智慧教育视域下基于OIM关系链的学习分析规则研究*
2018-11-24郁晓华张莹渊
郁晓华 张莹渊
(华东师范大学 教育学部 教育信息技术学系,上海 200062)
一、引言
智慧教育本质是数据驱动下教与学的决策与变革,“智慧”的核心即是对教育数据的充分挖掘与创新应用。而学习分析技术,毫无疑问为智慧教育视域下的教学服务,提供强而有力的证据支持。学习分析是对学习行为的观察和理解,进而追溯行为发生的情境和环境并加以优化,但学习分析又因教育应用问题情境和服务对象的不同,而形成了不同的内容取向和技术方法。
随着学习分析实践的日渐丰富与深入,教学情境的日趋开放性和多样化,越来越多的学习分析研究和实践发现:要有目标地开展学习分析的数据收集;要有方案地执行分析处理;要有策略地实施教育应用,这样才能确保最后的应用成效。而这一行动方向,需采用一定的教育学方法(Pedagogy-based)加以指导。
OIM(Objective/Indicator/Metric,即目标/指示/度量,下同)关系链,最早由Chatti等于2012年提出[1]。它描述了围绕教育应用的目标,如何选择数据指标,然后加以转换并度量处理的一套学习分析实施的设计逻辑。OIM可有效指导学习分析实践的开展,并确保分析结果产生最大化的教育效益。
在此设计思想基础上,本研究试图对当前学习分析中常见的分析目标、数据指标和技术方法加以梳理。然后,基于三者的相关性,从现有实践案例中提炼出特定的学习分析规则,构建不同问题情境下目标、数据和方法之间的一般性实施路径。进而,结合当前跨平台、多元化的开放学习生态环境,尝试提出基于OIM关系链的开放学习分析系统架构。
二、OIM关系链的设计思想
当前,以数据驱动教育决策为特征的智慧教育,激发了学习分析技术的新一轮发展热潮。虽然,自2010年学习分析技术正式形成以来,多元化的学习分析实践产出了大量的分析结果,揭示了一些教育发现,但由于缺乏教育学方法的指导[2],意义逻辑离散零乱,很难有效加以应用与推广。在由美国国家教育部2012年发布的《通过教育数据挖掘和学习分析促进教与学》报告中指出,“在规划教育大数据挖掘和学习分析具体应用的时候,一定要按照“解决问题界定→分析数据选择→技术选择”的技术路线进行,避免不必要的人力和物力的浪费”[3]。
许多研究开始关注在实施学习分析时引入教育学方法的指导,让数据的收集有目标可以引导,分析处理有方案可以遵循,结果应用有策略可以落实,以实现教育效益的最大化。以Lisa和Elias的学习分析持续改进循环模型[4],和Cooper[5]的学习分析特征框架模型为代表,他们提出可嵌入一定的理论指导,以使分析应用的思路清晰有效,同时认为优质的教学实践、领域知识与需求视角,可被引入提供参考。
基于此,本研究尝试引入OIM关系链的设计思想,通过案例提炼,建构基于不同问题情境的目标、数据和方法之间的应用路径,并将抽象的OIM关系链思想,转化为具体的OIM关系链分析规则,以更好指导学习分析的实践应用[6]。
OIM关系链是由学习分析领域专家Chatti等最早提出,原指目标/指标/度量关系链(Objective/Indicator/Metric)[7],意图通过良好的设计逻辑,来指导学习分析实践的有效开展。本研究在参考这一思想的基础上,为更好提升实践性,进行了一些调整和扩展,使OIM关系链转变为目标/数据/方法关系链(Objective/Indicator/Method)。
Objective维持原意,即学习分析的目标,比如评估教学设计、识别高危学生、预测学习表现、提供个性化和自适应等。目标有不同层次,不同利益相关者有不同的问题情境和目标需求。
Indicator的含义有所调整,原指学习分析的测量指标,包括用于衡量学习者学习投入度的登录频次和在线时长,衡量学习者学习成效的作答正确率、完成任务数量等等。由于大部分的测量指标,都是由原始数据经过一定的算法加工处理后获得,最后也体现为一组数据。并且,对数据的选择和理解具有一定的情境性,同样的数据信息可度量不同的问题情境,即作用于不同的分析目标。因此,本研究在此不严格区分数据和指标概念的不同。
Method为增加的维度,指数据分析的方法与技术,例如:统计分析法、社会网络分析、自然语言处理、数据挖掘等。学习分析的本质就是挖掘隐藏在教育数据背后的有趣信息与模式,但技术手段需要选取得当,才能省事且不费力地揭示尽可能多的有价值信息。
总的来讲,新OIM关系链是围绕特定学习分析应用情境,关于目标、指标、方法之间关系组合的高度概括。它描述了为实现一定学习分析目标,需要选择哪些数据进行转换,并加以度量,然后采用何种算法展开分析的一套实践逻辑。
通过梳理国内外关于学习分析实践的典型框架或指导模型,本研究抽取其中常涉及到的目标(简称O)、数据(简称 I)、方法(简称 M)的分类描述,最终确定了17个OIM分类值,如表1所示。
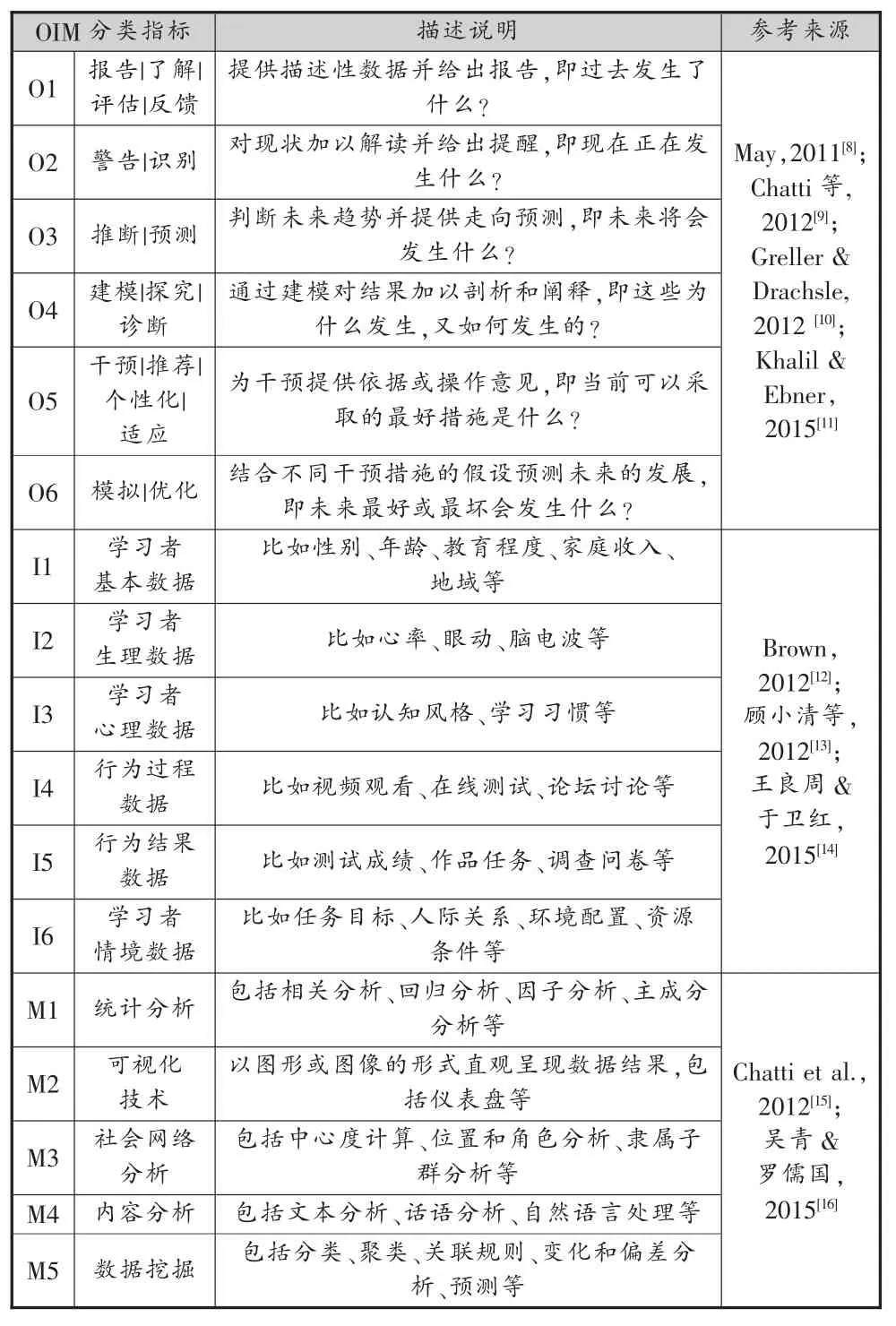
表1 OIM分类指标编码表
三、基于OIM关系链的学习分析规则的建构
(一)研究设计
本研究从学习分析与知识(International Conference on Learning Analytics and Knowledge,LAK)国际会议近五年(2013-2017)的论文中,筛选出学习分析应用实践的有效案例144个;然后,基于案例元分析法,从分析目标(O)、数据指标(I)和技术方法(M)三个维度、17个分类值,对案例加以整理和标识;接着,使用统计分析软件SPSS.24,应用聚类分析(包括二阶聚类和系统聚类)对案例进行分组,进而对聚类结果加以解读,提炼出学习分析实践的常见模式,挖掘所隐含的OIM特征,以此建构出基于OIM关系链的学习分析规则。
(二)研究对象
作为学习分析领域最为权威的国际会议之一,LAK会议由学习分析研究协会(Society for Learning Analytics Research,SoLAR)发起并组织。自2011年SoLAR成立以来,每年召开一次。本研究的学习分析实践案例均来自此会议,所选取2013-2017年间LAK会议的主题和案例抽取情况,如表2所示。
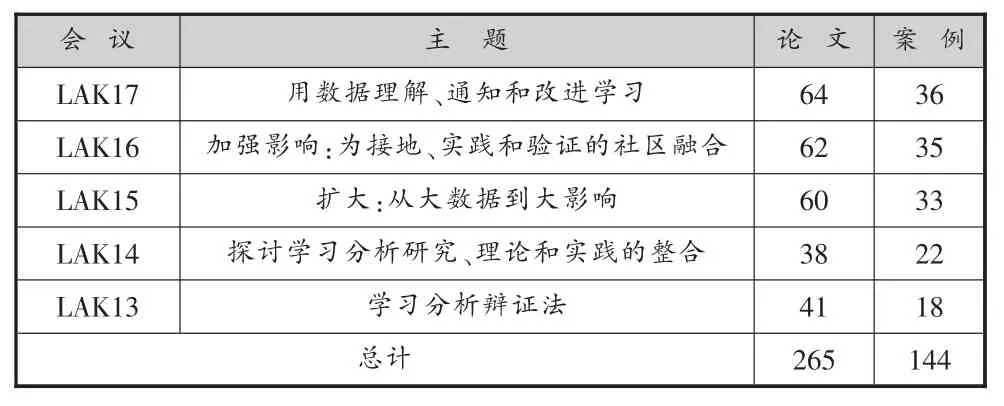
表2 2013-2017年LAK会议主题与案例抽取情况
案例抽取的原则为:(1)案例来自真实的教育实践。具体可分为两种情况:一是使用现实教育中的真实数据开展学习分析探索,以揭示一定的教育问题;二是基于一定的教与学理论,提出应用模型框架并开展实践,然后采用学习分析技术加以检验[17]。学习分析的理论和趋势研究,以及关于学习分析中道德规范的探讨等,不在本研究的案例筛选范畴内。(2)案例必须有清楚的学习分析目标和过程,即在论文中有明确的关于数据集、数据项、分析过程、方法手段等内容的详细介绍。
(三)研究过程
1.数据准备
依据OIM分类指标编码表(表1),本研究从分析目标、数据指标、技术方法三个维度的17个分类指标出发,对入选的144个学习分析案例逐篇标记,“0”表示是,“1”表示否,形成如图1所示的数据矩阵。

图1 案例OIM指标标记示例
2.聚类分析
(1)分类变量的相关性分析。本研究首先分别对目标、数据、方法三个维度的分类变量,进行了相关性分析。6个目标变量之间的相关系数r基本都小于0.5;6个数据变量之间的相关系数r基本都小于0.2;5个方法变量之间的相关系数r基本都小于0.3。结果表明:6个目标变量之间、6个数据变量之间以及5个方法变量之间都不高度相关,均可纳入各自的聚类模型。
(2)二阶聚类确定最佳聚类数。为了确定最佳聚类数,本研究采用了两阶聚类法。两阶聚类法可确定在当前群体中,出现的聚类形成自然而有意义的差异;当使用连续变量和分类变量以及未预先确定聚类数量时,两阶聚类法优于其他形式的聚类分析[18]。因此,本研究分别以目标、数据、方法为聚类变量,对144条案例数据进行了二阶聚类,然后,结合Bayesian信息标准(BIC)数值较小、BIC变化量和距离测量比率数值较大,以及各类的特征变化,最终判定目标分类的最佳聚类数为10类,预测变量的重要性为 O5>O3>O6>O1>O4>O2。 同理可得,数据分类的最佳聚类数为10类;预测变量的重要性为I3>I4>I2>I6>I5>I1。方法分类的最佳聚类数为 8类;预测变量的重要性为 M2>M3>M1>M5>M4。
(3)系统聚类。接着,采用方法选择“组内联接”,测量选择 “二元”|“平方欧氏距离”|存在 “1”|不存在“0”。本研究对144个案例,分别以目标、数据、方法为聚类变量进行了系统聚类。然后,再对每一类聚类结果进行描述性统计,即统计每一个目标类/数据类/方法类的案例集合中,各个目标/数据/方法指标标记的频数。最终,综合频数和频率,以确定每一个目标类/数据类/方法类的目标特征,结果如表3所示。
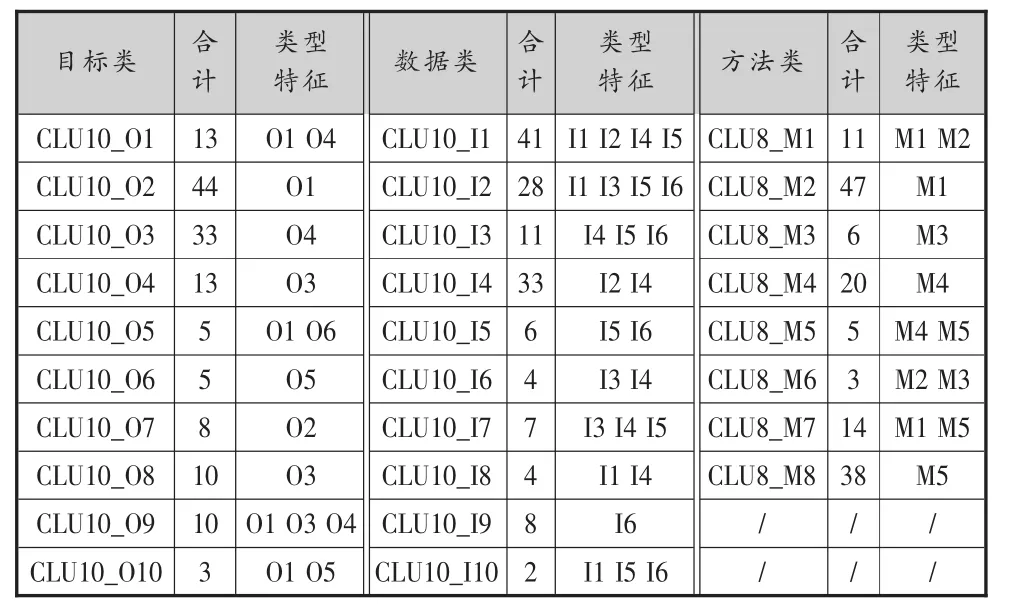
表3 目标类/数据类/方法类的类型特征
(4)聚类变量的方差检验。为了验证聚类结果的可靠性,本研究对目标、数据、方法的聚类结果,分别进行单因素方差分析。以分类变量为因变量,以系统聚类结果产生的类变量为因子。结果显示,各聚类变量差异显著。因此,该分类有效果,17个变量对聚类都起到了作用,都可纳入聚类模型中。
3.多重对应分析与OIM关系链建构策略
为了建构完整的OIM关系链,我们需要了解不同目标类、数据类、方法类变量彼此之间的相关性。设置每个变量权重为1,“解的维数”为2,对分类变量进行多重对应分析,得到如图2所示的类别点联合图。十字虚线是散点图的坐标轴,通过观察变量散点间的相对位置,可知道变量间相关性的强弱。
上述144个案例的系统聚类结果,反映了当前学习分析实践在目标、数据、方法选择上的常见组合;而多重对应分析结果则揭示出目标、数据、方法组合之间的相关性。将两者结合,可作为OIM关系链的建构策略。例如:目标类散点CLU10_O7表示“警告|识别”,以它为圆心在类别点的联合图中画圆,如图2所示。

图2 OIM关系链建构策略实例
CLU10_O7附近有数据类散点CLU10_I6、CLU10_I7、CLU10_I8,方法类散点CLU8_M2、CLU8_M8。通过连线比较发现,CLU10_I6、CLU8_M8与CLU10_O7最为接近。由此,可建构这样一条OIM关系链,即以“警告|识别(CLU10_O7)”为分析目标的学习分析实践,可能选择“学习者心理数据、行为过程数据 (CLU10_I6)”,并采用 “数据挖掘技术(CLU8_M8)”。
四、典型的OIM关系链
基于上述多重对应分析结果和OIM关系链建构策略,结合当下学习分析应用实践的热点话题,本研究提炼出10条典型的学习分析OIM关系链,如图3、表4所示。
第一条:理解学习行为 (O1-I2 I4 I5-M1 M2 M3)

图3 典型的OIM关系链图谱

表4 典型的OIM关系链
学习分析最根本的任务,就是对学习环境中所捕获的大量学习行为数据进行分析处理,进而加以理解,以促进学习的优化。研究者们通过对学习者的在线视频观看情况、学习任务完成状况、在线测验得分,以及论坛参加与发言等数据进行收集和处理,以可视化方式呈现,形成对个体学习行为的过程报告;或者将学习者的行为痕迹与认知或情感过程进行关联,以协助细致地理解行为所发生的情境。
随着Kinect、Leap Motion和计算机视觉等新兴传感技术的运用,新颖而能有意识进行学习支持交互的学习环境,被不断研发出来。在此环境中,更多与学习相关的数据得以被捕捉、记录和分析,比如眼神、语言、肢体运动、面部表情、脑电波、皮肤电、身体激素分泌等。这使得对学习者学习行为的理解,更加全面、透彻。在此规则下的典型案例有Maldonado等[19]、Andrade[20]的研究。
第二条:评估学习设计 (O1 O6-I4 I5 I6-M1 M2)
有效的学习设计是在线学习成功的关键。教师所创建的学习内容要求可访问且包容性强,一方面,能支持学习不同阶段任务的发展需要;另一方面,还要能应对学习者需求和偏好的多样性。对这一创作过程进行评价,可确保最终的教学效果。
为了实现此目标,研究者们分析学习者在学习系统中的行为数据和学习成绩,将两者关联以诊断课程的设计效果,找出能有效增强学习成效的教学实践模型。进而,对各种类型学习者的数据进行模式识别和趋势模拟,提炼能够帮助教师改进学习内容或教学活动的信息,以优化他们的学习设计。此规则下的典型案例有Avila等[21]的研究。
第三条:评估文本写作 (O1 O4-I5 I6-M1 M4 M5)
文本写作是教学中经常运用到的交流和反思实践活动。学习者发言可为教师开展形成性学习评估提供丰富的数据参考。传统方式的文本评价由教师主导,但教师因自身阅历、情绪状态以及理解能力等限制,评估结果往往受主观因素影响较大,因而,学习者的学习状态与结果很难被全面、客观、合理地加以反映。
当前,自然语言处理、文本建模、文本挖掘等技术的发展,使得依赖技术实现分析和解读文本成为可能,其可有效协助教师和管理者基于学习者的文本信息,开展学习诊断与评估。此规则下的典型案例有 Chen 等[22],Whitelock 等[23]的研究。
第四条:识别高危学生(O2 O3-I1 I4 I5-M1 M5)
对高危学生 (包括学习能力较弱的学生或存在辍学可能的学生)的预警与干预,可有效提升在线学习平台的学生保有率,降低学校和教育机构的辍学率,改善在线学习的服务质量。在智慧教育的大背景下,如何利用教育大数据成功识别高危学生人群,是当前在线教育发展迫切需要解决的难题。
从理论上看,当数据的数量和类型足够丰富时,记录学习者真实行为表现的学习数据,即是最好的预测数据源。因此,可将学习者当前课程的学习状况与历史测评成绩相结合,然后,对学生的危险程度加以评估和诊断。但在具体实践中,相对简单的学习者学业成绩、学习活动参与数据、学习者的人口学统计信息,仍然是使用最多的评估变量。在完成对数据的清洗、归集等预处理之后,学习分析通常会以机器学习技术为核心,建立风险预测模型,以此展开对高危学生的甄别。常用的预测算法有Logistic回归、支持向量机(SVM)、朴素贝叶斯(Naive Bayes)、随机森林(Random Forests)、决策树(Decision trees)等。此规则下的典型案例有Hlostaetal等[24],Lorenzo等[25]的研究。
第五条:学习者分类(O1 O3-I1 I3 I4 I5-M5)
构建学习者模型,对学习者进行分类是实现个性化学习机制的关键。研究者们首先需要收集学习者在学习系统中的行为过程和结果数据,结合人口学统计信息、学习兴趣、学习风格和偏好等学习者的基本信息数据,使用数据挖掘和机器学习算法,构建出不同类型学习者的学习特征集。例如,聚类分析和关联规则分析,常被用来抽取学习者的访问模式、学习兴趣和学习策略等。接着,再归类或分组具有相似学习特征的学习者,分别对不同类型的学习者,提供适合的学习资源、学习环境以及学习建议,以实现学习的个性化,促进有效学习的发生。此规则下的典型案例有 Ferguson 等[26],Xiao Hu 等[27],Corrin 等[28]的研究。
第六条:学习者行为建模(O3 O4-I4 I5-M5)
学习行为是学习过程的重要表现,对学习成效有着重要的影响。首先,研究者们收集学习者的学习进度信息、学习行为变化情况(比如:观看时长、访问频次、点击序列、暂停规律等)、在时间轨迹上的学习活动流信息、前后测试成绩等数据。然后,结合不同的学习任务情境,抽取其中的行为特征,并通过数据挖掘识别学习者行为在决策和执行上的差异,从而提炼出不同的学习行为模型。进一步分析学习者对学习资源、学习环境以及教师和同伴的不同反馈,还可用于研究不同行为模型与学业成绩之间的关联。此规则下的典型案例有Kaiser等[29]、Papamitsiou等[30]的研究。
第七条:学习者知识建模(O1 O4-I4 I5 I6-M3 M4 M5)
学习者知识模型体现了学习者的过程性知识体系,主要应用于自适应学习系统和智能教学系统等。这便于系统在恰当的时间、以恰当的学习方式,推送恰当的学习内容给学习者。为了描述学习者知识与技能的建构过程和掌握情况,研究者们从学科、专业、课程、知识点等不同层面,抽取在线学习系统中学习者的交互数据,包括学习者作答的正误率、回答问题的时长、求助的数量和类型,以及错误的重复率等等。同时,结合领域知识图谱,通过内容分析和文本挖掘技术,构建不同的学习者知识模型。
同时,学习者可通过参与在线协作学习,在社交和文化环境中共同建构知识。由于学习者同时面对自己及其合作伙伴的知识与文化差异,而引发不同的话语互动和思维碰撞,因此,社会网络分析也是重要的一项分析技术。此规则下的典型案例有Peffer和 Kyle[31]、Ferguson 等[32]的研究。
第八条:学习者情绪建模(O1 O4-I2 I3 I5-M1 M2 M4)
越复杂、高阶的学习,越需要良好的情绪调控。近年来,围绕情绪与认知之间的联系,教育心理学、神经科学和人工智能教育领域开展了大量的研究,试图揭示情绪在学习过程中的作用机制。为检测学习者“无聊”、“沮丧”、“兴奋”等不同情感状态,对学习积极性和学习进展的影响,研究者们目前利用视觉跟踪器、心脏速率监视器等多种可穿戴技术,收集和分析类似微笑次数、专注时间、心跳速率等身体活动数据。同时,结合学习者的自我报告来对学习者的学习情绪模型加以建构,并通过情绪可视化分析仪表盘加以呈现。计算机面部识别技术的最新发展使用,以及非侵入式网络摄像头结合复杂算法的支持,使得实时测量学习者的情绪成为可能。此规则下的典型案例有Allen等[33]、Zaouia和Lavoue[34]等的研究。
第九条:预测学习表现 (O3 O4-I4 I5-M1 M4 M5)
对学习者学习表现和结果预测,是当前教学干预与后期教学优化的重要参考依据。预测通常以学习者以往的学习数据为基础,挖掘并分析其发展变化,推算其可能的学习结果,以便及时识别不良的学习状态。传统的学习表现预测比较单一,主要是根据学习者过去的学业成绩表现,以及对在学习管理系统(LMS)中的交互进行预判。
而当前可获取的学习数据类型逐渐多样化,个人背景特征、学习作品档案、多模态技能、学习情绪和情感状态都是新增加的因素,可作为常见分析指标,用于诊断学习表现。通过组合不同层级、不同类型的数据,从中找出能够评价学习者表现的观察指标,成为当前预测研究的重要步骤。但在实践中仍主要以学习行为的频次分析为主,在预测算法上以多元回归分析为主。此规则下的典型案例有Kennedy等[35]、Elbadrawy 等[36]的研究。
第十条:个性化和自适应(O1 O4 O5-I4 I5-M1 M5)
个性化和自适应是学习分析在教育应用中的终极目标。要实现这一目标,首先,需要提取学习者个体或群体的特征,构建相关的学习者模型;然后,结合所获取的学习状态、学习效果等信息,预测学习者的认知偏好、兴趣需求和学习表现;最后,依据预先定义好的学习策略和方案,实现针对不同学习行为或结果的自动化反馈,为学习者提供个性化的学习建议或资源,从而调整或改善学习者的在线学习体验。此规则下的典型案例有Mutahi等[37]的研究。
五、基于OIM关系链的开放学习分析系统架构
随着学习分析应用实践的不断深入,以及智慧教育理念的成熟,越来越多的学习平台和系统开始在自身服务中,引入或加强学习分析的支持,比如Moodle、Sakai、Blackboard、MOOCs等。由于该应用是在单个的系统或平台上运行的,因此,跨平台的各类数据与资源无法整合,也不能全面地捕捉学习者的所有学习轨迹。
与此同时,在丰富的技术手段支持下,学习者的学习活动愈加多元和开放,可以发生在课堂内、课堂外,校内、校外的不同时空环境中(可以线上线下),涉及学校、家庭、工作、社区、爱好等正式或非正式的学习情境。因此,单一孤立的学习分析架构,已无法完整、准确地描绘学习者的学习全貌。
基于此,“开放学习分析 (Open Learning Analytics)”这一术语开始出现在由SoLAR发布的2011年愿景文件中。文件提出,要搭建一个集成的模块化平台,来整合异构的学习分析技术[38]。随后,关于开放学习分析的研究开始得到极大的关注。英国联合信息系统委员会(JISC)[39]基于项目实践,提出了划分为数据收集、数据存储和分析、演示和动作三层的开放学习分析架构(OLAA)。2015年,美国Apereo基金会设计了由“沟通”作为介导的开放学习分析“钻石模型”,包含“收集”、“存储”、“分析”和“行动”四个主要领域[40]。Chatti等[41]研究者则提出了开放式学习分析生态系统的理念,并讨论了实现开放式学习分析的四个要素:用户场景、教育需求、技术架构和平台组件。
本研究在参考现有开放学习分析模型的基础上,提出了基于OIM关系链的 “开放学习分析系统”(OIM based Open Learning Analytics System, OIMOLAS)[42],如图4所示。OIMOLAS引入揭示学习分析目标、数据和方法之间映射关系的OIM关系链,来增强在不同教育应用问题情境下,开放学习分析操作的目标和过程导向实施流程的程序化和规范性,以确保分析结果的可用性和有效性。

图4 基于OIM关系链的“开放学习分析系统”架构
OIMOLAS由数据管理、数据映射、分析引擎、分析算法、可视化呈现这五大核心组件构成。数据管理组件对收集的数据进行预处理准备,包括清洗、变换、规约、集成等过程,将数据转换为适合后续分析的输入格式。不同利益相关者的用户,根据自身需求在平台的菜单项中选择特定的分析目标,从而将目标信息传递到分析引擎中,触发学习分析任务的执行。
分析引擎作为整个学习分析系统的协同中枢,首先,从OIM关系链库中,读取出适配于当前分析目标任务的OIM关系链(可能一条或多条),并结合以往执行历史加以策略性的评估和选择。OIM关系链定义了不同问题情境的学习分析逻辑,每个分析目标都对应有一套数据指标。分析引擎围绕这些指定的数据指标,从数据管理器中提取学习分析所需要使用的数据,并在数据映射器中加以标记。同时,分析引擎还从分析算法组件中,调用选定的OIM关系链所设定的技术方法,进行数据分析。分析结果以仪表盘方式,在系统或APP中进行可视化呈现;或者以交互数据形式提供反馈 (例如提出干预建议),来影响教学服务流程。分析过程可以调用一些预设好的学习者画像库和内容建模库,以加强分析的效率和效果。而分析的结果,又会进一步反馈优化学习者画像和内容建模的识别策略和模型特征。最后,隐私规则会约束和作用于整个学习分析实施的各个环节,以保护学习者的隐私。
OIMOLAS遵循系统开放性、互操作性和标准化的原则。OIMOLAS可收集多种来源的学习数据,以统一的数据格式标准,存储在学习记录存储库(Learning Record Store, LRS)中。 OIMOLAS 的数据类型,也不再局限于各类学习平台自动捕获的学习数据,而是超越LMS,可汇聚多模态的教育数据,比如MOOCs、社交媒体、眼动仪、可穿戴设备等。
为实现数据之间的沟通与操作,在OIMOLAS中,数据的收集和存储,将遵循两大国际主流学习分析技术规范xAPI和IMS Caliper[43]。学习分析所得的数据结果,也将遵循学习工具互操作规范(Learning Tools Interoperability,LTI),返回指定的系统平台和工具。
此外,OIMOLAS还可实现 “自学习”。一方面,OIMOLAS通过学习分析的实践反馈,不断校正或优化OIM关系链的效度;另一方面,OIMOLAS还可通过收录用户对OIM关系链的自主定义,以扩展分析的领域。在分析算法组件中,OIMOLAS预先存储了一些公共的、通用的分析算法;而对于一些特殊的分析目标,尤其是用户自主配置的,分析引擎在调用数据映射、学习者画像、内容建模等模块的分析运作中,开展深度学习,从而衍生出新的分析方法。
六、总结与展望
智慧教育是教育信息化发展追求成效与卓越的新境界,它表达了一种技术以洞察性、连通性、智慧性方式,促进教与学活动的行动导向[44],因此,更加要求学习分析在提供“数据证据”方面的大力支持和常态应用。引入OIM关系链的方法思想,围绕学习分析的目标确定、指标选择、方法应用构建学习分析规则,可优化当前学习行为分析领域的研究视角和技术路线,大大提升学习分析数据发现的指向和挖掘的效率。
本研究基于144个学习分析的实践案例,构建了10条典型的OIM关系链。在规则应用的路径方面,学习分析实践者既可以从问题情境和分析目标出发,选择相适应的数据和方法,确保分析结果的行动指向;也可以从现有的各类学习数据出发,挖掘数据中所隐含的学习相关信息,并在一定程度上指导学习分析的数据收集环节;还可以从OIM的关系出发,进一步细化学习分析规则的操作。
在规则应用的方式方面,OIM关系链既可以作为开展相关实践和研究的行动指南和指导规则 (实践应用);也可以应用于学习分析系统(系统应用),作为系统分析模块的程序逻辑和执行智能。此外,本研究还提出了基于OIM关系链的开放学习分析系统(OIMOLAS)的系统架构。在应用形式上,OIMOLAS既可作为LMS、MOOC等平台的嵌入式模块构件,服务于开放学习生态发展的必然趋势;也可以作为独立运作的学习分析系统,为LMS、MOOC等学习平台提供专业、全面的数据分析服务。
但总体而言,本研究仍属于探索性研究,学习情境分析规则的构建,还存在以下一些问题:(1)进一步细化学习分析规则在目标、数据、方法维度的指标内容,提高实践的可操作性;(2)可尝试建立面向更多教育情境的OIM关系链,特别是非正式教育,以更好地揭示学习生态的全貌;(3)可尝试建立学习分析规则应用的案例库,以案例的方式提供不同情境下学习分析规则的应用示范;(4)进一步细化OIMOLAS系统架构组件的技术开发和细节;等等。
本研究通过对OIM关系链学习分析规则的探讨,希望能够抛砖引玉,引起业内研究者对于学习分析实践中,引入教育学方法指导的关注、思考与讨论,增强学习分析今后实践与应用的效能,助力学习分析的常态化发展,以加快智慧教育视域下学习分析实践应用的进程。
