基于人工智能推理引擎在微博数据挖掘中的应用分析
2018-11-22杨达贤
杨达贤
(厦门云之端信息科技有限公司, 漳州 361000)
0 引言
微博作为一种互动的信息平台,在社交中的地位越来越重要。此外,微博还可以通过用户的关注形成一个庞大的人际互动网络。然而,很多人只是使用了微博的少数功能。为了促进微博的应用和提高微博的可用性和乐趣,搜狐微博推出"想你知道”功能。人工智能推理引擎系统根据用户输入的词语,自动进行归纳推理,并将推理结果反馈给用户[1]。
现有的搜索引擎资源获取方式是盲目的。依靠现有的算法,往往会得到大量的不相关信息,导致效率和搜索精确度下降。该系统基于人工智能(包括增益和衰减),自动调整推理机系统,不仅大大降低了后台人员的维护成本,而且提高了用户体验,使微博用户获得更好、更准确的服务[2]。
1 人工智能引擎
1.1 搜索引擎分类
搜索引擎是指通过网络爬虫程序获取网页数据,并建立数据库提供查询系统。根据工作原理,引擎分为两类:一类是分类搜索目录;另一类是全文搜索目录[ 3 ]。
全文搜索引擎的数据库是基于一个名为“网络爬虫”的软件。它通过web上的各种链接自动获取大量的Web信息内容,并根据既定规则进行分析和排序。分类法是收集和收集Web数据以手动形成数据库的[4]。
1.2 工作原理
全文搜索引擎是一种网络软件,它穿越网络空间,可以扫描网站的某个地址范围,并沿着网络从一个页面链接到另一个页面,从一个站点到另一个网页数据采集网络。其工作原理,如图1所示。
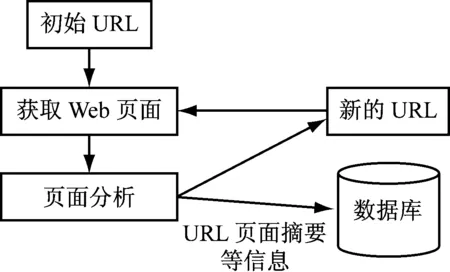
图1 网络爬虫工作原理
1.3 人工智能推理引擎
将人工智能应用于网络爬虫程序,将使搜索引擎在获取信息资源方面取得更大的成功。
采用启发式算法,网络爬虫可以消除无关链接,访问和浏览。在整个页面中合格页面的比例相当大。网络爬虫收集信息资源的准确性也提高了[5]。
2 数据挖掘
微博信息丰富,数据量巨大,所以微博数据的研究中,应选择合理的数据采集方法,为本文的研究提供了方便,数据采集分为以下3种类型:官方API采集,通过网络爬虫抓取网页和直接使用开放的数据集[6]。
2.1 数据获取
(1) 基于官方API开发的系统。
为了使微博提供的服务和嵌入的小应用更加多样化和更加具有吸引力,开发商选择了向应用开发者和研究人员提供开放式的应用接口,即开放API。开放API指的是开放应用程序编程接口,即使用SOAP、JavaScript等的一系列技术[7]。
(2) 通过网络爬虫爬取微博页面。
通过网络爬虫抓取微博数据通常指的是通过HTTP协议发送请求到服务器,分析返回的网页,并提取相应的微博数据[8]。
这种方法几乎适用于任何微博数据的获取,与官方API的数据采集不同,它不受微博运营商权限的限制。
(3) 开放的数据集。
随着web2.0的发展,信息披露和资源共享变得越来越重要。越来越多的学者将语言库和数据集开放到不同的开放程度以供开发和使用。利用已有的数据集,避免了预处理过程,提高了研究效率[9]。
目前,在微博数据的应用研究中,首先采用的是数据采集的方法。这些数据采集方法基本上满足了研究人员的需要,但也存在一些差异。
2.2 数据选择
根据引擎开发的目的,选择研发适用范围内的数据集至关重要。在之前的微博数据选择范围研究中,研究人员一般选择以下两种数据选择方法。
(1) 指定主题或者用户
当研究人员利用微博中的数据进行社会现象分析或用户行为分析等相关研究时,他们通常会在指定的主题或用户中选择数据[10]。根据研究的需要,研究人员通常使用规定的时间段来限制数据量。在数据选择的过程中,也存在随机选择过程[ 11 ]。
(2) 随机获取用户数据
在理论和实践研究方面,当研究者需要研究微博的结构特点、拓扑结构、性能评价及其应用时,通常采用随机访问用户数据的方式。随机获取用户数据和信息的方法可以掌握微博用户群的全部数据。它可以得到更准确、更全面的结果,也更有利于微博自身的发展和发展。
2.3 数据分析
在数据分析阶段中,主要工作是对微博数据库中的数据进行特征提取和分析。一般采用社会网络分析、数理统计和数据挖掘等方法。
(1) 社会网络分析方法。
社会网络分析方法主要是利用网络拓扑图来反映社会结构之间的关系和属性。这种方法能够从大局上把握微博的整体特征和用户之间交互情况。通过分析以往的研究成果,也证实了社会网络分析方法在微博中的应用是可行的、相对成熟的[12]。
(2) 数理统计方法
数理统计方法在社会科学相关的科学研究中比较常用,是一种定量分析方法。该方法通过用户的基本信息数据和经常使用的数据,利用统计学方法对数据中的某些参数或者参数间的关系进行统计和分析。通过分析和研究得出整体数据的分布特征[13]。
(3) 数据挖掘方法
数据挖掘是采用智能自动或半自动的,采用相关分析、聚类分析、分类、预测、时间序列模型和误差分析,分析大量的数据,做出归纳性的推理,趋势和相关资料,挖掘隐含的、先前未知的、潜在的信息价值。
3 微博数据特点
微博是一个信息分享、传播的平台,这种分享和传播是通过相互关注的人之间进行的。用户可以通过WEB、WAP(手机客户端)和各种客户端建立个人的交往圈子。微博具有短文本性、终端扩展性、即时性、“裂变型”、信息传递性等特点[ 14 ]。
3.1 篇散文的性质
传统博客(blog)不限制用户发文的篇幅,而微博将用户的发文限制在140个字符以内。
3.2 终端的可扩展性
因为微博平台具有开放性,因此,用户可以通过web、wap等多种方式轻松使用微博。根据美国互联网统计公司统计分析,与2011年相比,2012年的移动推特用户数量增加了约101%。目前,它已成为增长最快的社交网络应用[ 15 ]。
3.3 即时性
微博具有及时性,主要表现是内容发布的即时性和信息传播的即时性。由于微博的及时性及短端扩展性,用户可以通过网络随时随地快速发布微博。微博的及时性彻底改变了信息传播的模式,使信息传播平台变得更加强大[ 16 ]。
此外,当微博用户的好友在主页上更新消息时,系统会自动在用户主页上完成信息的更新,并将其推送到微博好友的主页上。这一步骤几乎是同时完成的,这样就进一步增强了微博信息的即时性。
3.4 “裂变类型”信息传播
微博的转发功能,使信息不受限制地转发。信息传递的范围是“核裂变”、公式的几何级数展开、微博的主动推送功能,信息迅速传播给广大用户。
4 人工智能推理系统的设计
4.1 系统结构
智能数据挖掘引擎由五个功能单元组成:核心算法模块、智能选择模块、输入输出模块、元知识库和中央控制模块。组成结构,如图2所示。
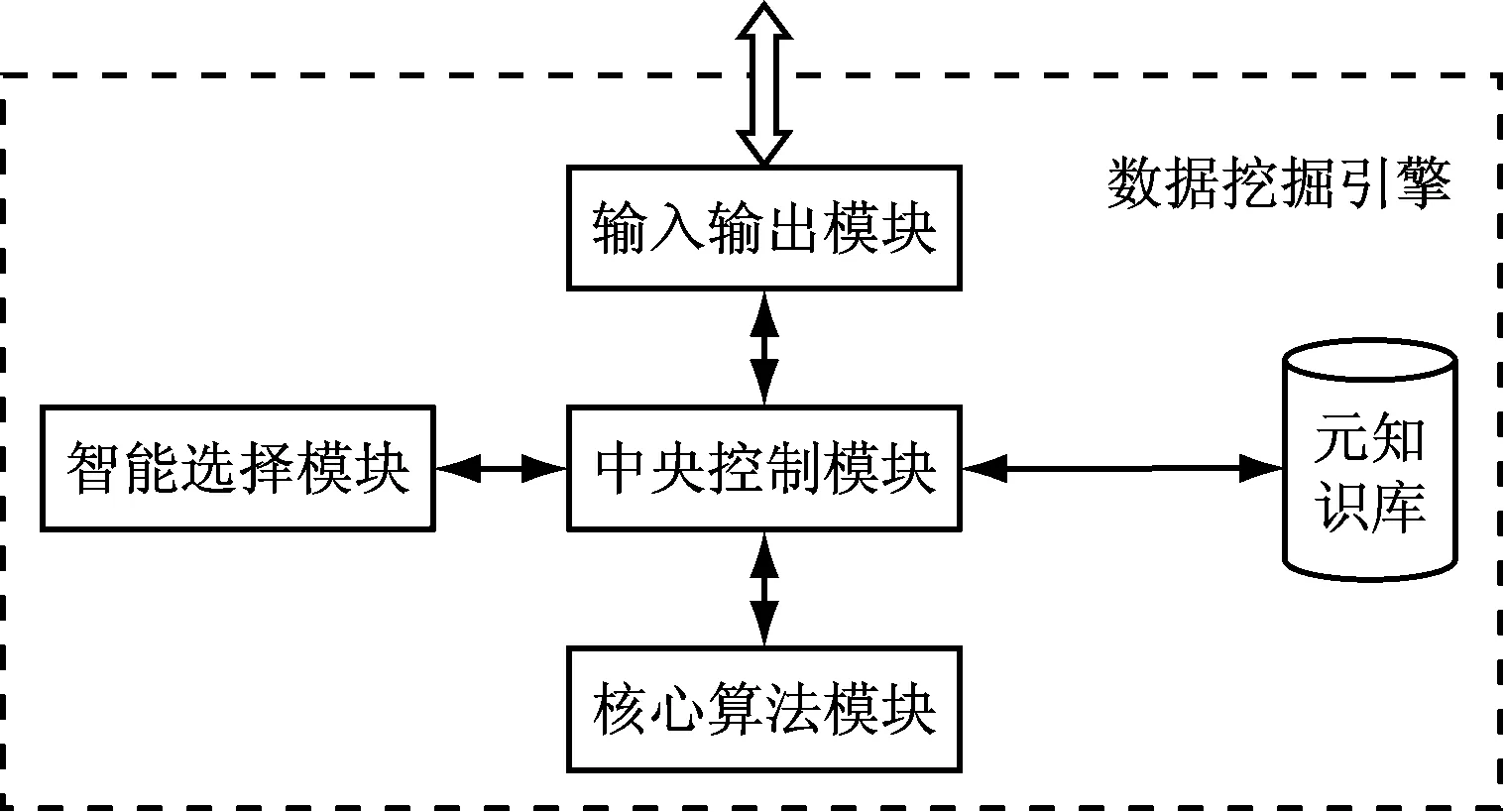
图2 智能数据挖掘引擎组成结构
(1) 核心算法模块
核心算法模块完成了数据挖掘引擎最基本的处理功能,是引擎中最重要的部分。核心算法模块主要由关联规则算法、基于内存的推理算法(MBR)和基于实例的推理算法(CBR)组成。
(2) 智能选择模块
智能选择模块根据用户数据挖掘的特点和信息提取的方式,决定合适的数据挖掘算法和数据挖掘,以达到最佳的挖掘效果。智能选择模块是数据挖掘引擎的核心智能模块,它直接决定了数据挖掘引擎的效率。
(3) 输入输出模块
输入输出模块负责从数据挖掘市场(数据源)和信息柜中从数据挖掘系统控制器中输入数据。数据通过中央控制模块提交给智能选择模块。同时,输入输出模块还负责向数据挖掘系统控制器提交数据挖掘引擎核心算法模块的处理结果。
(4) 中央控制模块
中央控制模块是数据挖掘引擎的核心控制单元,负责整个引擎的各个模块的协调和控制。通过控制引擎的输入输出模块,控制引擎与整个数据挖掘系统之间的相互作用,实现引擎的完整性和独立性。
(5) 元知识库
元知识库主要存储数据挖掘引擎构建和工作过程的知识、核心算法模块算法和智能选择模块,中央控制模块负责对数据挖掘引擎进行更新和控制。元知识库是实现数据挖掘引擎智能化的基本单元。
4.2 关键技术
(1) 数据挖掘算法
数据挖掘算法是整个数据挖掘引擎的核心。不同的挖掘算法有不同的应用领域和特点,这就要求数据挖掘引擎在数据挖掘时必须有多种算法供用户选择。
(2) 智能选择控制技术
智能选择控制技术是实现数据挖掘引擎通用性的关键技术。基于元数据库的推理机制实现了引擎的智能选择。
(3) 元知识库
利用元知识库对数据挖掘算法、智能选择模块、中央控制模块和引擎工作控制过程中的知识信息进行存储和管理。元知识库中知识的存储和管理对整个引擎的性能至关重要。
4.3 系统流程
这个过程包括设置状态参数、数据和用户需求预处理、加载元素知识库和一些模块的初始化等。
(1) 导入数据挖掘引擎的状态参数配置文件,设置引擎的状态;状态参数配置文件是一个文本文件,用于描述引擎的默认参数。
(2) 收集数据的特征信息和用户的请求信息。
(3) 加载元知识库知识。
(4) 将相关参数和元知识传递给相应的功能模块。
(5) 初始化中央控制模块。
(6) 初始化智能选择模块。
最后,在中央控制模块的控制下,智能模块选择合适的数据挖掘算法模块,根据元数据库提供的元知识、数据特征信息和用户需求进行数据挖掘。
5 总结
将人工智能运用到搜索引擎中,可以帮助用户更加便捷、更加准确的搜索到需要的信息。因此,人工智能推理引擎将是未来发展的趋势。本文可以得出以下结论:
(1) 搜索引擎工作方式不同,微博数据体量庞大,人工智能推理引擎可以收集用户的关键词和使用习惯,即时向用户推送需要的信息、功能和使用方法。
(2) 人工智能搜索引擎的实现需要设计智能数据挖掘引擎系统。智能数据挖掘引擎由五个功能单元组成:核心算法模块、智能选择模块、输入输出模块、元知识库以及中央控制模块等。
(3) 数据挖掘算法是人工智能推理引擎的基石。挖掘算法是否具有先进性和高效性,直接决定了数据挖掘引擎的性能。
