小语料库重庆话语音识别的研究
2018-11-28,,
, ,
(重庆第二师范学院 数学与信息工程学院,重庆 400065)
0 引言
语音识别技术[1]是人机交互领域的重要研究内容,解决了人机交互过程中计算机不能够听懂人说话的问题。语音识别技术起步于上世纪五十年代,发展至今已经取得了长足的进步。国内外很多科技公司都在语音识别领域进行了深入的研究。如谷歌、微软以及科大讯飞等公司已经走在了语音识别领域最前沿。目前研究语音识别主要的研究对象是主流的语言,而关于方言的研究就相对少些。
重庆话是重庆地区方言文化,承载着重庆本地的传统文化,人口覆盖超过3 000万。近些年来,重庆的电子信息产业已经成为重庆经济的重要增长极,在2012年重庆市提出的“两江有云,西永有端,南岸有网”的电子信息产业发展总战略布局背景下,人工智能产品将在重庆各个领域广泛应用。语音识别是人工智能领域的重要组成部分,实现了计算机能“听懂”人的语音。重庆话语音识别的研究将有助于实现重庆地区的人们能够自然地利用重庆话与人工智能产品进行交流,实现“人机对话”,从而让人们享受到科技发展给生活带来的便利和高效。
1 重庆话的发音特点
重庆方言虽然也属于汉语,但是和汉语普通话存在一些差异。在声母方面的差异,汉语普通话有21个声母[2],而重庆话中没有翘舌声母/zh/、/ch/、/sh/以及鼻音声母/n/;重庆话只有17个声母[3-6],重庆话不能区分/n/和/l/,也就是说没有鼻音声母/n/,并且通常把声母/h/读成/f/。在韵母方面的差异,汉语普通话共有39个韵母[2],而重庆话只有37个韵母[3-6],没有/ing/和/eng/这两个后鼻音韵母,多一个/vu/,少一个/ui/。汉语普通话、重庆话的声母和韵母分别如表1、表2、表3和表4。

表1 汉语普通话声母表

表2 汉语普通话韵母表
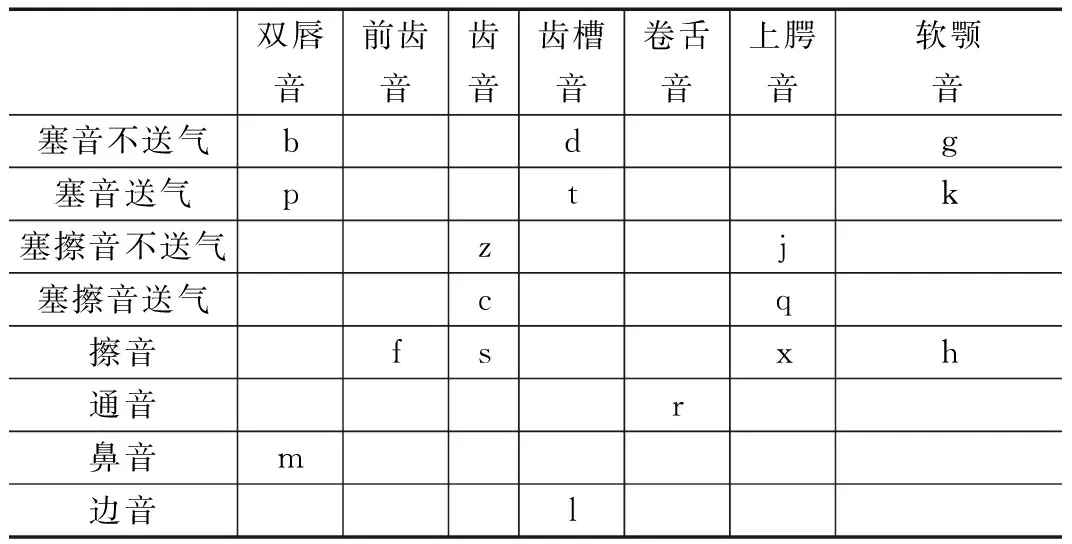
表3 重庆话声母表

表4 重庆话韵母表
2 重庆话识别方法
简单来讲,重庆话语音识别是利用声学模型匹配方法将输入是语音识别系统的待识别语音与经过训练的声学模型进行模式匹配,并按照一定的判别规则得到待识别语音对应的文本信息。
2.1 训练方法
语音识别过程中需要对语料库中的语音基元建立声学模型,并对语音基元的声学模型的参数进行训练[7],得到含有语音特征信息的声学模型。对建立的声学模型的状态转移概率进行重估训练,重估训练的方法如公式(1)所示。
(1)

(2)
从HMM模型的非发射入口状态进入HMM模型的由公式(3)嵌入式重估完成。
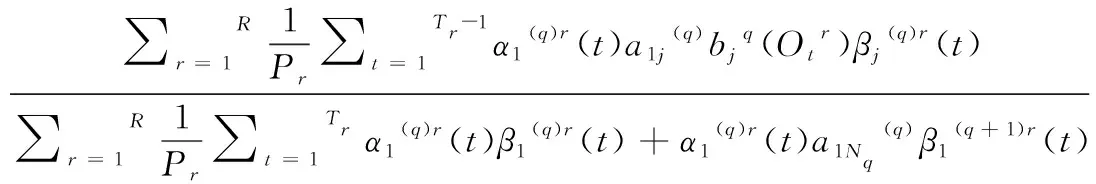
(3)
然后,从HMM模型进入HMM模型的非发射入口状态由公式(4)嵌入式重估完成。
(4)
最后,从HMM模型的非发射入口状态进入HMM模型的非发射入口状态由公式(5)嵌入式重估完成。
(5)
在公式(2)、公式(3)、公式(4)以及公式(5)中的下标q表示嵌入式重估的次数,如果q没有明显的标注出来,嵌入式重估的输出概率分布公式和单个模型的输出分布是一样。然而,概率计算公式必须将公式(6)变成公式(7)才能实现从入口状态的转移。
(6)
(7)
语音识别中训练声学模型的方法较多,以上7个公式仅仅是语音识别中对声学模型进行重估训练所涉及的基本公式。
2.2 识别方法
语音识别过程就是待识别语音的声学模型和声学模型库中的模型进行匹配,得到匹配度最高的声学模型即是识别结果。待识别语音的声学模型和声学模型库中的语音的匹配过程采用维特比算法实现。本文基于HMM模型的维特比算法基本思想是从观测序列O=(o1,o2,o3,...,ot)中求取给定模型λ=(A,B,π)下的最大似然概率。维特比算法用于语音识别解码的公式[7]如下所示。
给定一个模型M,设Φj(t)表示在t时刻观测到语音序列从O1到Ot处于j状态的最大似然,那么Φj(t)如公式(8)所示。
(8)
其中:i和j为不同的状态,aij为状态转移概率,bj(ot)为输出概率密度如公式(9)所示。
(9)
其中:cjsm是第m个分量的权重,Ν(o;μ,Σ)是具有均值向量μ和协方差矩阵Σ的多元高斯模型,ost是在时间t观测向量被分成s个独立的数据流。
3 重庆话识别过程
重庆话语音识别是将重庆话语音识别成文本的过程。重庆话语音识别分为两个过程,即训练过程和识别过程。其中训练过程是利用语料对声学模型进行训练,最终得到声学模型库;识别过程是将待识别的语音进行预处理,然后提取语音的特征参数,最后利用相应的识别方法实现语音识别,并对识别结果进行分析得到识别结果。重庆话语音识别过程如图1所示。
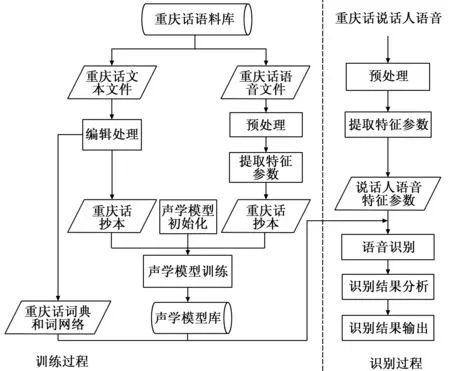
图1 重庆话语音识别过程
3.1 建立重庆话语料库
首先采集本实验需要的语音文件对应的文本,选择重庆话和普通话发音标准的录音人;然后按照实验方案分别录制重庆话语音30句,重庆话口音的普通话语音30句,每句语音发音10遍,共得到(30+30)*10句语音;最后由重庆话语音以及重庆话口音的普通话语音文本和与之对应的语音文件形成语料库。
语料库由训练集和测试集组成,训练集中包含(30+30)*7句语料,测试集中包括(30+30)*3句语料。其中测试集细分为(30+30)*1句、(30+30)*2句以及(30+30)*3句。语料库中语音对应的文本如表5所示。
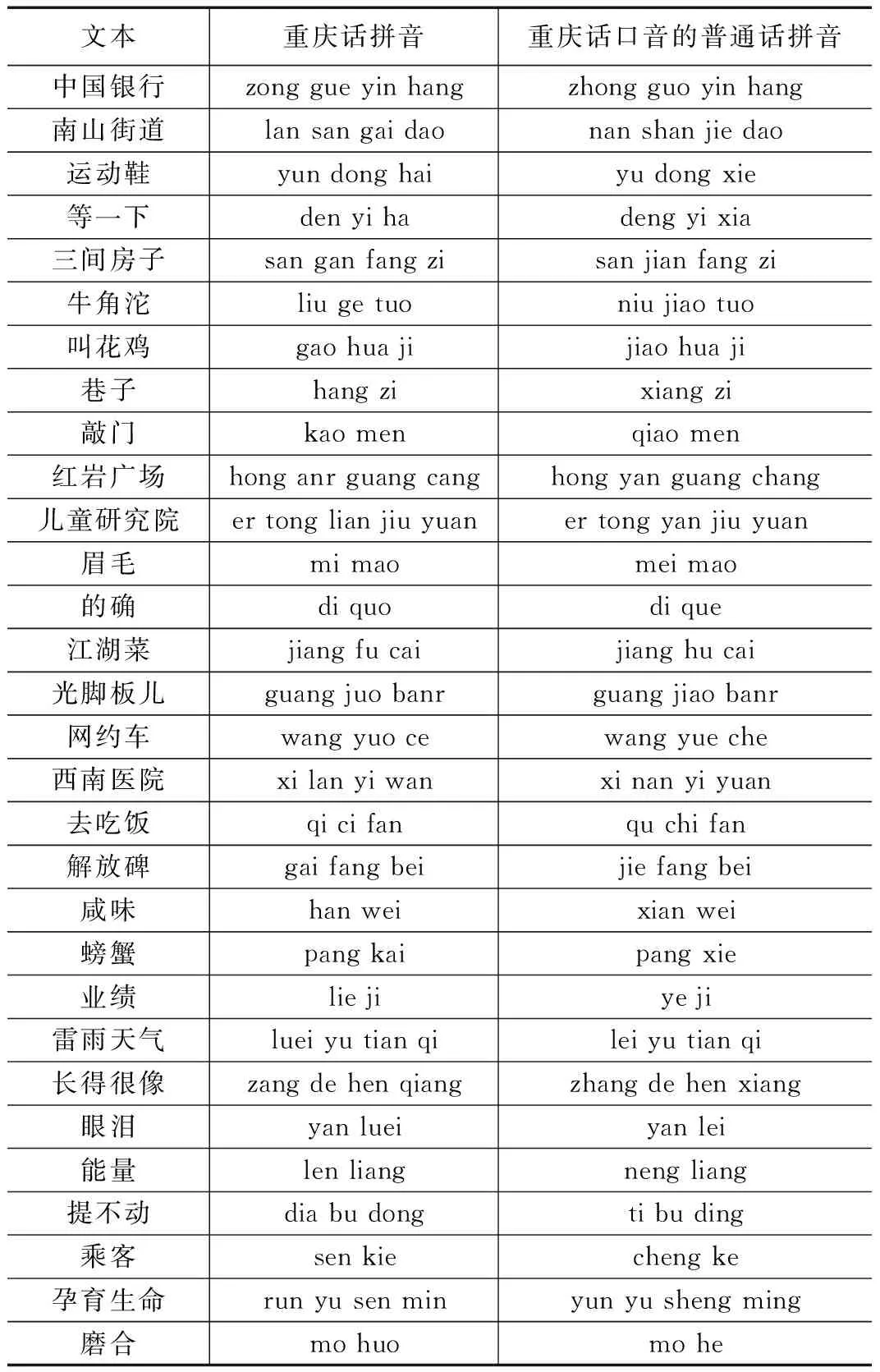
表5 重庆话语料库文本与发音对照表
3.2 语音预处理
语料库中的语音是连续且非平稳的信号,而非平稳的信号不便于处理,因此需要对语音信号进行预处理。预处理包括采样量化、分帧加窗以及预加重等过程。
1)采样量化是将连续语音信号转换成离散数字信号。本实验的语料库采用的采样量化标准是16 kHz采样、16 bit量化。
2)分帧加窗是为了将语音信号进行短时化处理,我们可以认为语音信号长度在10~30ms时为准平稳信号,因此需要对语音信号加窗函数以实现短时化处理。常用的窗函数有矩形窗、哈明窗以及哈宁窗等,根据语音信号的特点,本文选取哈明窗函数,如公式(10)所示。
(10)
3)预加重是为了解决高频低功率谱的问题,即语音信号在高频部分呈现低能量,而低频部分呈现高能量的现象。在对语音信号进行处理分析过程中需要提高语音高频部分的功率谱,因此需要预加重处理。
3.3 提取特征参数
语音信号含有大量的信息,包括基频、时长以及频谱等基本声学参数,也包括语音韵律等信息。为了便于对语音信号的处理,去掉一些不太重要的冗余信息,因此需要对语音信号提取能够表征语音信号的相关参数,即语音信号特征参数。语音特征参数常见的语音特征参数有线性预测系数(linear predictive coefficients, LPC)、线性预测倒谱系数(linear predictive cepstral coefficients, LPCC)、基于Mel频率倒谱系数(mel frequency cepstral coefficients, MFCC)[8-9]。本论文根据声学建模的需要,选择接近人耳对语音信号频率的感知特性的特征参数。以上3种参数中的基于Mel频率倒谱系数(MFCC)作为特征参数。Mel频率与Hz频率之间的映射关系如公式(11)所示。
fMel=(1000/lg2)×lg(1+0.001fHz)
(11)
MFCC特征参数的产生过程如图2所示。

图2 MFCC参数提取过程
本文对语音信号提取的信号是12维的MFCC特征参数,为了反应语音信号的停顿及重音等参数需要加上1维短时平均能量构成13维特征参数,并且为了表示语音的动态特征,需对13维的特征参数求取一阶差分和二阶差分得到39维的特征参数。
3.4 训练声学模型
语音基元是发声的基本单元,本文是以重庆话的声韵母为语音基元,因此要为参与模型训练的声韵母建立声学模型。常用的声学模型较多,其中隐马尔可夫模型(hidden markov model, HMM)[10-12]是应用很广泛的声学模型。HMM模型是由“单链”的马尔可夫演变为“双链”而来,其中一条隐藏的链描述了状态的转移,产生了不可观测的状态序列;另外一条可见的链描述了状态和观测值之间的统计对应关系。观察者只能通过可见的观测值来感知状态的转移关系。五状态的HMM模型如图3[13]所示。

图3 5状态的HMM模型
从图3中可以看出,由于5状态的HMM模型左右两端的状态只起到前后连接作用,这两个状态并没有高斯分布,因此5状态的HMM模型只有中间3个状态有状态转移。
声学模型p(y|x,λ)在HMM模型中方可以变换如公式(12)所示。
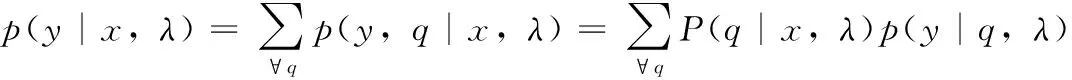
=
(12)
其中:P(·)表示一个概率密度函数,p(yt|qt,λ)是第qt个状态的状态输出概率密度,它是一个典型对角协方差矩阵的单高斯分布,并且q={q1,...,qT}是HMM状态序列。
为每一个语音基元建立了HMM模型之后,需要对HMM模型进行重估训练,训练方法如2.1节。对训练后的HMM模型建立HMM模型库,模型库中包含了(30+30)*7句语料的所有基元对应的声学模型。
3.5 语音识别
语音识别是将待识别的语音识别成对应文本的过程,即在声学模型和语言模型下,对待识别语音的特征参数进行解码,从而将语音识别成对应的文本。
语音识别过程分为4个大组,每1个大组再以测试语句细分为30句、60句以及90句3个小组,共计12组语音识别实验。具体的实验方案设计如下:
1)利用重庆话语音库中训练集的语料训练语音模型,重庆话语音库中测试集的语料为测试语句。
2)利用重庆话口音的普通话语音库中训练集的语料训练语音模型,重庆话口音的普通话语音库中测试集的语料为测试语句。
3)利用重庆话语音库中训练集的语料训练语音模型,重庆话口音的普通话语音库中测试集的语料作为测试语句。
4)利用重庆话口音的普通话语音库中训练集的语料训练语音模型,重庆话语音库中测试集的语料作为测试语句。
4 识别结果
根据以上4个大组,共12个小组的实验方案分别进行识别实验,并将实验结果整理如表6所示。
从表6中可以看出,重庆话和重庆口音的普通话对应识别自己本身的正确识别率为100%,而两种语音交叉进行语音识别则呈现出不同的正确识别率。其中重庆话声学模型去识别重庆话口音的普通话在不同的测试集下呈现出不同的识别结果,当测试集为30句和60句时均为76.67%,而在90句时达到78.89%;重庆话口音的普通话声学模型去识别重庆话在不同的测试集下也呈现出不同的识别结果,随着测试集语句数的增加,正确识别率总体趋势上也随之增加,并在30句时达到90.00%,60句和90句时分别达到91.67%和91.11%。

表6 12组实验结果
5 结语
本文以重庆话为实验研究对象,采集了重庆话文本,并将文本录制成重庆话和重庆话口音的普通话,建立了两种语音与之对应的小语料库。搭建了基于HMM的重庆话语音识别系统,设计了12组语音识别方案,并得到了12个实验结果。实验结果表明:在30句、60句以及90句测试集下重庆话和重庆话口音的普通话训练得到声学模型分别去识别对应的两种语音的正确识别率均为100%;重庆话语音声学模型识别重庆话口音的普通话语音的正确识别率要比重庆话口音的普通话语音声学模型识别重庆话语音的正确识别率要高。
