi parameter classification evaluation index (combined feature parameters)
4 结论
(1)利用地面激光雷达提取单木测树因子及识别树种是可行且有效的,与传统仪器和测量手段相比具有明显优势。利用一台地面激光雷达设备对单木进行一次扫描,获取的点云数据可用于提取树高、胸径、枝下高、冠高、冠幅等测树因子,减轻外业测量工作量,提升效率;在提取测树因子的同时,根据树木测树因子和组合特征参数可以准确识别不同树种,为今后建立树种识别信息库提供技术支撑。
(2)从提取的测树因子结果来看,胸径的绝对误差最小;一般而言枝下高的相对误差最小,其次是胸径、冠高、树高,冠幅的相对误差最大。从不同树种来看,臭椿提取胸径的相对误差最小,银杏提取枝下高、树高、冠高的相对误差最小,鹅掌楸提取冠幅的相对误差略小。
(3)对于树种识别问题,采用了树木测树因子和组合特征参数2种方式,分别利用支持向量机、分类回归决策树和随机森林方法,加入分类识别器,进行树种识别。通过分析发现,总体来说使用组合特征参数识别效果比单一使用测树因子优,不同分类方法相比,从平均准确率和召回率来看,随机森林方法优于支持向量机和分类回归决策树方法。
