基于Storm的大数据在线学习平台数据处理的设计与实现
2018-11-20刘引涛
刘引涛
(陕西工业职业技术学院,陕西 咸阳 712000)
0 引 言
由于“互联网+”的飞速发展,移动互联网在线学习平台成为一种新型学习方式,教育信息化开启了互联网在线学习的信息化[1],催生了各种在线学习平台的普及与应用,因此需要一种新技术解决消息请求响应,实时交叉、吞吐等过程中数据不完整的问题[2]。
在数据处理方式上,一般开发平台会选择Batch或Storm模型。传统的Batch形式已无法完全满足多途径多部门管理的数据处理,尤其是在对各业的务数据的获取和分析上,目前需要一种实时分析的数据处理方法,而Storm对实时流数据的处理具有实时性、可靠性、完整性及可扩展性的优势;对于大数据分析平台而言,技术选择一般使用Spark-streaming,部分技术实力雄厚的公司会进行专门程序的开发与信息处理。平台开发主要是对业务需求的实现,而对于实时数据引用的稳定性、数据和信息的共享性及分析处理系统无法达到统一。从系统开发的稳定性和成熟度出发,选择Storm作为实时平台的开发数据处理方案是一种较为理想的做法。本文的研究探索主要将Storm技术应用于移动互联网在线学习平台,可促进该系统的优化改进。
1 系统业务需求
移动互联在线学习平台在“互联网+”背景下得到了快速响应与发展,并在教育教学中得到了推广与应用,因学习平台在运行过程中会产生大量数据,如学习者登录学习平台后点击的文档、视频、音频会让平台在任意时间面临多种数据查询的请求,该运行数据具有类型多样、规模繁杂等特点,传统的分散性业务系统与平台已难以满足当前移动互联网大数据平台的要求[3]。
移动互联网在线学习平台的数据来源主要是学习者学习、浏览、讨论、留言、答疑、测试等全部学习活动的记录轨迹,并将活动记录传递到学习功能服务器。由功能服务器收集、计算、处理、存储学习者的学习情况。学习功能服务器通过使用Storm对实时数据进行快速清洗、格式转换、数据分析,设计实现可降低请求响应时间,解决数据库因连接限制而丢失数据的问题。重点在于集成多种数据,分析挖掘数据的可视化等方面。
数据读取、处理环节主要通过Storm的Topology编程模型中的Spout组件和Bolt组件完成,其中Spout组件主要完成数据读取,Bolt组件主要完成任务处理,使用Topology编程模型的目的在于降低处理延迟[4-5]。
2 总体方案设计
在线学习平台为学习者提供了专属的学习环境,学习者可多终端学习,授课教师、助教、企业导师等完成学习讨论,通过随堂练习及时检验学习成果。
移动互联网在线学习平台要应对突发的大数据量请求,提出数据源、大数据平台和业务应用三层数据处理结构,根据数据来源不同,将数据分为内部和外部两种,在线学习平台的内部数据主要来源于后台管理平台、课程管理平台和资源管理系统平台,外部数据主要来源于创建者的专属课程搭建平台、在线学习系统平台和互动管理平台[6]。
在线学习平台的优化架构中每个模块的功能实现主要通过Memcached,Flume,Storm,Kafka技术实现数据收集、数据缓冲、数据处理与数据存储[7]。这里将优化方案应用到网络学习平台中进行分析对比,对总体架构的环境进行搭建和部署。学习者通过课程学习、讨论、测试等形成数据流,由互动管理实现多维度统计,并通过Storm架构进行流数据处理。在线学习平台大数据框架如图1所示。
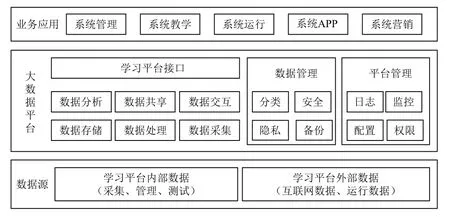
图1 在线学习平台构架
3 Storm平台框架的分析与整合
Storm架构采用一个主进程和多个从进程的主从架构模式,对该进程配置时,主要依靠ZooKeeper进程完成主进程和多个从进程之间的协调,需将ZooKeeper进程同时配置到集群的每个节点上。ZooKeeper进程主要保证各服务器之间的流数据同步。ZooKeeper角色分析见表1所列。
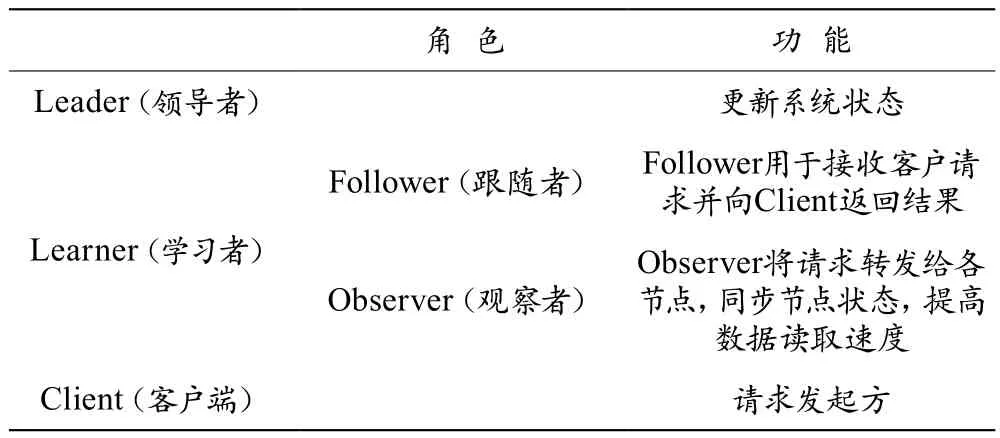
表1 ZooKeeper角色分析一览表
运用Storm完成数据的接收与逻辑运算,Storm在进行数据处理时主要通过Spout读取逐条记录,并通过Bolt1对不符合要求的数据进行筛查,Bolt2将统计结果存储或更新至数据库,拓扑Topology完成数据处理。在集群状态下,运用ZooKeeper进程保证数据的完整性和一致性。
4 平台的设计与实现
4.1 平台环境搭建
通过安装Storm系统依赖包与工具包,在若干个节点机构集群上搭建Storm开发环境,依赖安装包主要包括python,jdk,gcc_c++,libuuid,uuid,libtool,libuuid-devel等;在安装所需工具上使用ZooKeeper封装关键服务,防止协调系统出错,将简单易用、性能高效、稳定的接口提供给用户;使用ZerMQ屏蔽网络编程,安装ZerMQ用于处理一个消息队列,实现多个线程、内核和主机盒之间的灵活伸缩[8]。
Storm主要实现主程序设计,可方便在任一计算机集群中编写与扩展复杂的实时计算,保证每个消息都能被及时处理并集中在一个小集群中,实现每秒处理百万消息。
环境搭建主要步骤(以4个集群为例):
步骤一:修改文件用户属性:#chow -r root:root/home/local/storm
步骤二:编辑prof i le文件:# vi/etc/prof i le
Export storm_home=/home/local/storm
Export PATH=$PATH:$STORM_HOME/bin;
步骤三:修改环境变量:#source/etc/prof i le;
步骤四:修改storm参数:# vi/home/local/ storm/conf/storm.yaml
步骤五:添加如下内容:
Storm.zookeeper.servers:
-“node1”
-“node2”
-“node3”
-“node4”
Nimbus.host:“node1”
Storm. Local.dir:” home/local/ storm/temp”
Storm.zookeeper.port:2181
Supervisor.slots.ports:
-6700
-6701
-6702
-6703
步骤六:新建temp:#mkdir/home/local/storm/temp
Storm开发环境需要在若干个节点机上分别安装相同的工具包,可从node1节点机上复制软件到其他节点机上,并分别修改环境变量和配置文件,主要通过如下两个步骤实现:
(1)使用scp-r复制文件到其他节点机上(# scp-r /home/local root@node n :/home/local);
(2)分别登录节点机修改环境变量,环境变量生效(#source/ect/prof i le)后根据zoo.cfg中server.id的ID值修改各节点机ZooKeeper_home/data/myid的内容。
4.2 平台中Storm的流数据处理
移动互联在线学习平台中的流数据处理是对在线学习平台的管理、运行、监控过程中产生的实时数据流提供有效数据的一种处理机制。笔者选择Storm作为计算系统,该系统具备高效的数据实时分析功能[9]。在线课程平台流数据处理架构如图2所示。
系统从数据来源、Storm计算平台及流处理三个环节入手,分析在线学习平台中所获取、处理及存储的数据。系统在完成数据收集及预处理后,将收集的完整、正确的数据提供给实时应用系统,并将不完整的数据处理成为标准化数据,通过业务逻辑对数据进行分析,最后将处理结果存储在数据库中。

图2 在线课程平台流数据处理架构
4.3 数据存储处理
数据存储主要采用关系型数据库存储数据,在关系型数据库前加上Memcached暂存数据,保证数据连接池中数据的完整性并解决数据存储和处理速度不一致问题,所有存储过程由Storm中的Bolt组件完成[10]。为保证数据的完整性和一致性,系统运用ZooKeeper的锁机制来解决这一问题。
解决方法的核心代码如下:
interprocessMuter lock=
new interprocessMutex(LockCuratorSrc.getCF(),Constant.
LOCKS_ORDER);
try{while(lock.acquire(5,timeUnit.Minutes))
BREAK;
LOCK.RELEASE();
5 结 语
在移动互联在线学习平台开发应用的背景下,通过对学习者行为数据的深入研究,在线学习系统服务的大数据平台管理成为一种发展新趋势。在理论研究的基础上,根据在线学习平台的特点及需求,提出大数据平台架构,针对在线学习平台的流数据处理,将流数据处理技术Storm与在线学习平台开发相结合,提出实时数据的处理方案。
