自动回复系统中基于焦点的问题分类
2018-11-22刘淑婷
刘淑婷
(西安翻译学院 工程技术学院,西安 710105)
0 引言
医保卡自动回复系统的建设补充了现有的咨询渠道,实现了信息及时、高效地传递,方便参保用户通过短信平台及时咨询医保缴费、报销、办理流程等问题,用户能随时了解参保情况,并享受医疗保险待遇,提高了西安市人社局的办公效率和对参保用户的服务质量,在参保用户与西安市人社局之间建立了一种快捷、高效、方便地的沟通渠道。
1 自动回复系统
自动回复系统目的是将精确答案发送到用户手机上,并将已发送信息保存到数据库中备查[1]。按照处理顺序分为问题理解、信息检索、答案抽取[2]。问题理解是对问句进行分析,包括词法分析、语义分析、问题分类,其准确度直接影响后续阶段的处理[3]。信息检索是在文档集合中利用问题理解抽取出来的关键字查找出相关的文档[4]。答案抽取是从信息检索得出的文档中提取与问题相关的段落生成答案[5]。自动回复系统的主要流程如图1所示。
2 基于焦点的问题分类
问题理解需要对问题语句做出分类,并对问题的类型、语义和答案类型等进行定性和定量。问题分析的质量限定了备选答案的范围,并减少了答案的搜索空间,决定后续步骤采取的处理策略。

图1 自动回复系统的主要流程
2.1 利用问题焦点分析分类的优势
传统的问题分析在对问题分析完成后留下的是关键词和一些对关键词的扩展,将句子分割成词,降低了语言表达能力,并且丢失了词语之间的关系,而问题焦点表示的问题分析在输出关键词集合的同时,还完整的保留了问句的句式结构和语义。
2.2 问题焦点的确定
汉语问句,一般分为疑问句、反问句、设问句,医保卡自动回复系统只处理用于询问信息的疑问句。疑问句主要分为是非问句、选择问句、特指问句[6]。据统计,在医保业务咨询方面是非问句不到10%,选择问句不到1%,约90%都是特指问句。所以本文重点对特指问句分析。
问题焦点定义:问题焦点(Question Focus,QF)是由疑问类型与疑问内容组成:
QF={疑问类型:疑问词,疑问对象:疑问内容}
例如,问题Q(A)={医保卡怎么补办?},疑问类型为特指疑问,疑问词为“怎么”,疑问对象为“补办”事件,所以问题焦点为QF(A)={特指疑问:怎么;事件:补办}。
2.2.1 疑问类型
疑问类型是问题焦点的疑问形式。特殊疑问的疑问类型常含有“什么”、“哪里”、“为什么”、“多少”等特指疑问词,其本身已显现询问者想知道的内容及回答方式,这些疑问词就是疑问句的问题焦点,能很准确的提取疑问句的意思。
2.2.2 疑问对象
疑问对象是询问者想知道的问题答案。事就是事件,包括事件自身(如:补办、办理、报销等)、事件论元(如:方式、地点、时间等)、事件之间的关系(如:区别、流程等);物就是实体,包括实体自身(如:医保卡、医疗保险、医保等)、实体的属性(如:卡号、基数、缴费比例等)、实体之间的相互关系(如:不同、包含等)等。疑问对象分为两大类六小类。如表1所示。

表1 问题语义内容分类体系实例
2.3 问题分类的方法
问题分类是把问题让机器区分,将寻找答案的范围尽量缩小,以提高答案的精度。问题分类结果的好坏直接影响问题回答的系统性能。问题焦点分类流程,如图2所示。
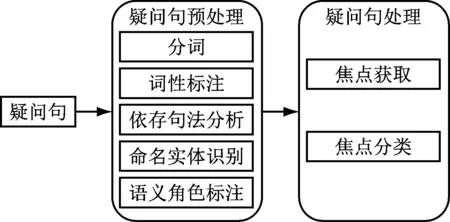
图2 问题焦点分类流程
2.3.1 问题焦点的获取
从问句中识别、标注问题焦点,建立问题焦点数据结构,筛选问题中的相关信息,添加到焦点数据结构中,即焦点的获取。
本文调用语言云(语言技术平台云 LTP-Cloud)对汉语中的文本句子进行分词处理。 LTP中采用863词性标注集,部分词性含义,如表2所示。
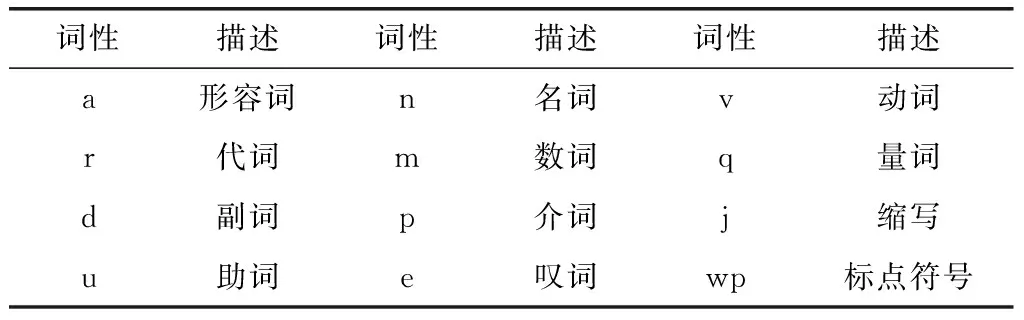
表2 部分词性含义
依存句法分析标注关系(共14种)及含义,如表3所示。
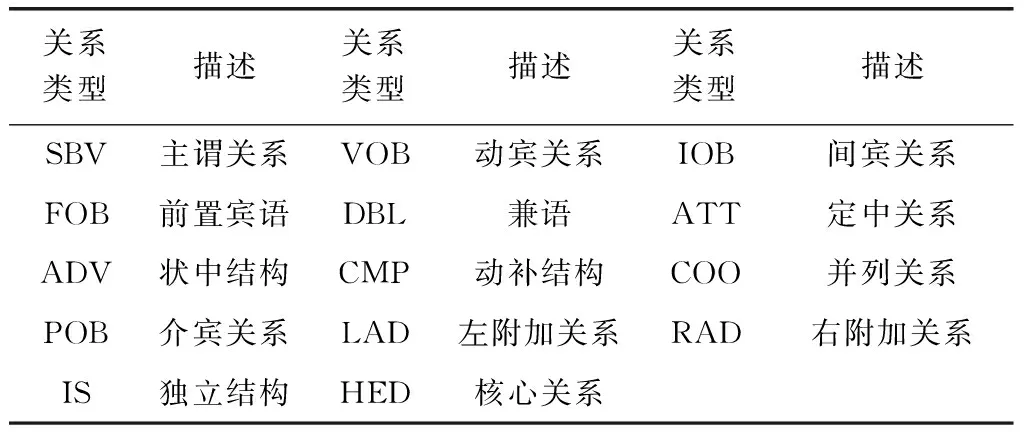
表3 依存句法分析标注关系(共14种)及含义
核心的语义角色为 A0-5 六种,A0 通常表示动作的施事,A1通常表示动作的影响等,A2-5 根据谓语动词不同会有不同的语义含义。其余的15个语义角色为附加语义角色。附加语义角色列表,如表4所示。
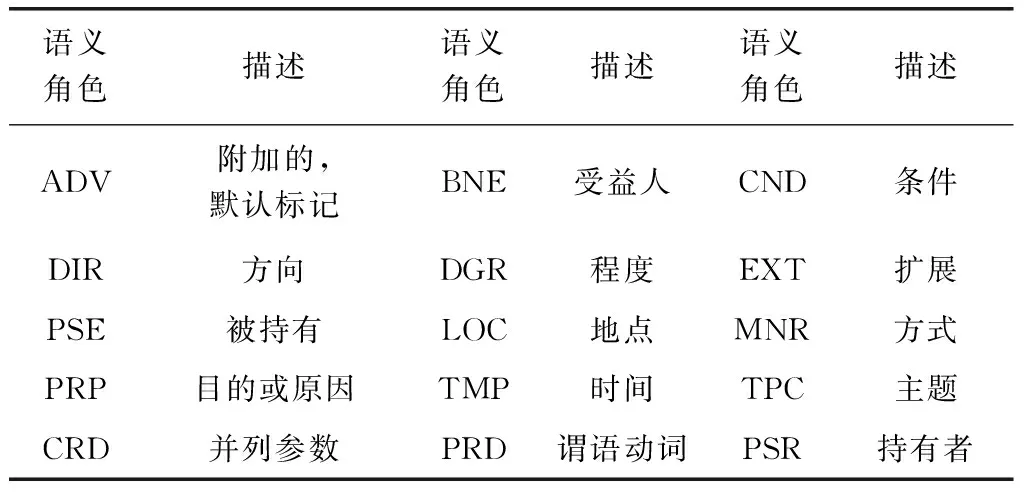
表4 附加语义角色及含义
例如,对问题A“怎样补办医保卡?”的预处理结果,如图3所示。

图3 对问题A“怎样补办医保卡?”的预处理结果
结果汇总,如表5所示。
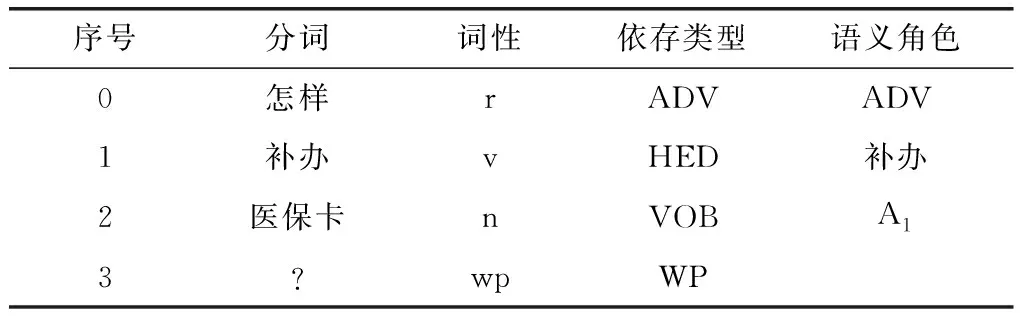
表5 问题A预处理结果
通过哈工大语言云的分析得出,问题A中的词性分别为:怎样(r代词), 补办(v动词),医保卡(n名词),?(wp标点符号)。
根据依存句法的分析结果,句子的核心谓词为“补办”,补办的宾语是“医保卡”,它们构成VOB动宾关系,“怎样”是“补办”的状语,它们构成ADV状中关系。
在语义角色标注中,补办是谓词,怎样是它的方式(用ADV表示),医保卡是它的受事(用A1表示)。
规则1:疑问词指代实体
例如,问题Q1={医保卡是什么?},“医保卡”是“是”的A0论元,以SBV依存于“是”;“什么”是“是”的A1论元,以VOB依存于“是”,得出的问题焦点QF(Q1)={特指疑问:什么;实体:医保卡},如图4所示。
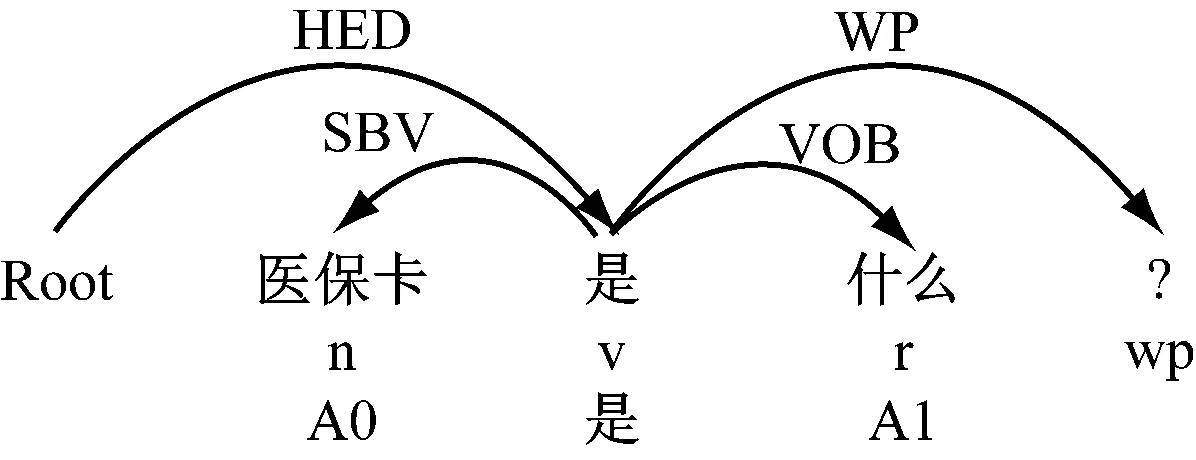
图4 对问题Q1的预处理结果
问题Q2={什么是医保卡?},“什么”是“是”的A0论元,以SBV依存于“是”;“医保卡”是“是”的A1论元,以VOB依存于“是”,得出的问题焦点QF(Q2)={特指疑问:什么;实体:医保卡},如图5所示。
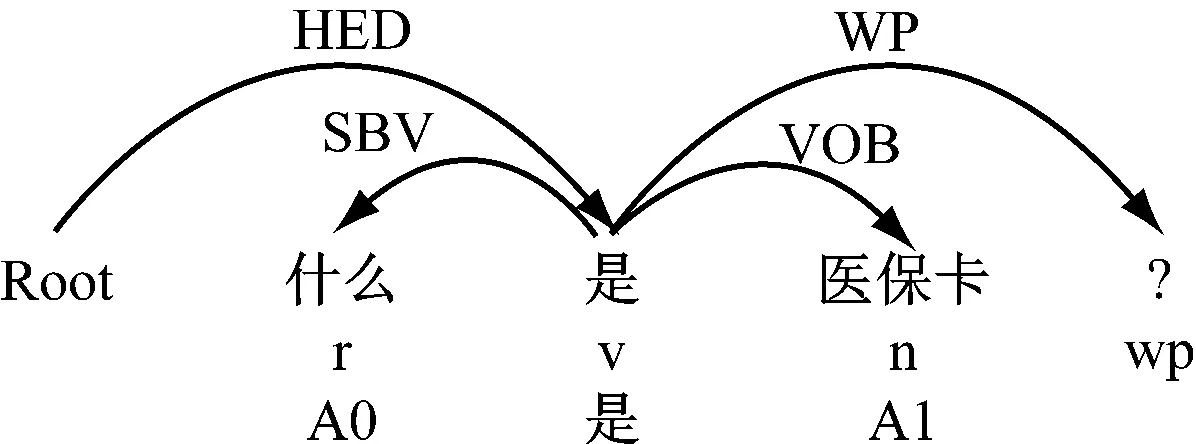
图5 对问题Q2的预处理结果
通过哈工大语言云分析得出,实体的名词是“医保卡”,Q1的焦点与Q1的焦点是一致的,即QF(Q1)=QF(Q2)。
规则2:疑问词修饰实体的属性
例如,问题Q3={医保卡的卡号是多少?},“医保卡的卡号”是“是”的A0论元,“卡号”以SBV依存于“是”;“多少”是“是”的A1论元,以VOB依存于“是”,从而确定问题的焦点,QF(Q3)={特指疑问:多少;实体属性(医保卡-卡号):?},用户的疑问是想知道实体“医保卡”的属性“卡号”的取值是什么,如图6所示。

图6 对问题Q3的预处理结果
问题Q4={医保的最低基数是多少?},“医保的最低基数”是“是”的A0论元,“基数”以SBV依存于“是”;“多少”是“是”的A1论元,以VOB依存于“是”,从而确定问题的焦点,QF(Q4)={特指疑问:多少;实体属性(医保-最低基数):? },用户的疑问是想知道实体“医保”的属性“最低基数”的取值是什么,如图7所示。
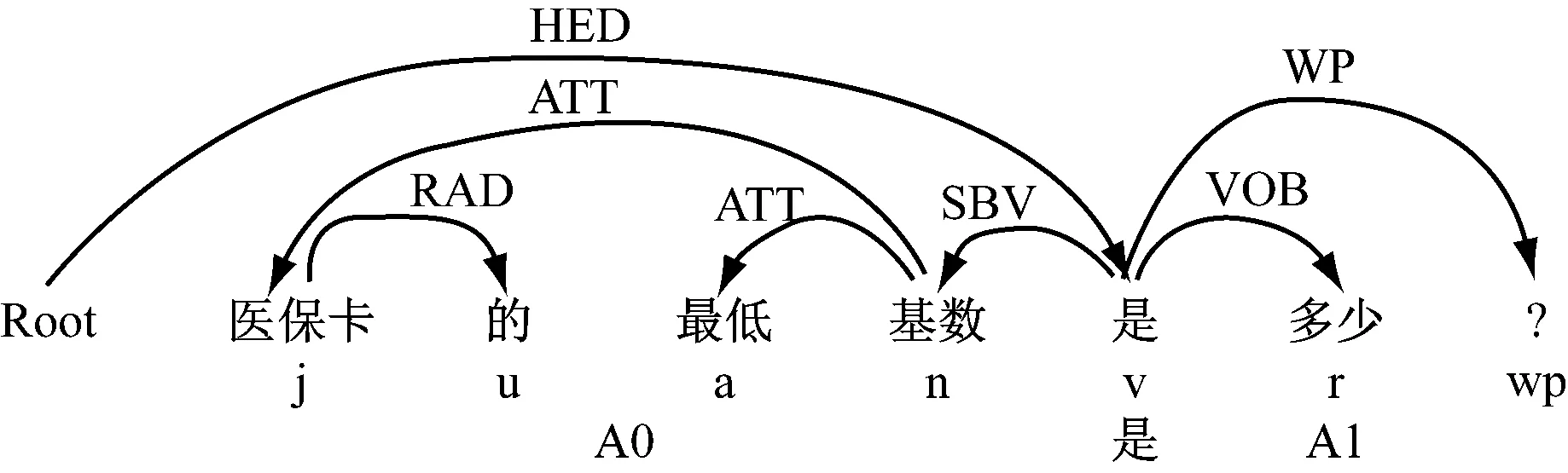
图7 对问题Q4的预处理结果
通过Q3与Q4可以看出,这类问题的疑问内容是实体的属性值。
规则3:特殊疑问词为事件的动词论元
例如,问题Q5={怎么办理医保卡?},QF(Q5)={特指疑问:怎么;事件论元(办理-医保卡):? },用户的疑问是想知道事件“办理”的论元取值是什么,如图8所示。
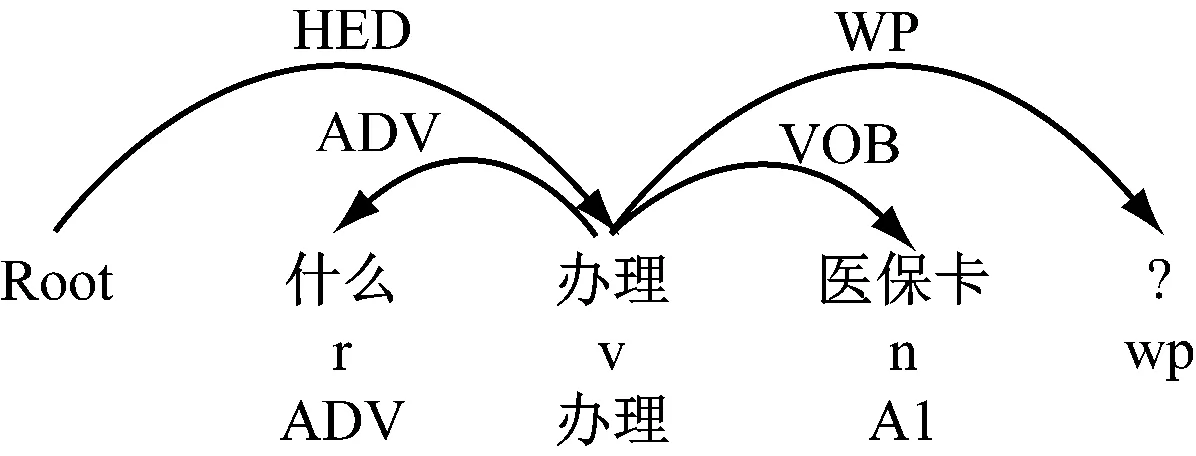
图8 对问题Q5的预处理结果
例如,问题Q6={如何办理医保?},QF(Q6)={特指疑问:如何;事件论元(办理-医保):?},用户的疑问是想知道事件“办理”的论元取值是什么,如图9所示。
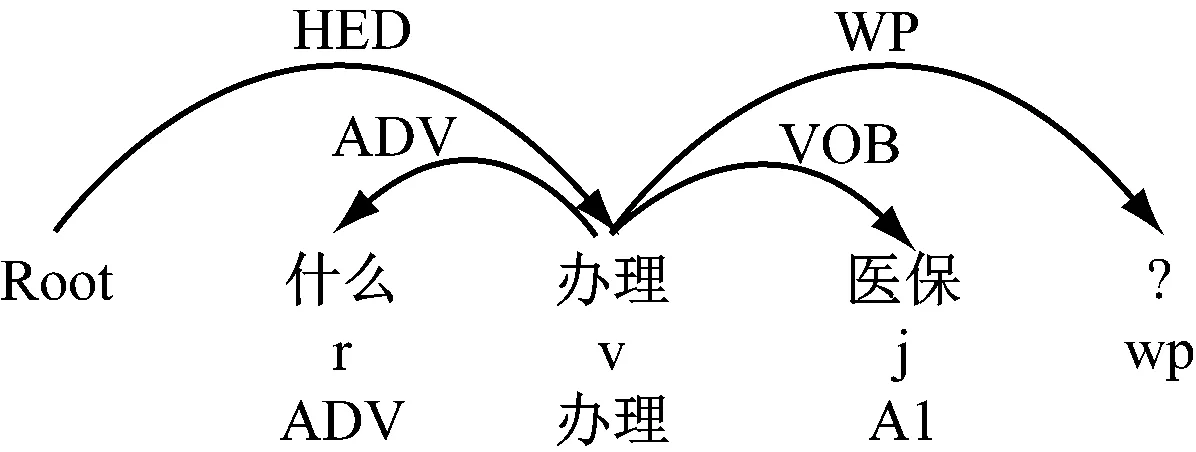
图9 对问题Q6的预处理结果
通过Q5与Q6可以看出,它们的事件都是“办理”,“怎么”与“如何”是同义词,但“办理”的对象不同,得出的焦点就不同,这类问题是用户想知道事件的论元取值,所以焦点是事件的论元。
2.3.2 基于焦点分类
焦点分类是对焦点相同的问题进行分类,焦点相同即同类。将疑问对象存入数据库中,并录入具体的答案。例如,问题Q3的疑问对象是“卡号”,在数据库中的实体属性列录入“卡号”。对问题Q1~Q6进行分类的结果是:Q1与Q2的类别是实体“医保卡”;Q4的类别是实体属性“最低基数”;Q5与Q6的类别是事件论元“办理”。
3 信息检索和答案抽取
信息检索是使用经过问题分类处理得出的关键字,在数据库中寻找问题的答案。答案抽取决定提供什么答案给用户。
经过问题分类,明确了问题焦点,医保卡数据库查询的过程是给定查询的目标(答案),以及查询的条件(事件、论元、实体、属性等),可以通过执行SQL命令的方式从表中迅速、方便地检索出数据。
具体语句为:SELECT问题答案FROM短信回复数据表WHERE特指疑问=具体的特指疑问词AND事件=具体事件名称AND实体=具体实体名称AND属性=具体属性名称。
可以通过上述语句完成答案的查询。其中,对于规则1的信息检索,只要查询(事件=具体事件名称)或(实体=具体实体名称)就可以查询出具体的答案。规则2的信息检索则需要查询(实体=具体实体名称)和(属性=具体属性名称)。只有规则3需要全部查询。
对于事件关系与实体关系问题,根据语义进行分析,通过自联接完成。以实体关系为例,具体语句为:SELECT表1.问题答 FROM短信回复数据表AS表1,短信回复数据表AS表2WHERE两表连接AND特指疑问=具体的特指疑问词AND表1.实体=具体实体名称AND表1.实体2=具体实体名称。
通过问题理解、信息检索、答案抽取,最终实现了医保卡短信自动回复系统,如图10所示。
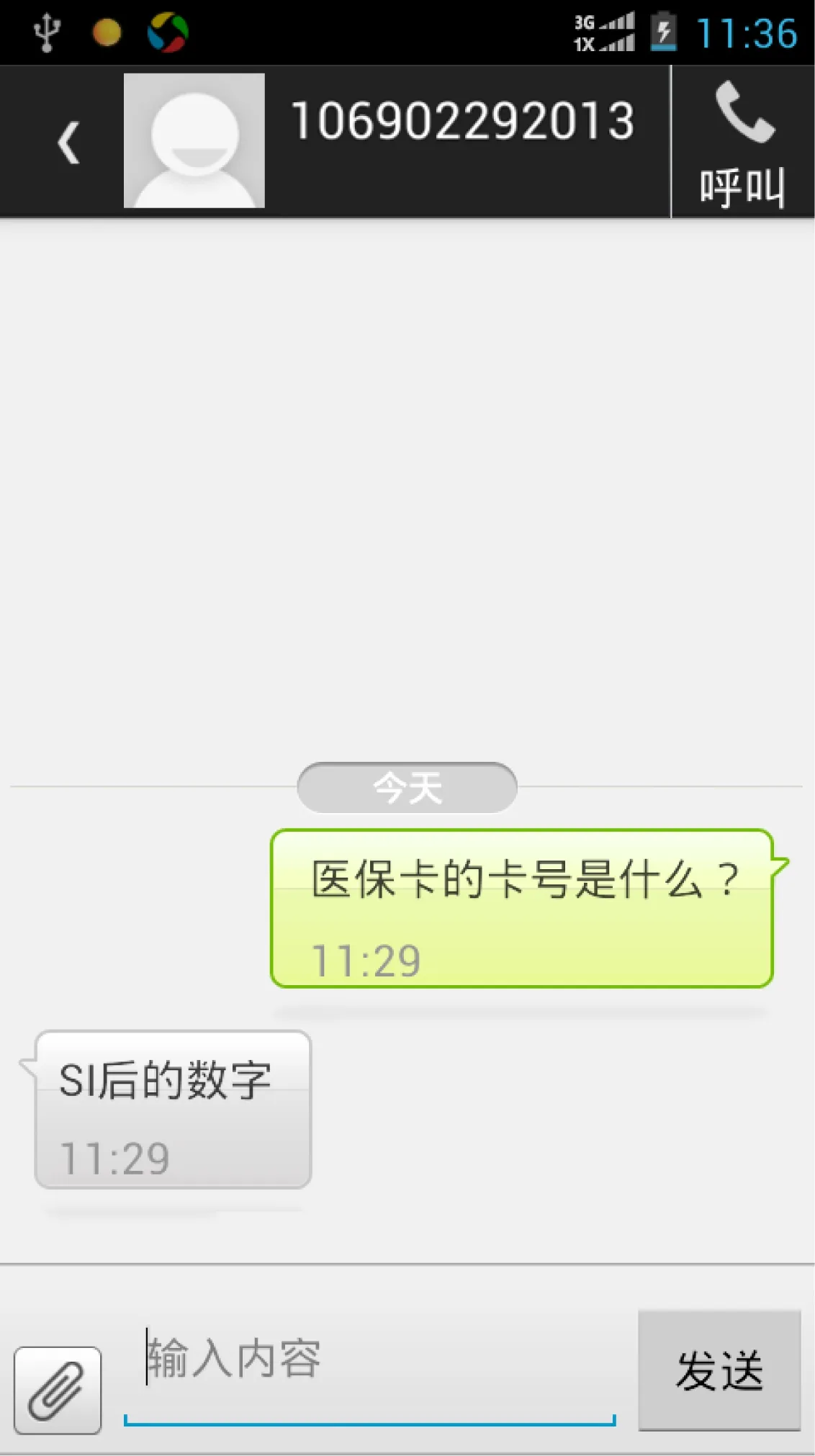
图10 短信自动回复
4 总结
医保卡自动回复系统结合焦点的问题理解,依存分析和语义角色标注对问题进行了浅层语义分析,然后从预先定义的问题焦点结构与焦点抽取规则中获取问题焦点,最后根据焦点相同即同类实现问题分类。该系统实现了医保信息能够方便、及时、高效的传递,一方面提高了人社局内部的办公效率,另一方面在参保用户与人社局之间搭建一种方便、高效、快捷的沟通渠道,提高了对参保用户的服务质量。
