中心损失与Softmax损失联合监督下的人脸识别
2018-11-30余成波田桐熊递恩许琳英
余成波 田桐 熊递恩 许琳英


摘要:深度学习在人脸识别领域已经取得了巨大的成就,针对当前大多数卷积神经网络采用Softmax损失函数进行特征分类,增加新的类别样本会减小类间距离的增长趋势,影响网络对特征判别的问题,采用了一种基于中心损失与Softmax损失联合监督的人脸识别算法,来提高网络对特征的识别能力。在Softmax基础上,首先,分别对训练集每个类别在特征空间维护一个类中心,训练过程新增加样本时,网络会约束样本的分类中心距离,从而兼顾了类内聚合与类间分离。其次,引入动量概念,在分类中心更新的时候,通过保留之前的更新方向,同时利用当前批次的梯度微调最终的更新方向,该方法可以在一定程度上增加稳定性,提高网络的学习效率。最后,在人脸识别基准库LFW上的测试实验证明:所提的联合监督算法,在较小的网络训练集上,获得了99.31%的人脸识别精度。
关键词:深度学习;中心损失;Softmax损失;动量;人脸识别
中图分类号:TP391.4
文献标志码:A文章编号:1000-582X(2018)05-092-09
Abstract: Nowadays, deep learning has made great achievements in face recognition. Most of the convolutional neural network uses the Softmax loss function to increase the distance between classes. However, adding samples of new classes will reduce the distance between classes and the performance of the network. In order to improve the recognition ability of the network characteristics, a face recognition approach based on joint supervision of center loss and Softmax loss is proposed. On the basis of Softmax, first of all, a class center is maintained in the feature space for each class of the training set. When a new sample is added to the training process, the network will constrain the distance of the classification center of the sample, and thus both intra-class aggregation and inter-class separation are considered. Secondly, the concept of momentum is introduced. When the classification center is updated, by retaining the previous update direction and using the gradient of the current batch to fine-tune the final update direction, the method can increase the stability and improve the learning efficiency of the network. Finally, the test experiments on the face recognition benchmark library LFW (labeled faces in the wild) prove that the proposed joint supervision algorithm achieves 99.31% of face recognition accuracy on a small network training set.
Keywords: deep learning; central loss; Softmax loss; momentum; face recognition
近年來,随着深度学习的不断发展,人脸识别技术已经获得了飞跃式的发展[1]。相较于传统的人脸识别技术,如:特征脸、局部特征分析法、基于几何特征法等,深度卷积神经网络(CNNs, convolutional neural networks)进行的人脸识别,能有效的克服诸如光照、多姿态、面部遮挡等干扰。深度卷积神经网络是通过不断的训练从图片中提取特征,克服了手动选择中人为的主观性[2]。对于CNNs的常用人脸识别框架如图1所述。
早期的人脸识别通过不断的研究网络结构来提升人脸的识别精度,其中较著名的网络有Lenet[3]、Alexnet[4]、Googlenet[4]、VGG[5]、Deep Residual Learning[6]等,其研究结果表现在网络越深,获得的识别精度就越高。然而,这些网络结构需要大量的人脸数据库、较大的计算资源及消耗大量的计算时间,而让许多研究者望而却步,并成为人脸识别的研究瓶颈。为了解决这个问题,文献[7]提出了迁移学习方法,并得到迅速发展,被广大研究者广泛使用。迁移学习可以利用现有的训练好的网络模型,在样本数据不是特别充足的情况下获得较好的结果。但迁移学习的前提是训练数据具有相似性,否则性能将会降低。
由于相似性的训练数据不具有普遍性,而简单的网络结构不能满足需求,因此研究者将目光转向了对数据特征关系的研究。在2005年,文献[8]中就提出可通过计算2幅人脸图像的相似距离来识别人脸,孪生网络[9]被广泛使用,孪生网络能够很好的提取2个输入获取到的特征的相似性。2014年,Taigman等人[10]通过对人脸进行三维对称处理,使用DeepFace孪生网络结构进行训练,该方法在LFW(labeled faces in the wild)人脸数据库上进行测试的精度达到了97.25,接近人眼识别精度。Sun等人[11]在DeepFace的基础上提出了DeepID(deep hidden identity features)网络,采用Softmax损失函数作为监督信号,通过在CelebFaces 和 WDRef结合的较大的人脸数据库上进行训练,最终在LFW上达到了97.35%的精度。
Softmax损失监督网络在面对未训练过的新标签样本时,由于网络对特征的泛化能力不足,其识别效果不佳。为了解决这个问题,文献[12]中提出使用识别信号和验证信号进行联合监督,其中识别信号能增大不同人脸的差异性,验证信号能减小人脸类内差异,使得在LFW上识别精度达到99.15%。与选取某一层直接使用损失进行分类的方法不同,文献[13]提出了triplet损失函数作为监督信号,直接学习图像到欧式空间上点的映射,2张图像所对应的特征的欧式空间上的点的距离直接对应着2个图像是否相似,来获得更好的分类效果,该方法在LFW上达到了99.63%的精度。
文献[13]中的方法对训练样本数量要求很高,并且计算量增大,训练步骤也变得复杂。为了解决这个问题,研究采用了一种中心损失与Softmax损失进行联合监督的方法,该方法在增大不同人脸间距离的同时,减小同一个人脸内部的距离,从而使学习到的特征具有更好的泛化性和辨别能力,提高深度卷积网络对特征的识别能力。其优点是收敛速度更快、所需样本数量比其他方法少,最后,通过在基准LFW库的实验也证明了算法的有效性,获得了99.31%的人脸识别精度。
1 损失函数及算法步骤
在卷积神经网络的前向传播中,通过网络最后一层预测结果与真实结果的比较得到损失,计算误差更新值,通过反向传播对网络的所有权值进行更新。其中,损失层是前向传播的终点,也是反向传播的起点。通过对预测值和真实值的计算,得到损失函数(loss function)的值,而分类中的优化过程实质就是对损失函数进行最小化的过程。可以采用梯度下降法等优化算法计算最小值。
1.1 Softmax损失
Softmax 函数是 Logistic 函数[14]的推广,主要用于解决多分类问题。Softmax所获得的结果代表输入图像被分到每一类的概率,若是一个K分类器,则输出是一个K维的向量(向量中元素的和为1)。
通过联合监督方法不仅解决了对比损失中无法采集合适的样本对的问题,同时也解决了三重损失中复杂采样的问题。在该中心损失中,采用了对比损失中同类样本损失公式,用同类样本中的类中心替换了其中的一个同类样本,而异类时,是直接采用Softmax损失进行计算。
1.4 网络参数配置及算法步骤
为了有效的实现非限制条件下的人脸识别,将Softmax损失与中心损失相结合,其联合损失的监督示意图如图3所示,对于整个训练网络的具体参数的配置见实验部分。
通过对网络结构的研究,构建网络,对于联合监督算法部分,将算法的输入抽象为:训练数据集{xi},分别初始化池化层和loss层的参数θc、W及{cjj=1,2,…,n},同时输入参数:λ、α和学习率μt,其中迭代的次数t初始化为0。输出则抽象为输出参数θc,因此归纳联合监督的人脸识别算法步骤如下所示。
2 实验及结果分析
为验证算法的有效性,选用人脸基准库LFW人脸库进行人脸识别实验。实验选用网络中单独使用Softmax损失监督的Model A、Softmax損失与对比损失联合监督的Model B几个使用最广泛的网络模型与算法的Model C进行对比分析。
2.1 网络模型及数据集
2.1.1 网络模型
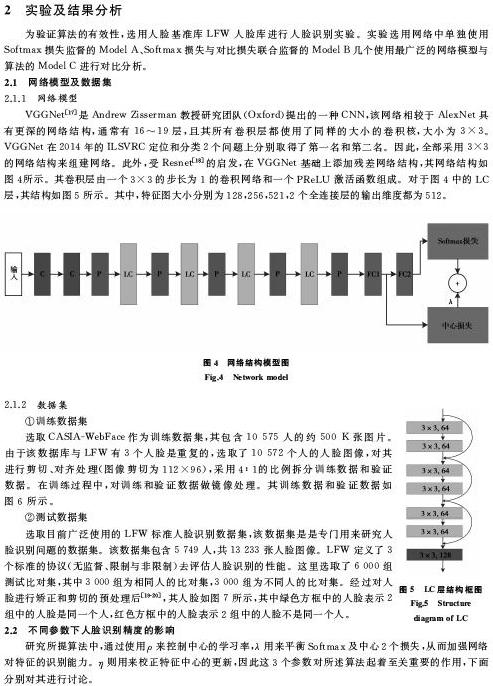
VGGNet[17]是Andrew Zisserman 教授研究团队(Oxford)提出的一种CNN,该网络相较于AlexNet具有更深的网络结构,通常有16~19层,且其所有卷积层都使用了同样的大小的卷积核,大小为3×3。VGGNet在2014年的ILSVRC定位和分类2个问题上分别取得了第一名和第二名。因此,全部采用3×3的网络结构来组建网络。此外,受Resnet[18]的启发,在VGGNet基础上添加残差网络结构,其网络结构如图4所示。其卷积层由一个3×3的步长为1的卷积网络和一个PReLU激活函数组成。对于图4中的LC层,其结构如图5所示。其中,特征图大小分别为128,256,521,2个全连接层的输出维度都为512。
2.1.2 数据集
①训练数据集
选取CASIA-WebFace作为训练数据集,其包含10 575人的约500 K张图片。由于该数据库与LFW有3个人脸是重复的,选取了10 572个人的人脸图像,对其进行剪切、对齐处理(图像剪切为112×96),采用4∶1的比例拆分训练数据和验证数据。在训练过程中,对训练和验证数据做镜像处理。其训练数据和验证数据如图6所示。
②测试数据集
选取目前广泛使用的LFW标准人脸识别数据集,该数据集是是专门用来研究人脸识别问题的数据集。该数据集包含5 749人,共13 233张人脸图像。LFW定义了3个标准的协议(无监督、限制与非限制)去评估人脸识别的性能。这里选取了6 000组测试比对集,其中3 000组为相同人的比对集,3 000组为不同人的比对集。经过对人脸进行矫正和剪切的预处理后[19-20],其人脸如图7所示,其中绿色方框中的人脸表示2组中的人脸是同一个人,红色方框中的人脸表示2组中的人脸不是同一个人。
2.2 不同参数下人脸识别精度的影响
研究所提算法中,通过使用ρ来控制中心的学习率,λ用来平衡Softmax及中心2个损失,从而加强网络对特征的识别能力。η则用来校正特征中心的更新,因此这3个参数对所述算法起着至关重要的作用,下面分别对其进行讨论。
1)参数λ对人脸识别精度的影响
本实验,通过固定ρ及动量η,改变λ参数的方式进行试验,从参考文献[15]中知道,当ρ=0.5的时候,能够获得较高的中心学习率。因此,第一个试验,固定ρ=0.5,η=0.5,而使λ从0变化到1,从而学习到不同的网络模型。
在LFW数据集上的测试结果如图8所示,由图可知,所提Softmax损失及中心损失联合监督算法的优越性,其人脸识别测试精度,要高于仅Softmax损失监督下(当λ=0时,训练网络仅有Softmax损失监督)的测试精度。同时,从图8中也可以得到,一个合适的λ值有助于提高人脸识别精度,参数λ的最佳结果为0.003。
2)学习率ρ对人脸识别精度的影响
根据本章实验(1)中获得的最优结果,本节实验固定λ=0.003,η=0.5,而让ρ从0.01变化到1,从而学习到不同的模型。
分别采用这些模型在精准库LFW上做人脸识别测试,可以得到该实验的人脸识别精度如图9所示。由图9分析得出,选择合适的ρ值,同样有助于提高训练网络的人脸识别精度。根据实验分析,参数ρ的最佳结果为0.6。
3)参数η对人脸识别精度的影响
根据实验(1)、(2)获得的最优结果,本节实验通过固定ρ=0.6,λ=0.003,而让参数η在0到1之间η发生变化,从而训练到不同的网络模型。通过LFW数据集上的测试,得到该实验的人脸识别精度,其实验结果如图10所示。
由图10分析得出,一个合适的动量选择,能够提高训练网络的人脸识别精度,从实验结果来看,当η取0.9时,人脸识别精度最高。同时,将其与图9、图10对比发现,最佳的λ、ρ及η值,能够在总体上提高人脸识别精度。
2.3 不同网络模型下的人脸识别精度比较
ROC(receiver operating characteristic)曲线和AUC(area under curve)常被用来评价一个二值分类器(binary classifier)的优劣[21]。其中,AUC被定义为ROC曲线下的面积。为了说明所提联合监督算法在人脸识别精度中的优势,将其与目前获得了最高人脸识别精度的几种经典网络模型比较分析,其中,网络模型是在CAISA-webface数据集上训练而来的,该数据集中的任何一张人脸都与LFW上的人脸不同,并且所采用的参数ρ=0.6,λ=0.003,η=0.9。
在实验中,通过人脸验证试验绘制ROC曲线,从而评价算法训练下的分类特征的好坏。人脸验证试验是:对于LFW中给定的6 000组测试人脸,分别判断他们是否是同一个人。经过试验,在LFW测试集中达到了99.31%的平均精度,与表1中所列方法的平均精度和ROC曲线的比较分别如表1和图11所示,其中用Model A表示仅使用Softmax损失函数监视的模型,Model B表示Softmax损失和对比损失联合监视的模型,而Model C则表示所提模型。
从表1及图11的实验数据分析来看,所提算法(Softmax损失与center损失联合监督)比单一的损失监督Model A,在相同训练数据图片的情况下获得了较高的识别精度,在LFW基准库上识别精度从97.35%提高到99.31%。该对比结果可以证明,联合监督方法相比单一监督方法,在对特征的分类能力上有显著的提升。其次,研究还将算法与当前使用最为广泛的联合监督Model B进行比较,从实验结果来看,表1显示Model C的人脸识别精度从原来的99.28%提高到99.31%,表2可見其训练时间已经缩短。实验表明网络收敛速度已经加快,在减小类内距离上有更加显著的优势。最后,表1还列出了当前表现最好的几种经典模型,结合图11的ROC曲线。可见所提算法模型的识别结果,能够在使用较小训练数据集的情况下,获得较高的人脸识别精度。
3 结 论
笔者提出了一种基于中心损失与Softmax损失联合监督的人脸识别算法,在LFW人脸库上的实验结果表明:算法能够提高网络对特征的识别能力,将中心损失与Softmax损失相结合,克服了Softmax损失在面对未训练过的新标签样本时,泛化能力不足的问题。同时,重点引入动量的概念,在分类中心更新的时候,通过保留之前的更新方向,同时利用当前批次的梯度微调最终的更新方向,该方法可以在一定程度上增加稳定性,提高网络的学习效率。
最后,实验表明:在较小的网络训练集的基础上,算法获得了99.31%的人脸识别精度,从而验证了算法在提高网络对特征的识别能力上的优越性。
参考文献:
[1] Parkhi O M, Vedaldi A, Zisserman A, et al. Deep face recognition[C]∥British Machine Vision Conference. Swansea, UK: British Machine Vision Association, 2015: 41-42.
[2] Mufti H N, Abidi S, Abidi S R, et al. Predictors of post-operative delirium in cardiac surgery patients; a machine learning approach[J]. Canadian Journal of Cardiology, 2014, 30(10): 237-238.
[3] LeCun L, Bottou Y, Bengio P, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2323.
[4] Ballester P, Araujo R M. On the performance of GoogLeNet and alexNet applied to sketches[C]∥Thirtieth AAAI Conference on Artificial Intelligence. Phoenix, USA: AAAI Press, 2016: 1124-1128.
[5] Day M J, Horzinek M C, Schultz R D, et al. Guidelines for the vaccination of dogs and cats[J]. Journal of Small Animal Practice, 2007, 48(9): 528.
[6] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[G]∥Computer Vision and Pattern Recognition, Las Vegas, USA: IEEE, 2015: 770-778.
[7] Sinno J, Yang Q. A survey on transfer learning[J]. IEEE Transactions on Knowledge & Data Engineering, 2010, 22(10):1345-1359.
[8] Hadsell R, Chopra S, Lecun Y, et al. Dimensionality reduction by learning an invariant mapping[C]∥Computer Vision and Pattern Recognition, Conference on 2006 IEEE Computer Society. New York: IEEE, 2006: 1735-1742.
[9] Chopra S, Hadsell R, Lecun Y, et al. Learning a similarity metric discriminatively, with application to face verification[C]∥Computer Vision and Pattern Recognition, 2005. New York: IEEE, 2005: 539-546.
[10] Taigman Y, Yang M. Deepface: closing the gap to human-level performance in face verification[C]∥Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014: 1701-1708.
[11] Sun Y, Wang X, Tang X. Deep learning face representation from predicting 10,000 classes[C]∥IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE Computer Society, 2014: 1891-1898.
[12] Sun Y, Wang X, Tang X, et al. Deep learning face representation by joint identification-verification[C]∥NIPS Montred, CANADA: MIT Press, 2014, 27: 1988-1996.
[13] Cheng D, Gong Y, Zhou S, et al. Person reidentification by multi-channel parts-based CNN with improved triplet loss function[C]∥Computer Vision and Pattern Recognition. Las Vega S, USA: IEEE, 2016: 1335-1344.
[14] King G, Zeng L. Logistic regression in rare events data[J]. Political Analysis, 2001, 9(2): 137-163.
[15] Wen Y, Zhang K, Li Z, et al. A discriminative feature learning approach for deep face recognition[C]∥Computer Vision-ECCV 2016. Amsterdam: Springer International Publishing, 2016: 11-26.
[16] Qian N. On the momentum term in gradient descent learning algorithms[J]. Neural Networks the Official Journal of the International Neural Network Society, 1999, 12(1): 145-151.
[17] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. Computer Science, 2014, 6(1): 1409-1556.
[18] Szegedy C, Ioffe S, Vanhoucke V, et al. Inception-v4, Inception-ResNet and the impact of residual connections on learning[C]∥AAAI. Palo Alto, California: AAAI, 2017: 4278-4284.
[19] Kazemi V, Sullivan J. One millisecond face alignment with an ensemble of regression trees[C]∥Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014: 1867-1874.
[20] Klawonn F, Hppner F, May S. An alternative to ROC and AUC analysis of classifiers[C]∥International Conference on Advances in Intelligent Data Analysis X. Berlin: Springer, 2011: 210-221.
(編辑 侯 湘)
