基于小生境人工蜂群算法的字符边缘图像提取
2018-11-28高金刚
张 爽, 王 华, 高金刚
(长春工程学院 机电工程学院, 长春 130012)
实际应用中的许多物体都存在数字或字符标记在物体或对象上用来标记信息的情形, 如身份证号、 车牌号及银行卡号等. 近年来, 二维码及各种电子标签的方式应用广泛, 但均为一种易于计算机软件识别的方式获取实体世界中的信息[1]. 而赋予机器设备能像人眼一样读懂字符和数字, 而不是以二维码或条形码方式获取信息, 是人工智能发展的一个重要方向[2-3].
目前, 字符识别系统应用广泛, 如车牌字符自动识别[4]等. 实践表明, 目前已有的这些算法具有良好的识别效果[5], 但其应用范围受环境影响, 如车辆行驶速度、 字符大小及格式、 光照条件等[6]. 随着科学技术的发展, 各行业的管理发展趋势都是逐步从人工管理转变为自动化管理[7]. 对于机械制造业中生产的零部件, 通常都要求在零部件上标记字符, 以表示零件名、 零件编号、 生产日期和批次号等. 列车转向架轮对端面刻有数字和英文字母的字符, 以表述生产日期和时间、 零件编号、 操作员编号等重要生产过程追溯信息. 生产过程追溯信息是产品质量控制分析和内外部物流跟踪、 转向架生产组织管理及售后质量问题分析的重要参考信息. 列车转向架轮对轴端刻印的字符如图1所示. 本文以列车转向架的关键部件轮对轴端刻印字符为研究对象, 提出一种在生产车间复杂的背景下, 适应实际环境的字符识别方法, 自动识别这些零部件上的字符, 用以指导生产、 车间物流及生产信息记录等.
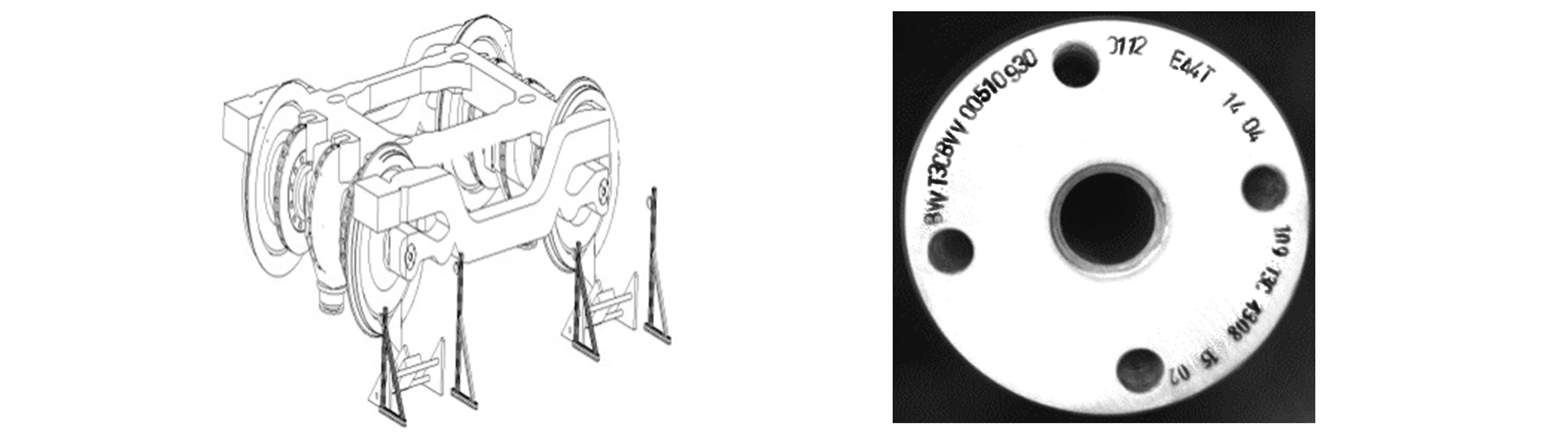
图1 列车转向架轮对轴端字符Fig.1 Characters on train wheel set bogie
1 人工蜂群算法
人工蜂群算法[8]源于蜜蜂寻找蜜源及采蜜的行为方式, 包括蜂群的分工、 信息传递等群体行为, 完成对寻优问题的求解[9]. 相比于蚁群算法、 遗传算法和粒子群算法等其他群智能优化算法, 其具有更显著的寻优能力, 广泛应用于各领域[10].
算法基本流程如下: 蜜源为整个搜索域内相对有价值的解, 选取合理的函数使蜜源的价值与求解问题的函数建立联系, 即收益度函数值能衡量蜜源价值. 初始时, 蜂群分为采蜜蜂和跟随蜂两类. 设蜜蜂总数为Ns, 跟随蜂数量为Nu, 采蜜蜂数量为Ne, 对于蜂群分组通常将采蜜蜂的数量设为蜂群总数的一半, 另一半蜂群被设为跟随蜂. 对于每个蜜蜂, 其搜索区域即为待优化问题解的变量空间, 变量空间的维数设为D. 蜂群设为x={x1,x2,…,xNe},xi为任意一只采蜜蜂, 则
(1)
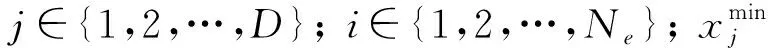
(2)
其中第xi个收益度函数值用f(xi)表示. 每次迭代后, 采蜜蜂招募跟随蜂对已搜索到位置的邻域进行搜索, 然后比较搜索到的新位置vi与原位置xi的收益度函数值大小, 并选择其中收益度大的位置作为该蜜蜂下一次邻域搜索的位置. 邻域搜索位置公式为
vi,j=xi,j+fi,j(xi,j-xk,j),
(3)
其中:j∈{1,2,…,D},k∈{1,2,…,Ne},k,j为搜索范围内随机自然数, 且k≠j;fi,j为[-1,1]内的随机系数, 其作用是保持邻域搜索时的随机性. 将蜂群按收益度大小排序, 跟随蜂优先选择收益度高的采蜜蜂, 跟随其在邻域内搜索. 若在邻域新位置找到的蜜源收益度更高, 则令新位置替代采蜜蜂的原位置.
若采蜜蜂的邻域搜索次数超过设定的规则, 但仍未找到收益度更高的蜜源, 则其身份转变为侦查蜂, 并继续在全局内随机产生新位置作为下一轮迭代的搜索位置. 当满足预先设定的停止条件时, 如总迭代次数或未满足收益值提高的阈值等, 则算法停止并输出结果; 若未满足算法停止条件, 则蜂群将进行下一轮迭代过程. 人工蜂群算法流程如图2所示.
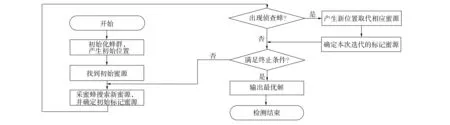
图2 人工蜂群算法流程Fig.2 Flowchart of artificial bee colony algorithm
人工蜂群算法通过模拟蜂群信息沟通, 控制蜂群在相对收益大的位置进行邻域搜索, 放弃适应度值低的位置, 并对在全局内随机产生的新位置进行搜索, 即可实现在每次迭代中逐步优化搜索值的目的, 并最终搜索到问题的最优解. 对采蜜蜂、 跟随蜂和侦查蜂进行不同分工及将其身份互相转化, 实现算法在全局搜索的优异性能及邻域求解的更高精度.
2 小生境技术及小生境人工蜂群算法
小生境是指在生物学的特定环境中由一种生物群体组成的群体组织. 在自然界中, 常见一些习性或特征等相似的物种聚集并生活在一起组成群体, 并逐渐形成一种物种及其特定的生存空间. 小生境技术通常被应用于处理多模函数优化问题中. 多模优化问题是搜索问题的全局最优解及局部最优解[11]. 小生境技术能控制群体优化方向, 并形成多个物种, 即使算法最终收敛到多个不同的解空间, 从而避免了算法过早收敛于局部最优空间, 可增强算法的局部搜索性能.
人工蜂群算法可用于寻找全局最优解, 具有收敛速度快、 求解精度高、 参数设置少等特点. 为优化人工蜂群算法局部最优解的搜索能力, 在算法中引进小生境技术, 在各局部搜索空间形成所需物种, 从而在兼顾全局最优解能力的基础上, 增强算法局部搜索能力. 小生境识别、 跟随蜂选择策略是将小生境技术应用到人工蜂群算法中的关键. 本文选择限制竞争策略作为小生境保持策略, 即设定每个子种群各自的独立搜索空间, 从而限制子种群之间在搜索域内的竞争, 避免了算法在局部搜索域内过早收敛于某个特定的位置.
在人工蜂群算法中, 蜜源效益度高的采蜜蜂群体具有引导跟随蜂的职能, 控制这些采蜜蜂的搜索方向, 可实现在迭代运算过程中引导整个蜂群的搜索范围. 采用设定小生境半径的方法限定每个子种群的搜索范围, 对于进入其他小生境搜索范围的采蜜蜂, 赋予其新的位置, 通过限制与引导的策略控制多次迭代中算法能按预定的方式搜索.
小生境人工蜂群算法步骤如下:
1) 设置基本参数, 包括限制次数limit、 最大迭代次数maxCycle、 子种群的数目N、 子种群规模Bee total、 小生境半径R-niche等;
2) 在规定的搜索范围内, 随机产生子种群的搜索位置, 结束搜索后计算每个子种群内蜜蜂的适应度函数值, 将数值按大小排序, 并存储相对优异的位置及函数值;
3) 子种群内的采蜜蜂按设定的方法搜索新蜜源, 并与上次迭代中存储的蜜源收益比较, 当新蜜源效益度值高于存储的蜜源效益度时, 令新蜜源替换之前的蜜源, 即存储本次新搜索到的蜜源效益度值及位置;
4) 根据蜜源效益度值的大小排序, 效益度高的采蜜蜂获得大概率招募跟随蜂, 并引领跟随蜂在上次迭代位置的邻域附近搜索新的潜在蜜源位置;
5) 若在邻域内搜索效益度更高的蜜源次数达到设定阈值, 但仍未找到更优的蜜源位置, 则将这只采蜜蜂身份转化为侦查蜂, 并在下次迭代中执行随机全局搜索;
6) 计算每个子种群内每个蜜蜂的效益度值, 排序并保存更新后的各子种群内最优解的效益度值及位置;
7) 判断蜜蜂是否进入其他子种群搜索范围内, 如果存在则重新设定该蜜蜂的搜索位置;
8) 检查算法是否已达到设定的迭代次数上限值, 如果达到则算法结束, 输出结果; 如果次数未达到, 则算法返回步骤3).
3 字符边缘提取
考虑字符图像的边缘特性, 并合理设置小生境人工蜂群算法参数, 包括子种群数量、 算法结束条件、 小生境半径、 群体规模、 解的保存方式和效益度函数. 算法结束条件的设置常用限定循环次数或效益度函数值大于设定的阈值. 小生境半径合理的设定可合理分配蜂群的搜索能力, 以获得包含多个局部最优解的结果. 在蜂群上次搜索的最优解对应的八邻域内继续搜索与效益度函数值最接近中心的点, 将搜索到的新位置替代原位置, 并作为下一次搜索的中心位置. 算法循环执行直至算法满足结束条件并停止. 提取出每次循环搜索到的位置, 即得到了对应图像的边缘图像.
蜂群的数量是决定算法搜索能力的重要参数. 若蜂群数量设定过多, 则会导致运算能力的浪费, 且结果中会包含劣势解. 若蜂群数量设定过少, 则会导致搜索能力不足[12]. 合理的蜂群数量应该是根据图像边缘信息及图像的尺寸确定. 本文采用将图像中所有像素点之和的平方根作为蜂群数量, 计算公式为
(4)
其中:N表示图像的像素行数;M表示图像的像素列数;Ns表示蜂群的总数量. 跟随蜂Ne的数量为
Ne=Ns/2.
(5)
子种群数量N由图像内容及布局设定, 对于字符图像, 可设定为字符的数量, 即每个子种群对应一个字符, 即可保证子种群的搜索能力覆盖到每个字符. 对于本文中待识别的字符, 每个字符像素点相对接近, 对于子种群规模Bee total设定时, 将蜂群总体平均分配到每个子种群中以简化算法. 为避免种群搜索空间交叉的现象, 小生境半径可设为字符中心之间的距离.
选择与图像边缘点强相关的函数作为小生境人工蜂群算法的效益度函数表达式[13-14]. 本文算法的效益度函数采用像素点八邻域的灰度突变值函数, 效益度函数为
f(Ii,j)=|Ii-1,j-1-Ii+1,j+1|+|Ii-1,j-Ii+1,j|+|Ii-1,j+1-Ii+1,j-1|+|Ii,j-1-Ii,j+1|,
(6)
其中: (i,j)表示图像中任意一个像素点的位置;Ii,j表示位置(i,j)的灰度值.f(Ii,j)的八邻域如图3所示.
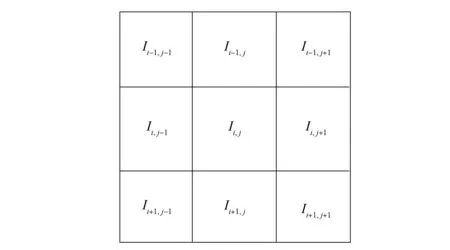
图3 八邻域示意图Fig.3 Schematic diagram of 8 neighbor area
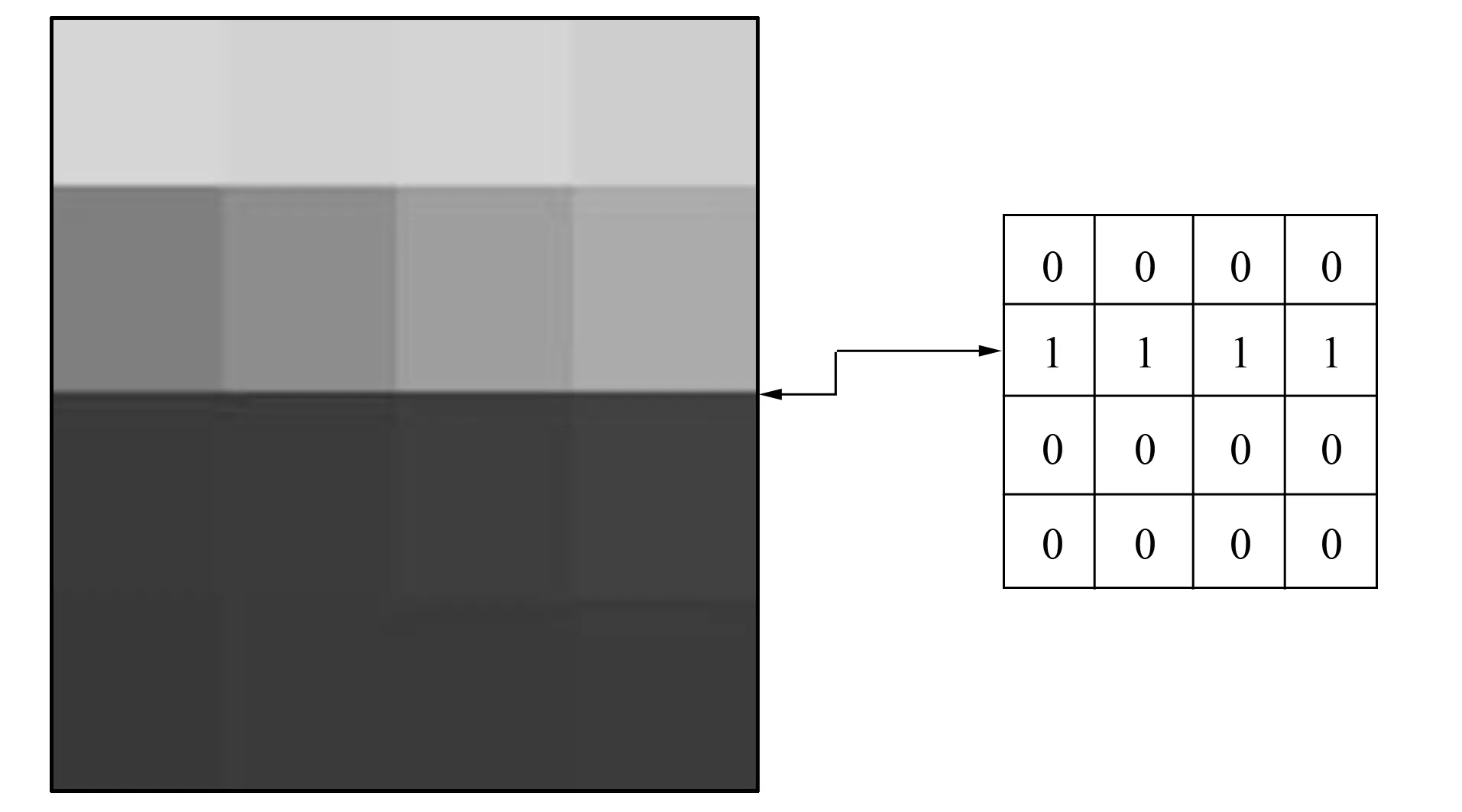
图4 图像边缘及灰度值Fig.4 Edge image and gray value
若某像素点八邻域灰度梯度值大于或等于设定的判定阈值, 则设定该像素点为边缘点, 并将该点的灰度值标记为1, 如图4所示. 图像灰度梯度值的阈值为
T=fix(std2(image))×1.5.
(7)
4 实验结果分析
以如图5所示的实际生产线上零部件采集到的单个字符为例说明本文算法的有效性. 图5中图像大小为193×103, 则蜂群数量

图5 初始图像Fig.5 Initial image
待搜索的字母为4个, 子种群规模
Beetotal=140÷4=35;
阈值
T=fix(std2(image))×1.5=93;
总迭代次数iter为10次, 邻域搜索次数设定为5次. 由图5可见, 图像宽度为193个像素, 其中每个字母在整个图像中宽度的分布列于表1. 在小生境算法中, 设定规则保证每个子种群的搜索范围固定在对应字母的整体图像宽度分布内, 从而保证每个字母得到均衡的搜索能力.

表1 字母宽度分布Table 1 Distribution of alphabet width
图6为未应用小生境半径算法得到的字符边缘图像, 图7为应用小生境算法得到的字符边缘图像. 对比图6与图7可见, 图6的边缘点明显分布不均, 以致于第一个字母V下部明显缺失.

图6 未应用小生境算法的边缘图像Fig.6 Edge image without niche algorithm

图7 应用小生境算法的边缘图像Fig.7 Edge image obtained by niche algorithm
分别统计图6和图7中每个字母的边缘点数量, 结果列于表2. 由表2可见, 应用小生境算法得到的对应每个字母的边缘点数量一致, 均为249个, 而未应用小生境算法得到的图像边缘点在4个字母上分布不均匀, 字母B上的数量为393个, 是字母T边缘点150个的2.62倍, 而应用了小生境算法得到的字母T的边缘点数量为249个, 是未应用小生境算法得到字母T边缘点的1.66倍. 实例测试结果表明, 应用小生境技术的人工蜂群算法采集到的边缘图像边缘点分布均匀, 更利于下一步的字符识别.

表2 边缘点数量对比Table 2 Quantity comparison of edge points
综上所述, 本文将小生境人工蜂群优化算法与图像边缘检测原理相结合, 提出了一种针对字符图像的边缘检测新方法. 利用小生境技术合理布置搜索能力, 通过控制子种群规模和搜索位置, 提高了局部搜索精度, 加强了算法的总体搜索能力. 对图像进行小生境人工蜂群算法的字符边缘检测, 可按需求控制搜索的位置和能力, 极大地方便了后续处理过程. 实验结果表明, 该方法不仅能快速地识别出字符, 且对较模糊或亮度不均匀的图像也能准确识别, 适用于生产车间的复杂环境, 可满足图像检测的实时性需求.
