和声搜索算法用于测试性建模的测点布局优化
2018-11-17刘远宏冯辅周
丛 华,张 睿,刘远宏,冯辅周+
(1.陆军装甲兵学院 机械工程系,北京 100072;2.武警工程大学 装备工程学院,陕西 西安 710000)
0 引 言
测点布局优化问题是属于典型的集合覆盖和多目标组合优化问题[1]。解决该问题通常是在系统测试性模型输出的故障-测试相关性矩阵基础上,引入遗传算法、粒子群等优化算法来实现。文献[2-4]通过采用不同的现代进化算法获得系统最优测试集合,具有较快的收敛速度,但是在使用不同算法求解该问题的稳定性方面还有待提高。
和声搜索算法是通过模拟音乐演奏原理来进行搜寻最优解[5,6]。该算法结构简单,具有良好的结合性,在解决多变量优化问题上比传统的遗传算法有着较好的稳定性,求解全局最优解的能力更好,已在多变量多维度调度问题[7-10]上得到应用。
目前,和声搜索算法未在解决设备系统的测点布局优化问题上得到应用,所以本文将传统和声搜索算法进行改进。首先将和声中每个位置进行离散编码,并对算法中“即兴创作”这一学习策略进行改进,引入一个新的控制参数—即兴创作概率(improvisation rate,IR)。该参数数值变化为指数递增,通过参数前期变化为小而慢,增强全局寻优能力;后期变化大而快,增强求解速度。最后,将改进和声搜索算法的优化结果与遗传算法的优化结果加以对比,验证其具有良好的优化性能,能更加快速稳定地获得最优测试集。
1 测点布局优化模型
1.1 测试性模型
传统的测点布局优化是通过技术人员的大量工业实践经验分析得到的,主观意识较强,往往存在一些隐蔽性较强的故障无法检测的现象,覆盖率不高,而且效率较低,只能针对简单系统进行优化分析。对于大型复杂的系统,通常采用建立测试性模型进行测点布局优化,能够准确地描述故障与测试之间的对应关系,并且可以有效地减少工作量,提高优化效率。
测试性模型采用有向图的方式表示系统组成单元、故障、测试等要素间的相关关系。常用的测试性模型有信息流模型、混和诊断模型和多信号流图模型。在所有的测试性模型中,系统模块表示系统内组成单元的结构,故障模块表示系统组成部件具有的多种故障,在系统组成部件内添加多种测试点,连接线用于表示单元、故障和测试之间信号传递。
建立测试性模型,输出故障-测试性相关矩阵。以故障-测试相关性矩阵为基础,得到故障与测试之间的关系,从而分析不同测点选择方案,可以更加快速地分析该系统的测试性,并对其作出评价。故障-测试相关性矩阵是解决基于测试性模型的测点布局优化问题的核心。
1.2 故障-测试相关性矩阵
故障-测试相关性矩阵,即D矩阵,以此为解空间,寻求测试成本最低的最优测试方案,并且满足系统所提出的测试性指标要求。
通常,D矩阵为布尔矩阵,能够描述系统内各个故障模式与各测试点之间的关系。其数学模型可以用下述矩阵来表示,即
矩阵中的元素tij值取1时,表示第i个故障模式与第j个测试点具有相关性;反之,二者不相关。其中,行向量代表故障模式在各测试点上的响应信息,列向量代表测试点所能检测的故障信息。D矩阵有着建立系统故障与测试性能之间关系的能力,在D矩阵的基础上计算系统的测试性指标参数。
1.3 测试性指标参数
测试性指标参数用于评判系统的测试诊断能力,最优测试集必须以满足所规定的测试性指标为前提,常用的测试性指标有故障检测率和故障隔离率。测点布局优化问题中,当D矩阵中存在某一行中元素不全为零,则该行对应的故障为可检测故障,所有可检测故障组成可检测故障集,即FD。故障检测率的定义请参见文献[11],则当考虑故障率时,故障检测率的计算公式如下
(1)
式中:λi第i个故障的先验概率;FD为可检测故障集;F为所有故障模式集。
如果存在相同的两行,则这两行所对应的故障不能隔离,否则能够进行故障隔离,所有可隔离故障组成可隔离故障集,即FI。故障隔离率的定义请参见文献[11],则当考虑故障率时,故障隔离率的计算公式如下
(2)
式中:FI为可隔离故障集。
1.4 优化模型
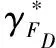
(3)
式中:T为所选测试集合,ti为测试集中元素,当取值为1时,该测试点被选中;ci为第i个测点的测试成本。
通过测试性模型所获得的D矩阵往往矩阵维数较大,不同于简单系统的D矩阵。对于简单系统以D矩阵为解空间,维数相对较少,有时通过穷举法就可以直接得到最优测试集,但是大型复杂系统来说,如果使用穷举法求解计算量是巨大的,并且求解效率较低。所以通常借助优化算法确定最优测试集,文中采用和声搜索算法进行求解,缩短了搜索时间并且提高了搜索效率。
2 改进和声搜索算法的基本原理
2.1 基本和声搜素算法
和声搜索算法是由Geem等提出的一种新型启发式全局优化算法[12]。该算法通过模拟音乐家凭借自己的经验记忆在创作音乐时不断进行音调的调节,以求得最为完美的和声的过程来进行求解全局最优解。
算法首先随机产生一个具有HMS(harmony memory size)个和声的和声记忆库,其中和声代表可行性解,并对每个和声进行适应度计算,用于最终筛选最优和声。然后,模拟音乐创作中3个步骤,即记忆学习、微调音调、即兴创作,产生新的和声Xnew,与记忆库中的适应度最差的进行比较,若优于原记忆库中的和声,则旧和声会被取代。不断重复上述过程更新和声记忆库,直到达到最大迭代次数为止,使得最终记忆库中的和声为最优和声。
2.2 改进和声搜索算法
2.2.1 编码
传统和声搜索算法中一个和声中的各个音调变量是对应求解问题的自变量所取的数值,而基于D矩阵的测点布局优化问题中需要将和声转变为测点的选取情况。因此对各个测点进行编码,生成n维的布尔数组,使和声能够表示测点是否选择。当系统内可选测点数量为n,则和声的长度为n,其中和声中每个元素代表相应编码测点的决策变量,当元素值取1时,表示该测点被选中,反之为0表示未被选中。
2.2.2 计算适应度
和声表示可选测试点中不同测点的组合选择方案。通过特定和声对应的测点在故障-测试相关性矩阵中对应的列向量重新构建新的子矩阵,并计算该矩阵的测试性指标参数。在原优化数学模型中,测点成本最少为最优目标,故障检测率和故障隔离率为约束条件。文中采用基于惩罚函数的处理方法,对不满足约束条件的解进行惩罚,反之对满足约定条件的解不进行惩罚,个体适应度的数学公式如下所示

(4)
其中,α、β与ε均为常数,代表惩罚因数,通常取值为α=0.7,β=0.5,ε=0.5。
2.2.3 产生新和声
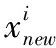
其中
(5)
式中:η1,η2为随机参数。
由于所优化问题为二进制问题,和声中元素为备选测点选取的决策变量,取值范围仅为0、1。而传统和声算法中和声元素表示为数值变量,采用即兴创作方式生产新和声时,只需在变量取之范围内随机生成,保证了所生和声的多样性,所以传统的即兴创作应用于测点布局优化问题上并无实际意义,不仅会减小测点选取的多样性,而且会影响求解该问题的收敛速度,因此在即兴创作方式中,引入一个即兴创作概率IR,并能够随迭代次数增加呈指数递增变化。
当随机参数η2小于IR时,新和声音调取值为0,反之,取值为1。在算法运行初期,IR数值变化减慢且取值较小,能够增加和声的多样性,有利于在全局范围内搜索到最优解;而在运行后期时IR数值变化速率加快且取值较大,能够加快搜索速度,有助于增加算法的收敛性,参考文献[13]中给出了IR的指数递增变化表达式,可得IR计算公式如下所示
(6)
其中,k为本代的迭代次数,IRmax为即兴创作概率的最大值,IRmin为即兴创作概率的最小值,K为最大迭代次数。由于参数IR为概率值,取值范围为(0,1),所以IRmin=0.01,IRmax=0.99。则改进后产生新和声的数学表达式为
其中
(7)
式中:η1,η2为随机参数。
2.3 和声搜索算法用于测点布局优化的优化流程
步骤1 初始化和声搜索算法各个控制参数,即确定和声记忆库大小HMS、记忆库学习概率HMCR、音调微调概率PAR以及最大迭代次数K;
步骤2 依据故障-测试相关性矩阵中测试数量的大小,确定每个和声的长度,并初始化随机生成和声记忆库;
步骤3 计算本记忆库中各个和声所对应的测试集的故障检测率、故障隔离率和测点数目,然后计算求得各和声的适应度,作为择优依据;
步骤4 根据HMCR、PAR及IR这3个控制参数,并采用记忆学习、音调微调及即兴创作3种方式,生成新的和声;
步骤5 更新和声记忆库,对新和声进行判别:是否优于原和声记忆库中最差和声;
步骤6 当迭代次数满足最大迭代次数时,停止运行算法,否则重复步骤3和步骤4。
改进和声算法的流程,如图1所示。

图1 改进和声算法的流程
3 实例分析
为检验改进和声搜索算法对于求解测点布局优化问题的优越性,以文献[3]给出的某设备的故障-测试相关性矩阵为例,见表1,其中故障源有15种,备选测试点有20个,每个测试点测试代价记作为1,各个故障模式的先验故障率分别为10-3×[1.0,1.0,1.0,1.0,1.0,1.0,1.0,2.0,1.0,1.0,1.0,2.5,1.5,1.0,1.0]。与遗传算法的优化结果进行对比实验,算法中的相关参数见表2、表3。
根据文献中所提出的测试性指标要求:γFD≥95%,γFI≥80%。对可选的20个测试进行编码,依次为t1~t20,并建立规模为30个和声的和声记忆库,依据所设置的3个控制参数进行和声搜索求解优化。最终得到最优测点选择方案为{t1,t3,t4,t9,t10,t11,t12,t13,t14,t19,t20},此时故障检测率为96.6%,故障隔离率为86.4%,均满足所提出的测试性指标要求,最小的测试成本为11。采用遗传算法进行求解优化,得到的最优测点选择方案与和声搜索算法的结果一致,并进行了求解速度与稳定性的对比实验。
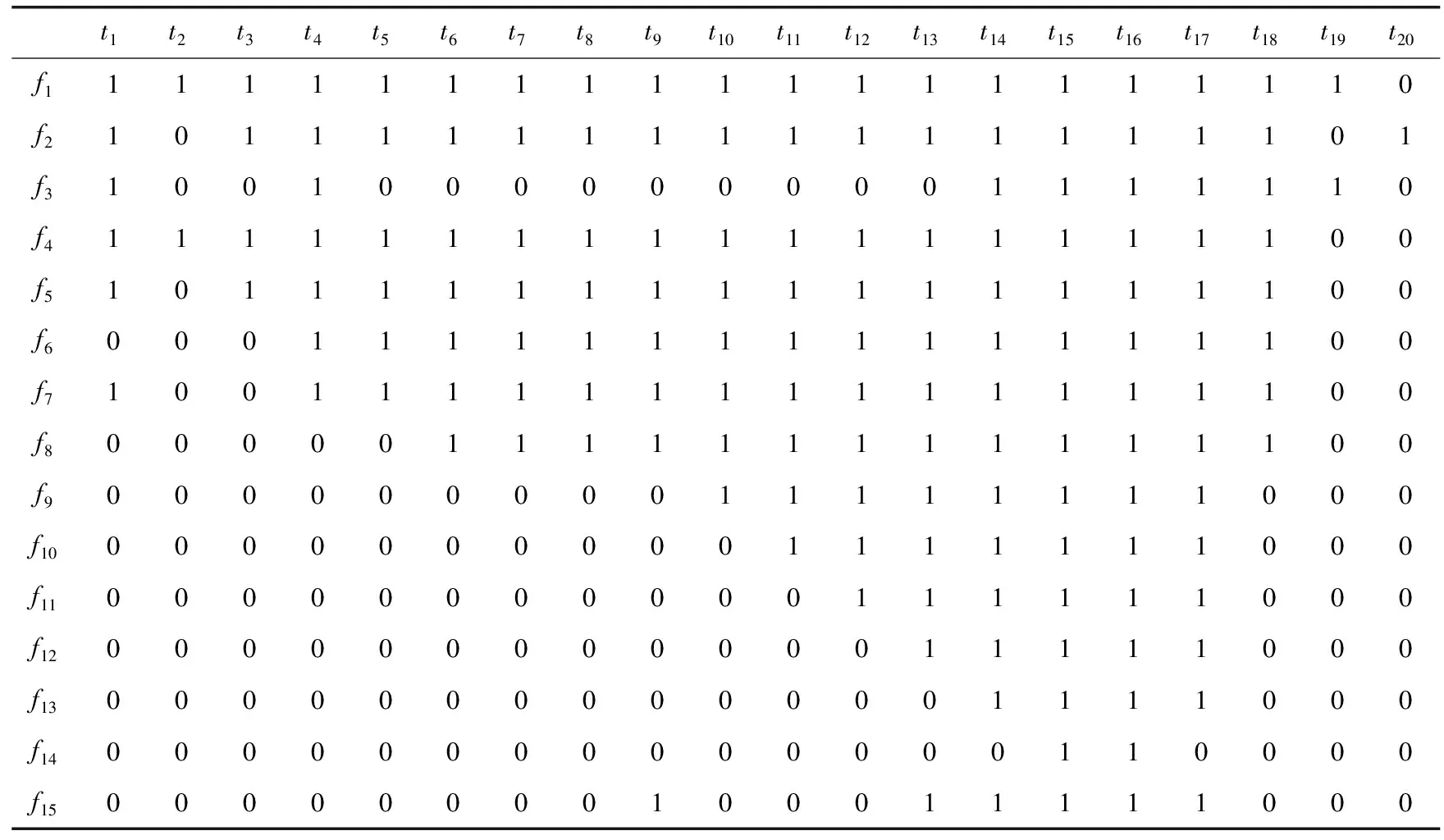
表1 故障—测试相关性矩阵
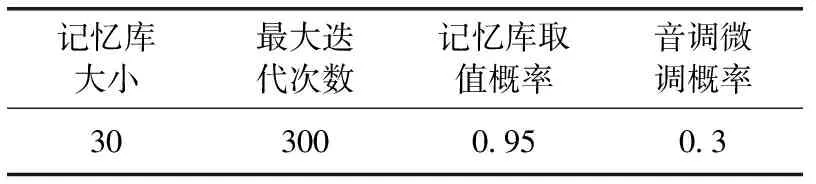
表2 改进和声搜索算法初始化参数

表3 遗传算法初始化参数
实验一:对比算法求解速度
在处理器为Intel(R)Core(TM)i5 CPU 1.80 GHz的电脑上,使用Matlab编程,分别独立运行100次,不同算法每一次的求解时间,如图2所示。从图2中在运行100次中遗传算法的求解时间集中分布在(1,2)之间,要普遍大于改进和声搜索算法的求解时间。取100次求解时间的平均值,见表4。实验对比结果表明改进和声搜索算法能够更加快速地找到最优解,所以能够在短时间内解决大型复杂系统的测点布局优化问题。
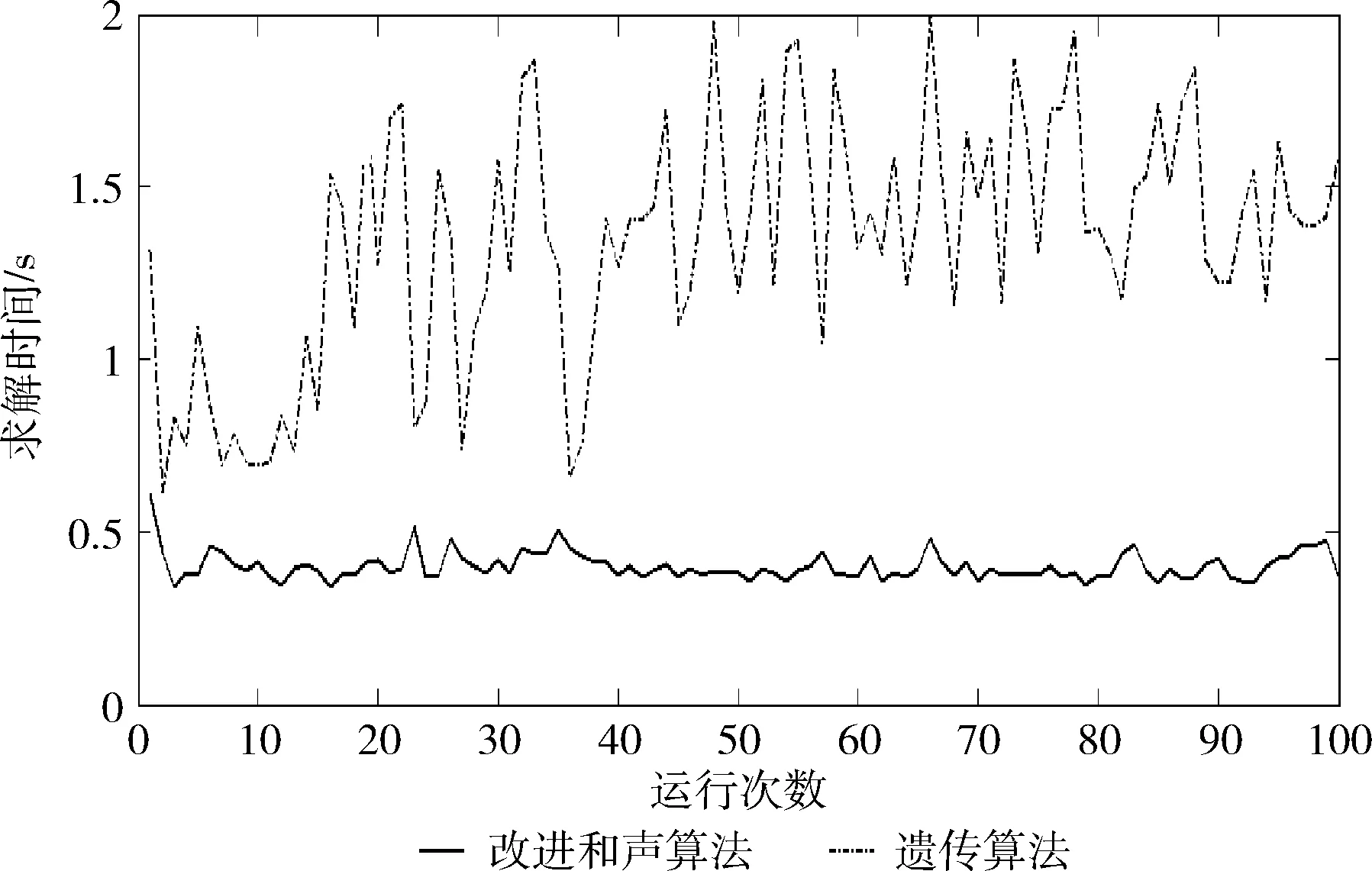
图2 求解时间对比

表4 平均求解时间对比结果
实验二:对比算法稳定性
为对比不同算法获取最优解的稳定性,分别运行100次,各算法运行后得到最优测试方案的统计直方图如图3所示。从中可以看出改进后的和声搜索算法所优化结果中最优测点选择方案占总数的96%,遗传算法占82%。算法稳定性对比结果:改进和声搜索算法>遗传算法。实验结果表明改进和声搜索算法的获取全局最优解的能力更强,比遗传算法陷入局部最优解的概率更低,能够有较大的概率获取真实的最优测试集。

图3 运行结果统计直方图
4 结束语
为解决遗传算法求解测点布局优化问题稳定性不强,易陷入局部最优解的问题,采用了和声搜索算法,并针对所优化问题为二进制寻优问题,对该算法进行改进,引入一个新的控制参数—即兴创作概率。通过与遗传算法优化结果对比,得出改进后的和声搜索算法在寻求全局最优解的能力上有者较好的能力,减小了陷入局部最优解的概率,提高了搜索全局最优解的稳定性,并且求解搜寻速度较快,具有较好的综合性能,验证了对于求解测点布局优化问题上的有效性,具有一定的工程应用价值。
