乌兰布和灌域有效灌溉面积预测模型研究与应用
2018-11-28李瑞平王艳明王思楠范雷雷樊爱霞
田 鑫,李瑞平,王艳明,王思楠,范雷雷,樊爱霞
(1.内蒙古农业大学水利与土木建筑工程学院,呼和浩特 010018;2.内蒙古河套灌区乌兰布和灌域管理局,内蒙古 巴彦淖尔 015200;3.内蒙古水利水电勘测设计院,呼和浩特 010020)
近年来,乌兰布和灌域有效灌溉面积增速呈现减缓趋势,水利设施损坏、土地利用不合理、渠道渗漏等问题都在制约着乌兰布和灌域有效灌溉面积的健康发展,而有效灌溉面积作为区域抗旱能力的体现,同时也是水利决策部门制定水利建设发展规划的重要指标,对有效灌溉面积进行预测将为水利决策部门制定水利建设发展规划提供参考依据,同时对有效灌溉面积的保护与健康发展都能起到积极作用。在有效灌溉面积预测方面,目前主要的方法有:回归分析法,灰色预测法,人工神经网络,支持向量机等[1-3]。2011年万玉文等利用GM(1, 1)模型对我国大中型灌域的有效灌溉面积进行了预测,虽然取得了较好的预测结果,但其预测精度并未达到一级[4],2011年何自立等通过新陈代谢GM(1,1)-Markov链模型对全国有效灌溉面积进行了预测,克服了GM(1, 1)模型在中长期预测中结果不稳定的问题,预测精度达到一级[5,6],吴丽丽、刘延明分别于2009、2011年对基于RBF的神经网络在有效灌溉面积预测方面的应用进行了讨论,结果显示基于RBF的神经网络在有效灌溉面积预测方面具有较强的适应性、精确性和较强的概括能力[7,8]。2009年张豪等通过遗传算法最小二乘支持向量机对江苏省无锡市的耕地面积进行了预测,结果表明遗传算法最小二乘支持向量机对于耕地面积的预测相较多元回归、GM(1, 1)模型、BP神经网络、支持向量机等模型具有更高的预测精度和更快的计算速度,但其需要构建耕地变化与耕地变化影响因子之间的关系模型,建模难度较高[9]。2013年李建伟等采用BP神经网络和支持向量机回归预测两种方法建立了有效灌溉面积的预测模型,结果表明支持向量机回归预测的方法具有更高的预测精度和更强的泛化能力[10]。且建模难度较低,无须构建预测值与影响因素之间的关系模型。鉴于以上原因,结合研究区实际情况与乌兰布和有效灌溉面积变化特点,研究采用支持向量机回归滑动预测模型与Logistic灰色预测模型对乌兰布和灌域各年份有效灌溉面积进行了预测,并对预测结果进行对比分析。
1 材料与方法
1.1 研究区概况
乌兰布和灌域位于巴彦淖尔市的西南部,东经106°09′~107°10′,北纬40°08′~40°57′,是内蒙古河套灌区的一个重要组成部分。灌域东南至黄河与鄂尔多斯市隔河相望,西南与阿拉善盟毗邻,东北部与解放闸灌域接壤,西北靠阴山山脉,东西长92 km,南北宽65 km,现有灌溉面积5.89 万hm2,其中一干渠灌域3.55 万hm2,东风分干渠灌域1.64 万hm2,大滩分干渠灌域0.7 万hm2,承担着中国林业科学研究院沙林中心,巴彦淖尔市6个国有农场,磴口县5个苏木、镇、办事处,杭锦后旗1个镇,阿拉善盟1个国有农场及鄂尔多斯市杭锦旗巴拉亥镇部分耕地的灌排任务。灌域内土壤类型以壤砂土和沙壤土居多,并含有少部分的砂土,同时灌域具有明显的大陆性气候特点,冬季严寒,夏季短促。气候干旱少雨,蒸发强烈,年平均降雨量在130~215 mm之间。而年平均蒸发量在2 100~2 400 mm之间。因其降水量与蒸发量严重失衡,造就了其农牧业生产和生态环境对引黄灌溉的绝对依赖。
1.2 预测方案的选择
有效灌溉面积的预测方案主要分为两大类:第一类为数据序列预测法,即将有效灌溉面积数值看作连续的时间序列,可以认为有效灌溉面积的变化规律已经蕴含在数据序列中,再采用合适的方法对该序列在未来的取值进行预测;第二类为结构式的预测方法,即通过一定方式建立起各主要影响因素与有效灌溉面积之间的联系,然后根据未来各影响因素的变化去预测相对应的有效灌溉面积。
在第二类方案中,准确的确定影响有效灌溉面积变化的各种因素本身就很有难度,各因素对有效灌溉面积影响规律的辨识同样也是一个较为复杂的问题。在第一类方案中,首先需要建立起能够充分反映有效灌溉面积变化规律的预测模型,然后通过求取该预测模型在未来的输出值即可实现预测。两种方案对比,显然第一类方案更容易实现,因此,在以下研究中采用数据序列预测方案。在目前广泛采用的有效灌溉面积数据序列预测方法中,支持向量机与神经网络从本质上来说更为适合应用于有效灌溉面积这种典型的非线性序列预测问题,但神经网络容易陷入局部收敛问题,显然在该研究中采用支持向量机方法较为合适,同时为了验证支持向量机的优越性与有效性,根据研究区实际情况与乌兰布和灌域有效灌溉面积变化特点,采用logistic灰色预测模型与支持向量机进行对比分析。
1.3 Logistic灰色预测模型理论基础
P E Verhulst于1838年首先提出Logistic模型,目前Logistic模型已经广泛应用于经济、医学、人口学等众多领域[11,12],Logistic模型可以表示如下。
(1)
(2)

1982年,邓聚龙教授创建了灰色系统理论,其是对贫信息、少数据且不确定性问题进行研究的一种方法。在灰色系统理论中应用最广泛的是灰色GM(1,1)模型[13]。它的数学式如下式。
(3)
式中:λ为发展系数;μ为灰作用量。
x=B(1+ae-bt)
(4)
方程式(4)两边同时对 求导并化简得:
(5)
若令λ=b,μ=Bb,则Logistic模型可以改写成与GM(1,1)模型相同的形式:
(6)
为能够使得对参数(λ,μ)的估计达到最优,需要实际、理论指标之间的差方平方和为最小。以该理论为基础的建模技术,参数(λ,μ)须满足下列关系式:
(7)
(8)
(9)
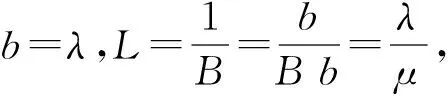
1.4 支持向量机回归模型理论基础
对于支持向量机回归问题,给定训练样本集(xi,yi),x∈Rd,yi∈R,i=1,2,…,N,支持向量机引入一个损失函数,通过使经验风险和置信风险之和最小化,从而满足结构风险最小化原则,使模型具有较好的泛化能力[16,17]。
为了保证计算得到的支持向量具有稀疏性,在支持向量机回归中引入ε-不敏感损失函数,定义为:
(10)
式中:ε为不敏感因子;f(x,ω)为回归估计函数;y为与x对应的目标值。
对于非线性支持向量回归问题,支持向量回归采用下列估计函数拟合样本集,使非线性回归问题转化为高维空间的函数估计问题[18,19]。
f(x)=ωTφ(x)+bφ(ξ):x→F,ω∈F
(11)
式中:ω为权值向量;φ(ξ)为非线性映射将数据X映射到高维特征空间F。
根据统计学理论,ε-SVM回归问题可表述为最优化问题。
(12)
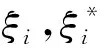
为了求解最优化问题,通常引入拉格朗日函数,同时由最优化理论的KKT优化条件,根据Wolf对偶定理,最终可以得到其对偶化问题[20,21]。
(13)
式中:k(xi,xj)=φ(xi)Tφ(xj)是核函数,最终得到支持向量回归估计函数式(14)。
(14)
在本次研究中,支持向量机采用滑动预测的方式,即每次的输入样本包含4个数据,以连续4 a的数据预测第5年的数据,据此可建立训练时的输入样本矩阵(4×6)和输出样本向量(6×1)。在对未来进行预测时,需结合新陈代谢法对有效灌溉面积进行预测,所谓新陈代谢法,就是将本次预测所获得的数值作为预测模型输入向量中最右端的数据,而舍弃上次输入向量中最左端的数据,从而获得新的输入向量,当获得了新的预测值后再重复以上过程,直至获得所有的预测值为止[22,23]。
2 预测模型的建立与精度对比
2.1 样本数据的预处理
根据水利部门统计资料,收集了2007-2017年乌兰布和灌域有效灌溉面积统计数据。
(1)由于Logistic灰色预测模型的变量x=1/NP,根据有效灌溉面积NP可以利用Excel计算出x。从而可以利用x与时间t的原始数据对logistic模型参数直接进行灰色估计,具体结果如表1所示。

表1 Logistic灰色预测模型数据预处理Tab.1 Data preprocessing of Logistic grey prediction model
(2)对于支持向量机回归预测模型来说,为了降低建模难度,需要对数据进行归一化处理,本文采用峰值法对2007-2017年有效灌溉面积数据进行了归一化处理,以归一化处理后的2007-2016年数据作为训练样本,以2017年数据作为检验样本。
2.2 模型参数的确定
(1)Logistic灰色预测模型模型根据Matlab计算结果如下:

从而b=λ=0.337 9,NR=λ/μ=5.221。

(15)
(2)影响支持向量机学习能力的主要参数为惩罚因子C和核参数g。C值越大,则允许误差越小,对数据的拟合程度越高;核参数g与学习样本的输越大,取值越大,因此,对惩罚因子C和核参数g的选取是提高支持向量机预测精度的关键。如图1所示,针对支持向量机回归预测模型参数的确定与训练,在多次实验的基础上,结合网络搜索法,确定惩罚因子C为147.033 4,核参数g为0.003 906 3,在此参数基础上建立的支持向量机回归预测模型预测结果较好,拟合程度较高。

图1 支持向量机参数选取结果图(3D视图)Fig.1 Support vector machine parameter selection result graph (3D view)
2.3 模型精度对比
利用Logistic灰色预测模型和支持向量机回归预测模型仿真预测2011-2016年的乌兰布和灌域有效灌溉面积,预测值、预测相对误差、预测误差的绝对值和均方根误差见表2。从表2可以看出支持向量机各预测值与实际值更为接近,其均方根误差仅为Logistic灰色预测模型的16.7%,在预测误差的绝对值均值方面,支持向量机回归滑动预测模型相比Logistic灰色预测模型少了0.023 3 万hm2,预测相对误差方面,支持向量机回归滑动预测模型为Logistic灰色预测模型的9.5%,通过精度对比可以看出,支持向量机回归滑动预测模型的预测精度远高于Logistic灰色预测模型,模型的优越性得到了体现。
利用两种模型分别对作为检验样本的2017年乌兰布和灌域有效灌溉面积进行预测,预测结果如表3所示,从表3可以看出支持向量机回归预测模型在检验样本处的预测精度同样远高于Logistic灰色预测模型。

表2 2011-2016年两种模型仿真预测结果及误差对比Tabl.2 The results of simulation and error comparison between the two models in 2011-2016

表3 2017年两种模型预测结果及误差对比Tab.3 Prediction results and error comparison of two models in 2017
3 模型应用与分析
利用结合新陈代谢法的支持向量机回归预测模型与Logistic灰色预测模型对2018-2025年乌兰布和灌域各年份的有效灌溉面积进行了预测,预测结果见表4,从表4可以看出,随着预测年份的增加,Logistic灰色预测模型的预测结果在一定程度上偏离了已知数据的变化规律,且与支持向量机回归预测模型之间的差距越来越大。

表4 两种模型预测结果对比 万hm2Tab.4 Comparison of prediction results between two models
综合两种模型的预测结果,显然基于支持向量机回归预测模型的预测结果更为合理,因此将支持向量机回归预测模型的预测结果作为乌兰布和灌域有效灌溉面积的预测值。根据预测结果显示,乌兰布和灌域有效灌溉面积增速将于2018年开始减缓甚至出现负增长,有效灌溉面积于2022年达到峰值后,将持续呈现负增长的状态,由此可以看出乌兰布和灌域有效灌溉面积发展前景不容乐观,造成这种现象的原因可以概括为两个方面:一是对有效灌溉面积发展起到积极作用的有利因素减少,导致有效灌溉面积每年的新增量减少,二是对有效灌溉面积发展起到消极作用的不利因素增多,导致有效灌溉面积减少量逐年增加[24]。因此,需要采取一定措施,根据支持向量机的预测结果,在促进有利因素的发展的同时,抑制消极不利因素。
4 结 语
根据支持向量机回归预测模型与Logistic灰色预测模型精度对比结果显示,支持向量机回归预测模型对乌兰布和灌域有效灌溉面积的预测精度更高、预测结果更贴合已有数据的变化规律,相比Logistic灰色预测模型,支持向量机展现了更强大的泛化能力与更好的有效性。结合支持向量机回归预测模型的预测结果,最终发现,研究区的有效灌溉面积将要达到上限,增长空间较小。结合研究区实际情况,可以从以下几点进行调整:
(1)在符合自然规律与经济规律的基础上,调整灌区的农业结构,扬长避短,趋利避害,促进土壤生态系统的良性循环和水资源的合理利用。
(2)乌兰布和灌域水资源匮乏,虽然已增加相应供水设施,且提高了水资源利用效率,但对比发达国家而言,灌溉水利利用系数之间的差距依然较为明显。寻找适合的畦田规格,改变灌区灌溉方式以提高灌溉水利用系数仍是急需解决的问题。
(3)乌兰布和地区的水利工程大多建于20世纪六七十年代,工程老化严重,特别是支、斗、农渠闸门的漏水和各级渠道的渗漏损失严重,对渠道进行衬砌防渗,及时修理损坏的水利工程等都是对有效灌溉面积发展有利的因素。
